当因式分解遇见近邻:一种多层面协同过滤模型(SVD++)
本文地址:https://www.cnblogs.com/kyxfx/articles/9392086.html
actorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model
原作者

本文地址:https://www.cnblogs.com/kyxfx/articles/9392086.html
2.1 基线估计
(略,有兴趣看原文)
2.2 邻域模型
CF最常用的方法是基于邻域模型。它最初的形式,几乎所有早期的CF系统都是用的,是面向用户的;请参阅[12]中的优秀算法。这种以用户为导向的方法基于有相同想法的用户的记录评分来估计未知的评分。后来,类似的面向项目的方法[15,21]开始流行起来。在这些方法中,使用相同用户对类似项目的已知评分来估计评分。更好的可扩展性和更高的准确性使得面向项目的方法在许多情况下更加有利[2,21,22]。此外,面向项目的方法更容易解释预测背后的推理。这是因为用户熟悉他们以前喜欢的东西,但不知道那些所谓的有想法的用户。因此,我们的重点是面向项目的方法,但可以通过切换用户和项目的角色,以面向用户的方式开发类似的技术。
大多数面向项目的方法的核心是项目之间相似性的度量。通常,它是根据皮尔逊相关系数,ρij,衡量用户评价物品i和j的相似性倾向。由于许多评分都是未知的,可以预期一些项目只能共享给少数几个普通的评分人。相关系数的计算仅基于普通用户的支持。相应的,基于更好的用户支持的相似性更可靠。一个合适的相似度度量,用sij表示,是缩小版的相关系数:
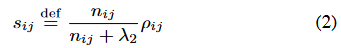
变量nij表示同时评价了i和j的用户数量,λ2的典型值为100。请注意,文献中提出了相似度度量的其他替代方法[21,22]。
我们的目标是预测rui-未被观察到的用户u对项目i的评分。通过相似性测量,我们确定k个被u评分过最接近i的项目。这组k近邻定义为Sk(i;u)。邻项评分的加权平均值,再通过基线估计对用户和项的影响进行调整,从而获取rui的预测值。rui的预测值使用通过基线估计对用户和项目的影响进行调整后的邻项评分的加权平均值:
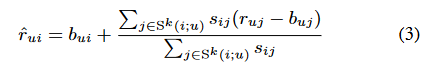
这种基于邻居的方法变得非常流行,因为它们是直观的,而且实现起来相对简单。然而,在最近的[2]工作中,我们对此类近邻结构提出了一些担忧。最值得注意的是,这些方法并不是由一个正式的模型证明的。我们还质疑两个项目之间的相似性度量的适用性,没有分析所有邻居集的交互另外,公式3中的连加和为1的插值权重强制方法完全依赖于近邻甚至在邻居信息缺席的情况下(即,用户u没有对与i类似的项目进行过评分),此时仅依赖于基线估计。
为了克服这些问题,我们提出了一个更准确的近邻模型。给定一组邻居的Sk(i;u)集合我们需要计算插值权重{θiju | j∈sk(i;u)}使该公式具有最佳的预测规则:
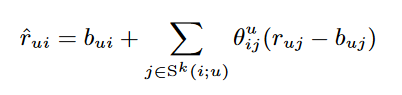
通过估计各项目评分之间的内积,可以有效地推导出插值权重;详细描述请参阅[2]。
2.3 隐式因子模型
(略,有兴趣看原文或svd算法)
2.4 Netflix的数据
(略,有兴趣看原文)
2.5隐式反馈
如前所述,这项工作的一个重要目标是设计集成显式和隐式的用户反馈的模型。对于Netflix数据这样的数据集,最自然的隐式反馈选择是电影租赁历史,它告诉我们用户的喜好,而不需要他们明确地提供他们的评分。然而,这些数据对我们来说是不可用的。不过,Netflix数据集中确实存在一种不太明显的隐式数据。数据集不仅告诉我们评分值,而且还告诉我们用户评了哪些电影,不管他们是如何评价。换句话说,用户通过选择表达自己的观点并投票给一个(高或低的)评分来含蓄地告诉我们她的偏好。这将评级矩阵减少为二元矩阵,其中“1”表示“评分了”,“0”表示“未评分”。诚然,这种二元数据并不像其他隐性反馈来源那样庞大和独立。尽管如此,我们发现,将这种隐含数据(在基于评分的推荐系统中固有存在的)结合起来,可以显著提高预测的准确性。一些先前的技术,如条件RBMs[18],也使用相同的数据二元视图。
我们提出的模型并不局限于某种隐性数据。为了保持通用性,每个用户u都与两组项目相关联,一组项用R(u)表示,并包含所有被u评分的可用项目。另一个用N(u)表示,包含所有u提供隐式偏好的项目。
3。一个近邻模型
在本节中,我们将介绍一个新的近邻模型,它允许一个有效的全局优化方案。该模型提供了改进的准确性和能够集成隐式用户反馈。我们将通过不断改进我们的公式逐步构建模型的各个组成部分。
先前的模型都是围绕特定的插值权重-θiju 公式(4)或者sij /∑j∈sk(i;u)sij 公式(3) -将项目i与用户相关的邻居sk(i)关联;为了促进全局优化,我们希望放弃这样的用户相关的权重,以支持独立于用户的全局权重。从j到i的权重值用wij表示,通过优化从数据中学习。该模型的初始草图描述了由该方程给出的每一个评分rui。
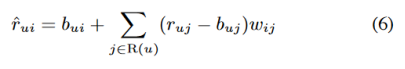
目前,(6)与(4)看起来并没有太大的不同,除了我们声称wij不是用户相关的。另一个不同之处是,我们将很快讨论一下,这里我们对u的所有项目求和,不像公式(4)只对Sk(i;u)。
让我们考虑一下权重的解释。通常,邻域模型中的权值表示将未知评级与现有评级相关联的插值系数。在这里,我们采用不同的观点,权重表示基线估计值的偏移。而差ruj−buj,被视为这些偏移的乘法系数。对于两个相关的项目i和j,我们期望wij是高的。因此,每当用户u评价j高于预期(r uj−buj很高),通过在基线估计上增加(ruj−buj)wij,我们将增加我们预估的u对i的评分。同样,当用户u给一个项目j评分比较接近期望(ruj−buj约为零),我们估计评分不会偏离项目i的基线太多。这个观点提出了对(6)的一些改进。首先,我们可以使用隐式反馈,它提供了一种学习用户偏好的替代方法。为此,我们添加另一组权重,并将(6)重写为

就像wij的一样,cij也是在基线估计值上增加的偏移量。对于项目i和j,由u到j的隐式偏好使我们用cij修改了对rui的估计值,如果j对i有预测性,则cij值会比较高。
将权值视为全局偏移量,而不是用户特有的插值系数,强调了缺失评分的影响。换句话说,用户的意见不仅是由他已评分的决定的,也是由他未评分决定的。例如,假设一个电影评分数据集显示,“指环王3”评分高的用户对“指环王1-2”的评分也很高。这将建立从《指环王1-2》到《指环王3》的高权重。现在,如果一个用户根本不给“指环王1-2”打分,那么他对“指环王3”的预估评分将会被扣分,因为一些必要的权重不能被加到总分中。
之前的模型((3),(4)),使用{ruj−buj | j∈sk(i;u)}插值rui-bui,有必要保持bui值与buj值之间的适应性。然而,这里我们不使用插值,所以我们可以解耦bui和buj的定义,更一般的预测规则是: 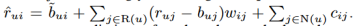 这里bui代表预测rui的一个其他方法,比如潜在因素模型。我们将在第5节中对此进行更详细的阐述。就目前而言,我们建议的规则是:
这里bui代表预测rui的一个其他方法,比如潜在因素模型。我们将在第5节中对此进行更详细的阐述。就目前而言,我们建议的规则是:

重要的是,buj仍然是常数,这在2.1节中解释过。然而,bu和bi变成了参数,它们使用与wij和cij类似的优化方法。
当前方案的一个特点是,对于提供许多评分(高|R(u)|)或大量隐式反馈(高|N(u)|)的用户,它鼓励更大程度地偏离基线估计。一般来说,这是推荐系统的良好实践。我们希望为提供大量输入的建模良好的用户冒更多的风险。对于这样的用户,我们愿意预测更古怪、更不常见的建议。另一方面,我们不太确信只提供少量输入的用户的建模,在这种情况下,我们希望使用接近基线值的安全估计。然而,我们的经验表明,目前的模型在某种程度上过分强调了重评分者和很少评分者之间的区别。当我们调节这种行为,用以下方法代替预测规则时,得到了更好的结果。
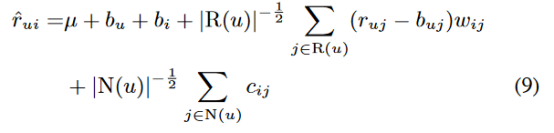
通过裁剪不相似的项目-项目关系相对应的参数,可以降低模型的复杂性。让我们用Sk(i)表示与项目i最相似的k项集合,由相似度Sij决定。此外,我们使用 和
和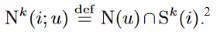 现在,在使用公式(9)预测rui时,预期影响最大的权重将与和i类似的项目相关联。因此我们使用以下公式替换公式(9)
现在,在使用公式(9)预测rui时,预期影响最大的权重将与和i类似的项目相关联。因此我们使用以下公式替换公式(9)
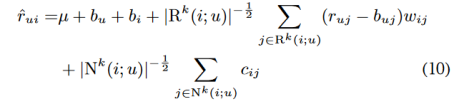
当k =∞,规则(10)和(9)一致。然而,对于k的其他值,它提供了显著减少所涉及变量数量的潜力。
这是我们的最终预测规则,它允许快速的在线预测。在估计参数的预处理阶段需要更多的计算工作。新邻域模型的一个主要设计目标是促进有效的全局优化过程,这是之前的邻域模型所缺乏的。通过求解与(10)相关的正则化最小二乘问题,得到模型参数:

这个凸问题的最优解可以通过最小二乘法得到,最小二乘法是标准线性代数软件包的一部分。然而,我们发现下面简单的梯度下降法工作得更快。让我们表示预测误差,rui−ˆrui为eui,在K中循环所有已知的评分,在一个给定的训练集rui下,我们通过向梯度方向相反的方向移动修改参数,产生
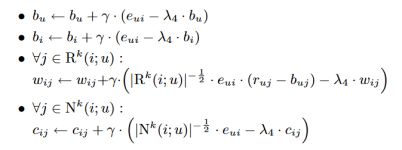
参数和性能部分略(有兴趣看原文)
4 隐因子模型回顾

通过最小化相关的平方差函数(5)来估计参数。Funk[9]推广了梯度下降法优化,这已经被许多人成功实践过[17,18,22]。今后,我们将把这个基本模型命名为“SVD”。我们想通过考虑隐式信息来扩展模型。根据Paterek[17]和前面部分的工作,我们提出以下预测规则:
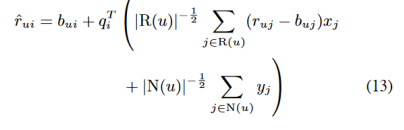
这里,每个项目i与三个因子向量有关qi,xi,yi∈ Rf。在另一方面,我们通过使用用户喜欢的物品来表达用户,从而代替为用户提供显式参数化,。因此,之前的用户因子pi(应该是pu)被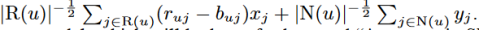 之和取代了。这个将是今后名叫“Asymmetric-SVD”(非对称svd)的新模型提供了许多优点:
之和取代了。这个将是今后名叫“Asymmetric-SVD”(非对称svd)的新模型提供了许多优点:
1。更少的参数。通常,用户的数量要比产品的数量大得多。因此,用项目参数替换用户参数降低了模型的复杂性。
2。新用户。由于非对称svd不参数化用户,所以我们可以在新用户向系统提供反馈后立即处理他们,而不需要重新训练模型并估计新的参数。同样,我们可以立即利用新的评分来更新用户偏好。注意,对于新项目,我们必须学习新的参数。有趣的是,用户和项目之间的这种不对称与常见的实践非常吻合:系统需要立即向期望得到高质量服务的新用户提供建议。另一方面,在向系统推荐新项目之前需要等待一段时间是合理的。顺便说一句,值得注意的是,面向项目的近邻模型显示了相同的不对称需求。
3所示。可解释性。用户希望系统给出预测的理由,而不是面对“黑盒”建议。这不仅丰富了用户体验,还鼓励用户与系统交互,修正错误的印象,提高长期的准确性。事实上,自动解释推荐的重要性得到了广泛的认可[11,23]。像SVD这样的潜在因素模型在解释预测时面临着真正的困难。毕竟,这些模型的关键是通过用户因素的中间层抽象用户。这个中间层将计算出来的预测与以前的用户操作分开,并使解释变得复杂。然而,新的非对称- svd模型没有在用户方面使用任何级别的抽象。因此,预测是过去用户反馈的直接作用。这样的框架允许识别过去的用户行为中哪些对计算预测最有影响,从而通过最相关的行为来解释预测。再一次,我们想提一下,面向项目的近邻模型也有同样的好处
4。隐式反馈的有效集成。通过考虑隐式反馈提高了预测精度,这提供了用户偏好的额外指示。显然,隐式反馈对用户来说变得越来越重要,因为他们提供的隐含反馈比显式的反馈要多得多。因此,在规则(13)中,当| N(u) |增加时,隐式视角变得更有优势,我们有很多隐含的反馈。另一方面,当| R(u) |增长时,显式视角变得更加重要,我们有很多显式观察。通常,一个显式输入比一个隐式输入更有价值。通过设置xj和yj参数的相对值,可以自动从数据中了解正确的转换比率,该比率表示有多少隐式输入与单个显式输入一样重要。
与往常一样,我们通过最小化与(13)相关的正则化平方差函数来学习相关参数的值:
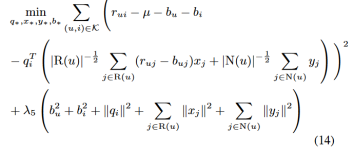
我们采用一个简单的梯度下降方案来解这个系统。在Netflix数据上,我们使用了30次迭代,步长大小(学习率)为0.002和λ5= 0.04。
一个重要的问题是,为了享受非对称svd的上述好处,我们是否会放弃一些预测精度。我们根据Netflix的数据进行了评估。如表1所示,不对称SVD的预测质量实际上略好于SVD。这种改进可能要感谢对隐性反馈的考虑。这意味着一个人可以享受非对称的svd所带来的好处,同时又不牺牲预测的准确性。如前所述,对于Netflix数据集,我们并没有真正的独立的隐式反馈。因此,我们预计,对于能够获得更好类型的隐式反馈(如租赁/购买历史)的现实生活系统,新的不对称svd模型将导致进一步的改进。然而,这仍然需要实验证明。
事实上,对于隐式反馈的集成,我们可以通过(12)的更直接的修改得到更准确的结果,从而得到如下模型:
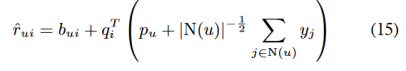
现在,用户u是建模为 ,我们使用一个从给定的显式的评分中学习的自由的用户因子向量pu,就像公式(12)中一样。这个向量组合上 ,这表示隐含的反馈。我们称这种模型为“SVD++”。[3,19]最近也讨论了类似的模型。通过梯度下降最小化相关的平方差函数来学习模型参数。SVD++不提供前面提到的参数较少,可以方便地处理新的用户并容易解释结果等好处。这是因为我们用一个因子向量来抽象每个用户。但是,如表1所示,SVD++显然在预测精度方面具有优势。事实上,据我们所知,它的结果比之前在Netflix数据上发布的所有方法都要准确。尽管如此,在下一节中,我们将描述一个集成的模型,它将进一步提高精确度。
5。一个集成模型
第3节的新近邻模型是基于一个这样的模型,它的参数是通过求解一个最小二乘问题来学习的。这种方法的一个优点是允许轻松集成其他基于类似结构的全局损失函数的方法。正如第一节所解释的,潜在因素模型和近邻模型相互补充。因此,在本节中,我们将把近邻模型与最精确的因子模型SVD++集成在一起。合并后的模型将对(10)和(15)的预测进行求和,从而使近邻模型和因子模型相互充实,如下所示:

在某种意义上,规则(16)为推荐提供了一个三层模型。第一层, 描述项目和用户的一般属性,不计算任何互动。例如,这一层可以证明说“第六感”电影是众所周知的好电影,而且我们的用户Joe的评分等级通常是平均的。下一层,,提供用户属性之间和项目属性的交互。在我们的例子中,它可能会发现《第六感》和Joe在心理惊悚片中排名很高。最后的“近邻层”提供了难以描述的细微调整,比如乔对相关电影《Signs》的评价很低。
模型参数是通过梯度下降最小化相关正则化平方差函数来确定的。回顾一下在一个给定的训练集下rui遍历K中所有已知的评分,我们通过向梯度的相反方向移动修改参数,产生:
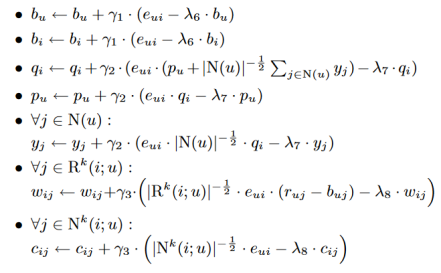
(猜测作者对上面提到的三个不同层的参数给了不同的正则化系数[即λ6,λ7,λ8])
(参数和性能部分略)
转载请注明出处:https://www.cnblogs.com/kyxfx/articles/9392086.html
当因式分解遇见近邻:一种多层面协同过滤模型(SVD++)的更多相关文章
- 【RS】Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model - 当因式分解遇上邻域:多层面协同过滤模型
[论文标题]Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model (35th-ICM ...
- 四种主要网络IO虚拟化模型
本文主要为大家简要介绍VMware.Redhat.Citrix.Microsoft主要虚拟化厂商使用的4种主要的虚拟化IO模型 (emulation.para-virtualization.pass- ...
- 从信用卡欺诈模型看不平衡数据分类(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制。过采样后模型选择RF、xgboost、神经网络能够取得非常不错的效果。(2)模型层面:使用模型集成,样本不做处理,将各个模型进行特征选择、参数调优后进行集成,通常也能够取得不错的结果。(3)其他方法:偶尔可以使用异常检测技术,IF为主
总结:不平衡数据的分类,(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制.过采样后模型选择RF.xgboost.神经网络能够取得非常不错的效果.(2)模型层面:使用模型 ...
- 【CI】CN.一种多尺度协同变异的微粒群优化算法
[论文标题]一种多尺度协同变异的微粒群优化算法 (2010) [论文作者]陶新民,刘福荣, 刘 玉 , 童智靖 [论文链接]Paper(14-pages // Single column) [摘要] ...
- (数据挖掘-入门-3)基于用户的协同过滤之k近邻
主要内容: 1.k近邻 2.python实现 1.什么是k近邻(KNN) 在入门-1中,简单地实现了基于用户协同过滤的最近邻算法,所谓最近邻,就是找到距离最近或最相似的用户,将他的物品推荐出来. 而这 ...
- 【机器学习算法-python实现】协同过滤(cf)的三种方法实现
(转载请注明出处:http://blog.csdn.net/buptgshengod) 1.背景 协同过滤(collaborative filtering)是推荐系统经常使用的一种方法.c ...
- 微软引入了两种新的网络过滤系统,WFP和NDISfilter
Windows 8是微软公司推出的最新的客户端OS,内部名称Windows NT 80.相对于Windows NT 5.x,其网络结构变化非常大,原有的TDI,NDIS系统挂接方法不再适用.在Wind ...
- 【事件中心 Azure Event Hub】使用Logstash消费EventHub中的event时遇见的几种异常(TimeoutException, ReceiverDisconnectedException)
问题描述 使用EFK(Elasticsearch, Fluentd and Kibana)在收集日志的解决方案中, 可以先把日志发送到EventHub中,然后通过Logstash消费EventHub中 ...
- RBAC 几种常见的控制权限模型
1. 几种常见的权限模型 2. ACL 和 RBAC 对比 3. RBAC 权限模型的优势 (1)简化了用户和权限的关系 (2).易于扩展 易于维护 4.优势(给权限和收回权限) 5.架构
随机推荐
- 使用TextView/EditText应该注意的地方,监听EditText,addTextChangedListener
http://blog.csdn.net/huichengongzi/article/details/7818676 监听 EditText 控件: addTextChangedListener(ne ...
- linux 使用sqlite3
:c中使用sqlite3需要调用函数接口操作: sqlite3 *db; int status=sqlite_open("dbname",&db);//打开或者创建数据库 ...
- js点赞效果图
点赞时点赞图标会发生变化. html部分: <img src="img/icon_thumb_up.png" id="imgs1" style=" ...
- Flask—01-轻松入门Flask
Flask入门 WEB工作原理 C/S与B/S架构:客户端-服务器,浏览器-服务器 B/S架构工作原理 客户端(浏览器) <=> WEB服务器(nginx) <=> WSGI( ...
- MySQL——用户与密码
mysql安装完成之后,在/var/log/mysqld.log文件中给root生成了一个默认密码.通过下面的方式找到root默认密码,然后登录mysql进行修改: grep 'temporary p ...
- ATX 浅谈自动化测试工具 python-uiautomator2
1.简介 python-uiautomator2是一个自动化测试开源工具,仅支持Android平台的原生应用测试. 2.支持平台及语言 python-uiautomator2封装了谷歌自带的uiaut ...
- Java OOP——第二章 继承
1. 继承: ●继承是面向对象的三大特征之一,是JAVA实现代码重用的重要手段之一: ●继承是代码重用的一种方式,将子类共有的属性和行为放到父类中: ●JAVA只支持单继承,即每一个类只有一个父类,继 ...
- 百度地图API定位+显示位置
1. 先在需要嵌入地图的页面引入map.js <script src="http://api.map.baidu.com/api?v=2.0&ak=你的秘钥"> ...
- PHP (Yii2) 自定义业务异常类(可支持返回任意自己想要的类型数据)
public function beforeAction($action) { return parent::beforeAction($action); } public function runA ...
- 做 JAVA 开发,怎能不用 IDEA!
用了 IDEA,感觉不错.决定弃用 Eclipse 入门教程: www.cnblogs.com/yangyquin/p/5285272.html