LightGBM的算法介绍
LightGBM算法的特别之处
LightGBM算法在模型的训练速度和内存方面都有相应的优化。
基于树模型的boosting算法,很多算法比如(xgboost 的默认设置)都是用预排序(pre-sorting)算法进行特征的选择和分裂。
- 首先,对所有特征按数值进行预排序。
- 其次,在每次的样本分割时,用O(# data)的代价找到每个特征的最优分割点。
- 最后,找到最后的特征以及分割点,将数据分裂成左右两个子节点。
优缺点:
这种pre-sorting算法能够准确找到分裂点,但是在空间和时间上有很大的开销。
i. 由于需要对特征进行预排序并且需要保存排序后的索引值(为了后续快速的计算分裂点),因此内存需要训练数据的两倍。
ii. 在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
LightGBM采用Histogram算法,其思想是将连续的浮点特征离散成k个离散值,并构造宽度为k的Histogram。然后遍历训练数据,统计每个离散值在直方图中的累计统计量。在进行特征选择时,只需要根据直方图的离散值,遍历寻找最优的分割点。
Histogram 算法的优缺点:
- Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在实际的数据集上表明,离散化的分裂点对最终的精度影响并不大,甚至会好一些。原因在于decision tree本身就是一个弱学习器,采用Histogram算法会起到正则化的效果,有效地防止模型的过拟合。
- 时间上的开销由原来的O(#data * #features)降到O(k * #features)。由于离散化,#bin远小于#data,因此时间上有很大的提升。
- Histogram算法还可以进一步加速。一个叶子节点的Histogram可以直接由父节点的Histogram和兄弟节点的Histogram做差得到。一般情况下,构造Histogram需要遍历该叶子上的所有数据,通过该方法,只需要遍历Histogram的k个捅。速度提升了一倍。
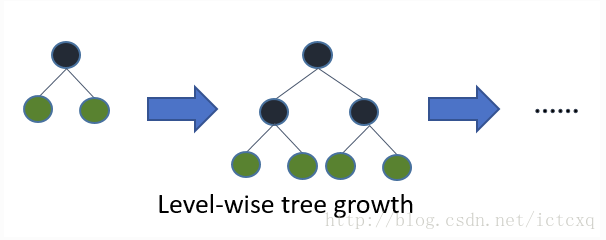
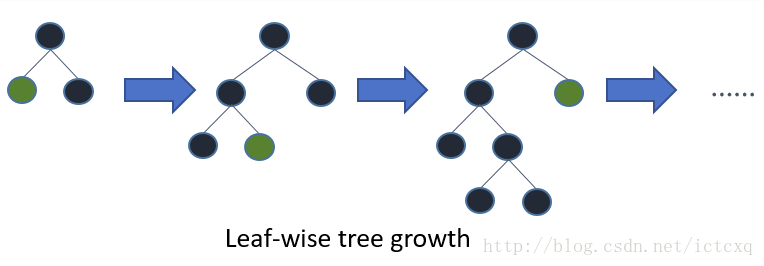
LightGBM的leaf-wise的生长策略
它摒弃了现在大部分GBDT使用的按层生长(level-wise)的决策树生长策略,使用带有深度限制的按叶子生长(leaf-wise)的策略。level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
LightGBM支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化one-hotting特征,降低了空间和时间的效率。而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。

以上是LightGBM算法的特别之处,除此之外LightGBM还具有高校并行的特点。下一篇文章将介绍LightGBM的特征并行(Feature Parallel)和数据并行(Data Parallel),以及相较于传统的并行方法的优点。
LightGBM的算法介绍的更多相关文章
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
- KNN算法介绍
KNN算法全名为k-Nearest Neighbor,就是K最近邻的意思. 算法描述 KNN是一种分类算法,其基本思想是采用测量不同特征值之间的距离方法进行分类. 算法过程如下: 1.准备样本数据集( ...
- ISP基本框架及算法介绍
什么是ISP,他的工作原理是怎样的? ISP是Image Signal Processor的缩写,全称是影像处理器.在相机成像的整个环节中,它负责接收感光元件(Sensor)的原始信号数据,可以理解为 ...
- Python之常见算法介绍
一.算法介绍 1. 算法是什么 算法是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制.也就是说,能够对一定规范的输入,在有限时间内获得所要求的输 ...
- RETE算法介绍
RETE算法介绍一. rete概述Rete算法是一种前向规则快速匹配算法,其匹配速度与规则数目无关.Rete是拉丁文,对应英文是net,也就是网络.Rete算法通过形成一个rete网络进行模式匹配,利 ...
- H2O中的随机森林算法介绍及其项目实战(python实现)
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator ...
- STL 算法介绍
STL 算法介绍 算法概述 算法部分主要由头文件<algorithm>,<numeric>和<functional>组成. <algorithm ...
- Levenshtein字符串距离算法介绍
Levenshtein字符串距离算法介绍 文/开发部 Dimmacro KMP完全匹配算法和 Levenshtein相似度匹配算法是模糊查找匹配字符串中最经典的算法,配合近期技术栏目关于算法的探讨,上 ...
- 机器学习概念之特征选择(Feature selection)之RFormula算法介绍
不多说,直接上干货! RFormula算法介绍: RFormula通过R模型公式来选择列.支持R操作中的部分操作,包括‘~’, ‘.’, ‘:’, ‘+’以及‘-‘,基本操作如下: 1. ~分隔目标和 ...
随机推荐
- 对象的比较与排序(三):实现IComparable<T>和IComparer<T>泛型接口
来源:http://www.cnblogs.com/eagle1986/archive/2011/12/06/2278531.html 1:比较和排序的概念 比较:两个实体类之间按>,=,< ...
- 使用transfor让图片旋转
材料:Transform,onmouseout,onmouseover css: html: js:
- Spring data JPA 理解(默认查询 自定义查询 分页查询)及no session 三种处理方法
简介:Spring Data JPA 其实就是JDK方式(还有一种cglib的方式需要Class)的动态代理 (需要一个接口 有一大堆接口最上边的是Repository接口来自org.springfr ...
- JavaScript 基础(六) 数组方法 闭包
在一个对象中绑定函数,称为这个对象的方法.在JavaScript 中,对象的定义是这样的: var guagua = { name:'瓜瓜', birth:1990 }; 但是,如果我们给瓜瓜绑定一个 ...
- 魔板 Magic Squares(广搜,状态转化)
题目背景 在成功地发明了魔方之后,鲁比克先生发明了它的二维版本,称作魔板.这是一张有8个大小相同的格子的魔板: 1 2 3 4 8 7 6 5 题目描述 我们知道魔板的每一个方格都有一种颜色.这8种颜 ...
- 【网络流】EK算法及其优化
今天上午我仿佛知道了什么叫做网络流,这里推荐一篇博客,大家入门网络流的可以看一下这篇博客,保证一看就懂! 博客链接: 网络流入门 这里有一篇经过我改过的EK带注释代码(博客里也有一样的,只是加了一些注 ...
- Ubuntu下安装Docker CE
官网配置步骤:https://docs.docker.com/install/linux/docker-ce/ubuntu/#install-docker-ce-1 安装Docker社区版仓库 Upd ...
- npm install 报错
今天准备在服务器上部署一下pm2,发现 npm install -g pm2 爆出了错误 error Unexpected end of JSON input while parsing near ...
- 构建ExtJS 6.x程序
构建ExtJS 6.x程序 ExtJS也有自己的打包工具 SenchaCmd,它用来生成构建ExtJS前端组织架构,最后打包发布生产,操控着前端整个开发生命周期,SenchaCmd依赖于JDK,所以要 ...
- 分享一个PC端六格密码输入框写法
如图.我们一般做商城类的项目不免会用到支付密码输入框,我研究了下并决定发上来,也当作是自己成长路上的一点小小的记录.本次介绍的是基于vue的项目 html: <template> < ...