Apache Hive 简介及安装
简介
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能。
本质是将 SQL 转换为 MapReduce 程序。
主要用途:用来做离线数据分析,比直接用 MapReduce 开发效率更高。Hive 利用 HDFS 存储数据,利用 MapReduce 查询分析数据。
数据库和数据仓库的区别在于:
- 数据库是面向事务的设计,数据仓库是面向主题设计的。
- 数据库一般存储业务数据,数据仓库存储的一般是历史数据。
- 数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的 User 表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
- 数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
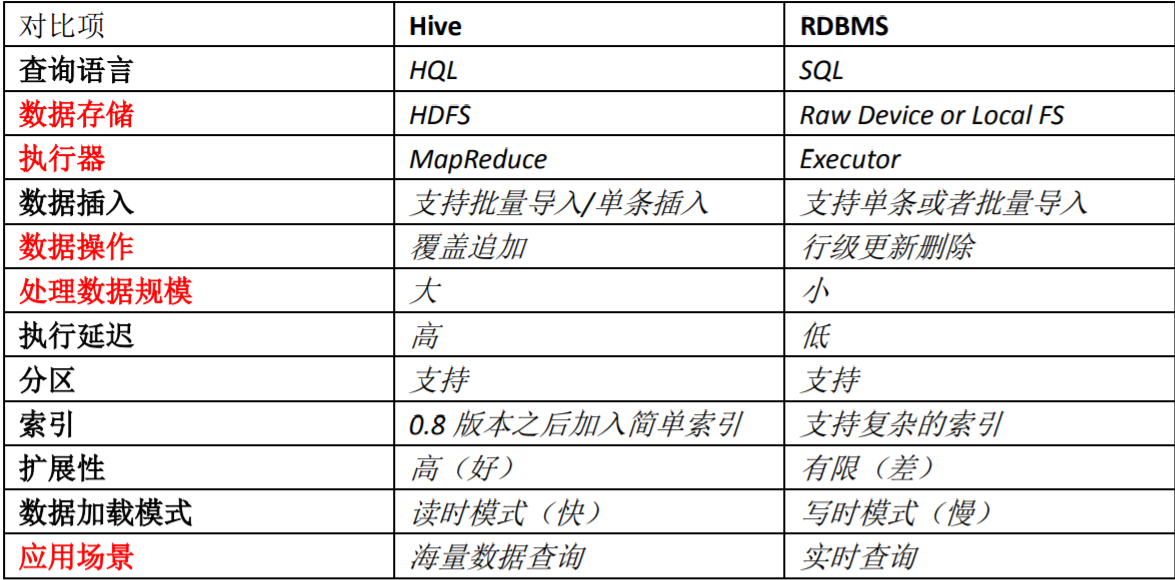
Hive优缺点
优点:
- 可扩展性,横向扩展,Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务 横向扩展:通过分担压力的方式扩展集群的规模 纵向扩展:一台服务器cpu i7-6700k 4核心8线程,8核心16线程,内存64G => 128G
- 延展性,Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数
- 良好的容错性,可以保障即使有节点出现问题,SQL 语句仍可完成执行
缺点:
- Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结 果导入到文件中(当前选择的 hive-2.3.2 的版本支持记录级别的插入操作)
- Hive 的查询延时很严重,因为 MapReduce Job 的启动过程消耗很长时间,所以不能 用在交互查询系统中。
- Hive 不支持事务(因为不没有增删改,所以主要用来做 OLAP(联机分析处理),而 不是 OLTP(联机事务处理),这就是数据处理的两大级别)。
Hive架构
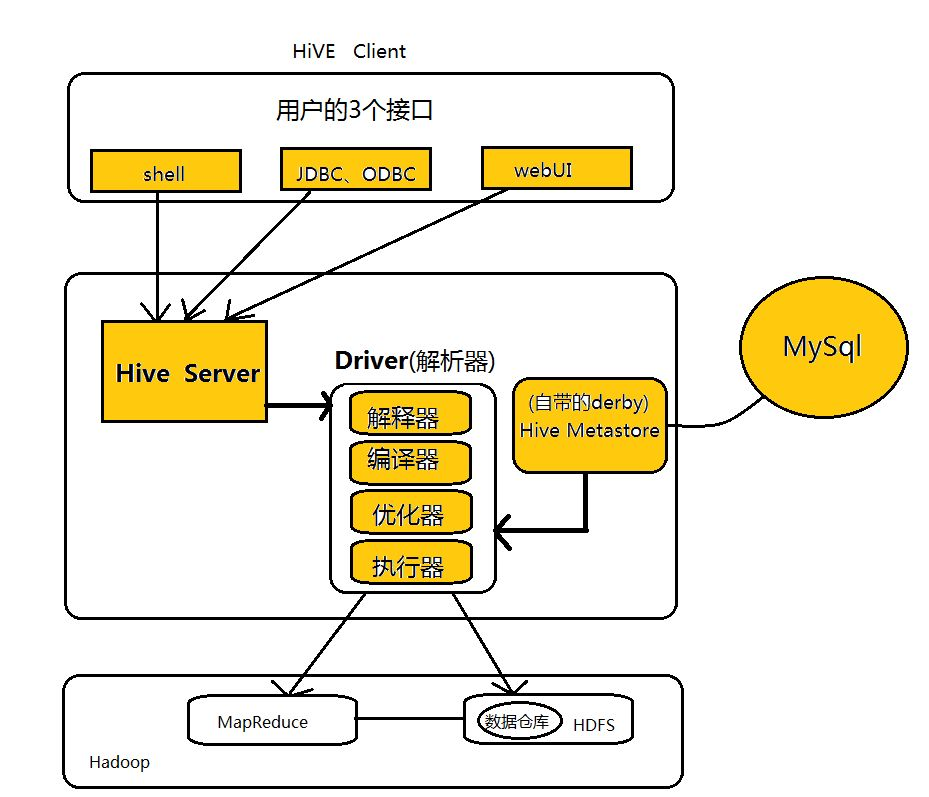
hive client我们一般用shell,hive metastore 我们一般配置成mysql。
Hive数据模型
Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式
在创建表时指定数据中的分隔符,Hive 就可以映射成功,解析数据。
Hive 中包含以下数据模型:
- db :在 hdfs 中表现为 hive.metastore.warehouse.dir 目录下一个文件夹
- table :在 hdfs 中表现所属 db 目录下一个文件夹
- external table :数据存放位置可以在 HDFS 任意指定路径
- partition :在 hdfs 中表现为 table 目录下的子目录
- bucket :在 hdfs 中表现为同一个表目录下根据 hash 散列之后的多个文件
- view:与传统数据库类似,只读,基于基本表创建
Hive安装部署
1,Hive 安装前需要安装好 JDK 和 Hadoop。配置好环境变量。
2,上传安装文件 apache-hive-x.x.x-bin.tar.gz,并解压。
3,配置HIVE_HOME环境变量
vi /export/servers/hive/conf/hive-env.sh 配置其中的HADOOP_HOME
export HADOOP_HOME=/export/servers/hadoop-2.7.4
4,配置元数据库信息,在conf文件夹内新添加hive-site.xml文件(分别配置mysql的位置,mysql的Driver,mysql的账号和密码)
vi hive-site.xml <configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.44.31:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>
5,把mysql-connector-java-5.1.32.jar上传到 Hive的lib文件夹中
6,启动hive,我们一般把Hive当做服务启动
启动Hive
bin/hiveserver2 启动成功后,可以在别的节点上用beeline去连接
[root@bigdata-02 bin]# ./beeline
Beeline version 1.2.1 by Apache Hive
beeline> ! connect jdbc:hive2://bigdata-01:10000
Connecting to jdbc:hive2://bigdata-01:10000
Enter username for jdbc:hive2://bigdata-01:10000: root
Enter password for jdbc:hive2://bigdata-01:10000: ******
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Apache Hive 简介及安装的更多相关文章
- 【转】 hive简介,安装 配置常见问题和例子
原文来自: http://blog.csdn.net/zhumin726/article/details/8027802 1 HIVE概述 Hive是基于Hadoop的一个数据仓库工具,可以将结构化 ...
- Apache Kafka简介与安装(二)
Kafka在Windows环境上安装与运行 简介 Apache kafka 是一个分布式的基于push-subscribe的消息系统,它具备快速.可扩展.可持久化的特点.它现在是Apache旗下的一个 ...
- HIVE简介及安装
一.简介 百度百科HIVE定义: hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运 ...
- Apache Kafka简介与安装(一)
介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计. 首先让我们看几个基本的消息系统术语: Kafka将消息以topic为单位进行归纳. 将向 ...
- Apache Flume简介及安装部署
概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件. Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目 ...
- Apache Hive处理数据示例
继上一篇文章介绍如何使用Pig处理HDFS上的数据,本文将介绍使用Apache Hive进行数据查询和处理. Apache Hive简介 首先Hive是一款数据仓库软件 使用HiveQL来结构化和查询 ...
- Apache Hive 安装文档
简介: Apache hive 是基于 Hadoop 的一个开源的数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供简单的sql查询功能,将 SQL 语句转换为 MapReduce 任务 ...
- 数据仓库Hive(一)——hive简介,产生,安装
1.Hive简介 数据仓库 解释器.编译器.优化器等 运行时,元数据存储在关系型数据库里面 1.1数据库和数据仓库的区别 数据库需要立即返回结果,数据仓库不需要 数据仓库能收纳各种数据源,而数据库只能 ...
- Netty学习——Apache Thrift 简介和下载安装
Netty学习——Apache Thrift 简介和下载安装 Apache Thrift 简介 本来由Facebook开发,捐献给了Apache,成了Apache的一个重要项目 可伸缩的,跨语言的服务 ...
随机推荐
- Precision/Recall、ROC/AUC、AP/MAP等概念区分
1. Precision和Recall Precision,准确率/查准率.Recall,召回率/查全率.这两个指标分别以两个角度衡量分类系统的准确率. 例如,有一个池塘,里面共有1000条鱼,含10 ...
- VS 2010 转到COFF期间失败。
可能的原因是framework 版本不匹配,我卸载4.5,装4.0后就解决了
- oracle重建undo表空间
create undo tablespace UNDOTBS2 datafile 'D:\oracle\product\10.2.0\oradata\ttonline\UNDOTBS02.DBF' s ...
- 【英语】TED视频笔记
2014-09-22 讲话的七宗罪呢:流言蜚语.评判.消极.抱怨.借口.浮夸.固执己见. 讲话的四个要素:HAIL - 诚实,做自己,说到做到,爱. 2014-09-23 Do more of the ...
- Python基本特殊方法之__format__
__format__()方法 __format__()传参方法:someobject.__format__(specification) specification为指定格式,当应用程序中出现&quo ...
- 使用Audition录制自己的歌曲
Audition专为在照相室.广播设备和后期制作设备方面工作的音频和视频专业人员设计,可提供先进的音频混合.编辑.控制和效果处理功能.最多混合 128 个声道,可编辑单个音频文件,创建回路并可使用 4 ...
- MATLAB的一些应用--最近用的比较多
MATLAB的一些应用--最近用的比较多 1.MATLAB分析信号的频谱 快速Fourier变换(FFT)是离散傅里叶变换的快速算法,他是根据离散傅里叶变换的奇.偶.虚.实等特性,对离散傅里叶变换的算 ...
- DbEntry 简单实现
在着手编码之前首先安装DbEntry DbEntry.Net.4.1.Setup.zip 在建立类库时选择 DbEntryClassLibrary 如图 DbEntryClassLibrary1 中建 ...
- Python 函数 set()
set() 功能: set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集.差集.并集等. iterable -- 可迭代对象对象:返回新的集合对象. 语法 ...
- 笔记:LIR2032 电池充电记录
笔记:LIR2032 电池充电记录 LIR2032 电池是锂电池,形状和 CR2032 一样,只不过可以充电,材料是锂离子. 一个单颗的 LIR2032 电池容量只有 40mAH,容量很小. 那么就需 ...