SQL Server-聚焦IN VS EXISTS VS JOIN性能分析(十九)
前言
本节我们开始讲讲这一系列性能比较的终极篇IN VS EXISTS VS JOIN的性能分析,前面系列有人一直在说场景不够,这里我们结合查询索引列、非索引列、查询小表、查询大表来综合分析,简短的内容,深入的理解,Always to review the basics。
IN VS EXISTS VS JOIN性能分析
我们继续创建测试表,如下
CREATE SCHEMA [compare]
CREATE TABLE t_outer (
id INT NOT NULL PRIMARY KEY,
val1 INT NOT NULL,
val2 INT NOT NULL
)
CREATE TABLE t_inner (
id INT NOT NULL PRIMARY KEY,
val1 INT NOT NULL,
val2 INT NOT NULL
)
CREATE TABLE t_smallinner (
id INT NOT NULL PRIMARY KEY,
val1 INT NOT NULL,
val2 INT NOT NULL
)
GO
CREATE INDEX ix_outer_val1 ON [compare].t_outer (val1)
CREATE INDEX ix_inner_val1 ON [compare].t_inner (val1)
CREATE INDEX ix_smallinner_val1 ON [compare].t_smallinner (val1)
创建三个表即t_outer、t_inner、t_smaler同时将三个表中的列val1创建索引而对t_smaller表中的val2未创建索引,下面我们开始插入测试数据
USE TSQL2012
GO DECLARE @num INT
SET @num =
WHILE @num <=
BEGIN
INSERT
INTO [compare].t_inner
VALUES (@num, RAND() * , RAND() * )
INSERT
INTO [compare].t_outer
VALUES (@num, RAND() * , RAND() * )
SET @num = @num +
END
GO
对t_inner和t_outer分别插入10万条随机数据,然后去取t_outer表中最后100条数据插入到表t_smaller中
USE TSQL2012
GO INSERT
INTO [compare].t_smallinner
SELECT TOP
ROW_NUMBER() OVER (ORDER BY id DESC),
val1,
val2
FROM [compare].t_outer
ORDER BY
id DESC
GO
表以及测试数据创建完毕,下面我们开始一个一个分析。
(1)IN性能分析(在大表上查询索引列val1)
SELECT val1
FROM [compare].t_outer o
WHERE val1 IN
(
SELECT val1
FROM [compare].t_inner
)
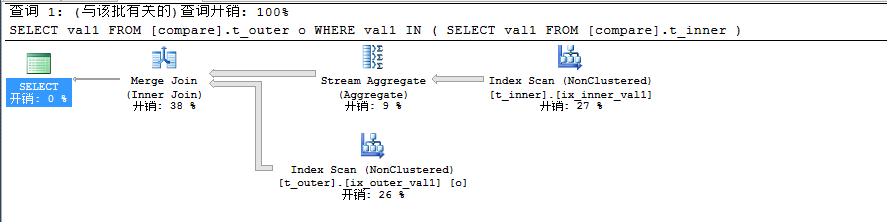
我们将上述查询计划示意图过程简短描述成如下:

整个查询耗费时间如下:

此时整个查询时间耗费70毫秒,对于10万条数据来说算是非常快的了,因为此时我们在t_inner表和t_outer表上的列val1都建立了索引,所以此时选择Stream Aggregate来进行过滤去除对于t_outer表上的val1中对应的t_inner表上的val1的重复值。到底是怎么去除重复的呢?它会记录重复的最后一个值,当再有值被找到,此时将无法通过。上述之所以查询非常快的原因在于输入行已经提前进行了预排序。最后得到的两个表的结果集进行Merge Join,进行Merge Join时,它会初始化一个变量并将指针指向加入的两个列的最小值,然后返回两个表结果集中匹配到的值,然后将指针指向下一个两个索引列中的存在的值,否则跳过不匹配的值,一直到完成,当进行如下查询时和上述查询计划是一致的。
SELECT o.val1
FROM [compare].t_outer o
JOIN (
SELECT DISTINCT val1
FROM [compare].t_inner
) i
ON i.val1 = o.val1
(1)EXISTS性能分析(在大表上查询索引列val1)
我们通过如下查询来分析EXISTS
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT val1
FROM [compare].t_outer o
WHERE EXISTS (
SELECT
FROM [compare].t_inner s
WHERE s.val1 = o.val1
)


上述我们能够很清楚的知道EXISTS查询计划和IN是一致的,信不信由你,当下次面试再问二者性能的问题时,可千万别说EXISTS性能高于IN,这是错误的,上述我们已经分析得出其实是一样的。如果你仍是觉得EXISTS性能高于IN,请用事实证明。上述我们一直演示的是查询索引列val1,那要是在非索引列val2上查询会怎样呢。
(2)IN性能分析(在大表上查询非索引列val2)
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT val2
FROM [compare].t_outer
WHERE val2 IN
(
SELECT val2
FROM [compare].t_inner
)
我们再来分析下查询计划
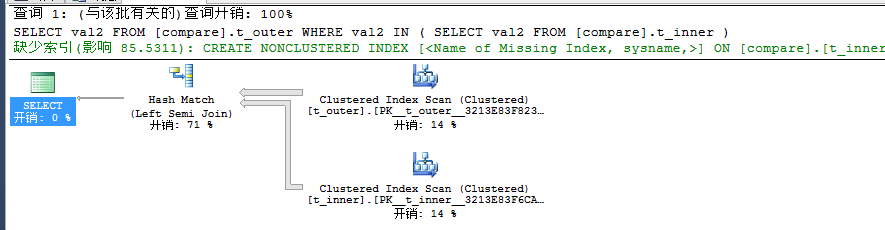

我们重点看看Hash Match(Left Semi Join),此时对t_outer表上的值建立哈希表,然后t_inner表中每一行值来探测该哈希表,接着通过Left Semi Join来匹配值,如果匹配到值,此时匹配到的值会立即从哈希表中移除,最终哈希表将逐渐缩小。接着我们再来看EXISTS。
(2)EXISTS性能分析(在大表上查询非索引列val2)
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT val2
FROM [compare].t_outer o
WHERE EXISTS (
SELECT
FROM [compare].t_inner s
WHERE s.val2 = o.val2
)


此时我们看到无论是查询索引列还是非索引列EXISTS和IN在查询计划和耗费时间几乎完全是一致的,到这里我们针对讨论的是大表10万条数据,下面我们会讨论在小表t_smaller中有关二者的查询。接下来我们看看利用JOIN在索引列上进行查询。
(2)JOIN性能分析(在大表上查询非索引列val2)
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT o.val2
FROM [compare].t_outer o
JOIN (
SELECT DISTINCT val2
FROM [compare].t_inner
) i
ON i.val2 = o.val2
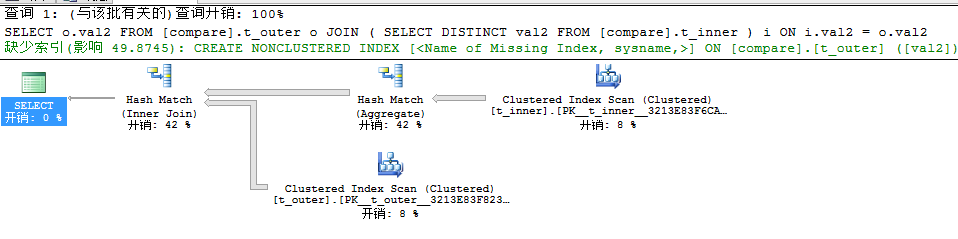

我们看到查询耗费时间和查询计划都和EXISTS、IN有不同,我们再来看看执行的顺序。

与上述不同的是JOIN在两个表联合之前首先进行了Hash Match(Aggregate),也就是说和EXISTS、IN不同之处在于重复值的处理,对于EXISTS、IN来说直接将两个表进行联合然后通过LEFT Semi Join来进行过滤重复值,在此通过哈希匹配中的聚合来过滤去除重复值val2,Hash Match(Aggregare)建立了一个唯一的哈希表,所以很容易来过滤重复值,因为有重复值过来时唯一哈希表能够探测到会产生值冲突,此时重复值都不会进入哈希表中。查询引擎通过哈希表来探测t_outer中的值,最终返回匹配的值。普遍想法是JOIN性能比EXISTS、IN性能要好,上述我们在查询非索引列时其查询开销和耗费时间却比EXISTS、IN要高,所以相对来说JOIN对于查询非索引列时其性能是比较低效的。接下来我们继续来看看查询小表t_smaller的情况。
(3)IN性能分析(在小表上查询索引列val1)
我们查询小表看看关于IN的查询情况是怎样的呢
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT val1
FROM [compare].t_outer o
WHERE val1 IN
(
SELECT val1
FROM [compare].t_smallinner
)


因为数据只有100条的小表其查询耗费时间当然非常少且查询速度非常快,我们重点看看其查询计划。此时合并结果集时不再是Merge Join代替的是遍历整个索引,它会扫描整个t_smaller表来过滤重复值,当然仅仅只是查找在t_outer表上创建的索引列val1且是通过索引查找的方式。数据量小所以即使是遍历整个索引也是非常快的。在EXISTS和JOIN中其执行计划结果和上述一致,下面我们再来看看查询非索引列的情况。
(4)IN性能分析(在小表上查询非索引列val2)
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT val2
FROM [compare].t_outer o
WHERE val2 IN
(
SELECT val2
FROM [compare].t_smallinner
)
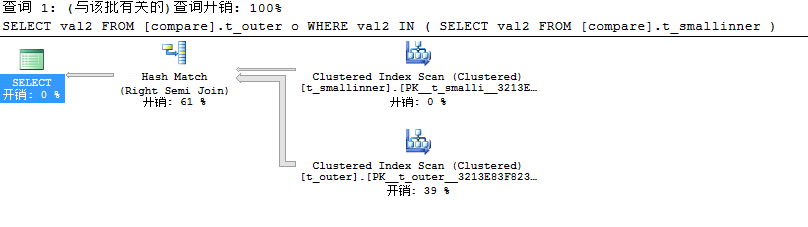

此时我们看到查询小表上非索引列val2和大表上的非索引列val2执行计划几乎是一样的,有一点不同的是在大表中建立哈希表是在外部查询表中,在这里却是在子查询表中建立哈希表,这就是查询引擎高明的地方,数据少时在小表上建立哈希表一来在哈希表中存储的数据少即占用内存少,二来当匹配到值时就缩减哈希表的大小。我们再来看看JOIN的情况。
(4)JOIN性能分析(在小表上查询非索引列val2)
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT o.val2
FROM [compare].t_outer o
JOIN (
SELECT DISTINCT val2
FROM [compare].t_smallinner
) i
ON i.val2 = o.val2
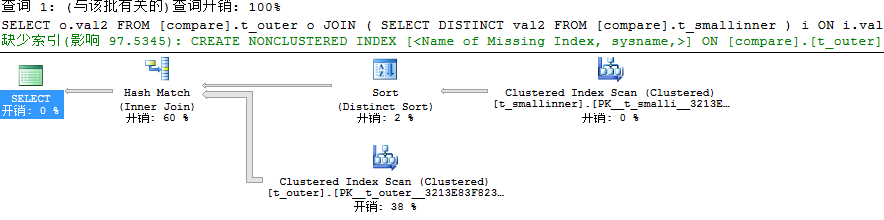

因为数据量小所以耗费时间短,这个我们可以忽略不看,我们还是看看查询计划情况,此时利用Distinct Sort来消除重复的数据而不是利用哈希表,它会一次次的重建,可想而知性能的低下。分析到这里为止,我们看到在SQL Server中其实在有些情况下IN、EXISTS的查询性能是高于JOIN的。还不相信吗,我们再来看一个例子。
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT val2
FROM [compare].t_outer o
WHERE EXISTS (
SELECT
FROM [compare].t_smallinner s
WHERE s.val2 - o.val2 =
)
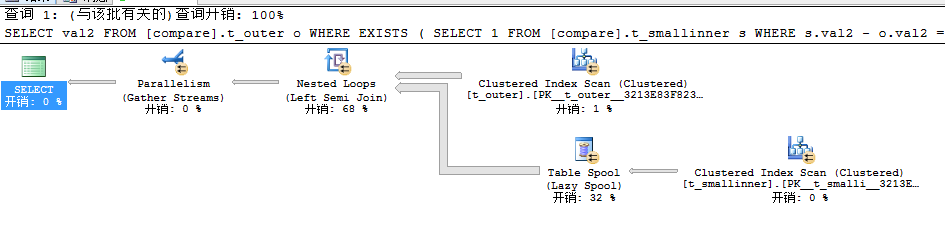

因为查询条件压根就无法匹配导致哈希表都不会有,结果查询引擎会使用Nested Loops(Left Semi Join)来进行全表扫描,此时耗费时间接近需要2秒。好了,到这里为止我们关于IN VS EXISTS VS JOIN的分析就已经完全结束,参考资料:【https://explainextended.com/2009/06/16/in-vs-join-vs-exists/】下面我们和前面一样来对这三者下一个结论:
IN VS EXISTS VS JOIN性能分析结论:在查询非索引列时,利用JOIN查询性能低下,因为利用EXISTS和IN会直接利用半联接来匹配哈希表,而JOIN需要先进行哈希聚合之后再进行完全JOIN,换句话说,EXISTS和IN只需一步操作就完成,而JOIN需要两步操作来完成,当然对于有索引的前提下,数据量巨大的话,利用JOIN其性能同样也是非常高效的。而IN和EXISTS的性能是一样的,至于为何推荐用EXISTS的原因在于基于EXISTS是三值逻辑,而IN是两值逻辑,利用EXISTS来查询比IN更加灵活,安全、保险,而且大多数情况下利用IN来查询都可以利用EXISTS来代替查询。
总结
本节我们讨论了IN VS EXISTS VS JOIN的性能比较,至此关于所有IN/NOT IN VS EXISTS/NOT EXISTS VS JOIN/LEFT JOIN..IS NULL的性能分析到此告一段落,接下来我们将会讲述Stream Aggregate VS Hash Match Aggregate,敬请期待,简短的内容,深入的理解,我们下节再会。
SQL Server-聚焦IN VS EXISTS VS JOIN性能分析(十九)的更多相关文章
- SQL Server事务、隔离级别详解(二十九)
前言 事务一直以来是我最薄弱的环节,也是我打算重新学习SQL Server的出发点,关于SQL Server中事务将分为几节来进行阐述,Always to review the basics. 事务简 ...
- SQL Server-聚焦EXISTS AND IN性能分析(十六)
前言 前面我们学习了NOT EXISTS和NOT IN的比较,当然少不了EXISTS和IN的比较,所以本节我们来学习EXISTS和IN的比较,简短的内容,深入的理解,Always to review ...
- sql server 子查询 和exists使用
概述 子查询的概念: 当一个查询是另一个查询的条件时,称之为子查询.子查询可以嵌套在主查询中所有位置,包括SELECT.FROM.WHERE.GROUP BY.HAVING.ORDER BY. 外面的 ...
- SQL Server中修改“用户自定义表类型”问题的分析与方法
前言 SQL Server开发过程中,为了传入数据集类型的变量(比如接受C#中的DataTable类型变量),需要定义"用户自定义表类型",通过"用户自定义表类型&quo ...
- SQL SERVER 2012 执行计划走嵌套循环导致性能问题的案例
开发人员遇到一个及其诡异的的SQL性能问题,这段完整SQL语句如下所示: declare @UserId INT declare @PSANo VAR ...
- [翻译]——SQL Server使用链接服务器的5个性能杀手
前言: 本文是对博客http://www.dbnewsfeed.com/2012/09/08/5-performance-killers-when-working-with-linked-server ...
- 智能SQL优化工具--SQL Optimizer for SQL Server(帮助提升数据库应用程序性能,最大程度地自动优化你的SQL语句 )
SQL Optimizer for SQL Server 帮助提升数据库应用程序性能,最大程度地自动优化你的SQL语句 SQL Optimizer for SQL Server 让 SQL Serve ...
- SQL Server ->> 尝试优化ETL中优化Merge性能
这几天突发想到在ETL中Merge性能的问题.思路的出发点是Merge到目标表需要扫描的数据太多,而现实情况下,假设应该是只有一小部分会被更新,而且这部分数据也应该是比较新的数据,比方说对于想Fact ...
- (转)SQL Server上的一个奇怪的Deadlock及其分析方法
原文地址:http://blogs.msdn.com/b/apgcdsd/archive/2012/02/28/sql-server-deadlock.aspx 最近遇到了一个看上去很奇怪,分析起来很 ...
随机推荐
- 轻量级“集合”迭代器-Generator
Generator是PHP 5.5加入的新语言特性.但是,它似乎并没有被很多PHP开发者广泛采用.因此,在我们了解PHP 7对Generator的改进之前,我们先通过一个简单却显而易见的例子来了解下G ...
- $.type 怎么精确判断对象类型的 --(源码学习2)
目标: var a = [1,2,3]; console.log(typeof a); //->object console.log($.type(a)); //->ar ...
- 读python源码--对象模型
学python的人都知道,python中一切皆是对象,如class生成的对象是对象,class本身也是对象,int是对象,str是对象,dict是对象....所以,我很好奇,python是怎样实现这些 ...
- ASP.NET Core 中文文档 第五章 测试(5.2)集成测试
原文: Integration Testing 作者: Steve Smith 翻译: 王健 校对: 孟帅洋(书缘) 集成测试确保应用程序的组件组装在一起时正常工作. ASP.NET Core支持使用 ...
- JS鼠标事件大全 推荐收藏
一般事件 事件 浏览器支持 描述 onClick HTML: 2 | 3 | 3.2 | 4 Browser: IE3 | N2 | O3 鼠标点击事件,多用在某个对象控制的范围内的鼠标点击 onDb ...
- 【干货分享】流程DEMO-费用报销
流程名: 费用报销 业务描述: 流程发起时,要选择需要关联的事务审批单,会检查是否超申请,如果不超申请,可以直接发起流程,如果超了申请,需要检查预算,如果预算不够,将不允许发起报销申请,如果预算够用, ...
- Android Retrofit 2.0 使用-补充篇
推荐阅读,猛戳: 1.Android MVP 实例 2.Android Retrofit 2.0使用 3.RxJava 4.RxBus 5.Android MVP+Retrofit+RxJava实践小 ...
- iOS 自定义方法 - 不完整边框
示例代码 ///////////////////////////OC.h////////////////////////// //// UIView+FreeBorder.h// BHBFreeB ...
- Performance Tuning
本文译自Wikipedia的Performance tuning词条,原词条中的不少链接和扩展内容非常值得一读,翻译过程中暴露了个人工程学思想和英语水平的不足,翻译后的内容也失去很多准确性和丰富性,需 ...
- 开始webservice了
一.WebService到底是什么 一言以蔽之:WebService是一种跨编程语言和跨操作系统平台的远程调用技术. 所谓跨编程语言和跨操作平台,就是说服务端程序采用java编写,客户端程序则可以采用 ...