javascript数据结构与算法--散列
一:javascript数据结构与算法--散列
一:什么是哈希表?
哈希表也叫散列表,是根据关键码值(key,value)而直接进行访问的数据结构,它是通过键码值映射到表中一个位置来访问记录的,散列表后的数据可以快速的插入和使用,散列使用的数据结构叫做散列表。
散列表的优点及缺点:
优点:在散列表上插入,删除和取用数据都非常快。
缺点:对于查找来说效率低下,比如查找一组数据中的最大值与最小值时候,这个时候我们可以使用二叉树查找了。
散列表实现的具体原理?
- 散列函数的选择依赖于键值的数据类型,如果键是整型,那么散列函数就是以数组的长度对键取余。取余结果就当作数组的下标,将值存储在以该数字为下标的数组空间里。
- 如果键值是字符串类型,那么就将字符串中的每个字符的ASCLL码值相加起来,再对数组的长度取余。取余的结果当作数组的下标,将值存储在以该余数为下标的数组空间里面。
一般情况下,散列函数会将每个键值映射为一个唯一的数组索引。然而,键的数量是无限的,数组的长度是有限的(在javascript上是这样的),那么我们的目标是想让散列函数尽量均匀地映射到数组中。使用散列函数时候,仍然会存在两个键(key)会映射到同一个值的可能。这种现象我们称为 ”碰撞”,为了避免 ”碰撞”,首先要确保散列表中用来存储数据的数组大小是个质数,因为这和计算散列值时使用的取余运算有关,并且希望数组的长度在100以上的质数,这是为了让数据在散列表中能均匀的分布,所以我们下面的数组长度先定义为137.
散列表的取数据方法:
当存储记录时,通过散列函数计算出记录的散列地址,当取记录时候,我们通过同样的散列函数计算记录的散列地址,并按此散列地址访问该记录。
散列基本含义如下图:
| 名字 | 散列函数(名字中每个字母的ASCLL码之和) | 散列值 | 散列表 | ||||||||||||||
| Durr | 68+117+114+114 | 413 |
|
||||||||||||||
| Smith | 81+109+105+116+104 | 517 | |||||||||||||||
| Jones | 74+111+110+101+115 | 511 |
比如我们现在如果想要取Durr值得话,那么我们就可以取散列表中的第413记录 即可得到值。
二:代码如何实现HashTable类;
1.先实现HashTable类,定义一个属性,散列表的长度,如上所说,定义数组的长度为137.代码如下:
- function HashTable() {
- this.table = new Array(137);
- }
2.实现散列函数;
就将字符串中的每个字符的ASCLL码值相加起来,再对数组的长度取余。取余的结果当作数组的下标,将值存储在以该余数为下标的数组空间里面。代码如下:
- function simpleHash (data) {
- var total = 0;
- for(var i = 0; i < data.length; i++) {
- total += data.charCodeAt(i);
- }
- console.log("Hash Value: " +data+ " -> " +total);
- return total % this.table.length;
- }
3. 将数据存入散列表。
- function put(data){
- var pos = this.simpleHash(data);
- this.table[pos] = data;
- }
4. 显示散列表中的数据
- function showDistro (){
- var n = 0;
- for(var i = 0; i < this.table.length; i++) {
- if(this.table[i] != undefined) {
- console.log(i + ":" +this.table[i]);
- }
- }
- }
下面是所有的JS代码如下:
- function HashTable() {
- this.table = new Array(137);
- }
- HashTable.prototype = {
- simpleHash: function(data) {
- var total = 0;
- for(var i = 0; i < data.length; i++) {
- total += data.charCodeAt(i);
- }
- console.log("Hash Value: " +data+ " -> " +total);
- return total % this.table.length;
- },
- put: function(data){
- var pos = this.simpleHash(data);
- this.table[pos] = data;
- },
- showDistro: function(){
- var n = 0;
- for(var i = 0; i < this.table.length; i++) {
- if(this.table[i] != undefined) {
- console.log(i + ":" +this.table[i]);
- }
- }
- }
- };
我们先来做demo来测试下,如上面的代码;如下:
- var someNames = ["David","Jennifer","Donnie","Raymond","Cynthia","Mike","Clayton","Danny","Jonathan"];
- var hTable = new HashTable();
- for(var i = 0; i < someNames.length; ++i) {
- hTable.put(someNames[i]);
- }
- hTable.showDistro();
打印如下:

simpleHash方法里面

打印如下:
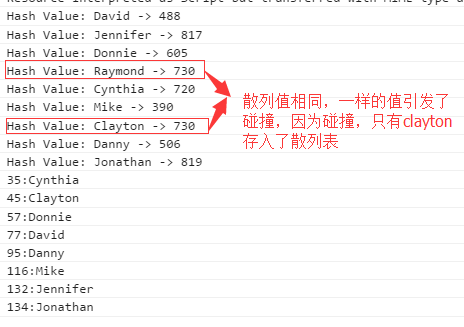
上面可以看出,不同的键名(key),但是他们的值相同,由此发生了碰撞,所以最后一个值会存入散列表中。
二:一个更好的散列函数;
为了避免碰撞,我们要有一个计算散列值的更好方法。霍纳算法很好地解决了这个问题,新的散列函数仍然先计算字符串中各字符的ASCLL码值,不过求和时每次要乘以一个质数。我们这里建议是31.代码如下:
- function betterHash(string) {
- var H = 31;
- var total = 0;
- for(var i = 0; i < string.length; ++i) {
- total += H * total + string.charCodeAt(i);
- }
- total = total % this.table.length;
- console.log("Hash Value: " +string+ " -> " +total);
- if(total < 0) {
- total += this.table.length - 1;
- }
- return parseInt(total);
- }
但是我们的put的方法要改成如下了:
- function put(data) {
- var pos = this.betterHash(data);
- this.table[pos] = data;
- }
下面是所有的JS代码如下:
- function HashTable() {
- this.table = new Array(137);
- }
- HashTable.prototype = {
- simpleHash: function(data) {
- var total = 0;
- for(var i = 0; i < data.length; i++) {
- total += data.charCodeAt(i);
- }
- console.log("Hash Value: " +data+ " -> " +total);
- return total % this.table.length;
- },
- put: function(data){
- //var pos = this.simpleHash(data);
- var pos = this.betterHash(data);
- this.table[pos] = data;
- },
- showDistro: function(){
- var n = 0;
- for(var i = 0; i < this.table.length; i++) {
- if(this.table[i] != undefined) {
- console.log(i + ":" +this.table[i]);
- }
- }
- },
- betterHash: function(string){
- var H = 31;
- var total = 0;
- for(var i = 0; i < string.length; ++i) {
- total += H * total + string.charCodeAt(i);
- }
- total = total % this.table.length;
- console.log("Hash Value: " +string+ " -> " +total);
- if(total < 0) {
- total += this.table.length - 1;
- }
- return parseInt(total);
- }
- };
测试代码还是上面的如下:
- var someNames = ["David","Jennifer","Donnie","Raymond","Cynthia","Mike","Clayton","Danny","Jonathan"];
- var hTable = new HashTable();
- for(var i = 0; i < someNames.length; ++i) {
- hTable.put(someNames[i]);
- }
- hTable.showDistro();
如下图运行所示:
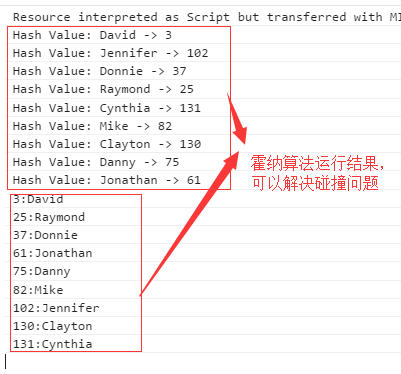
三:散列化整型键;
上面我们展示了如何散列字符串类型的键,现在我们来看看如何散列化整型键,使用的数据是学生的成绩。我们将随机产生一个9位数的键,用以识别学生身份和一门成绩。
代码如下:
- function getRandomInt(min,max) {
- return Math.floor(Math.random() * (max - min +1)) + min;
- }
- function genStuData(arr) {
- for(var i = 0; i < arr.length; ++i) {
- var num = "";
- for(var j = 1; j <= 9; ++j) {
- num += Math.floor(Math.random() * 10);
- }
- console.log(num);
- num += getRandomInt(50,100);
- console.log(num);
- arr[i] = num;
- }
- }
使用getRandomInt()函数时,可以指定随机数的最大值与最小值。拿学生的成绩来看,最低分是50,最高分是100;
genStuData()函数生成学生的数据。里面的循环是用来生成学生的ID,紧跟在循环后面的代码生存一个随机成绩,并把成绩连在ID的后面。如下:
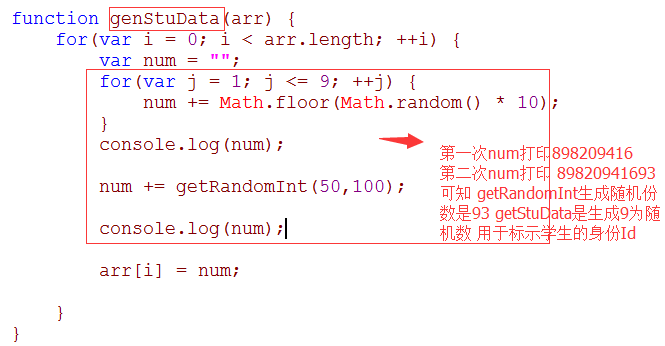

主程序会把ID和成绩分离。如下所示:
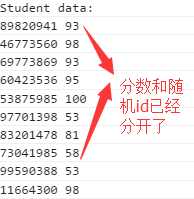
下面就是上面的测试代码如下:
- var numStudents = 10;
- var students = new Array(numStudents);
- genStuData(students);
- console.log("Student data: \n");
- for(var i = 0; i < students.length; i++) {
- console.log(students[i].substring(0,8) + " " +students[i].substring(9));
- }
- console.log("\n\nData distribution:\n");
- var hTable = new HashTable();
- for(var i = 0; i < students.length; i++) {
- hTable.put(students[i]);
- }
- hTable.showDistro();
从散列表取值
前面讲的是散列函数,现在我们要学会使用散列存取数据操作,现在我们需要修改put方法,使得该方法同时接受键和数据作为参数,对键值散列后,将数据存储到散列表中,如下put代码:
- function put(key,data) {
- var pos = this.betterHash(key);
- this.table[pos] = data;
- }
Put()方法将键值散列化后,将数据存储到散列化后的键值对应的数组中的位置上。
接下来我们定义get方法,用以读取存储在散列表中的数据。该方法同样需要对键值进行散列化,然后才能知道数据到底存储在数组的什么位置上。代码如下:
- function get(key) {
- return this.table[this.betterHash(key)];
- }
下面是所有的JS代码如下:
- function HashTable() {
- this.table = new Array(137);
- }
- HashTable.prototype = {
- simpleHash: function(data) {
- var total = 0;
- for(var i = 0; i < data.length; i++) {
- total += data.charCodeAt(i);
- }
- console.log("Hash Value: " +data+ " -> " +total);
- return total % this.table.length;
- },
- put: function(key,data) {
- var pos = this.betterHash(key);
- this.table[pos] = data;
- },
- get: function(key) {
- return this.table[this.betterHash(key)];
- },
- showDistro: function(){
- var n = 0;
- for(var i = 0; i < this.table.length; i++) {
- if(this.table[i] != undefined) {
- console.log(i + ":" +this.table[i]);
- }
- }
- },
- betterHash: function(string){
- var H = 31;
- var total = 0;
- for(var i = 0; i < string.length; ++i) {
- total += H * total + string.charCodeAt(i);
- }
- total = total % this.table.length;
- console.log("Hash Value: " +string+ " -> " +total);
- if(total < 0) {
- total += this.table.length - 1;
- }
- return parseInt(total);
- }
- };
测试代码如下:
- var someNames = ["David","Jennifer","Donnie","Raymond","Cynthia","Mike","Clayton","Danny","Jonathan"];
- var hTable = new HashTable();
- for(var i = 0; i < someNames.length; ++i) {
- hTable.put(someNames[i],someNames[i]);
- }
- for(var i = 0; i < someNames.length; ++i) {
- console.log(hTable.get(someNames[i]));
- }
四:碰撞处理
当散列函数对于多个输入产生同样的输出时,就产生了碰撞。当碰撞发生时,我们仍然希望将键存储到通过散列算法产生的索引位置上,但是不可能将多份数据存储到一个数组单元中。那么实现开链法的方法是:在创建存储散列过的键值的数组时,通过调用一个函数创建一个新的空数组,然后在该数组赋值给散列表里的每个数组元素元素,这样就创建了一个二维数组,使用这种技术,即使两个键散列后的值相同,依然被保存在同样的位置上,但是他们的第二个数组的位置不一样。
1下面我们通过如下方法来创建一个二维数组,我们也称这个数组为链。代码如下:
- function buildChains(){
- for(var i = 0; i < this.table.length; i++) {
- this.table[i] = new Array();
- }
- }
2. 散列表里面使用多维数组存储数据,所以showDistro()方法代码需要改成如下:
- function showDistro() {
- var n = 0;
- for(var i = 0; i < this.table.length; i++) {
- if(this.table[i][0] != undefined) {
- console.log(i + ":" +this.table[i]);
- }
- }
- }
3. 使用了开链法后,需要重新对put和get方法进行改造,put()方法实现原理如下:
put()方法将键值散列,散列后的值对应数组中的一个位置,先尝试将数据放在该位置上的数组中的第一个单元格,如果该单元格里已经有数据了,put()方法会搜索下一个位置,直到找到能放置数据的单元格,并把数据存储进去,下面是put实现的代码:
- function put(key,data) {
- var pos = this.simpleHash(key);
- var index = 0;
- if(this.table[pos][index] == undefined) {
- this.table[pos][index] = data;
- }else {
- while(this.table[pos][index] != undefined) {
- ++index;
- }
- this.table[pos][index] = data;
- }
- }
4.get() 方法先对键值散列,根据散列后的值找到散列表相应的位置,然后搜索该位置上的链,直到找到键值,如果找到,就将紧跟在键值后面的数据返回,如果没有找到,就返回undefined。代码如下:
- function get(key) {
- var index = 0;
- var pos = this.simpleHash(key);
- if(this.table[pos][index] == key) {
- return this.table[pos][index];
- }else {
- while(this.table[pos][index] != key) {
- ++index;
- }
- return this.table[pos][index];
- }
- return undefined;
- }
下面是实现开链法的所有JS代码如下:
- function HashTable() {
- this.table = new Array(137);
- }
- HashTable.prototype = {
- simpleHash: function(data) {
- var total = 0;
- for(var i = 0; i < data.length; i++) {
- total += data.charCodeAt(i);
- }
- console.log("Hash Value: " +data+ " -> " +total);
- return total % this.table.length;
- },
- put: function(key,data) {
- var pos = this.simpleHash(key);
- var index = 0;
- if(this.table[pos][index] == undefined) {
- this.table[pos][index] = data;
- }else {
- while(this.table[pos][index] != undefined) {
- ++index;
- }
- this.table[pos][index] = data;
- }
- },
- get: function(key) {
- var index = 0;
- var pos = this.simpleHash(key);
- if(this.table[pos][index] == key) {
- return this.table[pos][index];
- }else {
- while(this.table[pos][index] != key) {
- ++index;
- }
- return this.table[pos][index];
- }
- return undefined;
- },
- showDistro: function(){
- var n = 0;
- for(var i = 0; i < this.table.length; i++) {
- if(this.table[i][0] != undefined) {
- console.log(i + ":" +this.table[i]);
- }
- }
- },
- buildChains: function() {
- for(var i = 0; i < this.table.length; i++) {
- this.table[i] = new Array();
- }
- }
- };
测试代码如下:
- var someNames = ["David","Jennifer","Donnie","Raymond","Cynthia","Mike","Clayton","Danny","Jonathan"];
- var hTable = new HashTable();
hTable.buildChains();- for(var i = 0; i < someNames.length; ++i) {
- hTable.put(someNames[i],someNames[i]);
- }
- hTable.showDistro();
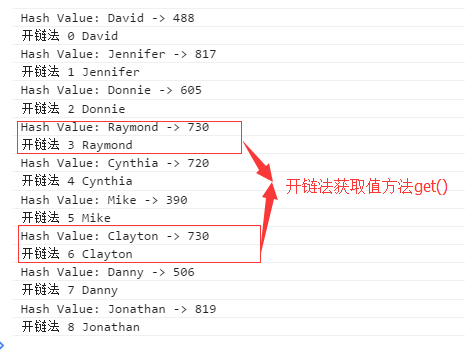
- console.log("--------------------------");
- for(var i = 0; i < someNames.length; ++i) {
- console.log("开链法 "+i + " "+hTable.get(someNames[i]));
- }
效果如下:

调用get()方法打印数据如下:
五:线性探测法
基本原理:
线性探测法属于一般的散列技术:开放寻址散列。当发生碰撞时,线性探测法检查散列表中的当前位置是否为空,如果为空,将数据存入该位置,如果不为空,则继续检查下一个位置,直到找到一个空的位置为止。
什么时候使用线性探测法,什么时候使用开链法呢?
如果数组的大小是待存储数据的个数是1.5倍,那么使用开链法,如果数组的大小是待存储的数据的2倍及2倍以上时,那么使用线性探测法。
为了实现线性探测法,我们需要增加一个新数组 values ,用来存储数据。代码如下:
- function HashTable() {
- this.table = new Array(137);
- this.values = [];
- }
我们知道探测法原理之后,我们就可以写put方法代码了,代码如下:
- function put(key,data) {
- var pos = this.simpleHash(key);
- if(this.table[pos] == undefined) {
- this.table[pos] = key;
- this.values[pos] = data;
- }else {
- while(this.table[pos] != undefined) {
- ++pos;
- }
- this.table[pos] = key;
- this.values[pos] = data;
- }
- }
2. get()方法的基本原理是:先搜索键在散列表中的位置,如果找到,则返回数组values中对应位置上的数据。如果没有找到,则循环搜索,以当前的位置的下一个位置开始循环搜索,如果找到对应的键,则返回对应的数据,否则的话 返回undefined;代码如下:
- function get(key) {
- var pos = this.simpleHash(key);
- if(this.table[pos] == key) {
- return this.values[pos];
- }else {
- for(var i = pos+1; i < this.table.length; i++) {
- if(this.table[i] == key) {
- return this.values[i];
- }
- }
- }
- return undefined;
- }
下面是所有JS代码如下:
- function HashTable() {
- this.table = new Array(137);
- this.values = [];
- }
- HashTable.prototype = {
- simpleHash: function(data) {
- var total = 0;
- for(var i = 0; i < data.length; i++) {
- total += data.charCodeAt(i);
- }
- console.log("Hash Value: " +data+ " -> " +total);
- return total % this.table.length;
- },
- put: function(key,data) {
- var pos = this.simpleHash(key);
- if(this.table[pos] == undefined) {
- this.table[pos] = key;
- this.values[pos] = data;
- }else {
- while(this.table[pos] != undefined) {
- ++pos;
- }
- this.table[pos] = key;
- this.values[pos] = data;
- }
- },
- get: function(key) {
- var pos = this.simpleHash(key);
- if(this.table[pos] == key) {
- return this.values[pos];
- }else {
- for(var i = pos+1; i < this.table.length; i++) {
- if(this.table[i] == key) {
- return this.values[i];
- }
- }
- }
- return undefined;
- },
- showDistro: function(){
- var n = 0;
- for(var i = 0; i < this.table.length; i++) {
- if(this.table[i] != undefined) {
- console.log(i + ":" +this.table[i]);
- }
- }
- }
- };
测试代码如下:
- var someNames = ["David","Jennifer","Donnie","Raymond","Cynthia","Mike","Clayton","Danny","Jonathan"];
- var hTable = new HashTable();
- for(var i = 0; i < someNames.length; ++i) {
- hTable.put(someNames[i],someNames[i]);
- }
- hTable.showDistro();
- console.log("--------------------------");
- for(var i = 0; i < someNames.length; ++i) {
- console.log(hTable.get(someNames[i]));
- }
效果如下:

javascript数据结构与算法--散列的更多相关文章
- JavaScript数据结构与算法-散列练习
散列的实现 // 散列类 - 线性探测法 function HashTable () { this.table = new Array(137); this.values = []; this.sim ...
- 为什么我要放弃javaScript数据结构与算法(第七章)—— 字典和散列表
本章学习使用字典和散列表来存储唯一值(不重复的值)的数据结构. 集合.字典和散列表可以存储不重复的值.在集合中,我们感兴趣的是每个值本身,并把它作为主要元素.而字典和散列表中都是用 [键,值]的形式来 ...
- 算法与数据结构(十二) 散列(哈希)表的创建与查找(Swift版)
散列表又称为哈希表(Hash Table), 是为了方便查找而生的数据结构.关于散列的表的解释,我想引用维基百科上的解释,如下所示: 散列表(Hash table,也叫哈希表),是根据键(Key)而直 ...
- 为什么我要放弃javaScript数据结构与算法(第九章)—— 图
本章中,将学习另外一种非线性数据结构--图.这是学习的最后一种数据结构,后面将学习排序和搜索算法. 第九章 图 图的相关术语 图是网络结构的抽象模型.图是一组由边连接的节点(或顶点).学习图是重要的, ...
- 为什么我要放弃javaScript数据结构与算法(第六章)—— 集合
前面已经学习了数组(列表).栈.队列和链表等顺序数据结构.这一章,我们要学习集合,这是一种不允许值重复的顺序数据结构. 本章可以学习到,如何添加和移除值,如何搜索值是否存在,也可以学习如何进行并集.交 ...
- 为什么我要放弃javaScript数据结构与算法(第二章)—— 数组
第二章 数组 几乎所有的编程语言都原生支持数组类型,因为数组是最简单的内存数据结构.JavaScript里也有数组类型,虽然它的第一个版本并没有支持数组.本章将深入学习数组数据结构和它的能力. 为什么 ...
- javascript数据结构与算法---栈
javascript数据结构与算法---栈 在上一遍博客介绍了下列表,列表是最简单的一种结构,但是如果要处理一些比较复杂的结构,列表显得太简陋了,所以我们需要某种和列表类似但是更复杂的数据结构---栈 ...
- javascript数据结构与算法---列表
javascript数据结构与算法---列表 前言:在日常生活中,人们经常要使用列表,比如我们有时候要去购物时,为了购物时东西要买全,我们可以在去之前,列下要买的东西,这就要用的列表了,或者我们小时候 ...
- 为什么我要放弃javaScript数据结构与算法(第十一章)—— 算法模式
本章将会学习递归.动态规划和贪心算法. 第十一章 算法模式 递归 递归是一种解决问题的方法,它解决问题的各个小部分,直到解决最初的大问题.递归通常涉及函数调用自身. 递归函数是像下面能够直接调用自身的 ...
随机推荐
- LLVM 笔记(五)—— LLVM IR
ilocker:关注 Android 安全(新手) QQ: 2597294287 LLVM 的 IR (Intermediate Representation) 是其设计中的最重要的部分.优化器在进行 ...
- ASP.NET Core AD 域登录
在选择AD登录时,其实可以直接选择 Windows 授权,不过因为有些网站需要的是LDAP获取信息进行授权,而非直接依赖Web Server自带的Windows 授权功能. 当然如果使用的是Azure ...
- Java集合框架之map
Java集合框架之map. Map的主要实现类有HashMap,LinkedHashMap,TreeMap,等等.具体可参阅API文档. 其中HashMap是无序排序. LinkedHashMap是自 ...
- unity 绘制三角形
哎 该学的还是要学 参考:http://www.narkii.com/club/thread-369573-1.html unity 顶点绘制三角形 脚本绘制; 其实filter和render就是进行 ...
- bzoj[1087][SCOI2005]互不侵犯King
Description 在N×N的棋盘里面放K个国王,使他们互不攻击,共有多少种摆放方案.国王能攻击到它上下左右,以及左上左下右上右下八个方向上附近的各一个格子,共8个格子. Input 只有一行,包 ...
- 浅显易懂的理解JavaScript中的this关键字
在JavaScript中this变量是一个令人难以摸清的关键字,this可谓是非常强大,充分了解this的相关知识有助于我们在编写面向对象的JavaScript程序时能够游刃有余. 1. 一般用处 对 ...
- 只需2分钟,简单构建velocity web项目
Velocity是一个基于java的模板引擎(template engine).它允许任何人仅仅简单的使用模板语言(template language)来引用由java代码定义的对象 velocity ...
- tensorflow学习笔记五:mnist实例--卷积神经网络(CNN)
mnist的卷积神经网络例子和上一篇博文中的神经网络例子大部分是相同的.但是CNN层数要多一些,网络模型需要自己来构建. 程序比较复杂,我就分成几个部分来叙述. 首先,下载并加载数据: import ...
- Linux实现https方式访问站点
超文本传送协议(HyperText Transfer Protocol,HTML)是一种通信协议,它允许将超文本标记语言文档从web服务器传送到wel浏览器. HTML的特点: 1.支持客户/服务器模 ...
- VS 团队资源管理 强制解锁锁定文件
故事是这样发生的: 以前有台电脑,在团队资源里看程序,可能冥冥中不小心按了个空格,so,文件被锁定 而我却没有发现 如果再给我一个机会,我只想说记得签入 然后,高潮来了 重装电脑 欣喜的装好新机子打开 ...