java深入探究12-框架之Hibernate
1.引入SSH框架
Struts框架,基于MVC 模式的应用层框架技术
Hibernate,基于持久层框架(数据访问层使用)
Dao代码编写的几种方式:
1.原始jdbc操作,Connection/Statement/ResultSet
2.自定义一个持久层框架,封装dao的通用方法
3.DbUtils组件,轻量级数据访问技术
4.Hibernate技术【最终执行的就是jdbc代码!】
2.开始学习SSH框架
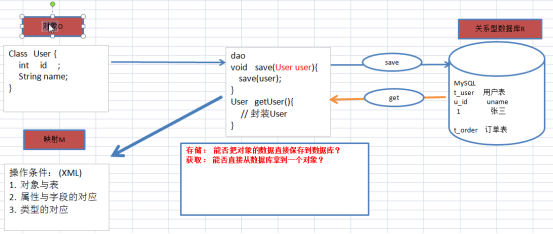
a) ORM概念
Object Realtion Mapping:对象关系映射
用于:直接将对象存入数据库;直接从数据库拿到对象!
想要做到这点:映射,映射信息存入xml中
映射中信息:1.对象与表,2.属性与字段,3.类型的对应
O R M三者间的关系
b) 组件的学习:源码引入jar文件
c) 环境搭建
我们也可以直接添加jar包,之后只有再添加一个连接数据库的包就好了

- 下载源码hibernate-distribution-3.6.0.Final
- jar包:实际上我们可以直接
hibernate3.jar核心+required必须引入的(6个)+jpa目录+数据库驱动包required中的jar:antlr-2.7.6;commons-collections-3.1;dom4j-1.6.1;javassist-3.12.0.GA;jta-1.1;slf4j-api-1.6.1
Jpa:hibernate-jpa-2.0-api-1.0.0.Final.jar
数据库驱动:mysql-connector-java-5.1.12-bin.jar
- 写对象和对象映射
- Employee.java 对象
- Employee.hbm.xml对象映射 我们可在源码中随便找个hbm文件再修改为自己的
- Src/hibernate.cfg.xml(源码project/etc/hibernate.cfg.xml可以找到再自行修改)
- 数据库连接配置;2.加载所用的映射(*.hbm.xml)
例子:
获取sessionFactory的工具类
public class HibernateUtils {
private static SessionFactory sf;
static{
sf=new Configuration().configure().buildSessionFactory();
}
public static Session getSession(){
return sf.openSession();
}
}
d) 核心API
Configuration 配置管理类对象
Config.configure(); 加载主配置文件的方法(hibernate.cfg.xml)
默认加载src/hibernate.cfg.xml
Config.configure(cn/config/hibernate.cfg.xml);加载指定路径下的
config.buildSessionFactory();创建session的工厂对象
SessionFactory Session的工厂(或者说代表hibernate.cfg.xml文件)
sf.openSession(); 创建一个session对象
sf.getCurrentSession();创建一个session或者取出session对象
Session session对象维护了一个连接(Connection),代表与数据库连接的回话,hibernate最重要的一个对象
session.beginTransaction();开启一个事务,hibernate要求所有与数据库的操作都要有事务,否则报错
更新:
Session.save(obj)
Session.update(obj)
session.saveOrUpdate(obj);保存或者更新方法
—》有主键执行更新
—》没主键执行保存
—》如果设置的主键不存在报错
主键查询:
Session.get(obj.class,1) 主键查询
Session.load(obj.class,1)主键查询(支持懒加载)
HQL查询:
与SQL区别:SQL(结构化查询语句)面向表查询,不区分大小写
HQL:Hebernate query language面向对象的查询语句,因为是对象,区分大小写
//适合有数据库基础的HQL面向对象,SQL面向表
public static void HQLQuery(){
/*这里的Hibernate的SQL与jdbc中的sql不同,对象对象的,jdbc是面向表字段的*/ Query q=session.createQuery("from Employee where empId=1 or empId=2");
List<Employee> list=q.list();
System.out.println(list);
}
Criteria查询:没有数据库基础也可以用完全面向对象的查询
//QBC查询,query by criteria 完全面向对象的查询
public static void CriteriaQuery(){
Criteria criteria=session.createCriteria(Employee.class);
//加条件
criteria.add(Restrictions.eq("empId", ));
List<Employee > list=criteria.list();//开始查询
System.out.println(list);
}
本地SQL查询:原生sql,缺点不能数据库跨平台
//本地事务查询sql直接查询
public static void SqlQuery(){
//把每一行数数据封装为对象数组,再添加list集合
//SQLQuery sq=session.createSQLQuery("select * from employee");
SQLQuery sq=session.createSQLQuery("select * from employee").addEntity(Employee.class);
//想要封装对象-》
List<?> list=sq.list();
System.out.println(list);
}
e)可能会遇到的问题
1.ClassNotFoundException...,缺少jar文件!
2.如果程序执行,hibernate也生成sql语句,但数据没有结果影响:
一般是事务没有提交。。
f)Hibernate crud
增删改查方法
package crud; import hello.Employee; import java.io.Serializable;
import java.util.List; import org.hibernate.HibernateException;
import org.hibernate.Query;
import org.hibernate.Session;
import org.hibernate.Transaction; import utils.HibernateUtils; public class EmployeeImpl implements EmployeeDao { @Override
public void save(Employee emp) {
// TODO Auto-generated method stub
//获取session
Session session=null;
Transaction ts=null;
try { //业务逻辑
session=HibernateUtils.getSession();
ts=session.beginTransaction(); } catch (HibernateException e) {
// TODO Auto-generated catch block
throw new RuntimeException();
}finally{
ts.commit();
session.close();
} } @Override
public void update(Employee emp) {
// TODO Auto-generated method stub
//获取session
Session session=null;
Transaction ts=null;
try {
session = HibernateUtils.getSession();
ts = session.beginTransaction(); //业务逻辑
session.update(emp); } catch (HibernateException e) {
// TODO Auto-generated catch block
throw new RuntimeException();
}finally{
ts.commit();
session.close();
} } @Override
public Employee findById(Serializable id) {
//获取session
Session session=null;
Transaction ts=null;
try {
session = HibernateUtils.getSession();
ts = session.beginTransaction(); //业务逻辑
return (Employee)session.get(Employee.class, id); } catch (HibernateException e) {
// TODO Auto-generated catch block
throw new RuntimeException();
}finally{
ts.commit();
session.close();
}
} @Override
public List<Employee> getAll() {
//获取session
Session session=null;
Transaction ts=null;
try {
session = HibernateUtils.getSession();
ts = session.beginTransaction(); //业务逻辑
return session.createQuery("from Employee").list(); } catch (HibernateException e) {
// TODO Auto-generated catch block
throw new RuntimeException();
}finally{
ts.commit();
session.close();
}
} @Override
public List<Employee> getAll(String employeeName) {
// TODO Auto-generated method stub
//获取session
Session session=null;
Transaction ts=null;
try {
session = HibernateUtils.getSession();
ts = session.beginTransaction(); //业务逻辑
Query q =session.createQuery("from Employee where empName=?");
q.setParameter(, employeeName);
return q.list(); } catch (HibernateException e) {
// TODO Auto-generated catch block
throw new RuntimeException();
}finally{
ts.commit();
session.close();
}
} @Override
public List<Employee> getAll(int index, int count) {
//获取session
Session session=null;
Transaction ts=null;
try {
session = HibernateUtils.getSession();
ts = session.beginTransaction(); //业务逻辑
Query q= session.createQuery("from Employee");
q.setFirstResult(index);//查询起始行
q.setMaxResults(count);//查询的行数
return q.list(); } catch (HibernateException e) {
// TODO Auto-generated catch block
throw new RuntimeException();
}finally{
ts.commit();
session.close();
}
} @Override
public void delete(Serializable id) {
Session session = null;
Transaction tx = null;
try {
session = HibernateUtils.getSession();
tx = session.beginTransaction();
// 先根据id查询对象,再判断删除
Object obj=session.get(Employee.class, id);
if(obj!=null){
session.delete(obj);
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
tx.commit();
session.close();
}
} }
g)配置文件
主配置:hibernate.cfg.xml:主要配置数据库信息、其他参数、映射信息
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <hibernate-configuration>
<!-- 通常,一个session-factory节点代表一个数据库 -->
<session-factory> <!-- . 数据库连接配置 -->
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql:///hib_demo</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password">root</property>
<!--
数据库方法配置, hibernate在运行的时候,会根据不同的方言生成符合当前数据库语法的sql
-->
<property name="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect</property> <!-- . 其他相关配置 -->
<!-- 2.1 显示hibernate在运行时候执行的sql语句 -->
<property name="hibernate.show_sql">true</property>
<!-- 2.2 格式化sql -->
<property name="hibernate.format_sql">true</property>
<!-- 2.3 自动建表 -->
<property name="hibernate.hbm2ddl.auto">update</property> <!-- . 加载所有映射 -->
<mapping resource="hello/Employee.hbm.xml"/> </session-factory>
</hibernate-configuration>
其中自动建表:就算数据库中的表被删了只要配置好就能自动在数据库中建表
<property name="hibernate.hbm2ddl.auto">update</property>
#hibernate.hbm2ddl.auto create-drop 每次在创建sessionFactory时候执行创建表;
当调用sesisonFactory的close方法的时候,删除表!
#hibernate.hbm2ddl.auto create 每次都重新建表; 如果表已经存在就先删除再创建
#hibernate.hbm2ddl.auto update 如果表不存在就创建; 表存在就不创建;
#hibernate.hbm2ddl.auto validate (生成环境时候) 执行验证: 当映射文件的内容与数据库表结构不一样的时候就报错!
自动建表代码方式:SchemaExport export = new SchemaExport(config);主要是创建工具类对象
export.creat(true,true),参数1显示在colsole,第二个是在数据库中执行
// 自动建表
@Test
public void testCreate() throws Exception {
// 创建配置管理类对象
Configuration config = new Configuration();
// 加载主配置文件
config.configure(); // 创建工具类对象
SchemaExport export = new SchemaExport(config);
// 建表
// 第一个参数: 是否在控制台打印建表语句
// 第二个参数: 是否执行脚本
映射配置:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <!-- 映射文件: 映射一个实体类对象; 描述一个对象最终实现可以直接保存对象数据到数据库中。 -->
<!--
package: 要映射的对象所在的包(可选,如果不指定,此文件所有的类都要指定全路径)
auto-import 默认为true, 在写hql的时候自动导入包名
如果指定为false, 再写hql的时候必须要写上类的全名;
如:session.createQuery("from cn.itcast.c_hbm_config.Employee").list();
-->
<hibernate-mapping package="cn.itcast.c_hbm_config" auto-import="true"> <!--
class 映射某一个对象的(一般情况,一个对象写一个映射文件,即一个class节点)
name 指定要映射的对象的类型
table 指定对象对应的表;
如果没有指定表名,默认与对象名称一样
-->
<class name="Employee" table="employee"> <!-- 主键 ,映射-->
<id name="empId" column="id">
<!--
主键的生成策略
identity 自增长(mysql,db2)
sequence 自增长(序列), oracle中自增长是以序列方法实现
native 自增长【会根据底层数据库自增长的方式选择identity或sequence】
如果是mysql数据库, 采用的自增长方式是identity
如果是oracle数据库, 使用sequence序列的方式实现自增长 increment 自增长(会有并发访问的问题,一般在服务器集群环境使用会存在问题。) assigned 指定主键生成策略为手动指定主键的值
uuid 指定uuid随机生成的唯一的值
foreign (外键的方式, one-to-one讲)
-->
<generator class="uuid"/>
</id> <!--
普通字段映射
property
name 指定对象的属性名称
column 指定对象属性对应的表的字段名称,如果不写默认与对象属性一致。
length 指定字符的长度, 默认为255
type 指定映射表的字段的类型,如果不指定会匹配属性的类型
java类型: 必须写全名
hibernate类型: 直接写类型,都是小写
-->
<property name="empName" column="empName" type="java.lang.String" length=""></property>
<property name="workDate" type="java.util.Date"></property>
<!-- 如果列名称为数据库关键字,需要用反引号或改列名。 -->
<property name="desc" column="`desc`" type="java.lang.String"></property> </class> </hibernate-mapping>
其中复合主键:一个表中主键除了一个可能还会有2个或更多在一起作为复合主键
映射文件中配置复合主键<composite-id>
// 复合主键类
public class CompositeKeys implements Serializable{
private String userName;
private String address;
// .. get/set
}
public class User { // 名字跟地址,不会重复
private CompositeKeys keys;
private int age;
}
User.hbm.xml
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="cn.itcast.d_compositeKey" auto-import="true"> <class name="User"> <!-- 复合主键映射 -->
<composite-id name="keys">
<key-property name="userName" type="string"></key-property>
<key-property name="address" type="string"></key-property>
</composite-id> <property name="age" type="int"></property> </class> </hibernate-mapping> App.java public class App2 { private static SessionFactory sf;
static {
// 创建sf对象
sf = new Configuration()
.configure()
.addClass(User.class) //(测试) 会自动加载映射文件:Employee.hbm.xml
.buildSessionFactory();
} //1. 保存对象
@Test
public void testSave() throws Exception {
Session session = sf.openSession();
Transaction tx = session.beginTransaction(); // 对象
CompositeKeys keys = new CompositeKeys();
keys.setAddress("广州棠东");
keys.setUserName("Jack");
User user = new User();
user.setAge();
user.setKeys(keys); // 保存
session.save(user); tx.commit();
session.close();
} @Test
public void testGet() throws Exception {
Session session = sf.openSession();
Transaction tx = session.beginTransaction(); //构建主键再查询
CompositeKeys keys = new CompositeKeys();
keys.setAddress("广州棠东");
keys.setUserName("Jack"); // 主键查询
User user = (User) session.get(User.class, keys);
// 测试输出
if (user != null){
System.out.println(user.getKeys().getUserName());
System.out.println(user.getKeys().getAddress());
System.out.println(user.getAge());
} tx.commit();
session.close();
}
}
hibernate执行周期:
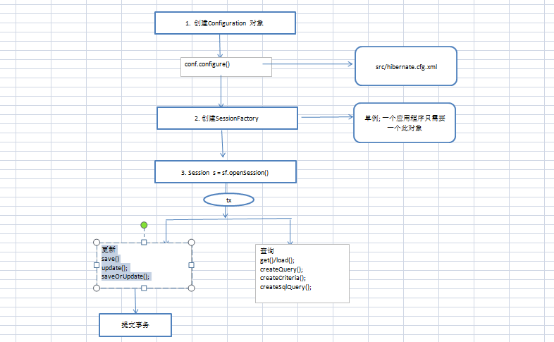
-------------------------------------------------------------------------
关联映射
1. 集合映射
开发流程:需求分析/数据库设计、项目设计/ 编码/测试/实施部署上线/验收
需求:一个用户有多个收货地址,通过映射创建映射表到数据库中,并对表数据做处理
核心思路:配置文件中<property name="hibernate.hbm2ddl.auto">update</property>设置为自动生成表
映射文件配置set映射配置:没有啥特殊之处,对应的只需外键就可以
List集合映射:List有记住存储顺序的能力,处了外键,还需能记住存储顺序的list-index
Map集合映射:map有兼职对的能力,处了外键还需键的存储,值得存储
查询数据时,当查询Map映射信息,或list信息,都属于懒加载,代码写到时才会从数据库发送sql
<!--
set集合属性的映射
name 指定要映射的set集合的属性
table 集合属性要映射到的表
key 指定集合表(t_address)的外键字段
element 指定集合表的其他字段
type 元素类型,一定要指定
-->
<set name="address" table="t_address">
<key column="uid"></key>
<element column="address" type="string"></element>
</set>
完整代码:
// javabean设计
public class User { private int userId;
private String userName;
// 一个用户,对应的多个地址
private Set<String> address;
private List<String> addressList = new ArrayList<String>();
//private String[] addressArray; // 映射方式和list一样 <array name=""></array>
private Map<String,String> addressMap = new HashMap<String, String>(); }
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="cn.itcast.a_collection"> <class name="User" table="t_user">
<id name="userId" column="id">
<generator class="native"></generator>
</id>
<property name="userName"></property> <!--
set集合属性的映射
name 指定要映射的set集合的属性
table 集合属性要映射到的表
key 指定集合表(t_address)的外键字段
element 指定集合表的其他字段
type 元素类型,一定要指定
-->
<set name="address" table="t_address">
<key column="uid"></key>
<element column="address" type="string"></element>
</set> <!--
list集合映射
list-index 指定的是排序列的名称 (因为要保证list集合的有序)
-->
<list name="addressList" table="t_addressList">
<key column="uid"></key>
<list-index column="idx"></list-index>
<element column="address" type="string"></element>
</list> <!--
map集合的映射
key 指定外键字段
map-key 指定map的key
element 指定map的value
-->
<map name="addressMap" table="t_addressMap">
<key column="uid"></key>
<map-key column="shortName" type="string" ></map-key>
<element column="address" type="string" ></element>
</map> </class> </hibernate-mapping> // 保存set
@Test
public void testSaveSet() throws Exception {
Session session = sf.openSession();
session.beginTransaction(); //-- 保存
Set<String> addressSet = new HashSet<String>();
addressSet.add("广州");
addressSet.add("深圳");
// 用户对象
User user = new User();
user.setUserName("Jack");
user.setAddress(addressSet); // 保存
session.save(user); session.getTransaction().commit();
session.close();
} // 保存list/map
@Test
public void testSaveList() throws Exception {
Session session = sf.openSession();
session.beginTransaction();
User user = new User();
user.setUserName("Tom");
// // 用户对象 -- list
// user.getAddressList().add("广州");
// user.getAddressList().add("深圳");
// // 保存
// session.save(user); // 用户对象 -- Map
user.getAddressMap().put("A0001", "广州");
user.getAddressMap().put("A0002", "深圳"); // 保存
session.save(user); session.getTransaction().commit();
session.close();
}
2. 关联映射 (重点)
有7中关联映射:1.单向一对一,单项一对一唯一外键关联;2.单向一对多,3.单向多对一,4.单向多对多,5.双向多对多,6.双向一对多,7.双向一对一
1)引入:集合映射,映射的集合元素,都是普通的类型, 能否为对象类型
2)需求1:
部门与员工:一个部门有多个员工【一对多】;多个员工,属于一个部门【多对一】
需求2:
项目与开发员工:一个项目有多个开发人员,一个开发人员参与多个项目【多对多】
3)多对一映射与一对多
映射配置:
<!--
一对多关联映射配置 (通过部门管理到员工)
casecade="save-update,delete";//关联表的联机影响
inverse=false set集合映射的默认值; 表示有控制权
-->
<set name="emps" cascade="save-update,delete" table="t_employee" inverse="true"> <!-- table="t_employee" -->
<key column="dept_id"></key>
<one-to-many class="Employee"/>
</set>
<!--
多对一关联映射配置
-->
<many-to-one name="dept" column="dept_id" class="Dept"></many-to-one>
Inverse属性
维护关系的时候起作用,表示控制权是否转移(只在一的一方有作用)
inverse=false 不反转;当前方有控制权
inverse-true 反转:当前方没有控制权,所以在以一对多存储(最后由一的结束控制关系)时就没有控制到关系了
影响
. 保存数据
有影响。
如果设置控制反转,即inverse=true, 然后通过部门方维护关联关系。在保存部门的时候,同时保存员工, 数据会保存,但关联关系不会维护。即外键字段为NULL . 获取数据
无。
. 解除关联关系?
有影响。
inverse=false, 可以解除关联
inverse=true, 当前方(部门)没有控制权,不能解除关联关系
(不会生成update语句,也不会报错)
. 删除数据对关联关系的影响?
有影响。
inverse=false, 有控制权, 可以删除。先清空外键引用,再删除数据。
inverse=true, 没有控制权: 如果删除的记录有被外键引用,会报错,违反主外键引用约束! 如果删除的记录没有被引用,可以直接删除。
casecade属性 【可以设置到一的方和多的方】
none 不级联操作, 默认值
save-update 级联保存或更新
delete 级联删除
save-update,delete 级联保存、更新、删除
all 同上。级联保存、更新、删除
例子:
public class Dept {
private int deptId;
private String deptName;
// 【一对多】 部门对应的多个员工
private Set<Employee> emps = new HashSet<Employee>();
public class Employee {
private int empId;
private String empName;
private double salary;
// 【多对一】员工与部门
private Dept dept;
Dept.hbm.xml
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.b_one2Many">
<class name="Dept" table="t_dept">
<id name="deptId">
<generator class="native"></generator>
</id>
<property name="deptName" length=""></property>
<!--
一对多关联映射配置 (通过部门管理到员工)
Dept 映射关键点:
. 指定 映射的集合属性: "emps"
. 集合属性对应的集合表: "t_employee"
. 集合表的外键字段 "t_employee. dept_id"
. 集合元素的类型
-->
<set name="emps"> <!-- table="t_employee" -->
<key column="dept_id"></key>
<one-to-many class="Employee"/>
</set>
</class>
</hibernate-mapping>
Employee.hbm.xml
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="cn.itcast.b_one2Many">
<class name="Employee" table="t_employee">
<id name="empId">
<generator class="native"></generator>
</id>
<property name="empName" length=""></property>
<property name="salary" type="double"></property>
<!--
多对一映射配置
Employee 映射关键点:
. 映射的部门属性 : dept
. 映射的部门属性,对应的外键字段: dept_id
. 部门的类型
-->
<many-to-one name="dept" column="dept_id" class="Dept"></many-to-one>
</class>
</hibernate-mapping>
测试
public class App {
private static SessionFactory sf;
static {
sf = new Configuration()
.configure()
.addClass(Dept.class)
.addClass(Employee.class) // 测试时候使用
.buildSessionFactory();
}
// 保存, 部门方 【一的一方法操作】
@Test
public void save() {
Session session = sf.openSession();
session.beginTransaction();
// 部门对象
Dept dept = new Dept();
dept.setDeptName("应用开发部");
// 员工对象
Employee emp_zs = new Employee();
emp_zs.setEmpName("张三");
Employee emp_ls = new Employee();
emp_ls.setEmpName("李四");
// 关系
dept.getEmps().add(emp_zs);
dept.getEmps().add(emp_ls);
// 保存
session.save(emp_zs);
session.save(emp_ls);
session.save(dept); // 保存部门,部门下所有的员工
session.getTransaction().commit();
session.close();
/*
* 结果
* Hibernate: insert into t_employee (empName, salary, dept_id) values (?, ?, ?)
Hibernate: insert into t_employee (empName, salary, dept_id) values (?, ?, ?)
Hibernate: insert into t_dept (deptName) values (?)
Hibernate: update t_employee set deptId=? where empId=? 维护员工引用的部门的id
Hibernate: update t_employee set deptId=? where empId=?
*/
}
// 【推荐】 保存, 部员方 【多的一方法操作】
@Test
public void save2() {
Session session = sf.openSession();
session.beginTransaction();
// 部门对象
Dept dept = new Dept();
dept.setDeptName("综合部");
// 员工对象
Employee emp_zs = new Employee();
emp_zs.setEmpName("张三");
Employee emp_ls = new Employee();
emp_ls.setEmpName("李四");
// 关系
emp_zs.setDept(dept);
emp_ls.setDept(dept);
// 保存
session.save(dept); // 先保存一的方法
session.save(emp_zs);
session.save(emp_ls);// 再保存多的一方,关系回自动维护(映射配置完)
session.getTransaction().commit();
session.close();
/*
* 结果
* Hibernate: insert into t_dept (deptName) values (?)
Hibernate: insert into t_employee (empName, salary, dept_id) values (?, ?, ?)
Hibernate: insert into t_employee (empName, salary, dept_id) values (?, ?, ?)
少生成2条update sql
*/
}
}
总结:多的一方来维护关系能提高效率
一对多的保存:先保存员工,再保存部门,关系有部门来维护,多了些update代码,不推荐
多对一的保存:先保存部门再保存员工,关系有员工来维护,效率高些
例子中两种保存都在测试App中save(),save2()
配置一对多与多对一,这种叫“双向关联”
只配置一对多, 叫“单项一对多”
只配置多对一, 叫“单项多对一”
注意:
配置了哪一方,哪一方才有维护关联关系的权限!
3. 多对多映射
项目与开发人员
电商系统 OA系统 曹吉 王春
完整代码:
/**
* 开发人员
*
* @author Jie.Yuan
*
*/
public class Developer {
private int d_id;
private String d_name;
// 开发人员,参数的多个项目
private Set<Project> projects = new HashSet<Project>();
} /**
* 项目
*
* @author Jie.Yuan
*
*/
public class Project {
private int prj_id;
private String prj_name;
// 项目下的多个员工
private Set<Developer> developers = new HashSet<Developer>(); Project.hbm.xml
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="cn.itcast.c_many2many"> <class name="Project" table="t_project">
<id name="prj_id">
<generator class="native"></generator>
</id>
<property name="prj_name" length=""></property>
<!--
多对多映射:
. 映射的集合属性: “developers”
. 集合属性,对应的中间表: “t_relation”
. 外键字段: prjId
. 外键字段,对应的中间表字段: did
. 集合属性元素的类型
-->
<set name="developers" table="t_relation" cascade="save-update">
<key column="prjId"></key>
<many-to-many column="did" class="Developer"></many-to-many>
</set> </class> </hibernate-mapping> Developer.hbm.xml
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="cn.itcast.c_many2many"> <class name="Developer" table="t_developer">
<id name="d_id">
<generator class="native"></generator>
</id>
<property name="d_name" length=""></property> <!--
多对多映射配置: 员工方
name 指定映射的集合属性
table 集合属性对应的中间表
key 指定中间表的外键字段(引用当前表t_developer主键的外键字段)
many-to-many
column 指定外键字段对应的项目字段
class 集合元素的类型
-->
<set name="projects" table="t_relation">
<key column="did"></key>
<many-to-many column="prjId" class="Project"></many-to-many>
</set> </class> </hibernate-mapping>
多对多配置:
<set name="projects" table="t_relation">
<key column="did"></key>
<many-to-many column="prjId" class="Project"></many-to-many>
</set>
在多对多中设置关系维护inverse属性:
) 保存数据
有影响。
inverse=false ,有控制权,可以维护关联关系; 保存数据的时候会把对象关系插入中间表;
inverse=true, 没有控制权, 不会往中间表插入数据。
) 获取数据
无。 ) 解除关系
// 有影响。
// inverse=false ,有控制权, 解除关系就是删除中间表的数据。
// inverse=true, 没有控制权,不能解除关系。
) 删除数据
有影响。
// inverse=false, 有控制权。 先删除中间表数据,再删除自身。
// inverse=true, 没有控制权。 如果删除的数据有被引用,会报错! 否则,才可以删除
映射总结:
一对多:
<set name="映射的集合属性" table="(可选)集合属性对应的外键表">
<key column="外键表的,外键字段" />
<one-to-many class="集合元素的类型" />
</set> 多对一:
<many-to-one name="对象属性" class="对象类型" column="外键字段字段" /> 多对多
<set name="" table="">
<key column="" />
<many-to-many column="" class="">
</set>
-------------------------------------------------------------------
1.对象状态
临时状态、持久化状态、游离状态
临时状态:new创建出来的,不由session管理,数据库中没有对应的值
持久化状态:session来调用save()方法,管理对象,数据库中有数据
session.save(user); //持久化状态后再对user处理就会反应到数据库中
user.setUserName("Jack333333"); // 会反映到数据库
游离状态:session管理,数据库中有值管理,一般都是持久化对象session关闭后
对对象的处理,不同结果是由对象当前的状态决定的!!!
user = (User) session.get(User.class, 5);// 先检查缓存中是否有数据,如果有不查询数据库,直接从缓存中获取
对象转换例子:
//1. 对象状态的转换
@Test
public void testSaveSet() throws Exception {
Session session = sf.openSession();
session.beginTransaction(); // 创建对象 【临时状态】
User user = new User();
user.setUserName("Jack22222");
// 保存 【持久化状态】
session.save(user);
user.setUserName("Jack333333"); // 会反映到数据库 // 查询
/*User user = (User) session.get(User.class, 5);
user.setUserName("Tomcat");// hibernate会自动与数据库匹配(一级缓存),如果一样就更新数据库
*/
session.getTransaction().commit();
session.close(); user.setUserName("Jack444444444");
// 打印 【游离状态】
System.out.println(user.getUserId());
System.out.println(user.getUserName());
}
2.缓存
缓存目的:减少对数据库的访问,从而提供hibernate的执行效率
1)一级缓存
session的缓存就是一级缓存;
1.如何将对象存入缓存:session调用方法save/saveOrUpdate/get/load/list/iterator方法时会将对象存入缓存
2.缓存感觉:小数据感觉不到,当操作数据库次数多时就能体现出来了
3.如何处理session的缓存:用户不能操作缓存数据,如果想要操作它的缓存数据必须通过hibernate提供的evit(),clear()方法
4.缓存的几个方法:
session.flush();//让一级缓存与数据库同步,同步后就相当事务提交,session就失去管理,对象处于游离状态
session.evit(arg0);//清空缓存中指定的对象
session.clear();//清空缓存中所有的对象
5.什么情况用上面的方法:批量操作的时候
Session.flush(); // 先与数据库同步
Session.clear(); // 再清空一级缓存内容
6.面试题:
一:session是否会共享缓存数据?不会!
二:list,iterator查询区别:
list查询会将所有的查询的记录都放入缓存,但不会缓存中获取数据
iterator:查询了N+1次,N是所有的查询记录,先将所有记录的主键(1)存入缓存,之后再通过缓存中的主键获得每条记录
/**
* list与iterator区别
* 1. list 方法
* 2. iterator 方法
* 3. 缓存
* @throws Exception
*/
//1. list 方法
@Test
public void list() throws Exception {
Session session = sf.openSession();
session.beginTransaction();
// HQL查询
Query q = session.createQuery("from User ");
// list()方法
List<User> list = q.list(); for (int i=; i<list.size(); i++){
System.out.println(list.get(i));
} session.getTransaction().commit();
session.close();
} //2. iterator 方法
@Test
public void iterator() throws Exception {
Session session = sf.openSession();
session.beginTransaction();
// HQL查询
Query q = session.createQuery("from User ");
// iterator()方法
Iterator<User> it = q.iterate();
while(it.hasNext()){
// 得到当前迭代的每一个对象
User user = it.next();
System.out.println(user);
} session.getTransaction().commit();
session.close();
}
3.懒加载:
1)session.get()不是懒加载,session.load()默认是懒加载
2)懒加载对于set集合的配置:
<!--
集合属性,默认使用懒加载
lazy
true 懒加载
extra 懒加载(智能)
false 关闭懒加载 -->
<set name="emps" lazy="extra">
<key column="dept_id"></key>
<one-to-many class="Employee"/>
</set>
3)懒加载运行路线:
在真正使用数据的时候才向数据库发送查询的sql;
如果调用集合的size()/isEmpty()方法,只是统计,不真正查询数据!
4)懒加载异常
Session关闭后,不能使用懒加载数据!
如果session关闭后,使用懒加载数据报错:
org.hibernate.LazyInitializationException: could not initialize proxy - no Session
如何解决session关闭后不能加载数据:
1.在关闭之前使用下数据;//dept.getDeptName();
2.强迫代理初始化://.Hibernate.initialize(dept);
3.直接关闭懒加载://lazy=false//在配置文件中直接修改
5)例子:
//1. 主键查询,及区别
@Test
public void get_load() { Session session = sf.openSession();
session.beginTransaction();
Dept dept = new Dept();
// get: 及时查询
//dept = (Dept) session.get(Dept.class, 1);
//System.out.println(dept.getDeptName()); // load,默认懒加载, 及在使用数据的时候,才向数据库发送查询的sql语句!
dept = (Dept)session.load(Dept.class, );
// 方式1: 先使用一下数据
dept.getDeptName();
// 方式2:强迫代理对象初始化
//Hibernate.initialize(dept);
// 方式3:关闭懒加载 session.getTransaction().commit();
session.close(); // 在这里使用
System.out.println(dept.getDeptName());
} //1. 主键查询,及区别
@Test
public void set() {
Session session = sf.openSession();
session.beginTransaction();
Dept dept = (Dept) session.get(Dept.class, );
System.out.println(dept.getDeptName());
System.out.println("------");
System.out.println(dept.getEmps().isEmpty()); // SQL,不是真正的查询 session.getTransaction().commit();
session.close(); }
4.映射
多对一;一对多;多对多;一对一(多对一的特例);组件;继承
1)一对一映射
例如案例:用户和身份证信息
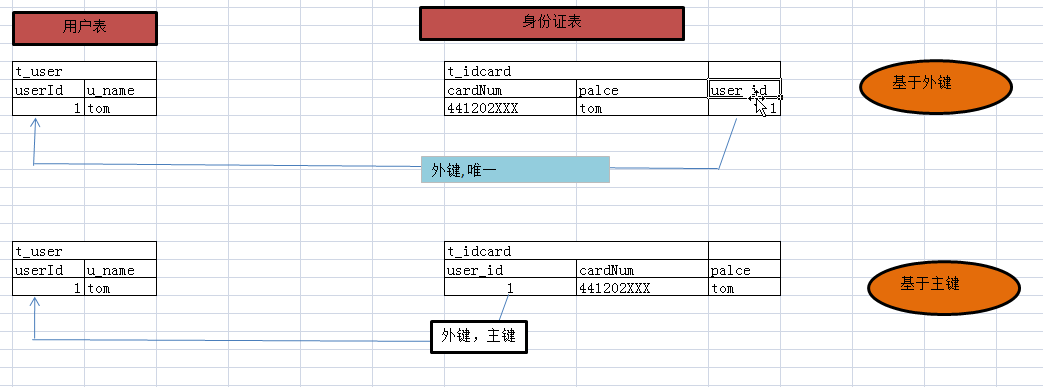
基于外键设计:
需要注意点:user对象的idcard属性:没有外键方只有主键方用<one-to-one name="idCard" class="IdCard"></one-to-one>
IdCard对象的user属性:有外键方用 <many-to-one name="user" column="user_id" class="User" unique="true" cascade="save-update"></many-to-one>
一对一是特殊的多对一:idCard的user_id外键对应唯一一个主键;
// 身份证
public class IdCard { // 身份证号(主键)
private String cardNum;// 对象唯一表示(Object Identified, OID)
private String place; // 身份证地址
// 身份证与用户,一对一的关系
private User user; // 用户
public class User { private int userId;
private String userName;
// 用户与身份证信息, 一对一关系
private IdCard idCard; <?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="cn.itcast.c_one2one"> <class name="IdCard" table="t_IdCard">
<id name="cardNum">
<generator class="assigned"></generator>
</id>
<property name="place" length=""></property> <!--
一对一映射,有外键方
unique="true" 给外键字段添加唯一约束
-->
<many-to-one name="user" unique="true" column="user_id" class="User" cascade="save-update"></many-to-one> </class> </hibernate-mapping> <?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="cn.itcast.c_one2one"> <class name="User" table="t_user">
<id name="userId">
<generator class="native"></generator>
</id>
<property name="userName" length=""></property>
<!--
一对一映射: 没有外键方
-->
<one-to-one name="idCard" class="IdCard"></one-to-one> </class> </hibernate-mapping>
基于主键设计:
需要注意点:主键是Icard表user_id是主键,也将是User表的外键
IdCard的主键user_id的设置:,并且需要给IdCard的user对象设置其外键约束<one-to-one name="user" class="User" constrained="true" cascade="save-update"></one-to-one>
User的配置就简单了idCard配置:<one-to-one name="idCard" class="IdCard"></one-to-one>
<id name="user_id">
<!--
id 节点指定的是主键映射, 即user_id是主键
主键生成方式: foreign 即把别的表的主键作为当前表的主键;
property (关键字不能修改)指定引用的对象 对象的全名 cn..User、 对象映射 cn.User.hbm.xml、 table(id)
-->
<!-- 这里讲user表的主键作为Idcard的外键 -->
<generator class="foreign">
<!-- 通过他能找到User表的主键 -->
<param name="property">user</param>
</generator>
</id>
// 身份证
public class IdCard { private int user_id;
// 身份证号
private String cardNum;
private String place; // 身份证地址
// 身份证与用户,一对一的关系
private User user; <?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="cn.itcast.c_one2one2"> <class name="IdCard" table="t_IdCard">
<id name="user_id">
<!--
id 节点指定的是主键映射, 即user_id是主键
主键生成方式: foreign 即把别的表的主键作为当前表的主键;
property (关键字不能修改)指定引用的对象 对象的全名 cn..User、 对象映射 cn.User.hbm.xml、 table(id)
-->
<generator class="foreign">
<param name="property">user</param>
</generator>
</id>
<property name="cardNum" length=""></property>
<property name="place" length=""></property> <!--
一对一映射,有外键方
(基于主键的映射)
constrained="true" 指定在主键上添加外键约束
-->
<one-to-one name="user" class="User" constrained="true" cascade="save-update"></one-to-one> </class> </hibernate-mapping>
2)组件映射,继承映射
类关系分为:组合关系:,继承关系;
1.组件映射:例如Car ,Wheel就属于组件映射
主要Car的映射配置:
<component name="wheel" class="Wheel"><property name="count"></property><property name="size"></property></component>
完整例子:
public class Car {
private int id;
private String name;
// 车轮
private Wheel wheel;
}
// 车轮
public class Wheel {
private int count;
private int size;
}
<hibernate-mapping package="cn.itcast.d_component">
<class name="Car" table="t_car">
<id name="id">
<generator class="native"></generator>
</id>
<property name="name" length=""></property>
<!-- 组件映射 -->
<component name="wheel">
<property name="size"></property>
<property name="count"></property>
</component>
</class>
</hibernate-mapping>
2.继承映射
1)简单继承映射:
直接写子类映射就可以了,父类的属性直接写上;
简单继承映射,有多少个子类,写多少个映射文件!
// 动物类
public abstract class Animal { private int id;
private String name; <!--
简单继承
-->
<hibernate-mapping package="cn.itcast.e_extends1"> <class name="Cat" table="t_Cat">
<!-- 简单继承映射: 父类属性直接写 -->
<id name="id">
<generator class="native"></generator>
</id>
<property name="name"></property>
<property name="catchMouse"></property>
</class> </hibernate-mapping> @Test
public void getSave() { Session session = sf.openSession();
session.beginTransaction(); // 保存
// Cat cat = new Cat();
// cat.setName("大花猫");
// cat.setCatchMouse("抓小老鼠");
// session.save(cat); // 获取时候注意:当写hql查询的使用,通过父类查询必须写上类的全名
Query q = session.createQuery("from cn.itcast.e_extends1.Animal");
List<Animal> list = q.list();
System.out.println(list); session.getTransaction().commit();
session.close(); }
2)复杂继承映射
需求:猫,狗,动物
1.所有子类映射到一张表
1)运用场景:子类较多只有个别属性;
2)好处缺点:只有一个映射文件,但是不符合数据库的设计原则
3)保存在数据库中的表样子:

4)配置文件:
<subclass name="Cat" discriminator-value="cat_">
每个子类节点都用subclass节点映射,discriminator-value鉴别器字段
<class name="Animal" table="t_animal">
<id name="id">
<generator class="native"></generator>
</id>
<!-- 指定鉴别器字段(区分不同的子类) -->
<discriminator column="type_"></discriminator> <property name="name"></property> <!--
子类:猫
每个子类都用subclass节点映射
注意:一定要指定鉴别器字段,否则报错!
鉴别器字段:作用是在数据库中区别每一个子类的信息, 就是一个列
discriminator-value="cat_"
指定鉴别器字段,即type_字段的值
如果不指定,默认为当前子类的全名
-->
<subclass name="Cat" discriminator-value="cat_">
<property name="catchMouse"></property>
</subclass> <!--
子类:猴子
-->
<subclass name="Monkey" discriminator-value="monkey_">
<property name="eatBanana"></property>
</subclass> </class>
2.每个类映射到一张表【3张表】
1)配置文件;
joined-subclass关键字表示子类
<class name="Animal" table="t_animal">
<id name="id">
<generator class="native"></generator>
</id>
<property name="name"></property> <!--
子类:猫 t_cat
key 指定_cat表的外键字段
-->
<joined-subclass name="Cat" table="t_cat">
<key column="t_animal_id"></key>
<property name="catchMouse"></property>
</joined-subclass> <!-- 子类:猴子 t_monkey -->
<joined-subclass name="Monkey" table="t_monkey">
<key column="t_animal_id"></key>
<property name="eatBanana"></property>
</joined-subclass> </class>
2)优点缺点:一个映射文件存储所有子类;子类父类都有映射;但表结构比较复杂,子类插入一条数据执行2条sql
3.(推荐)每个子类映射一张表,父类不对应表(2张表)
1)配置文件:
父类设置abstract="true"指定实体对象不对应表,即在数据库中不生成表
union-subclass节点存储子类
<!--
abstract="true" 指定实体类对象不对应表,即在数据库段不生成表
-->
<class name="Animal" abstract="true">
<!-- 如果用union-subclass节点,主键生成策略不能为自增长! -->
<id name="id">
<generator class="uuid"></generator>
</id>
<property name="name"></property> <!--
子类:猫 t_cat
union-subclass
table 指定为表名, 表的主键即为id列
-->
<union-subclass name="Cat" table="t_cat">
<property name="catchMouse"></property>
</union-subclass> <!-- 子类:猴子 t_monkey -->
<union-subclass name="Monkey" table="t_monkey">
<property name="eatBanana"></property>
</union-subclass> </class>
-------------------------------------------------------------------------------------------
1.hibernate查询
1)Get/load主键查询
Dept dept = (Dept) session.get(Dept.class, 12);
Dept dept = (Dept) session.load(Dept.class, 12);
2)对象导航查询
Dept dept = (Dept) session.get(Dept.class, 12);
System.out.println(dept.getDeptName());
System.out.println(dept.getEmps());
3)HQL查询Hibernate Query language hibernate 提供的面向对象的查询语言。
// 注意:使用hql查询的时候 auto-import="true" 要设置true,
如果是false,写hql的时候,要指定类的全名
Query q = session.createQuery("from Dept");
System.out.println(q.list());
查询的几种例子:函数查询,连接查询
// a. 查询全部列
// Query q = session.createQuery("from Dept"); //OK
// Query q = session.createQuery("select * from Dept"); //NOK, 错误,不支持*
// Query q = session.createQuery("select d from Dept d"); // OK
// System.out.println(q.list()); // b. 查询指定的列 【返回对象数据Object[] 】
// Query q = session.createQuery("select d.deptId,d.deptName from Dept d");
// System.out.println(q.list()); // c. 查询指定的列, 自动封装为对象 【必须要提供带参数构造器】
// Query q = session.createQuery("select new Dept(d.deptId,d.deptName) from Dept d");
// System.out.println(q.list()); // d. 条件查询: 一个条件/多个条件and or/between and/模糊查询
// 条件查询: 占位符
// Query q = session.createQuery("from Dept d where deptName=?");
// q.setString(0, "财务部");
// q.setParameter(0, "财务部");
// System.out.println(q.list()); // 条件查询: 命名参数
// Query q = session.createQuery("from Dept d where deptId=:myId or deptName=:name");
// q.setParameter("myId", 12);
// q.setParameter("name", "财务部");
// System.out.println(q.list()); // 范围
// Query q = session.createQuery("from Dept d where deptId between ? and ?");
// q.setParameter(0, 1);
// q.setParameter(1, 20);
// System.out.println(q.list()); // 模糊
// Query q = session.createQuery("from Dept d where deptName like ?");
// q.setString(0, "%部%");
// System.out.println(q.list()); // e. 聚合函数统计
// Query q = session.createQuery("select count(*) from Dept");
// Long num = (Long) q.uniqueResult();
// System.out.println(num); // f. 分组查询
//-- 统计t_employee表中,每个部门的人数
//数据库写法:SELECT dept_id,COUNT(*) FROM t_employee GROUP BY dept_id;
// HQL写法
// Query q = session.createQuery("select e.dept, count(*) from Employee e group by e.dept");
// System.out.println(q.list()); //1) 内连接 【映射已经配置好了关系,关联的时候,直接写对象的属性即可】
// Query q = session.createQuery("from Dept d inner join d.emps"); //2) 左外连接
// Query q = session.createQuery("from Dept d left join d.emps"); //3) 右外连接
Query q = session.createQuery("from Employee e right join e.dept");
q.list();
迫切连接
//1) 迫切内连接 【使用fetch, 会把右表的数据,填充到左表对象中!】
// Query q = session.createQuery("from Dept d inner join fetch d.emps");
// q.list(); //2) 迫切左外连接
Query q = session.createQuery("from Dept d left join fetch d.emps");
q.list();
HQL优化:HQL放到映射文件中
映射文件:
<!-- 存放sql语句 -->
<query name="getAllDept">
<![CDATA[
from Dept d where deptId < ?
]]> </query>
// HQL 放到映射文件中
Query q = session.getNamedQuery("getAllDept");
q.setParameter(, );
System.out.println(q.list());
4)Criteria查询,完全面向对象查询(Query By Criteria ,QBC)
Criteria criteria = session.createCriteria(Employee.class);
// 构建条件
criteria.add(Restrictions.eq("empId", ));
// criteria.add(Restrictions.idEq(12)); // 主键查询
5)SQLQuery本地查询
SQLQuery q = session.createSQLQuery("SELECT * FROM t_Dept limit 5;")
.addEntity(Dept.class); // 也可以自动封装
System.out.println(q.list());
6)分页:
Query q = session.createQuery("from Employee");
// 从记录数
ScrollableResults scroll = q.scroll(); // 得到滚动的结果集
scroll.last(); // 滚动到最后一行
int totalCount = scroll.getRowNumber() + ;// 得到滚到的记录数,即总记录数
// 设置分页参数
q.setFirstResult();
q.setMaxResults();
// 查询
System.out.println(q.list());
System.out.println("总记录数:" + totalCount);
2.Hibernate对连接池的支持
1)hibernate自带连接池和配置文件和c3p0配置
Hibernate 自带的也有一个连接池,且对C3P0连接池也有支持! Hbm 自带连接池:
只维护一个连接,比较简陋。
可以查看hibernate.properties文件查看连接池详细配置: #################################
### Hibernate Connection Pool ###
################################# hibernate.connection.pool_size 【Hbm 自带连接池: 只有一个连接】 ###########################
### C3P0 Connection Pool### 【Hbm对C3P0连接池支持】
########################### #hibernate.c3p0.max_size 最大连接数
#hibernate.c3p0.min_size 最小连接数
#hibernate.c3p0.timeout 超时时间
#hibernate.c3p0.max_statements 最大执行的命令的个数
#hibernate.c3p0.idle_test_period 空闲测试时间
#hibernate.c3p0.acquire_increment 连接不够用的时候, 每次增加的连接数
#hibernate.c3p0.validate false
2)如何选择自己的连接池:可以在Hibernate.cfg.xml中配置
<!-- 【连接池配置】 -->
<!-- 配置连接驱动管理类 -->
<property name="hibernate.connection.provider_class">org.hibernate.connection.C3P0ConnectionProvider</property>
<!-- 配置连接池参数信息 -->
<property name="hibernate.c3p0.min_size"></property>
<property name="hibernate.c3p0.max_size"></property>
<property name="hibernate.c3p0.timeout"></property>
<property name="hibernate.c3p0.max_statements"></property>
<property name="hibernate.c3p0.idle_test_period"></property>
<property name="hibernate.c3p0.acquire_increment"></property>
3.二级缓存
1)引入二级缓存i
一级缓存Session只在当前的有效,Sesssion关闭就会失效,而二级缓存作用了应用程序,可以跨越多个session
2)优点:享用二级缓存在配置文件中配置下就好,不想用删了就可以;也可以换成自己的缓存框架
3)配置二级缓存
hibernate.properties中对二级缓存的配置
##########################
### Second-level Cache ###
########################## #hibernate.cache.use_second_level_cache false【二级缓存默认不开启,需要手动开启】
#hibernate.cache.use_query_cache true 【开启查询缓存】 ## choose a cache implementation 【二级缓存框架的实现】 #hibernate.cache.provider_class org.hibernate.cache.EhCacheProvider
#hibernate.cache.provider_class org.hibernate.cache.EmptyCacheProvider
hibernate.cache.provider_class org.hibernate.cache.HashtableCacheProvider 默认实现
#hibernate.cache.provider_class org.hibernate.cache.TreeCacheProvider
#hibernate.cache.provider_class org.hibernate.cache.OSCacheProvider
#hibernate.cache.provider_class org.hibernate.cache.SwarmCacheProvider
二级缓存的使用步骤:
打开二级缓存-》选择缓存框架-》指定哪些类加入缓存-》测试
其中指定哪些类加入缓存可以用缓存策略:
HQL查询 【setCacheable 指定从二级缓存找,或者是放入二级缓存】
<class-cache usage="read-only"/> 放入二级缓存的对象,只读;
<class-cache usage="nonstrict-read-write"/> 非严格的读写
<class-cache usage="read-write"/> 读写; 放入二级缓存的对象可以读、写;
<class-cache usage="transactional"/> (基于事务的策略)
例子:
集合缓存:
<usage="read-wirte" collection="Dept.emps">集合缓存的元素对象也加入二级缓存
查询缓存:list()默认存入缓存不会存入一级,只能存入二级中
Hibernate.cfg.xml
<!--****************** 【二级缓存配置】****************** -->
<!-- a. 开启二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!-- b. 指定使用哪一个缓存框架(默认提供的) -->
<property name="hibernate.cache.provider_class">org.hibernate.cache.HashtableCacheProvider</property>
<!-- 开启查询缓存 -->
<property name="hibernate.cache.use_query_cache">true</property>
<!-- c. 指定哪一些类,需要加入二级缓存 -->
<class-cache usage="read-write" class="cn.itcast.b_second_cache.Dept"/>
<class-cache usage="read-only" class="cn.itcast.b_second_cache.Employee"/>
<!-- 集合缓存[集合缓存的元素对象,也加加入二级缓存] -->
<collection-cache usage="read-write" collection="cn.itcast.b_second_cache.Dept.emps"/> App 测试类 public class App { private static SessionFactory sf;
static {
sf = new Configuration()
.configure()
.addClass(Dept.class)
.addClass(Employee.class) // 测试时候使用
.buildSessionFactory();
}
// 1. 测试二级缓存的使用
// 没有/有用 二级缓存
@Test
public void testCache() {
Session session1 = sf.openSession();
session1.beginTransaction();
// a. 查询一次
Dept dept = (Dept) session1.get(Dept.class, );
dept.getEmps().size();// 集合
session1.getTransaction().commit();
session1.close(); System.out.println("------"); // 第二个session
Session session2 = sf.openSession();
session2.beginTransaction();
// a. 查询一次
dept = (Dept) session2.get(Dept.class, ); // 二级缓存配置好; 这里不查询数据库
dept.getEmps().size(); session2.getTransaction().commit();
session2.close();
} @Test
public void listCache() {
Session session1 = sf.openSession();
session1.beginTransaction();
// HQL查询 【setCacheable 指定从二级缓存找,或者是放入二级缓存】
Query q = session1.createQuery("from Dept").setCacheable(true);
System.out.println(q.list());
session1.getTransaction().commit();
session1.close(); Session session2 = sf.openSession();
session2.beginTransaction();
q = session2.createQuery("from Dept").setCacheable(true);
System.out.println(q.list()); // 不查询数据库: 需要开启查询缓存
session2.getTransaction().commit();
session2.close();
}
}
4)Session的管理方式:
可以sf.openSession()方式创建;
可以通过线程的方式创建 :首先要在配置文件中配置:
<property name="hibernate.current_session_context_class">thread</property>
之后:通过sf.getCurrentSession()获得当前的线程的session或者存入session
@Test
public void testSession() throws Exception {
//openSession: 创建Session, 每次都会创建一个新的session
Session session1 = sf.openSession();
Session session2 = sf.openSession();
System.out.println(session1 == session2);
session1.close();
session2.close(); //getCurrentSession 创建或者获取session
// 线程的方式创建session
// 一定要配置:<property name="hibernate.current_session_context_class">thread</property>
Session session3 = sf.getCurrentSession();// 创建session,绑定到线程
Session session4 = sf.getCurrentSession();// 从当前访问线程获取session
System.out.println(session3 == session4); // 关闭 【以线程方式创建的session,可以不用关闭; 线程结束session自动关闭】
//session3.close();
//session4.close(); 报错,因为同一个session已经关闭了!
}
4.Hibernate与struts小案例
java深入探究12-框架之Hibernate的更多相关文章
- 轻量级Java持久化框架,Hibernate完美助手,Minidao 1.6.2版本发布
Minidao 1.6.2 版本发布,轻量级Java持久化框架(Hibernate完美助手) Minidao产生初衷? 采用Hibernate的J2EE项目都有一个痛病,针对复杂业务SQL,hiber ...
- Java - Struts框架教程 Hibernate框架教程 Spring框架入门教程(新版) sping mvc spring boot spring cloud Mybatis
https://www.zhihu.com/question/21142149 http://how2j.cn/k/hibernate/hibernate-tutorial/31.html?tid=6 ...
- 框架之 hibernate之二
1. Hibernate持久化对象的状态 2. Hibernate的一级缓存 3. Hibernate操作持久化对象的方法 4. Hibernate的基本查询 Hibernate的持久化类 什么是持久 ...
- 三大框架 之 Hibernate框架概述(概述、配置、核心API)
目录 Hibernate框架概述 什么是框架 hibernate简介(JavaEE技术三层架构所用到的技术) hibernate是什么框架 ORM hibernate好处 Hibernate基本使用 ...
- 【Java EE 学习 44】【Hibernate学习第一天】【Hibernate对单表的CRUD操作】
一.Hibernate简介 1.hibernate是对jdbc的二次开发 2.jdbc没有缓存机制,但是hibernate有. 3.hibernate的有点和缺点 (1)优点:有缓存,而且是二级缓存: ...
- [原创]java WEB学习笔记81:Hibernate学习之路--- 对象关系映射文件(.hbm.xml):hibernate-mapping 节点,class节点,id节点(主键生成策略),property节点,在hibernate 中 java类型 与sql类型之间的对应关系,Java 时间和日期类型的映射,Java 大对象类型 的 映射 (了解),映射组成关系
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- [原创]java WEB学习笔记76:Hibernate学习之路---Hibernate介绍,hibernate 环境的搭建
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- Java 集合系列 12 TreeMap
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java知识总结--三大框架
1 应用服务器有哪些:weblogic,jboss,tomcat 2 Hibernate优于JDBC的地方 1)对jdbc访问数据库进行了封装,简化了数据访问层的重复代码 2)Hibernate 操作 ...
随机推荐
- iOS学习笔记(十)——iOS真机调试
前面一直使用模拟器运行,今天使用了真机调试,这一篇介绍一下真机调试.真机调试需要99$注册,如果有注册过的账号,也可以使用注册账号邀请你加入一个账号下,注册账号可以给你分配权限,我也是使用的邀请成为开 ...
- influxDB选择类函数
1)TOP()函数 作用:返回一个字段中最大的N个值,字段类型必须是长整型或float64类型. 语法: SELECT TOP(<field_key>[,<tag_keys>] ...
- jquery,日常 记录知识 点 (选择器的引用类型)
1.标签引用$("p").$("input")例子 $("p").append( $("input").map(func ...
- 禁止向 HTML 页面输出未经安全过滤或未正确转义的用户数据。
https://github.com/alibaba/p3c/blob/master/阿里巴巴Java开发手册(详尽版).pdf 5. [强制]禁止向 HTML 页面输出未经安全过滤或未正确转义的用户 ...
- <2013 08 17> BucketList of girlfriend
BucketList of girlfriend 1.出国旅游 2.跟相爱的人结婚,生个健康可爱的孩子 3.说一口流利的英语 4.学素描和水彩 5.买个雅马哈钢琴,偶尔学着弹一首曲子 6.把泪腺堵住 ...
- Java线程的5种状态及切换
ava中的线程的生命周期大体可分为5种状态. 1. 新建(NEW):新创建了一个线程对象. 2. 可运行(RUNNABLE):线程对象创建后,其他线程(比如main线程)调用了该对象的start()方 ...
- 基础篇-java开发
开局必知 1.变量 在java中,以{}为作用域,所以就存在成员变量和局部变量之说 由于java是强类型语言,所以在申明变量的时候,必须指定类型 java里,一个变量有声明过程和初始化过程(也就是赋值 ...
- pymysql连接数据库,实现数据库增删改查
1.数据库连接 # 创建连接 def create_conn(): import pymysql conn = pymysql.connect( host='localhost', port=3306 ...
- Js全局异常捕获
重新window.onerror方法就行了 window.onerror = handleError function handleError(msg,url,l) { var txt="T ...
- 1.3 使用电脑测试MC20的电话语音功能
需要准备的硬件 MC20开发板 1个 https://item.taobao.com/item.htm?id=562661881042 GSM/GPRS天线 1根 https://item.taoba ...