Paper: ImageNet Classification with Deep Convolutional Neural Network
本文介绍了Alex net 在imageNet Classification 中的惊人表现,获得了ImagaNet LSVRC2012第一的好成绩,开启了卷积神经网络在cv领域的广泛应用。
1.数据集
ImageNet [6], which consists of over 15 million labeled high-resolution images in over 22,000 categories.
here,ILSVRC uses a subset of ImageNet with roughly 1000 images in each of 1000 categories. In all, there are roughly 1.2 million training images, 50,000 validation images, and
150,000 testing images.我们在这从ImageNet 中生成一个1000类,每类大约1000张图片,即大约120万个训练样例,50000个验证样例,150,000个测试样例。
ImageNet consists of variable-resolution images, while our system requires a constant input dimensionality. Therefore, we down-sampled the images to a fixed resolution of 256 × 256. Given a
rectangular image, we first rescaled the image such that the shorter side was of length 256, and then cropped out the central 256×256 patch from the resulting image. We did not pre-process the images
in any other way, except for subtracting the mean activity over the training set from each pixel. So we trained our network on the (centered) raw RGB values of the pixels.
2.网络架构 The architecture of our network is summarized in Figure 2. It contains eight learned layers —five convolutional and three fully-connected
2.1 activation function
using RELU Nonlinearity,The standard way to model a neuron’s output f as
a function of its input x is with f (x) = tanh(x) or f (x) = (1 + e −x ) −1 . In terms of training time
with gradient descent, these saturating nonlinearities are much slower than the non-saturating nonlinearity f (x) = max(0, x).
Deep convolutional neural networks with ReLUs train several times faster than their equivalents with tanh units.
2.2 Training on Multiple GPUs
2.3 Local Response Normalization
2.4 Overlapping Pooling
Pooling layers in CNNs summarize the outputs of neighboring groups of neurons in the same kernel map. Traditionally, the neighborhoods summarized by adjacent pooling units do not overlap (e.g.,
[17, 11, 4]). To be more precise, a pooling layer can be thought of as consisting of a grid of pooling units spaced s pixels apart, each summarizing a neighborhood of size z × z centered at the location
of the pooling unit. If we set s = z, we obtain traditional local pooling as commonly employed in CNNs. If we set s < z, we obtain overlapping pooling. This is what we use throughout our
network, with s = 2 and z = 3. This scheme reduces the top-1 and top-5 error rates by 0.4% and 0.3%, respectively, as compared with the non-overlapping scheme s = 2, z = 2, which produces
output of equivalent dimensions. We generally observe during training that models with overlapping pooling find it slightly more difficult to overfit.
当池化窗口的大小为z*z时,如果stride<z ,则进行Overlapping pooling,如果stride=z ,则进行一般的池化操作
2.5 Overall Architectur
Now we are ready to describe the overall architecture of our CNN. As depicted in Figure 2, the net contains eight layers with weights; the first five are convolutional and the remaining three are fully-
connected. The output of the last fully-connected layer is fed to a 1000-way softmax which produces a distribution over the 1000 class labels. Our network maximizes the multinomial logistic regression
objective, which is equivalent to maximizing the average across training cases of the log-probability of the correct label under the prediction distribution. The kernels of the second, fourth, and fifth convolutional
layers are connected only to those kernel maps in the previous layer which reside on the same GPU (see Figure 2). The kernels of the third convolutional layer are connected to all kernel maps in the second layer.
The neurons in the fully-connected layers are connected to all neurons in the previous layer. Response-normalization layers follow the first and second convolutional layers. Max-pooling layers, of the kind described in Section
3.4, follow both response-normalization layers as well as the fifth convolutional layer. The ReLU non-linearity is applied to the output of every convolutional and fully-connected layer.
The first convolutional layer filters the 224 × 224 × 3 input image with 96 kernels of size 11 × 11 × 3with a stride of 4 pixels (this is the distance between the receptive field centers of neighboring
neurons in a kernel map). The second convolutional layer takes as input the (response-normalized and pooled) output of the first convolutional layer and filters it with 256 kernels of size 5 × 5 × 48.
The third, fourth, and fifth convolutional layers are connected to one another without any intervening pooling or normalization layers. The third convolutional layer has 384 kernels of size 3 × 3 ×
256 connected to the (normalized, pooled) outputs of the second convolutional layer. The fourth convolutional layer has 384 kernels of size 3 × 3 × 192 , and the fifth convolutional layer has 256
kernels of size 3 × 3 × 192. The fully-connected layers have 4096 neurons each.

3.降低overfitting
3.1 数据增广
The easiest and most common method to reduce overfitting on image data is to artificially enlarge the dataset using label-preserving transformations (e.g., [25, 4, 5]). We employ two distinct forms
of data augmentation, both of which allow transformed images to be produced from the original images with very little computation, so the transformed images do not need to be stored on disk.
In our implementation, the transformed images are generated in Python code on the CPU while the GPU is training on the previous batch of images. So these data augmentation schemes are, in effect,
computationally free.
The first form of data augmentation consists of generating image translations and horizontal reflections. We do this by extracting random 224 × 224 patches (and their horizontal reflections) from the
256×256 images and training our network on these extracted patches 4 . This increases the size of our training set by a factor of 2048, though the resulting training examples are, of course, highly inter-
dependent. Without this scheme, our network suffers from substantial overfitting, which would have forced us to use much smaller networks. At test time, the network makes a prediction by extracting
five 224 × 224 patches (the four corner patches and the center patch) as well as their horizontal reflections (hence ten patches in all), and averaging the predictions made by the network’s softmax
layer on the ten patches. The second form of data augmentation consists of altering the intensities of the RGB channels in training images. Specifically, we perform PCA on the set of RGB pixel values throughout the
ImageNet training set. To each training image, we add multiples of the found principal components,with magnitudes proportional to the corresponding eigenvalues times a random variable drawn from
a Gaussian with mean zero and standard deviation 0.1.
3.2 dropout
Combining the predictions of many different models is a very successful way to reduce test errors[1, 3], but it appears to be too expensive for big neural networks that already take several days
to train. There is, however, a very efficient version of model combination that only costs about a factor of two during training. The recently-introduced technique, called “dropout” [10], consists
of setting to zero the output of each hidden neuron with probability 0.5. The neurons which are “dropped out” in this way do not contribute to the forward pass and do not participate in back-
propagation. So every time an input is presented, the neural network samples a different architecture, but all these architectures share weights. This technique reduces complex co-adaptations of neurons,
since a neuron cannot rely on the presence of particular other neurons. It is, therefore, forced to
learn more robust features that are useful in conjunction with many different random subsets of the other neurons. At test time, we use all the neurons but multiply their outputs by 0.5, which is a
reasonable approximation to taking the geometric mean of the predictive distributions produced by the exponentially-many dropout networks.
We use dropout in the first two fully-connected layers of Figure 2. Without dropout, our network exhibits substantial overfitting. Dropout roughly doubles the number of iterations required to converge.
4. Learning details
We trained our models using stochastic gradient descent with a batch size of 128 examples, momentum of 0.9, and
weight decay of 0.0005. We found that this small amount of weight decay was important for the model to learn. In
other words, weight decay here is not merely a regularizer: it reduces the model’s training error. The update rule for
weight w was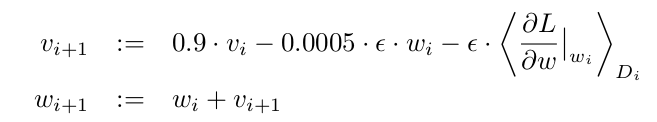


5 . Results
Paper: ImageNet Classification with Deep Convolutional Neural Network的更多相关文章
- 1 - ImageNet Classification with Deep Convolutional Neural Network (阅读翻译)
ImageNet Classification with Deep Convolutional Neural Network 利用深度卷积神经网络进行ImageNet分类 Abstract We tr ...
- ImageNet Classification with Deep Convolutional Neural Network(转)
这篇论文主要讲了CNN的很多技巧,参考这位博主的笔记:http://blog.csdn.net/whiteinblue/article/details/43202399 https://blog.ac ...
- 论文笔记《ImageNet Classification with Deep Convolutional Neural Network》
一.摘要 了解CNN必读的一篇论文,有些东西还是可以了解的. 二.结构 1. Relu的好处: 1.在训练时间上,比tanh和sigmod快,而且BP的时候求导也很容易 2.因为是非饱和函数,所以基本 ...
- [notes] ImageNet Classification with Deep Convolutional Neual Network
Paper: ImageNet Classification with Deep Convolutional Neual Network Achievements: The model address ...
- AlexNet论文翻译-ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 深度卷积神经网络的ImageNet分类 Alex Krizhevsky ...
- 中文版 ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 摘要 我们训练了一个大型深度卷积神经网络来将ImageNet LSVRC ...
- 《ImageNet Classification with Deep Convolutional Neural Networks》 剖析
<ImageNet Classification with Deep Convolutional Neural Networks> 剖析 CNN 领域的经典之作, 作者训练了一个面向数量为 ...
- ImageNet Classification with Deep Convolutional Neural Networks(译文)转载
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geo ...
- [论文阅读] ImageNet Classification with Deep Convolutional Neural Networks(传说中的AlexNet)
这篇文章使用的AlexNet网络,在2012年的ImageNet(ILSVRC-2012)竞赛中获得第一名,top-5的测试误差为15.3%,相比于第二名26.2%的误差降低了不少. 本文的创新点: ...
随机推荐
- 系列文章--WCF后传学习文章
WCF后传系列(10):消息处理功能核心 摘要: WCF是一个通信框架,同时也可以将它看成是一个消息处理或者传递的基础框架,它可以接收消息.对消息做处理,或者根据客户端给定的数据构造消息并将消息发送到 ...
- python 函数 hex()
hex(x)作用:hex() 函数用于将10进制整数转换成16进制整数. x-10进制整数,返回16进制整数 实例: >>>hex(255) '0xff' >>> ...
- npm包的发布
假设该待发布包在你本地的项目为 project1 包的本地安装测试 在发布之前往往希望在本地进行安装测试.那么需要一个其他的项目来本地安装待发布项目. 假设该其他项目为project2.假设proje ...
- php时间 显示刚刚 几分钟前等
功能示例: $now = time();foreach($sys_res as $k => $v){ $day = intval(floor(($now - $v->system_time ...
- CodeReview是开发中的重要一个环节,整理了一些关于jupiter for java
什么是代码评审(CodeReview)? 代码评审也称代码复查,是指通过阅读代码来检查源代码与编码标准的符合性以及代码质量的活动. Jupiter提供了代码行级别的评审批注功能,方便评审参与人了解具体 ...
- MVVM模式下 修改 store的ajax请求url。
MVVM模式下 修改 store的ajax请求url. view.down('Pro').getViewModel().getStore('xx_store').proxy.url = "s ...
- MYSQL数据库索引类型都有哪些?
索引类型: B-TREE索引,哈希索引•B-TREE索引加速了数据访问,因为存储引擎不会扫描整个表得到需要的数据.相反,它从根节点开始.根节点保存了指向子节点的指针,并且存储引擎会根据指针寻找数据.它 ...
- Java-Runoob:Java 基本数据类型
ylbtech-Java-Runoob:Java 基本数据类型 1.返回顶部 1. Java 基本数据类型 变量就是申请内存来存储值.也就是说,当创建变量的时候,需要在内存中申请空间. 内存管理系统根 ...
- xml处理模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的 ...
- mysql锁,事务
什么是事务 事务定义了一个服务操作序列,由服务器保证这些操作序列在多个客户并发访问和服务器出现故障情况下的原子性事务的属性 A --redo&undo C --undo I --lock D ...