C++ 基础知识回顾(I/O)
[1] I/O基础
大多数计算机语言的输入输出的实现都是以语言本身为基础的,但是C/C++没有这样做。C语言最初把I/O留给了编译器实现人员。这样做的一个原因是可以提供足够的自由度,使之最适合目标机器的硬件条件。但是大多数实现人员都将I/O建立在了Unix库函数中,之后C才将该库引入了C标准中,被C++继承了下来。
但是C++也有自己的I/O解决方案,将其定义于iostream和fstream中。这两个库不是语言的组成部分,只是定义了一些类而已。
C++把输入和输出看作字节流。对于面向文本的程序,一个字节代表一个字符。流充当了源于目标之间的桥梁,因此对流的管理包含两个方面:从哪里来,到哪里去。其中,缓冲区作为临时存储空间,可以提高流处理的速度。
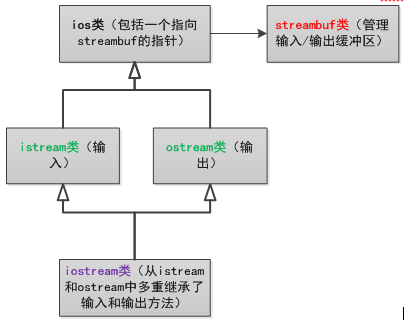
C++中专门定义了一些类来管理流和缓冲区:
C++98定义了一些模板类,用以支持char和wchar_t类型;
C++ 11添加了char16_t和char32_t类型(实则就是一些typedef来模拟不同的类型)。
C++程序中若包含了iostream类库,则自动创建8个流对象:4个窄的,4个宽的:
cin: 标准输入流,默认关联到键盘[与之对应的宽型为wcin(处理wchar_t)];
cout: 标准输出流,默认关联到显示器[与之对应的宽型为wcout(处理wchar_t)];
cerr: 标准错误输出流,默认关联到显示器,这个流没有缓冲区,意味着信息会直接发送到显示器[与之对应的宽型为wcerr(处理wchar_t)];
clog: 标准错误输出流,默认也关联到显示器,但是这个流对应着缓冲区[与之对应的宽型为wclog(处理wchar_t)]。
[1.1] cout 的使用
C++将输出看作是字节流(可能是8位/16位/32位),但在将字节流发送给屏幕时,希望每个字节表示一个字符值。比如,要显示-2.34,需要5个字符表示,分别为-/2/./3/4,并不是这个值的浮点数表示形式。因此,ostream类的最重要的任务之一就是将数值类型转换为文本形式表示的字符流。为了达到这个目标,C++使用了如下方法:
重载的<<运算符:C++的重载操作除了基本的内置类型,还有如下几种:const signed char*/const unsigned char*/const char*/void*。
对于其他类型的指针,C++将其看作void*,然后打印地址的数值。如果要想获得字符串的地址,必须将其强转为void*类型。
ostream类的put()和write()方法,前者用于显示字符,后者用于显示字符串。
ostream& put(char);
// cout.put(‘B’).put(‘T’);
basic_ostream<charT, traits>& write(const char_type* s, streamsize n);
// write()的第一个参数是要显示的字符串的地址,第二个参数是要显示字符个数。
const char* name = "benxintuzi";
for(int i = ; i <= strlen(name); i++)
{
cout.write(name, i);
cout << endl;
} /** output */
b
be
ben
benx
benxi
benxin
benxint
benxintu
benxintuz
benxintuzi
说明:
write()方法不会在遇到空白字符就停止打印,而是打印指定数目的字符,即使超出了字符串的边界。write()也可将数字转换为相应的形式打印,此时需要将数字的地址转换为char*,但是不会打印字符,而是内存中表示数值的位,可能是乱码,这个再正常不过了。
由于ostream类对数据进行了缓冲,因此利用cout也许并不会立即得到输出,而是被存储在缓冲区中,直至缓冲区填满为止。通常,缓冲区大小为512字节及其整数倍。如果需要将尚未填满的缓冲区进行刷新操作,需要执行如下代码:
cout << flush; // 立即刷新
或者:
cout << endl; // 立即刷新并插入换行符
控制数值显示的格式:
dec/hex/oct,虽然这些都是函数,但是其通常的使用方式是:
cout << hex;
cout << value << endl;
使用width成员函数将不同的字段放到宽度相同的字段中:有两个函数版本:
int width()/int width(int i);
第一个返回当前字段所占的空格数;
第二个函数将宽度设置为i个空格后,返回旧的空格数。但是注意:该函数只影响紧挨着它的一项显示输出,然后将字段宽度恢复为默认值。
说明:
C++不会截断数据,比如如果在宽度为2的字段中打印7位的值,那么该字段将被增大,C++的原则是:内容比形式更重要。
默认情况下,C++的对其方式为右对齐,并且默认的填充字符是空格。可以使用fill()成员函数来更改填充字符,例如:cout.fill(‘*’);
string birth("");
cout.width();
cout << birth << endl;
cout.fill('*');
cout.width();
cout << birth << endl;
/** output */
************
默认情况下,浮点数的显示精度指的是总位数;
在定点模式和科学模式下,指的是小数点后的位数;
C++默认的精度为6位,并且末尾的0不显示。可以使用cout.precision(int)设置精度的位数,一旦设置,直到第二次设置前永远有效。
对于有些输出,必须保留末尾的0,此时需要借助于ios_base类中的setf()函数:cout.setf(ios_base::showpoint);
为了简化格式设置工作,C++专门提供了一个工具(头文件<iomanip>),3个最常用的格式控制符分别为:setprecision()、setfill()、setw(),分别用来设置精度、填充字符、字段宽度。
for(int i = ; i <= ; i++)
{
cout << setw() << i << setw() << i * << endl;
} /** output */
[1.2] cin 的使用
cin对象将标准输入表示为字节流,通常情况下,键盘生成的是字符流,cin根据接受值的变量的类型,将字符序列转换为所需的类型。
再次强调:C++解释输入的方式取决于变量的数据类型。istream类重载了>>,可以识别如下基本类型:
signed char&/unsigned char&/char&/short&/unsigned short&/int&/unsigned int&/long&/unsigned&/long long&/unsigned long long&/float&/double&/long double&。
除此之外,还支持:
signed char*/char*/unsigned char*。
[1.3] 流状态
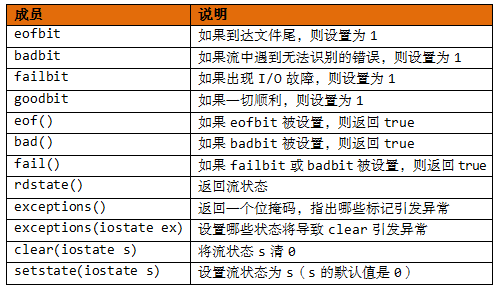
cin和cout对象各自包含一个描述流状态的数据成员(从ios_base中继承的)。流状态被定义为iostate类型,实则是bitmask类型,由3个ios_base元素组成:eofbit/badbit/failbit。其中每个元素都是一位:
当cin到达文件末尾时,置位eofbit;
当cin未能读取到预期的字符时,置位badbit;
当I/O故障失败时,置位failbit。
当全部三个状态位设置为0时,说明一切顺利。程序可以根据当前的流状态决定下一步的动作。
[1.4] 字符的输入
首先应该确定是否希望跳过空白符,希望跳过空白则选择>>;如果希望检查输入的每个字符,则使用get(void)或者get(char&)。如果要将标准C程序改写为C++程序,可以使用cin.get()替换getchar(), 使用cin.put(ch)替换putchar(ch)。
字符串输入函数getline()、get()、ignore():
|
istream& get(char*, int, char); istream& get(char*, int); istream& getline(char*, int, char); istream& getline(char*, int); 其中: char*: 存放字符串的内存单元地址; int: 内存单元大小(比字符串长度大1,用于存放’\0’); char: 指定分界符。 例如,将字符串读入字符数组line中: char line[50]; cin.get(line, 50); 读取时,get将在到达第49个字符或者遇到换行符后停止从流中读取字符,其在中途若遇到流中的换行符,那么将其留在流中不予处理,下一次读取时,首先看到的仍然是换行符;而getline则会将遇到的换行符读取出来并丢弃掉,这样流中就没有换行符了。 cin.ignore(255, ‘\n’)表示即将读取接下来的255个字符并且丢弃掉或者遇到分界符\n后停止读取操作,其默认形式为:istream& ignore(int = 1, int = EOF)。 |
#include <iostream>
#include <cstring>
#include <iomanip>
using namespace std; const int Limit = ; int main()
{
char input[Limit]; cout << "Enter a string for getline() processing: ";
cin.getline(input, Limit, '#'); // 丢弃流中的# cout << "Here is your input: ";
cout << input << "\nDone with phase 1" << endl; char ch;
cin.get(ch); // 读取到的字符为#后边的第一个字符
cout << "The next input character is: " << ch << endl;
if(ch != '\n')
cin.ignore(Limit, '\n'); cout << "Enter a string for get() processing: ";
cin.get(input, Limit, '#'); // 保存流中的# cout << "Here is your input: ";
cout << input << "\nDone with phase 2" << endl; cin.get(ch); // 读取到的字符为#
cout << "The next input character is: " << ch << endl; return ;
} /** output */
Enter a string for getline() processing: I love tu#zi !
Here is your input: I love tu
Done with phase
The next input character is: z
Enter a string for get() processing: I love tu#zi !
Here is your input: I love tu
Done with phase
The next input character is: #
除了前面介绍的方法外,其他的istream方法还包括read()/peek()/gcount()/putback()等:
|
read()读取指定数目的字节并存储到指定的位置,如: char gross[100]; cin.read(gross, 100); 说明: 与get和getline不同,read不会在输入后加上’\0’,因此,不能将输入转换为字符串。Read常与ostream write()函数结合使用,完成文件的输入和输出。返回类型为istream&。 peek()函数返回输入中的下一个字符,但是不去读下一个字符,也就是说可以用来作为检查流的作用,以此来判断是否还要继续读取: char gross[80]; char ch; int i = 0; while((ch = cin.peek()) != ‘\n’) cin.get(gross[i++]); gross[i] = ‘\0’; gcount()返回最后一个非格式化方法读取的字符个数,意味着get()/ getline()/ ignore()/ read()方法读取的字符个数。实际中用的不多,可以用strlen()代替。 putback()方法将一个字符退回到流中,以便下一次读取。该方法返回一个istream&。使用peek()的效果相当于先使用一个get()读取一个字符,然后使用putback()将该字符退回到流中去。当然,putback()也可将字符放置在流中的其他位置。 |
#include <iostream>
using namespace std; int main()
{
char ch; while(cin.get(ch))
{
if(ch != '#')
cout << ch;
else
{
cin.putback(ch);
break;
}
}
if(!cin.eof())
{
cin.get(ch);
cout << endl << ch << "is the next input character." << endl;
}
else
{
cout << "End of file reached." << endl;
} while(cin.peek() != '#')
{
cin.get(ch);
cout << ch;
}
if(!cin.eof())
{
cin.get(ch);
cout << endl << ch << "is the next input character." << endl;
}
else
{
cout << "End of file reached." << endl;
} return ;
} /** output */
I love #tuzi and I am #benxin.
I love
#is the next input character.
tuzi and I am
#is the next input character.
[2] 文件I/O
文件类的I/O与基本I/O非常相似,其相关类派生自iostream类,只是要操作文件,还必须将文件与流进行关联起来。
[2.1] 文件I/O基础
要让程序写文件,必须进行如下操作:
1 创建一个ofstream对象管理输出流:ofstream fout;
2 将该对象与特定文件关联起来:fout.open(“jar.txt”)【如果jar.txt不存在,那么会自动创建它】;
3 将内容写入文件中去:fout << “benxintuzi test”;
要完成上述任务,首先包含头文件fstream, 由于fstream中的类大多派生自iostream中的类,因此,fstream必然包含了iostream,因此,包含头文件fstream后不必再显式包含iostream了。
说明:
可以在创建流的同时关联文件:ofstream fout(“jar.txt”);
以上述这种默认模式打开文件时,如果文件不存在,则自动创建该文件;若文件存在,则自动将文件清空,然后再写入新内容。
程序读文件流程类似:
ifstream fin;
fin.open("jayne.txt");
char buf[50];
fin.getline(buf, 50); // 读入一行内容
cout << buf << endl;
虽然程序结束时会自动关闭流,但是最好显式关闭,如下:
fout.close();
fin.close();
关闭流并不是删除流,只是将断开流与文件的关联性。这样就可以重新将该流关联到另一个文件中。
[2.2] 流状态检查
C++文件流类从ios_base类继承了一个表示流状态的成员以及报告流状态的方法。可以通过这些方法判断流操作是否成功。比如检查打开文件是否成功,可以如下:
fin.open(“***”);
if(fin.fail())
或者:
fin.open(“***”);
if(!fin)
或者利用C++提供的新方法:
if(!fin.is_open())
说明:
if(fin.fail())、if(!fin.good())、if(!fin)...是等价的。但是如果以不合适的文件模式打开文件失败时,这些方法将不会检测出来。相比之下,is_open()却可以检测到这种错误。
在打开多个文件时,常理来说需要为每个文件关联一个流对象,然而为了节约系统资源,可以创建一个流,然后分别关联到不同的文件中。
文件模式描述的是打开的文件将被如何使用:读、写、追加等。
ifstream fin(“jar.txt”, model);
ofstream fout;
fout.open(“jar.txt”, model);
ios_base类定义了一个openmode类型,用来表示模式。与fmtflags和iostate类型一样,它也是一个bitmask类型。可以选择ios_base类中定义的多个常量来指定模式:
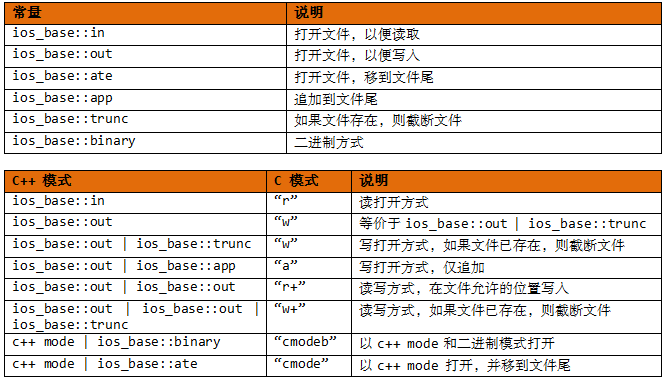
说明:
ios_base::ate和ios_base::app都将文件指针指向打开的文件尾,二者的区别在于:ios_base::app模式只允许将数据添加到文件尾,而ios_base::ate模式将指针放到文件尾。
追加文件示例:
#include <iostream>
#include <fstream>
#include <string>
#include <cstdlib> using namespace std; const char* file = "append.txt"; int main()
{
// show the initial contents
ifstream fin;
fin.open(file);
if(fin.is_open())
{
cout << "The contents of " << file << " is: " << endl;
char ch;
while(fin.get(ch))
cout << ch;
fin.close();
} // add new contents to the end of file
ofstream fout(file, ios::out | ios::app);
if(!fout.is_open())
{
exit(EXIT_FAILURE);
}
else
{
cout << "Enter your contents to be added: ";
string contents;
while(getline(cin, contents) && contents.size() > )
fout << contents << endl;
fout.close();
} // show revised file
fin.clear();
fin.open(file);
if(fin.is_open())
{
cout << "The contents of " << file << " is: " << endl;
char ch;
while(fin.get(ch))
cout << ch;
fin.close();
}
cout << endl << "Done !" << endl; return ;
} /** output */
The contents of append.txt is:
This is line
This is line
This is line
Enter your contents to be added: I love tuzi
So you can guess The contents of append.txt is:
This is line
This is line
This is line
I love tuzi
So you can guess Done !
说明:
以二进制读写文件时,请使用write和read方式。
[2.3] 随机存取文件
随机存取常被用于数据库文件中,可以根据索引操作数据项。
在文件中移动指针:
seekg(): 将输入指针移到指定的位置;
seekp(): 将输出指针移到指定的位置。
说明:
其实由于fstream类使用缓冲区来存储中间数据,因此指针指向的是缓冲区的位置,而不是真正的文件中的位置。
检查文件指针的当前位置:
对于输入流,使用tellg();
对于输出流,使用tellp();
它们都返回一个表示当前位置距离起始位置的偏移量,单位为字节。
在系统中需要创建临时文件时,可以使用cstdio中的char* tmpnam(char* pszName)函数,该函数可以生成TMP_NAM个不同的临时文件名,其中每个文件名包含的字符不超过L_tmpnam个。
#include <cstdio>
#include <iostream> using namespace std; int main()
{
char pszName[L_tmpnam] = {'\0'};
cout << "10 temp file names are follows: " << endl;
for(int i = ; i < ; i++)
{
tmpnam(pszName);
cout << pszName << " ";
}
cout << endl; return ;
} /** output */
temp file names are follows:
\s4ic. \s4ic. \s4ic. \s4ic. \s4ic. \s4ic. \s4ic. \s4ic. \s4ic. \s4ic.
[2.4] 内核格式化
iostream提供程序与终端之间的I/O;
fstream提供程序和文件之间的I/O;
sstream提供程序和string对象之间的I/O。
读取string对象中的格式化信息或者将格式化的信息写入到string对象中被称为内核的格式化(incore formatting):
sstream类定义了一个从ostream类派生而来的ostringstream类,当创建了一个ostringstream对象时,就可以将信息写入其中。该对象使用动态内存分配来增大缓冲区。ostringstream类有一个名为str()的成员函数,该函数返回一个被初始化为缓冲区内容的string对象。
string mesg = outstr.str();
注意:使用str()方法后不能再对ostringstream对象进行写操作。
与之相对的有istringstream类。
#include <iostream>
#include <sstream>
#include <string>
using namespace std; int main()
{
ostringstream outstr; // 管理一个string流
string name;
cout << "What's the name of your hard disk ? : ";
getline(cin, name);
cout << "What's the capacity in GB ? : ";
int cap;
cin >> cap; outstr << "The name is : " << name << ", and the capacity is " << cap << " GB." << endl;
string str = outstr.str(); // <11111>
cout << "<11111>" << endl;
cout << str << endl; // <22222>
cout << "<22222>" << endl;
istringstream instr(str);
string word;
while(instr >> word) // read a word every a time
cout << word << endl; return ;
} /** output */
What's the name of your hard disk ? : TOSHIBA
What's the capacity in GB ? : 320
<>
The name is : TOSHIBA, and the capacity is GB. <>
The
name
is
:
TOSHIBA,
and
the
capacity
is GB.
C++ 基础知识回顾(I/O)的更多相关文章
- java基础知识回顾之---java String final类普通方法
辞职了,最近一段时间在找工作,把在大二的时候学习java基础知识回顾下,拿出来跟大家分享,如果有问题,欢迎大家的指正. /* * 按照面向对象的思想对字符串进行功能分类. * ...
- C#基础知识回顾-- 反射(3)
C#基础知识回顾-- 反射(3) 获取Type对象的构造函数: 前一篇因为篇幅问题因为篇幅太短被移除首页,反射这一块还有一篇“怎样在程序集中使用反射”, 其他没有什么可以写的了,前两篇主要是铺垫, ...
- C#基础知识回顾-- 反射(1)
C#基础知识回顾-- 反射(1) 反射(reflection)是一种允许用户获得类型信息的C#特性.术语“反射”源自于它的工作方式: Type对象映射它所代表的底层对象.对Type对象进行查询可以 ...
- C#基础知识回顾--线程传参
C#基础知识回顾--线程传参 在不传递参数情况下,一般大家都使用ThreadStart代理来连接执行函数,ThreadStart委托接收的函数不能有参数, 也不能有返回值.如果希望传递参数给执行函数, ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- Java基础知识回顾之七 ----- 总结篇
前言 在之前Java基础知识回顾中,我们回顾了基础数据类型.修饰符和String.三大特性.集合.多线程和IO.本篇文章则对之前学过的知识进行总结.除了简单的复习之外,还会增加一些相应的理解. 基础数 ...
- C++ 基础知识回顾总结
一.前言 为啥要写这篇博客?答:之前学习的C和C++相关的知识,早就被自己忘到一边去了.但是,随着音视频的学习的不断深入,和C/C++打交道的次数越来越多,看代码是没问题的,但是真到自己操刀去写一些代 ...
- scrapy实战1,基础知识回顾和虚拟环境准备
视频地址 https://coding.imooc.com/learn/list/92.html 一. 基础知识回顾 1. 正则表达式 1)贪婪匹配,非贪婪匹配 .*? 非贪婪 . ...
- C#学习笔记(基础知识回顾)之值类型与引用类型转换(装箱和拆箱)
一:值类型和引用类型的含义参考前一篇文章 C#学习笔记(基础知识回顾)之值类型和引用类型 1.1,C#数据类型分为在栈上分配内存的值类型和在托管堆上分配内存的引用类型.如果int只不过是栈上的一个4字 ...
- C#学习笔记(基础知识回顾)之值传递和引用传递
一:要了解值传递和引用传递,先要知道这两种类型含义,可以参考上一篇 C#学习笔记(基础知识回顾)之值类型和引用类型 二:给方法传递参数分为值传递和引用传递. 2.1在变量通过引用传递给方法时,被调用的 ...
随机推荐
- CentOS系统使用yum安装配置MariaDB数据库
http://www.server110.com/mariadb/201310/2670.html 1.在 /etc/yum.repos.d/ 下建立 MariaDB.repo,内容如下:[azure ...
- paypal - 支付所遇到的问题,编码等等
1.ipn支付方式编码问题,paypal默认编码为 gb2312,需要登录paypal后台,进入用户信息设置>销售工具>更多销售工具>paypal按钮编码设置>更多选项,全部修 ...
- Django开发博客(七)——markdown优化
背景 上一次把markdown集成之后.发现还是有非常多问题. 这次须要做一些优化. 1.markdown与普通文本的差别显示. 2.添加点击量的统计 3.加入名片卡的滑动 版本号相关 操作系统:Ma ...
- 【方法1】删除Map中Value反复的记录,而且仅仅保留Key最小的那条记录
介绍 晚上无聊的时候,我做了一个測试题,測试题的大体意思是:删除Map中Value反复的记录,而且仅仅保留Key最小的那条记录. 比如: I have a map with duplicate val ...
- tomcat 输入localhost:8080显示404 (找不到tomcat主页)
最近使用tomcat时常出现一个问题,tomcat开启后浏览器输入localhost:8080时显示404,但是输入项目的路径是可以看到效果的,因为没啥大碍,所以没有在意 [ 在这里顺便介绍几种访问 ...
- 借鉴炉石传说的战棋游戏《DarkWar》
<炉石传说>是现在很火的休闲对战游戏,本人也非常喜欢玩,玩的时候经常想能不能把炉石的这些元素融入到战棋类游戏中,于是思索良久,又恰逢游戏蛮牛开展第三届蛮牛杯游戏开发大赛,于是用Unity3 ...
- tony_nginx的安装和配置
yum安装nginx Centos默认的yum源里没有nginx,需要手动添加源,有两种方法: 使用nginx提供的一个源设置安装包 nginx下载页面:http://nginx.org/en/dow ...
- Vue 获取验证码倒计时组件
子组件 <template> <a class="getvalidate":class="{gray: (!stop)}"@click='cl ...
- 我的 Android 学习笔记-Okhttp 的使用(译)
okhttp 已经是非常流行的网络请求库了.网上介绍的文章非常之多,但感觉都不是特别系统.遂想到官方应该有介绍的文档,仔细寻找一番,果然.但可惜是英文的,于是就大致翻译了一下,权当做笔记了. 1.Ca ...
- 解决js下跳转无referer的方法
HTTP Header referer这玩意主要是告诉人们我是从哪儿来的,就是告诉人家我是从哪个页面过来的,可以用于统计访问本网站的用户来源,也可以用来防盗链.获取这个东西最好的方式是js,如果在服务 ...