k-means聚类:擒贼先擒王,找到中心点,它附近的都是一类
属于无监督学习,聚类算法事先并不需要知道数据的类别标签,只是根据数据特征去学习,找到相似数据的特征,然后把已知的数据集划分成几个不同的类别
算法原理:
假设数据总共有m条,计划分成3个类别
先随机在这个空间中选取三个点,称之为中心点;计算所有的点到这三个点的距离,这里的距离计算使用的是欧氏距离;使用每个组的数据计算出这些数据的一个均值,使用这个均值作为下一轮迭代的中心点
如何确定k值
手肘法(适用于k值不那么大)
循环尝试k值,计算在不同的k值情况下,所有数据的损失即用每一个数据点到中心点的距离之和计算平均距离
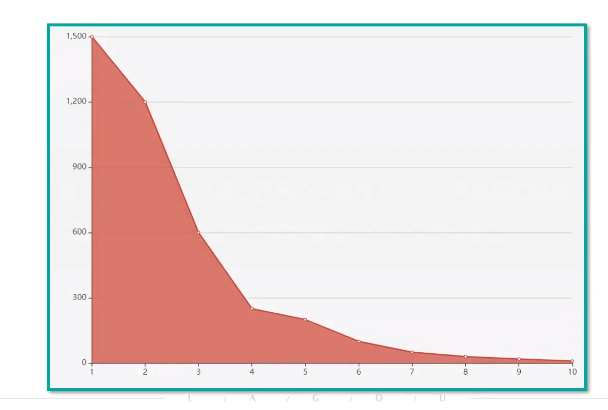
k=4时左侧数值变化大,右侧较为平缓
算法优点
简洁明了,计算复杂度低
收敛速度较快
算法缺点
结果不稳定
无法解决样本不均衡的问题
容易收敛到局部最优解
受噪声影响较大
from sklearn import datasets import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans """
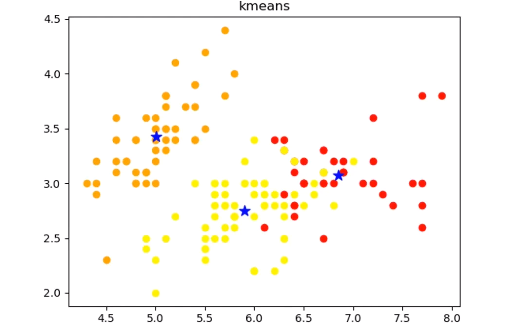
画出聚类后的图像
labels:聚类后的label,从0开始的数字
cents:质心坐标
n_cluster:聚类后簇的数量
"""
def draw_result(train_x,labels,cents,title):
n_clusters = np.unique(labels).shape[0]
color = ["red","orange","yellow"]
plt.figure()
plt.title(title)
for i in range(n_clusters):
current_data = train_x[labels ==i]
plt.scatter(current_data[:,0],current_data[:,1],c=color[i])
#使用蓝色的星形表示中心点位置
plt.scatter(cents[i,0],cents[i,1],c="blue",marker="*",s=100)
return plt if _name_ == '__main__':
iris = datasets.load_iris()
iris_x - iris.data
#设定聚类数目为3
clf = KMeans(n_clusters=3,max_iter=10,n_init=10,init="k-means++",algorithm="full",tol=1e-4,n_jobs=-1,random_state=1)
clf.fit(iris_x)
print("SSE={0}".format(clf.inertia_))
draw_result(iris_x,clf.labels_,clf.cluster_centers_,"kmeans").show()
#SEE是误差平方和,越接近0说明效果越好
k-means聚类:擒贼先擒王,找到中心点,它附近的都是一类的更多相关文章
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- R与数据分析旧笔记(十五) 基于有代表性的点的技术:K中心聚类法
基于有代表性的点的技术:K中心聚类法 基于有代表性的点的技术:K中心聚类法 算法步骤 随机选择k个点作为"中心点" 计算剩余的点到这个k中心点的距离,每个点被分配到最近的中心点组成 ...
- 第十篇:K均值聚类(KMeans)
前言 本文讲解如何使用R语言进行 KMeans 均值聚类分析,并以一个关于人口出生率死亡率的实例演示具体分析步骤. 聚类分析总体流程 1. 载入并了解数据集:2. 调用聚类函数进行聚类:3. 查看聚类 ...
- 机器学习算法与Python实践之(六)二分k均值聚类
http://blog.csdn.net/zouxy09/article/details/17590137 机器学习算法与Python实践之(六)二分k均值聚类 zouxy09@qq.com http ...
随机推荐
- windows10使用wireshark抓取本机请求包
1.管理员运行cmd 右键左下角windows图标,管理员运行Windows PowerShell 2.输入ipconfg查看本机ip和网关ip 3.执行命令 route add 本机ip mask ...
- memcached 测试代码
转载请注明来源:https://www.cnblogs.com/hookjc/ #include<stdio.h> #include <iostream> #include & ...
- js 保存并排序输入内容
转载请注明来源:https://www.cnblogs.com/hookjc/ /* Create By:jiangcheng_15 Create Date:2012-01-32 */ functio ...
- spring 注解注入bean
通过注解方式注入bean,需要在配置类下注入bean 第一步,配置扫描文件夹 首先要在spring.xml中配置需要扫描的配置类 <context:componenet-scan base-pa ...
- 键盘弹起及lab时的动态计算高度 --董鑫
1.键盘抬起或掉下时,动态计算高度 2.动态计算Label的高度 计算的高度时,numberOfLines必须设置为0: 2.1 ios7.0之后 2.2 iOS 7.0之前
- Codeforces Round #756 (Div. 3)
本场战绩:+451 题目如下: A. Make Even time limit per test 1 second memory limit per test 256 megabytes input ...
- [GWCTF 2019]re3 wp
[GWCTF 2019]re3 关键点:AES MD5 动态调试 smc自解密 gdb使用 跟进main函数 发现一个典型smc异或自解密 可以用idc脚本 或者python patch 或者动态调试 ...
- nginx 配置文件与日志模块
内容概要 Nginx 虚拟主机 基于多 IP 的方式 基于多端口的方式 基于多域名的方式 日志配置(日志格式详解) Nginx 访问控制模块(可以去 Nginx.org 文档 documentatio ...
- 自学linux(常用命令)STEP3
tty tty 可以查看当前处于哪一个系统中. 比如我在图形化界面输入 tty: alt+ctrl+F3切换到命令行: linux命令 linux命令,一般都是 命令+选项+参数,这种格式,为了防止选 ...
- 面向对象—多态、鸭子类型(Day21)
编程原则java具有自己的编程原则和设计模式,不能多继承.python的编程原则:1.开放封闭原则:开放是对扩展是开放的,封闭是对修改是封闭的(已经写完的代码程序是不能修改的).2.依赖倒置原则:高层 ...