hive从入门到放弃(一)——初识hive
之前更完了《Kafka从入门到放弃》系列文章,本人决定开新坑——hive从入门到放弃,今天先认识一下hive。
没看过 Kafka 系列的朋友可以点此传送阅读:
《Kafka从入门到放弃》系列
hive介绍
hive是一个开源的用于大数据分析和统计的数据库工具,它的存储基于HDFS,计算基于MapReduce或Spark,可以将结构化数据映射成表,并提供类SQL查询功能。
特点
- 提供类SQL查询,容易上手,开发方便
- 封装了很多方法,尽量避免了开发MapReduce程序,减少成本
- 支持自定义函数,可以根据需求实现函数
- 适用于处理大规模数据,小数据的处理没有优势
- 执行延迟较高,适合用于数据分析,不适合对时效性要求较高的场景
hive的架构
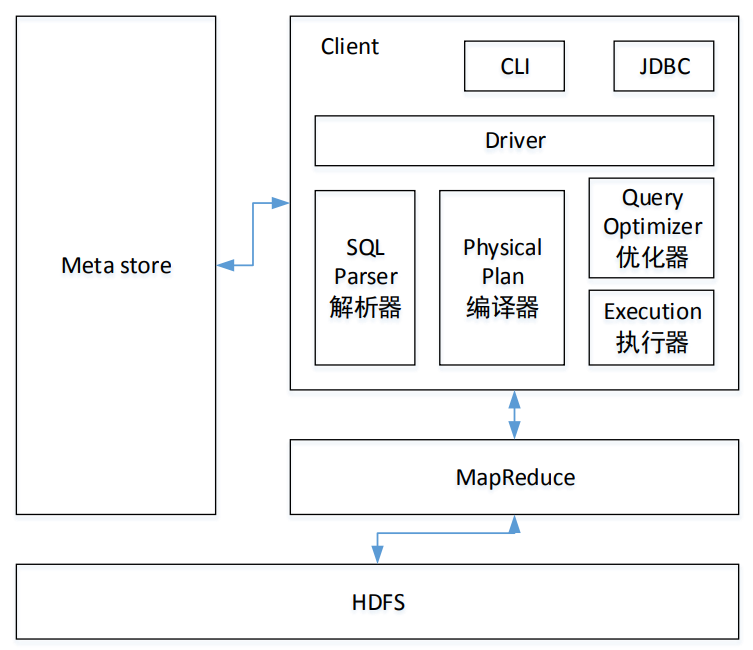
- MetaStore:元数据,数据的数据,比如某个表的元数据,包括表名、表所属的数据库、表的类型、表的数据目录等;
- CLI(命令行接口)、JDBC:用户接口,用以访问hive;
- Sql Parser 解析器:将SQL转换成抽象语法树,一般用第三方工具库完成;对抽象语法树进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误;
- Physical Plan 编译器:将抽象语法树编译生成逻辑执行计划;
- Query Optimizer 优化器:对逻辑执行计划进行优化;
- Execution 执行器:把逻辑执行计划转换成可以运行的物理计划。对Hive而言,就是 MR/Spark;
- HDFS:hive数据文件存放的地方。
不熟悉 HDFS 的朋友可以点击传送:《大数据 | 分布式文件系统 HDFS》
hive运行机制
当创建表的时候,需要指定HDFS文件路径,表和其文件路径会保存到MetaStore,从而建立表和数据的映射关系。当数据加载如表时,根据映射获取到对应的HDFS路径,将数据导入。
用户输入SQL后,hive会将其翻译成MapReduce或者Spark任务,提交到Yarn上面执行,执行成功将返回结果。
*hive默认将元数据存储在derby数据库中,但其仅支持单线程操作,若有一个用户在操作,其他用户则无法使用,造成效率不高;
而且当在切换目录后,重新进入Hive会找不到原来已经创建的数据库和表,
因此一般用MySQL存储元数据。
hive与数据库
可能有些朋友会认为,hive是数据库,因为它提供了类SQL查询功能。但其实除了这一点和数据库相似以外,其它的根本就没有多少共性。
- 数据库支持事务,可读可写;而hive不支持事务,一般用于读多写少的情况,不建议改动数据,因为数据存储在HDFS中,而HDFS的文件不支持修改;
- hive延迟比较大,因其底层是MapReduce,执行效率较慢。但当数据规模较大的情况下,hive的并行计算优势就体现出来了,数据库的效率就不如hive了;
- hive不支持索引,查询的时候是全表扫描,这也是其延迟大的原因之一;
*hive在0.14以后的版本支持事务,前提是文件格式为 orc 格式,同时必须分桶,还必须显式声明 transactional=true
hive的数据类型
数字类
| 类型 | 长度 |
|---|---|
| TINYINT | 1-byte |
| SMALLINT | 2-byte |
| INT/INTEGER | 4-byte |
| BIGINT | 8-byte |
| FLOAT | 4-byte |
| DOUBLE | 8-byte |
| DECIMAL | - |
日期类
| 类型 | 版本 |
|---|---|
| TIMESTAMP | 0.8.0以后 |
| DATE | 0.12.0以后 |
| INTERVAL | 1.2.0以后 |
字符类
| 类型 | 版本 |
|---|---|
| STRING | - |
| VARCHAR | 0.12.0以后 |
| CHAR | 0.13.0以后 |
Misc类
| 类型 | 版本 |
|---|---|
| BOOLEAN | - |
| BINARY | 0.8.0以后 |
复合类
| 类型 | 版本 | 备注 |
|---|---|---|
| ARRAYS | 0.14.以后 | ARRAY<data_type> |
| MAPS | 0.14.以后 | MAP<primitive_type, data_type> |
| STRUCTS | - | STRUCT<col_name : data_type [COMMENT col_comment], ...> |
| UNION | 0.7.0以后 | UNIONTYPE<data_type, data_type, ...> |
小结
本文从hive的特点、架构及运行机制开始,并将hive与数据库做对比,简单介绍了hive,同时对hive的数据类型做一个简单的介绍。
如果觉得写得还不错,麻烦点个小小的赞支持一下作者,可以持续关注【大数据的奇妙冒险】,解锁更多知识。
hive从入门到放弃(一)——初识hive的更多相关文章
- hive从入门到放弃(二)——DDL数据定义
前一篇文章,介绍了什么是 hive,以及 hive 的架构.数据类型,没看的可以点击阅读:hive从入门到放弃(一)--初识hive 今天讲一下 hive 的 DDL 数据定义 创建数据库 CREAT ...
- hive从入门到放弃(三)——DML数据操作
上一篇给大家介绍了 hive 的 DDL 数据定义语言,这篇来介绍一下 DML 数据操作语言. 没看过的可以点击跳转阅读: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--D ...
- hive从入门到放弃(四)——分区与分桶
今天讲讲分区表和分桶表,前面的文章还没看的可以点击链接: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--DDL数据定义 hive从入门到放弃(三)--DML数据操作 分区 ...
- hive从入门到放弃(六)——常用文件存储格式
hive 存储格式有很多,但常用的一般是 TextFile.ORC.Parquet 格式,在我们单位最多的也是这三种 hive 默认的文件存储格式是 TextFile. 除 TextFile 外的其他 ...
- python全栈开发从入门到放弃之初识面向对象
面向过程 VS 面向对象 面向过程的程序设计的核心是过程(流水线式思维),过程即解决问题的步骤,面向过程的设计就好比精心设计好一条流水线,考虑周全什么时候处理什么东西. 优点是:极大的降低了写程序的复 ...
- (MonoGame从入门到放弃-2) 初识MonoGame
上一节记录了大致的搭建MonoGame的环境,默认大家都是都是使用过Visual Studio的,没使用过的话,可以去https://www.visualstudio.com/下载一个试试,社区版免费 ...
- Kafka从入门到放弃(一) —— 初识Kafka
消息中间件的使用已经越来越广泛,基本上具有一定规模的系统都会用到它,在大数据领域也是个必需品,但为什么使用它呢?一个技术的广泛使用必然有它的道理. 背景与问题 以前一些传统的系统,基本上都是" ...
- Kafka从入门到放弃(三)—— 详说消费者
之前介绍了Kafka以及生产者,包括它的一些特性和参数,这回写一下消费者. 之前没看得可以点击链接阅读. Kafka从入门到放弃(一) -- 初识Kafka Kafka从入门到放弃(二) -- 详说生 ...
- [Hadoop大数据]——Hive部署入门教程
Hive是为了解决hadoop中mapreduce编写困难,提供给熟悉sql的人使用的.只要你对SQL有一定的了解,就能通过Hive写出mapreduce的程序,而不需要去学习hadoop中的api. ...
随机推荐
- BeanUtils JavaBean 工具包使用
感谢原文作者:小老弟 原文链接:https://www.cnblogs.com/syncmr/p/10523576.html 目录 简介 BeanUtils类 使用示例 ConvertUtils 功能 ...
- Java GUI界面补充总结(不定期补充)
一.Java中如何设置各类组件透明 感谢原文:https://kslsi.iteye.com/blog/2096608 补充:Frame透明:AWTUtilities.setWindowOpacity ...
- Redis实现延迟对列
一.应用场景: 订单超过 30 分钟未支付,则自动取消. 外卖商家超时未接单,则自动取消. 医生抢单电话点诊,超过 30 分钟未打电话,则自动退款.等等场景都可以用定时任务去轮询实现,但是当数据量过大 ...
- 简单理解Zookeeper的Leader选举
Leader选举是保证分布式数据一致性的关键所在.Leader选举分为Zookeeper集群初始化启动时选举和Zookeeper集群运行期间Leader重新选举两种情况.在讲解Leader选举前先了解 ...
- [转载] IOS 获取网络图片的大小 改变 图片色值 灰度什么的方法集合
IOS 获取网络图片的大小 改变 图片色值 灰度什么的方法集合
- sublime与python交互
点击菜单栏中的工具 -> 编译系统,勾选Python即可 创建hello.py文件,Ctrl+S保存文件,Ctrl+B执行文件,结果如下图 3.sublime运行python文件的交互环境设 ...
- MySQL时间格式TIMESTAMP和DATETIME的区别
时区,timestamp会跟随设置的时区变化而变化,而datetime保存的是绝对值不会变化 自动更新,insert.update数据时,可以设置timestamp列自动以当前时间(CURRENT_T ...
- 利用shell为MobaXterm生成session模板
文章目录 1.前言 2.导出MobaXterm的session模板 3.利用shell脚本生成.mxtsessions文件 4.导入到MobaXterm 5.效果图 1.前言 其实这是一件花里胡哨的事 ...
- Redis学习详解(一):Redis持久化机制之RDB
Redis的持久化机制有两种:RDB持久化和AOF持久化.因为Redis是一个内存数据库,如果没有合适的持久化机制,那么一旦服务器进程退出,服务器中的数据库状态也会消失.本章介绍RDB持久化机制. R ...
- 轻量级DI框架Guice使用详解
背景 在日常写一些小工具或者小项目的时候,有依赖管理和依赖注入的需求,但是Spring(Boot)体系作为DI框架过于重量级,于是需要调研一款微型的DI框架.Guice是Google出品的一款轻量级的 ...