Win10 pycharm中显示PyTorch tensorboard图
import numpy
import numpy as np
import torch
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim import torchvision
import torchvision.transforms as transforms
import tensorboard
from torch.utils.tensorboard import SummaryWriter # print(tensorboard.__version__) device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # Assuming that we are on a CUDA machine, this should print a CUDA device: # print(device) '''
device="cuda" if torch.cuda.is_available() else "cpu"
# print(device)
'''
torch.set_printoptions(linewidth=120) # Display options for output
torch.set_grad_enabled(True) # Already on by default
print(torch.__version__, torchvision.__version__, sep='\n') def get_num_correct(preds, labels):
return preds.argmax(dim=1).eq(labels).sum().item() class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5) self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10) def forward(self, t):
# (1) input layer
t = t # (2) hidden conv layer
t = self.conv1(t)
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2) # (3) hidden conv layer
t = self.conv2(t)
t = F.relu(t)
t = F.max_pool2d(t, kernel_size=2, stride=2) # (4) hidden Linear layer
t = t.reshape(-1, 12 * 4 * 4) # -1表示对行没约束,反正是12*4*4列
t = self.fc1(t)
t = F.relu(t)
# (5) hidden Linear layer
t = self.fc2(t)
t = F.relu(t)
# (6) output layer
t = self.out(t)
# t=F.softmax(t,dim=1) #此处不使用softmax函数,因为在训练中我们使用了交叉熵损失函数,而在torch.nn函数类中,已经在其输入中隐式的
# 执行了一个softmax操作,这里我们只返回最后一个线性变换的结果,也即是 return t,也即意味着我们的网络将使用softmax操作进行训练,但在
# 训练完成后,将不需要额外的计算操纵。 return t # get data train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST',
train=True,
download=True,
transform=transforms.Compose([transforms.ToTensor()])
) data_loader = torch.utils.data.DataLoader(train_set,batch_size=100,shuffle=True) # shuffle=True # from collections import Iterable
#
# print(isinstance(data_loader,Iterable)) #返回True #####################
# starting out with TensorBoard(Network Graph and Images) 下面一段为生成日志文件的代码,直到tb.close()
#####################
tb=SummaryWriter() network=Network()
images,labels=next(iter(data_loader))
grid=torchvision.utils.make_grid(images)#网格效用函数 tb.add_image('images',grid)
tb.add_graph(network,images)
tb.close() # optimizer = optim.Adam(network.parameters(), lr=0.01) ''' for epoch in range(3): total_loss = 0
total_correct = 0 for batch in data_loader: # get batch
images, labels = batch
images, labels = images.to(device), labels.to(device) preds = network(images) # pass batch
loss = F.cross_entropy(preds, labels) # calculate loss optimizer.zero_grad()
loss.backward() # calculate gradients
optimizer.step() # update weights using the gradient and the learning rate
total_loss += loss.item()
total_correct += get_num_correct(preds, labels) print('epoch:', epoch, 'total_correct:', total_correct, 'total_loss:', total_loss) print(total_correct / len(train_set)) '''
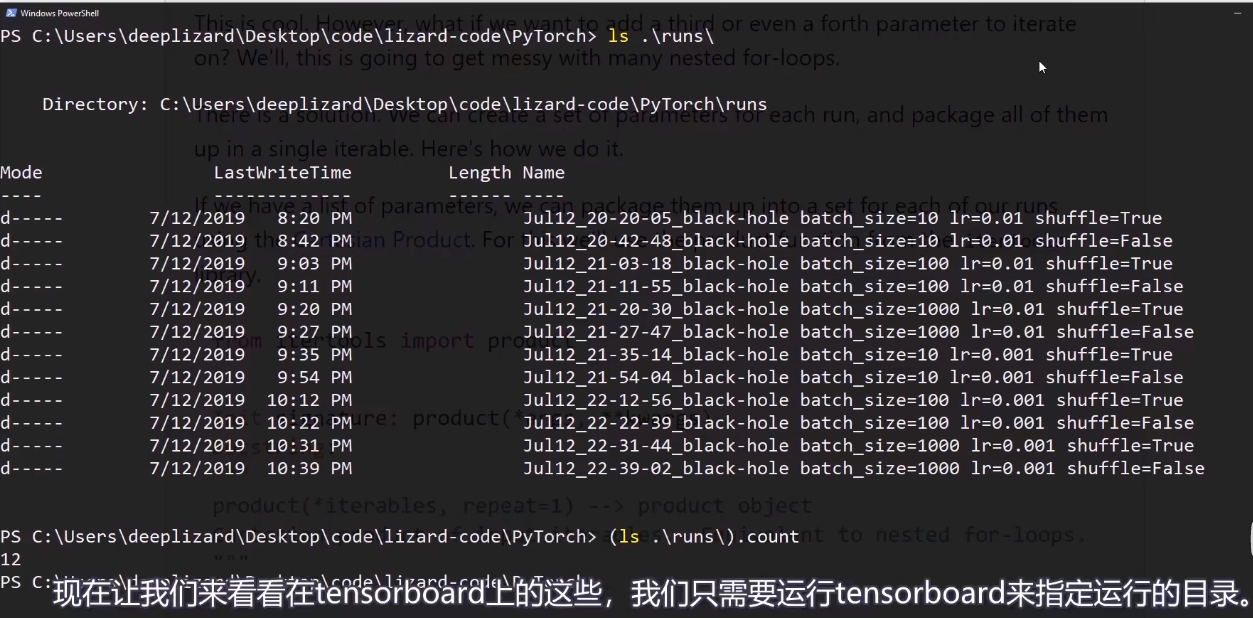
其中 runs为该代码所在文件夹中位置,日志文件生成后也在这个文件夹里
如下图:
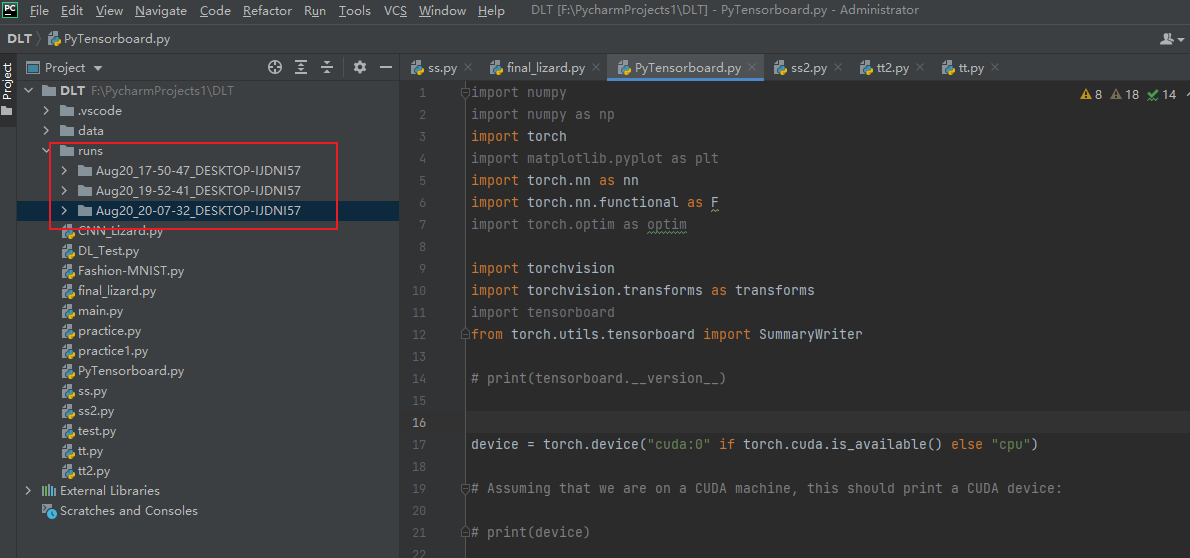
在runs文件夹上点击鼠标右键 有一个open in terminal 点击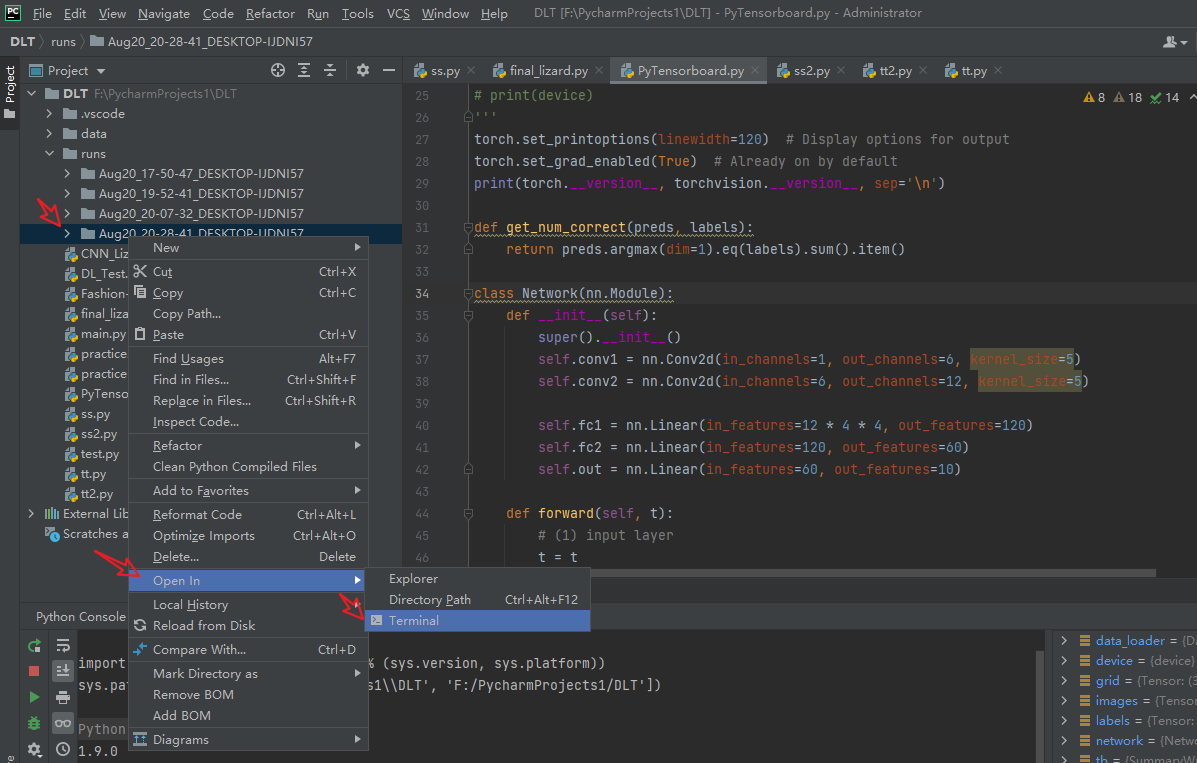
打开后如下图所示:
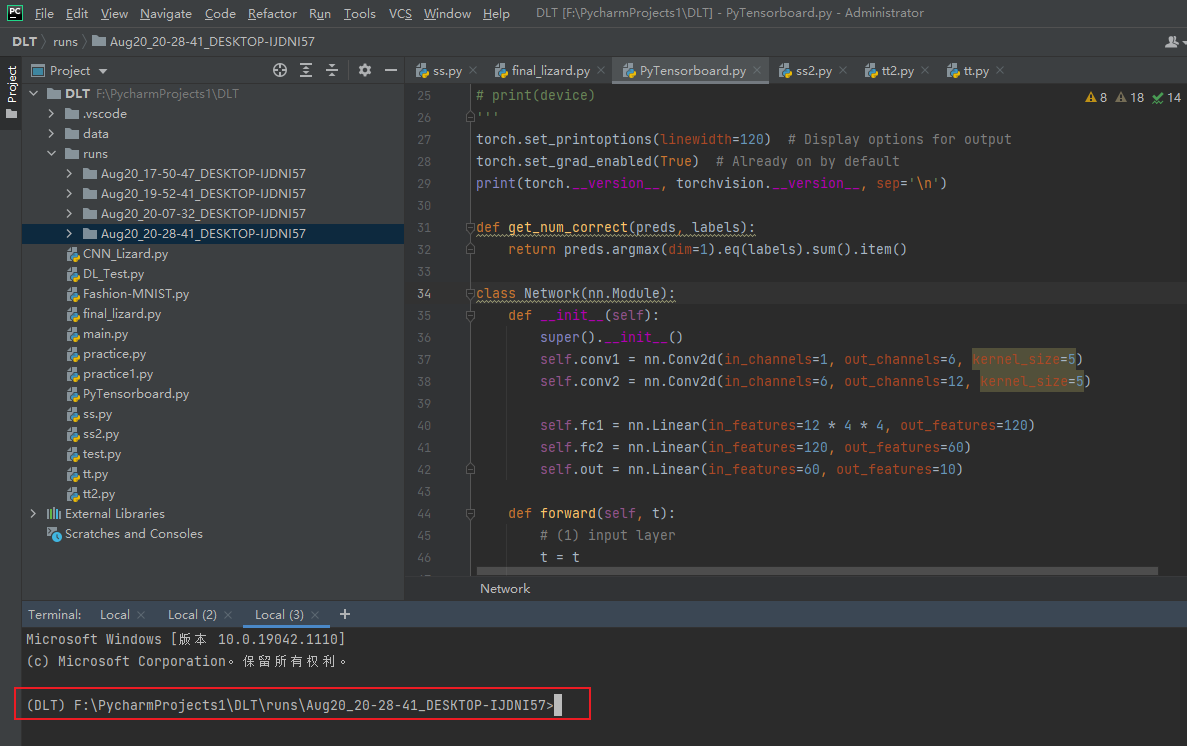
然后再再上图红框右边输入:tensorboard --logdir=日志文件所在的绝对路径
日志文件绝对路径可以直接在runs文件夹右击 有一个copy path 即可
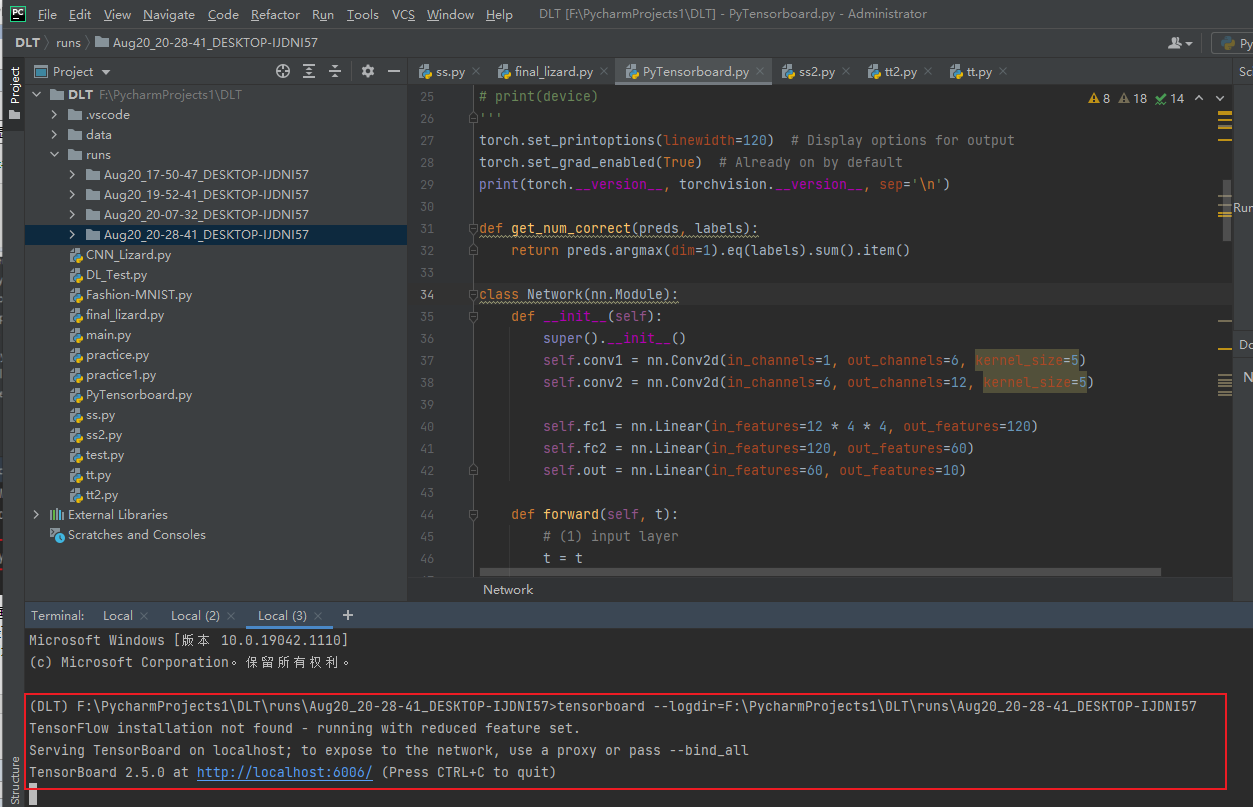
回车后出现一个网址,点击就可以看到tensorboard图:
Win10 pycharm中显示PyTorch tensorboard图的更多相关文章
- 最全Pycharm教程(43)——Pycharm扩展功能之UML类图使用 代码结构
版权声明:本文为博主原创文章,转载时麻烦注明源文章链接,谢谢合作 https://blog.csdn.net/u013088062/article/details/50353202 1.什么是UML ...
- Android中使用SVG矢量图(一)
SVG矢量图介绍 首先要解释下什么是矢量图像,什么是位图图像? 1.矢量图像:SVG (Scalable Vector Graphics, 可伸缩矢量图形) 是W3C 推出的一种开放标准的文本式矢量图 ...
- WIN10下使用Anaconda配置opencv、tensorflow、pygame并在pycharm中运用
昨天想运行一段机器学习的代码,在win10系统下配置了一天的python环境,真的是头疼,准备写篇博客来帮助后面需要配置环境的兄弟. 1.下载Anaconda 根据昨天的经历,发现Anaconda真的 ...
- win10下Anaconda 2 和 3 共存安装,并切换jupyter notebook和Pycharm中的对应版本
win10下Anaconda 2 和 3 共存安装,并切换jupyter notebook和Pycharm中的对应版本 zoerywzhou@163.com http://www.cnblogs.co ...
- win10 64位专业版系统中显示32位dcom组件配置的方法
word.excel是32位的组件,当用户64位系统在运行窗口中输入dcomcnfg命令时,在打开的组件服务管理窗口,是找不到Microsoft Excel.word程序的.另外,Windows 环境 ...
- pycharm:terminal中显示乱码的解决方式
pycharm:terminal中显示乱码的解决方式
- win10的cmd中显示:telnet不是内部或外部命令也不是可运行的程序或批处理?
win10的cmd中显示:telnet不是内部或外部命令也不是可运行的程序或批处理? 摘录自:https://blog.csdn.net/haijing1995/article/details/664 ...
- 解决在Pycharm中无法显示代码提示的问题
#coding: utf-8from cx_Oracle.CURSOR import *import cx_Oracle conn= cx_Oracle.connect('XX', 'XX', '12 ...
- 可视化Tensorboard图中的符号意义
可视化Tensorboard图中的符号意义
随机推荐
- 【合集】Python基础知识【第二版】
更新部分 为了避免冗长的代码影响大家观感,将部分案例拆开 增加部分知识点,为了减少大家阅读的负担,尽可能使用短句子,但知识点不可能全覆盖,笔者不是写书,就算是写书也不可能全面,请同学们自行去补充 增加 ...
- Python 图_系列之基于<链接表>实现无向图最短路径搜索
图的常用存储方式有 2 种: 邻接炬阵 链接表 邻接炬阵的优点和缺点都很明显.优点是简单.易理解,对于大部分图结构而言,都是稀疏的,使用炬阵存储空间浪费就较大. 链接表的存储相比较邻接炬阵,使用起来更 ...
- 网络协议之:socket协议详解之Unix domain Socket
目录 简介 什么是Unix domain Socket 使用socat来创建Unix Domain Sockets 使用ss命令来查看Unix domain Socket 使用nc连接到Unix do ...
- Oracle安装 - shmmax和shmall设置
一.概述 在Linux上安装oracle,需要对内核参数进行调整,其中有shmmax和shmall这两个参数,那这两个参数是什么意思,又该如何设置呢? 二.官方文档 在oracle的官方文档( htt ...
- centos下 Docker-修改磁盘存储目录(实操)
预备知识: Docker 是一个开源项目,诞生于 2013 年初,最初是 dotCloud 公司内部的一个业余项目.它基于 Google 公司推出的 Go 语言实现. 项目后来加入了 Linux 基金 ...
- 『忘了再学』Shell基础 — 8、管道符介绍
我们之前已经有文章说过管道符了,今天这里再简单总结一下用法. 1.行提取命令grep grep命令的作用,是在指定的文件中,搜索符合条件的字符串. 命令格式: [root@localhost ~ ] ...
- 线程的概念及Thread模块的使用
线程 一.什么是线程? 我们可以把进程理解成一个资源空间,真正被CPU执行的就是进程里的线程. 一个进程中最少会有一条线程,同一进程下的每个线程之间资源是共享的. 二.开设线程的两种方式 开设进程需要 ...
- RESTFUL风格的接口命名规范
1.首先restfulf风格的api是基于资源的,url命名用来定位资源,而不是表示动作,动作通过请求方式进行表示. 2.URL中应该单复数区分,推荐的实践是永远只用复数.比如GET /api/use ...
- Grafana中文汉化
可视化图表 Grafana是一个通用的可视化工具.通过Grafana可以管理用户权限,数据分析,查看,导出,设置告警等. 仪表盘Dashboard 通过数据源定义好可视化的数据来源之后,对于用户而言最 ...
- 微信小程序循环列表点击每一个单独添加动画
首先,咱们看一下微信小程序动画怎么实现,我首先想到的是anime.js,但是引入之后用不了,微信小程序内的css也无法做到循环的动态,我就去找官方文档看看有没有相应的方法,哎,还真有 点击这里查看 微 ...