VideoMAE Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training概述
0.前言
1.针对的问题
视频存在非常多的冗余信息,所以,对视频的处理需要非常大的计算资源,transformer需要非常多的额外训练数据,此外,视频transformer高度依赖于预训练好的权重。作者的目标是在当前的视频数据集上以不依赖于任何额外预训练权重和数据的情况下训练一个原始的transformer模型。
2.主要贡献
1.提出了一个简单但有效的视频掩码自编码器,释放了原始视觉transformer视频识别的潜力。这是第一个仅使用普通ViT backbones的掩蔽视频预训练框架。为了缓解掩蔽视频建模中的信息泄漏问题,我们提出了极高比例的tube 掩蔽,从而提高了视频建模的性能。
2.与NLP和图像在掩蔽建模上的结果一致,VideoMAE证明了这种简单的掩蔽和重建策略为自监督视频预训练提供了一个很好的解决方案。用VideoMAE预先训练的模型明显优于那些从头开始训练或用对比学习方法预训练的模型。
3.获得了关于掩蔽建模的特别重要的发现,而这些发现在以前的NLP和图像研究中可能被忽略。(1)证明了VideoMAE是一种数据高效的学习器,可以通过3.5k个视频成功训练。(2)当源数据集和目标数据集之间存在域移时,数据质量比数量更重要。
3.方法
作者提出的VideoMAE尝试在两个方面解决上述挑战。
1.采用一种自监督的预训练方法,以掩蔽自编码器为基础,提出了一种对于视频的自监督预训练范式,
2.提出了一种新的以tube为形式的掩蔽操作,并且这种掩蔽操作具有非常大的掩码比率。如果不针对性地设计掩码策略,这种时序相关性可能会增加重建过程中的“信息泄漏”的风险。具体来说,如图所示,如果使用全局随机掩码或随机掩码图像帧,网络可以利用视频中的时序相关性,通过““复制粘贴””相邻帧中时序对应位置的未被遮蔽的像素块来进行像素块重建。这种情况下一定程度上也能完成代理任务,但是可能会导致VideoMAE仅仅能学习到较低语义的时间对应关系特征,而不是高层抽象的语义信息。
输入和输出都是一致的,整个自编码器结构就是要基于被掩蔽之后剩下的token来恢复出原始的视频,首先经过时序下采样的时序clip会进行tube mask掩码,掩码后未被掩蔽的token会被送入Decoder中,Decoder将基于这些token来恢复原始的视频,需要注意的是,这里的编码器和解码器都是vit的结构,不过编码器会比较大,解码器比较小,这将组成一个mask auto encoder的训练范式,这种范式非常的高效,因为只有一小部分的token会被送入解码器中进行处理,这种高效的预训练范式使得在视频上的预训练大大加速。
mask策略:tube mask指的是mask的操作在时序上是一致的,在空间上的某一帧随机进行掩码操作,之后时序上的各个帧都共享这种掩码操作,这样就形成了一种管道式的掩码,要注意的是掩码的比率是非常高的,达到90%到95%,这种掩码比率使得训练过程非常高效,同时,也为预训练设置了一种非常具有挑战性的代理任务,使得在下游各个识别检测task上都能取得很好的性能。
模型结构如下:
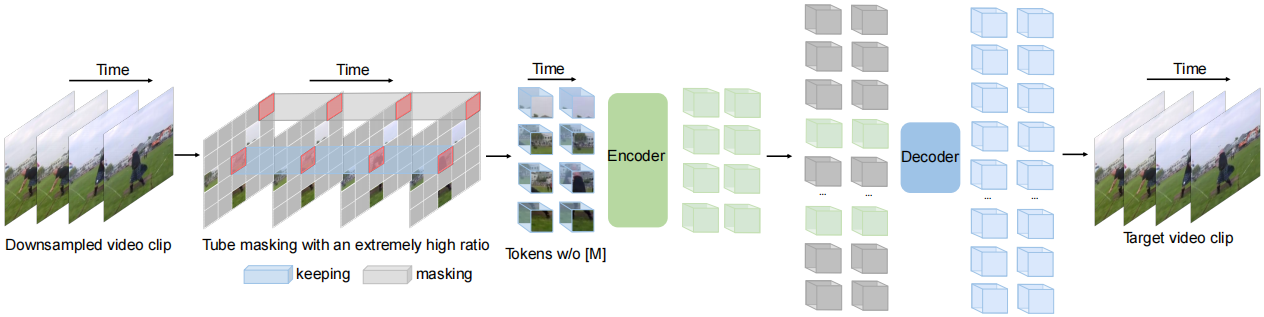
时序下采样
根据前文中对视频中密集连续帧中存在的时序冗余性的分析,因此在VideoMAE中选择采用带有时序间隔的采样策略来进行更加高效的视频自监督预训练。具体来说,首先从原始视频中随机采样一个由t个连续帧组成的视频片段。然后使用带有时序间隔采样将视频片段压缩为T帧,每个帧包含 H×W×3 个像素。在具体的实验设置中,Kinetics-400 和 Something-Something V2 数据集上的采样间隔τ分别设置为4和2。
时空块嵌入
在输入到编码器中之前,对于采样得到的视频片段,采用时空联合的形式进行像素块嵌入。具体来说,将大小为 T×H×W 视频片段中大小为 2×16×16 的视觉像素视为一个视觉像素块。因此,采样得到的视频片段经过时空块嵌入(cube embedding)层后可以得到 T/2×H/16×W/16 个视觉像素块。在这个过程中,同时会将视觉像素块的通道维度映射为 D 。这种设计可以减少输入数据的时空维度大小,一定程度上也有助于缓解视频数据的时空冗余性。
带有极高的掩码比率的管道式掩码策略
为了解决由视频数据中的时序冗余性和时序相关性导致的“信息泄漏”问题,本方法选择在自监督预训练的过程中采用管道式掩码策略。管道式的掩码策略可以将单帧彩色图像的掩码方式自然地在整个视频的时序上进行拓展,即不同的帧中相同空间位置的视觉像素块将被遮蔽。具体来说,管道式掩码策略可以表示为 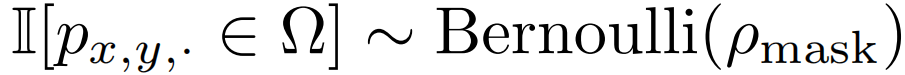 。不同的时间 t 共享相同的值。 使用这种掩码策略,相同空间位置的token将总是会被掩码。所以对于一些视觉像素块(例如,不同掩码策略的示例图第 4 行的包含手指的像素块),网络将无法在其他帧中找到其对应的部分。这种设计这有助于减轻重建过程中出现“信息泄露”的风险,可以让VideoMAE通过提取原始视频片段中的高层语义信息,来重建被掩码的token。
。不同的时间 t 共享相同的值。 使用这种掩码策略,相同空间位置的token将总是会被掩码。所以对于一些视觉像素块(例如,不同掩码策略的示例图第 4 行的包含手指的像素块),网络将无法在其他帧中找到其对应的部分。这种设计这有助于减轻重建过程中出现“信息泄露”的风险,可以让VideoMAE通过提取原始视频片段中的高层语义信息,来重建被掩码的token。
相对于图像数据,视频数据具有更强的冗余性,视频数据的信息密度远低于图像。这种特性使得VideoMAE使用极高的掩码率(例如 90% 到 95%)进行预训练。值得注意的是,MAE的默认掩码率为75% 。实验结果表明,使用极高的掩码率不仅能够加速预训练(仅有 5% 到 10% 的视觉像素块被输入到编码器中),同时能够提升模型的表征能力和在下游任务中的效果。
时空联合自注意力机制
前文中提到了VideoMAE采用了极高的掩码率,只保留了极少的token作为编码器的输入。为了更好地提取这部分未被遮蔽的token的时空特征,VideoMAE选择使用原始的ViT作为Backbone,同时在注意力层中采用时空联合自注意力(即不改变原始ViT的模型结构)。因此所有未被遮蔽的token都可以在自注意层中相互交互。时空联合自注意力机制的 O(n2) 级别的计算复杂度是网络的计算瓶颈,而前文中针对VideoMAE使用了极高掩码比率策略,仅将未被遮蔽的token(例如10%)输入到编码器中。这种设计一定程度上可以有效地缓解O(n2) 级别的计算复杂度的问题。
VideoMAE Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training概述的更多相关文章
- 论文解读(MGAE)《MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs》
论文信息 论文标题:MGAE: Masked Autoencoders for Self-Supervised Learning on Graphs论文作者:Qiaoyu Tan, Ninghao L ...
- 数据量与半监督与监督学习 Data amount and semi-supervised and supervised learning
机器学习工程师最熟悉的设置之一是访问大量数据,但需要适度的资源来注释它.处于困境的每个人最终都会经历逻辑步骤,当他们拥有有限的监督数据时会问自己该做什么,但很多未标记的数据,以及文献似乎都有一个现成的 ...
- Microsoft: Get started with Dynamic Data Masking in SQL Server 2016 and Azure SQL
Dynamic Data Masking (DDM) is a new security feature in Microsoft SQL Server 2016 and Azure SQL DB. ...
- 论文翻译——Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection
Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection 动态池和展开递归自动编码器的意译检测 论文地 ...
- Lessons Learned from Developing a Data Product
Lessons Learned from Developing a Data Product For an assignment I was asked to develop a visual ‘da ...
- Oracle 10g Data Pump Expdp/Impdp 详解
Data Pump 介绍 在第一部分看了2段官网的说明, 可以看出数据泵的工作流程如下: (1)在命令行执行命令 (2)expdp/impd 命令调用DBMS_DATAPUMP PL/SQL包. 这个 ...
- Reducing the Dimensionality of Data with Neural Networks:神经网络用于降维
原文链接:http://www.ncbi.nlm.nih.gov/pubmed/16873662/ G. E. Hinton* and R. R. Salakhutdinov . Science. ...
- [Javascript] Classify JSON text data with machine learning in Natural
In this lesson, we will learn how to train a Naive Bayes classifier and a Logistic Regression classi ...
- [DE] How to learn Big Data
打开一瞧:50G的文件! emptystacks jobstacks jobtickets stackrequests worker 大数据加数据分析,需要以python+scikit,sql作为基础 ...
- Setting up the data and the model
Table of Contents: Setting up the data and the model Data Preprocessing Weight Initialization Batch ...
随机推荐
- c++随笔测试(Corner of cpp)
在c++17下,程序的输出是什么?(有可能编译出错,有可能输出未知,有可能是未定义行为) 点击查看代码 #include<iostream> void foo(unsigned int) ...
- 【博学谷学习记录】超强总结,用心分享|前端CSS总结(一)
CSS总结(一) shift+alt,选中多行 外链式 <link rel="stylesheet" href="./my.css"> 1 选择器 ...
- idea 函数名灰色
idea被引用的方法名突然全部灰掉了 idea被引用的方法名突然全部灰掉了[已解决]_weixin_42554373的博客-CSDN博客_idea方法名灰色
- [WPF]Win10便签软件
项目地址 Github:项目地址 软件截图 项目中用到的技术和问题 [WPF]限制程序单例运行 [WPF]创建系统栏小图标 [WPF]程序随系统自启动 [WPF]xml序列化以及反序列化数据 [WPF ...
- 2.PyQt5【窗口组件】对话框-Dialog
一.前言 QDialog 类是对话框窗口的基类.对话框窗口是主要用于短期任务以及和用户进行简要 通讯的顶级窗口.QDialog 可以是模态对话框也可以是非模态对话框.QDialog 支持扩展性并 且可 ...
- liunx系统安装Redis详细步骤
liunx系统安装Redis详细步骤 官网下载Redis安装包 使用工具将redis安装包拖入liunx系统 创建Redis存放目录 mkdir /usr/local/redis 解压到redis存放 ...
- Coolify系列-手把手教学解决局域网局域网中的其他主机访问虚拟机以及docker服务
背景 我在windows电脑安装了一个VM,使用VM开启了Linux服务器,运行docker,下载服务镜像,然后运行服务,然后遇到了主机无法访问服务的问题. 问题排查 STEP1:首先要开启防火墙端口 ...
- 反射_Class对象功能_获取Constructor-反射_Class对象功能_获取Method
反射_Class对象功能_获取Constructor Constructor<?>[] getConstructors() Constructor<T> getConstruc ...
- Hive删除分区名称中含有特殊字符
先说方案:通过show partitions和hdfs url看到的都不是真正的分区名称,都是经过URI重新编码的,访问这些分区应该使用分区名称的原始字符串. 场景描述 当我们在SQL语句中使用变量时 ...
- ClickHouse(12)ClickHouse合并树MergeTree家族表引擎之AggregatingMergeTree详细解析
目录 建表语法 查询和插入数据 数据处理逻辑 ClickHouse相关资料分享 AggregatingMergeTree引擎继承自 MergeTree,并改变了数据片段的合并逻辑.ClickHouse ...