Windows 环境搭建 PostgreSQL 物理复制高可用架构数据库服务
PostgreSQL 高可用数据库的常见搭建方式主要有两种,逻辑复制和物理复制,上周已经写过了关于在Windows环境搭建PostgreSQL逻辑复制的教程,这周来记录一下 物理复制的搭建方法。
首先介绍一下逻辑复制和物理复制的一些基本区别:
- 物理复制要求多个实例之间大版本一致,并且操作系统平台一致,如主实例是 Windows环境下的 PostgreSQL15 则 从实例也必须是这个环境和版本,逻辑复制则没有要求。
- 物理复制是直接传递 WAL归档 文件,在从实例进行重放执行,可以理解为实时的 WAL归档恢复,所以延迟低,性能高。,
- 逻辑复制可以简单理解为解析了WAL归档文件中的信息,处理成为 标准的SQL语句,传递给存库进行执行,相对于直接传递WAL性能较低,延迟高。
- 物理复制不需要像逻辑复制一些去手动的建立数据库,数据表,因为物理复制是直接恢复WAL所以包含了DDL操作,逻辑复制则需要自己进行DDL操作。
- 逻辑复制更加灵活,可以自己指定需要复制的库,从实例,还可以建立其他库用于其他业务,而物理复制则是面向整个实例进行的,从实例和主实例100%一致最多只能进行只读操作。
关于 Windows 系统 PostgreSQL 的安装方法可以直接看之前的博客 https://www.cnblogs.com/berkerdong/p/16645493.html
如果追求高性能,高一致性的数据库复制备份方案建议采用物理复制的方式。
搭建物理复制模式的主从订阅首先要调整主实例的 postgresql.conf 文件
wal_level = replica
synchronous_commit = remote_apply

因为我们采用的 synchronous_commit = remote_apply 是同步复制的模式,该模式可以理解为同步复制,当客户端像主实例提交事务之后,需要等 synchronous_standby_names 总配置的节点全部完成 remote_apply 收到数据之后,主实例才会给备库返回事务成功提交的状态,创建好名为 s 的订阅创建之后,我们再次打开 主实例的 postgresql.conf 文件进行调整设置
synchronous_standby_names = 's'

当有多个从实例从主实例同步的时候synchronous_standby_names 还可以采用以下配置模式
- synchronous_standby_names='s1' 代表s1备机返回就可以提交。
- synchronous_standby_names='FIRST 2 (s1,s2,s3)' 代表s1,s2,s3三个备机中前两个s1和s2返回主实例就可以提交。
- synchronous_standby_names='ANY 2 (s1,s2,s3)' 代表s1,s2,s3三个备机中任意两个备机返回主实例就可以提交。
- synchronous_standby_names='ANY 2 (*)' 代表所有备机中任意两个备机返回主实例就可以提交。
- synchronous_standby_names='*' 代表匹配任意主机,也就是任意主机返回就可以提交。
这里有一点需要注意,这是 PostgreSQL 在同步复制时的一个已知问题,假设 一个主实例,一个备库 s1,采用同步模式,然后 synchronous_standby_names 配置为 synchronous_standby_names='s1',虽然从配置上来看似乎数据必须要提交到s1并且s1成功响应之后,主实例才会为客户端返回事务操作成功的响应,但是实际情况下,当备库挂掉的情况下,主实例在收到一个事务操作时,在等待 s1 备库的返回时因为 s1库已经挂掉了所以这个操作肯定会超时,当主备节点通信超时之后,主节点还是会像客户端返回事务成功提交的命令,客户端的操作还是会成功,同时因为每个事务操作都要经历这个超时的流程,所以客户端的所有事务操作都会相对很卡。
比如每个 insert 都会经过主实例和备库的这个通信超时过程,所以每个 insert 动作都变成了大约30秒次才能完成,就会导致应用程序很卡。这时候就相当于主实例在以(很卡的)独立模式运行,这个情况在备库重新上线之后就会恢复正常(如果备库短期之内无法恢复,可以调整主实例的 synchronous_standby_names设置 移除对于s1备库的事务等待验证,变为单库运行模式重启实例之后也就不会卡了),但是要注意当主实例脱离备库独立运行时,如果这个时候主实例发生灾难比如硬盘坏掉,则就会产生数据丢失。所以建议至少有2个从实例来提升保障级别
然后还需要调整主实例的 pg_hba.conf,添加 replication 模式的连接白名单配置。
host replication all 0.0.0.0/0 scram-sha-256
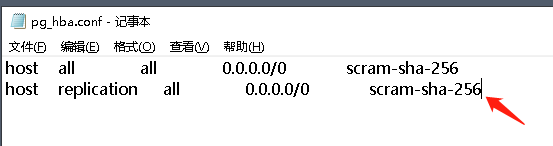
调整配置文件之后记得重启主数据库实例。
主实例重启之后,我们还需要连接到主实例创建复制槽,默认情况下WAL归档文件是循环滚动清理,这就会导致一个问题如果我们的从实例挂机之后离线的时间较长,就有可能因为主实例的WAL文件已经循环滚动删除了,这种情况下,就算从实例修复好之后重新上线,因为主实例的部分WAL归档文件已经清理了,也无法再追赶上我们主实例的数据进度,这种情况下从实例会直接报错。因为有这种场景的存在所以 PostgreSQL 里面出现了一个复制槽的概念,主实例可以创建多个复制槽,一个复制槽绑定给一个从实例使用,复制槽的好处在于会确保从实例获取到WAL文件之后才会进行清理,不会有前面说的滚动循环自动清理的问题。
复制槽的维护都在主实例进行:创建,查询,删除的语句如下
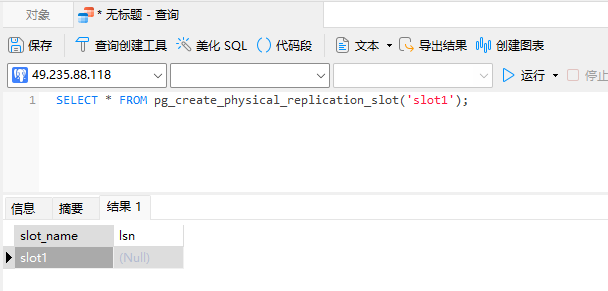
创建复制槽
SELECT * FROM pg_create_physical_replication_slot('slot1');
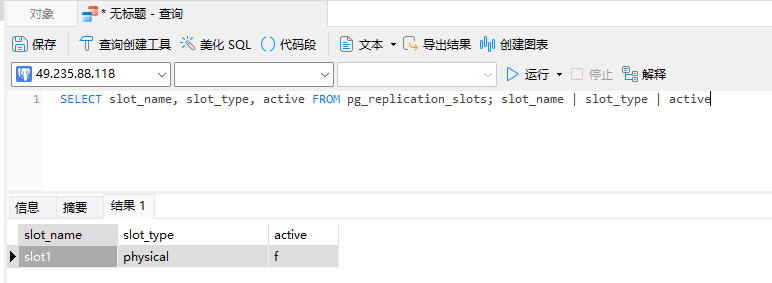
查询全部的复制槽
SELECT slot_name, slot_type, active FROM pg_replication_slots; slot_name | slot_type | active
删除复制槽
SELECT * FROM pg_drop_replication_slot('slot1')
至此主实例的配置就都完成了,接下来就是准备我们的从实例,因为物理复制不同于逻辑复制,是针对整个实例复制的,所以我们需要准备一个和主实例,版本相同的从实例,如果主实例已经有数据库在上面了,推荐直接把停止主实例的运行然后把PostgreSQL文件夹和Data整体打包压缩复制一份到新的服务器上启动起来作为从实例。
我这里选择直接把云服务器上的 PostgreSQL 打包压缩然后复制到本地解压,作为从实例
在本地解压之后,做为 从实例 需要做如下的调整,postgresql.conf
primary_conninfo = 'host=49.235.88.118 port=5432 user=postgres password=xxxxxx application_name=s'
primary_slot_name = 'slot1'
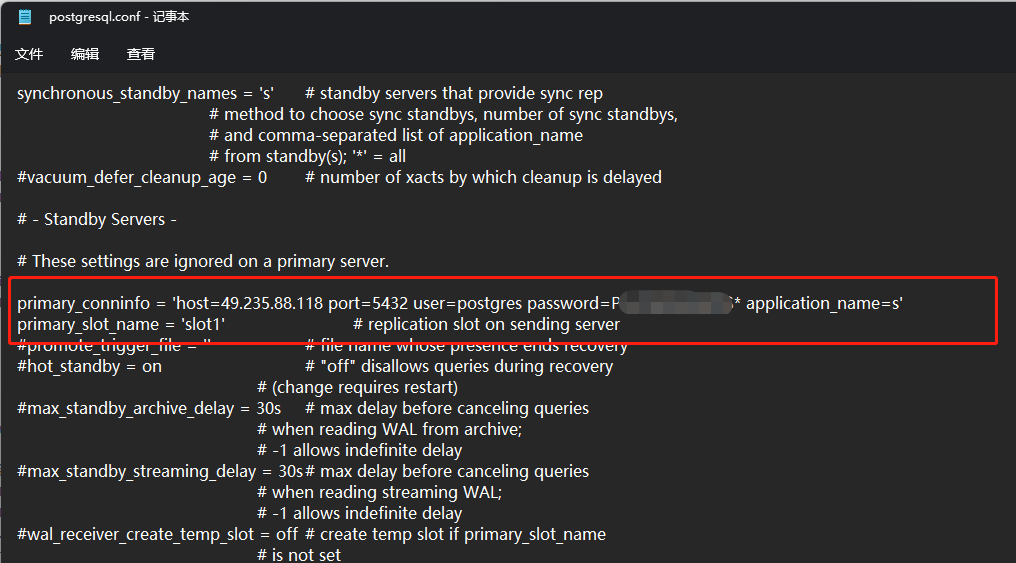
primary_conninfo 主要内容就是我们主实例的连接字符串信息然后加一个 application_name ,application_name 和我们前面在主实例上配置的 synchronous_standby_names 想关联,前面我们配置了主实例的所有事务操作都需要同步等待 名字为 s 的备库执行完成
primary_slot_name 则是复制槽的名称我们前面创建了一个 slot1 的复制槽,给我们的这个从实例使用。
这里需要注意一点,在配置的时候如果有多个从实例,则一个从实例对应一个复制槽,绑定一个 application_name。
然后在 data 目录下新建一个空文件
standby.signal
这个文件的其实一个信号标记,标识我们当前的实例时一个只读实例,不可以用于数据插入。
然后启动备库就可以了,正常情况会看到如下界面
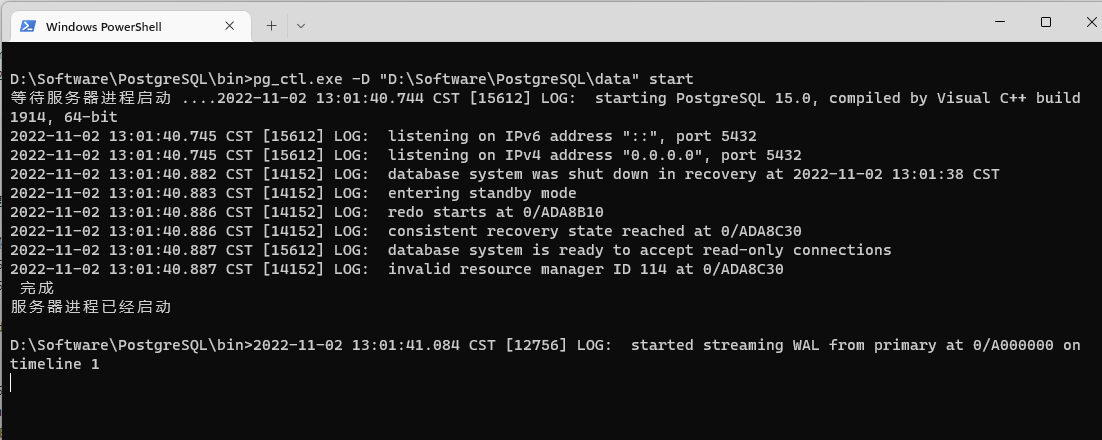
这时候我们可以尝试去主实例创建一个数据库做一些操作,然后连接从实例,就会发现两边都是互相同步的。
如果要解除从实例和主实例的关联,操作如下:
从主实例的 postgresql.conf 找到 synchronous_standby_names 删除 s 节点的配置
#synchronous_standby_names='s'
如果只有一个从节点的,则直接添加 # 对 synchronous_standby_names 进行注释即可
调整之后重启主实例。
然后打开从实例的 postgresql.conf,注释
primary_conninfo
primary_slot_name
配置节点的信息,然后删除 data 目录下的 standby.signal 文件,重新启动从实例即可。
至此 Windows 环境搭建 PostgreSQL 物理复制高可用架构数据库服务 就讲解完了,有任何不明白的,可以在文章下面评论或者私信我,欢迎大家积极的讨论交流,有兴趣的朋友可以关注我目前在维护的一个 .NET 基础框架项目,项目地址如下
https://github.com/berkerdong/NetEngine.git
https://gitee.com/berkerdong/NetEngine.git
Windows 环境搭建 PostgreSQL 物理复制高可用架构数据库服务的更多相关文章
- Windows 环境搭建 PostgreSQL 逻辑复制高可用架构数据库服务
本文主要介绍 Windows 环境下搭建 PostgreSQL 的主从逻辑复制,关于 PostgreSQl 的相关运维文章,网络上大多都是 Linux 环境下的操作,鲜有在 Windows 环境下配置 ...
- mysql复制(高可用架构方案的基础)
mysql复制:把一个数据库实例上所有改变复制到另外一个数据库库服务器实例的过程特点:1.没有改变就无所谓复制 ;改变是复制的根本与数据源2.所有的改变:是指可以复制全部改变,也可以复制部分改变 可以 ...
- 004.Heartbeat+HAProxy+MySQL半复制高可用架构
一 基础环境 节点 系统版本 MySQL版本 业务IP 心跳IP Master CentOS 7.5 MySQL 5.6 192.168.88.100 192.168.77.100 Slave Cen ...
- Heartbeat+HAProxy+MySQL半复制高可用架构
目录 一 基础环境 二 架构设计 三 安装MySQL 3.1 安装MySQL 3.2 初始化MySQL 四 配置MySQL半同步 4.1 加载插件 4.2 配置半同步复制 4.3 master创建账号 ...
- PostgreSQL 流复制+高可用
QA PgPool-II 同步 Postgresql X1 服务器准备 192.168.59.121 PostgreSQL10 192.168.59.120 PGPool-II 3.7 X2 安装Po ...
- 搭建Hadoop的HA高可用架构(超详细步骤+已验证)
一.集群的规划 Zookeeper集群: 192.168.182.12 (bigdata12)192.168.182.13 (bigdata13)192.168.182.14 (bigdata14) ...
- MySQL高可用架构-MMM环境部署记录
MMM介绍MMM(Master-Master replication manager for MySQL)是一套支持双主故障切换和双主日常管理的脚本程序.MMM使用Perl语言开发,主要用来监控和管理 ...
- MySQL高可用架构-MHA环境部署记录
一.MHA介绍 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司) ...
- Redis 实战搭建高可用架构
前言:最近在看关于redis缓存方面的知识,今天就来个 Redis sentinel 高可用架构,实战开始之前,先看看sentinel的概念 什么是redis-sentinel Redis-Senti ...
随机推荐
- 介绍下Java内存区域(运行时数据区)
介绍下Java内存区域(运行时数据区) Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域.JDK 1.8 和之前的版本略有不同. 下图是 JDK 1.8 对JV ...
- 微软Azure配置中心 App Configuration (二):Feature Flag 功能开关特性
写在前面 Web服务开发过程中我们经常有这样的需求: 某些功能我必须我修改了配置才启用,比如新用户注册送券等: 某个功能需到特定的时间才启用,过后就失效,比如春节活动等: 某些功能,我想先对10%的用 ...
- Mac设置外网访问本地项目
> 官网地址:https://ngrok.com/download 步骤(官网基本已经说明了步骤,但还不完善,以下为亲测步骤): 下载并注册账号 打开终端,进入ngrok.zip所在文件夹(方法 ...
- P4675 [BalticOI 2016 day1]Park (并查集)
题面 在 Byteland 的首都,有一个以围墙包裹的矩形公园,其中以圆形表示游客和树. 公园里有四个入口,分别在四个角落( 1 , 2 , 3 , 4 1, 2, 3, 4 1,2,3,4 分别对应 ...
- HTML+JS+CSS 实现随机跳转到一个网址
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta http ...
- 钓鱼利用-CVE-2018-20250
钓鱼利用-CVE-2018-20250 漏洞影响版本 WinRAR < 5.70 Beta 1 Bandizip< = 6.2.0.0 好压(2345压缩) < = 5.9.8.10 ...
- 部署nfs
NFS可以让服务端跟客户端通过网络共享主机磁盘上的一些数据,主要是在unix和linux系统上实现的一种文件共享方式. 我们可以简单的将NFS看做是一个文件服务器 (file server) ...
- 【lwip】005-lwip内核框架剖析
目录 前言 5.1 lwip初始化 5.2 内核超时 5.2.1 内核超时机制 5.2.2 周期定时机制 5.2.3 内核超时链表数据结构 5.2.4 内核超时初始化 5.2.6 超时的溢出处理 5. ...
- GB/T 28181联网系统通信协议结构和技术实现
技术回顾 在本文开头,我们先一起回顾下GB/T28181联网系统通信协议结构: 联网系统在进行视音频传输及控制时应建立两个传输通道:会话通道和媒体流通道. 会话通道用于在设备之间建立会话并传输系统控制 ...
- JAVA中方法的调用主要有以下几种
JAVA中方法的调用主要有以下几种: 1.非静态方法 非静态方法就是没有 static 修饰的方法,对于非静态方法的调用,是通过对 象来调用的,表现形式如下. 对象名.方法() eg: public ...