vivo 故障定位平台的探索与实践
作者:vivo 互联网服务器团队- Liu Xin、Yu Dan
本文基于故障定位项目的实践,围绕根因定位算法的原理进行展开介绍。鉴于算法有一定的复杂度,本文通过图文的方式进行说明,希望即使是不懂技术的同学也能理解。
一、背景介绍
1.1 程序员的困扰
作为一名IT从业人员,比如开发和运维,多少有过类似的经历:睡觉的时候被电话叫醒,过节的时候在值班,游玩的时候被通知处理故障。作为一名程序员,我们时时刻刻都在想着运用信息技术,为别人解决问题,提升效率,节省成本。随着微服务架构的快速发展,带来一系列复杂的调用链路和海量的数据。对于我们来说,排查问题是一个大挑战,寻找故障原因犹如大海捞针,需要花费大量的时间和精力。
1.2 现状分析
vivo已经建立了一套完整的端到端监控体系,涵盖了基础监控、通用监控、调用链、日志监控、拨测监控等。这些系统每天都会产生海量的数据,如何利用好这些数据,挖掘数据背后的潜在价值,让数据更好的服务于人,成为了监控体系的探索方向。目前行业内很多厂商都在朝AIOps探索,业界有一些优秀的根因分析算法和论文,部分厂商分享了在故障定位实践中的解决方案。vivo有较完整的监控数据,业界有较完整的分析算法和解决方案,结合两者就可以将故障定位平台run起来,从而解决困扰互联网领域的定位问题。接下来我们看下实施的效果。
二、实施效果
目前主要针对平均时延指标的问题,切入场景包括两种:主动查询和调用链告警。
2.1 主动查询场景
当用户反馈某个应用很慢或超时,我们第一反应可能是查看对应服务的响应时间,并定位出造成问题的原因,通常这两个步骤是分别进行,需要用到一系列的监控工具,费时费力。如果使用故障定位平台,只需从vivo的paas平台上进入故障定位首页,找到故障服务和故障时间,剩下的事情就交给系统完成。
2.2 告警场景
当收到一条关于平均响应时间问题的调用链告警,只需查看告警内容下方的查看原因链接,故障定位平台就能帮助我们快速定位出可能的原因。下图是调用链告警示例:

调用链是vivo服务级监控的重要手段,上图红框内原因链接是故障定位平台提供的根因定位能力。
2.3 分析效果
通过以上两种方式进入故障定位平台后,首先看到的是故障现场,下图表示服务A的平均响应时间突增。
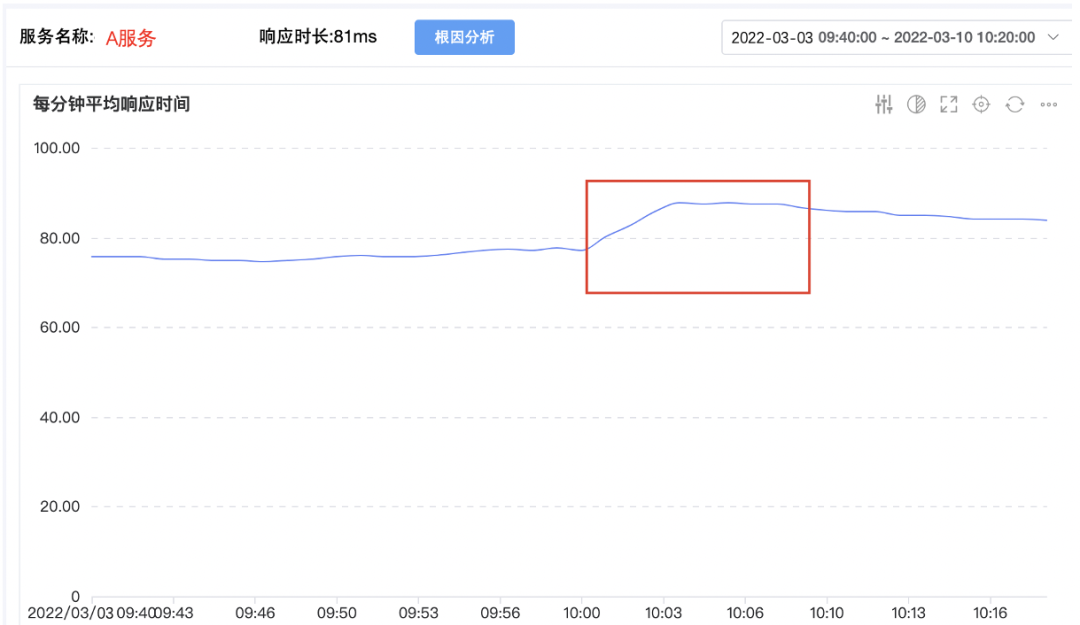
上图红框区域,A服务从10:00左右,每分钟平均时延从78ms开始增长,突增到10:03分的90ms左右。
直接点击图2蓝色的【根因分析】按钮,就可以分析出下图结果:
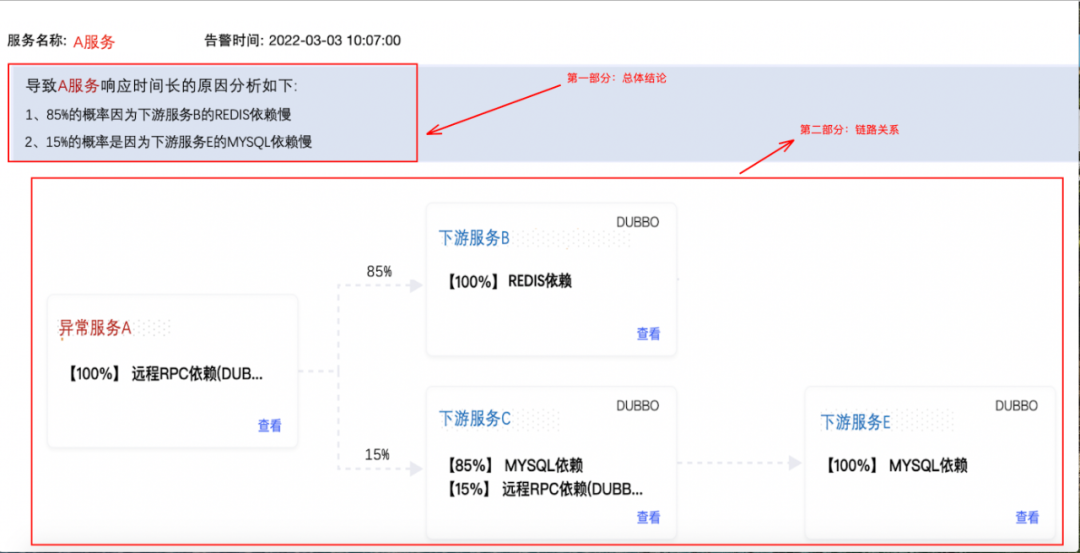
从点击按钮到定位出原因的过程中,系统是如何做的呢?接下来我们看下系统的分析流程。
三、分析流程
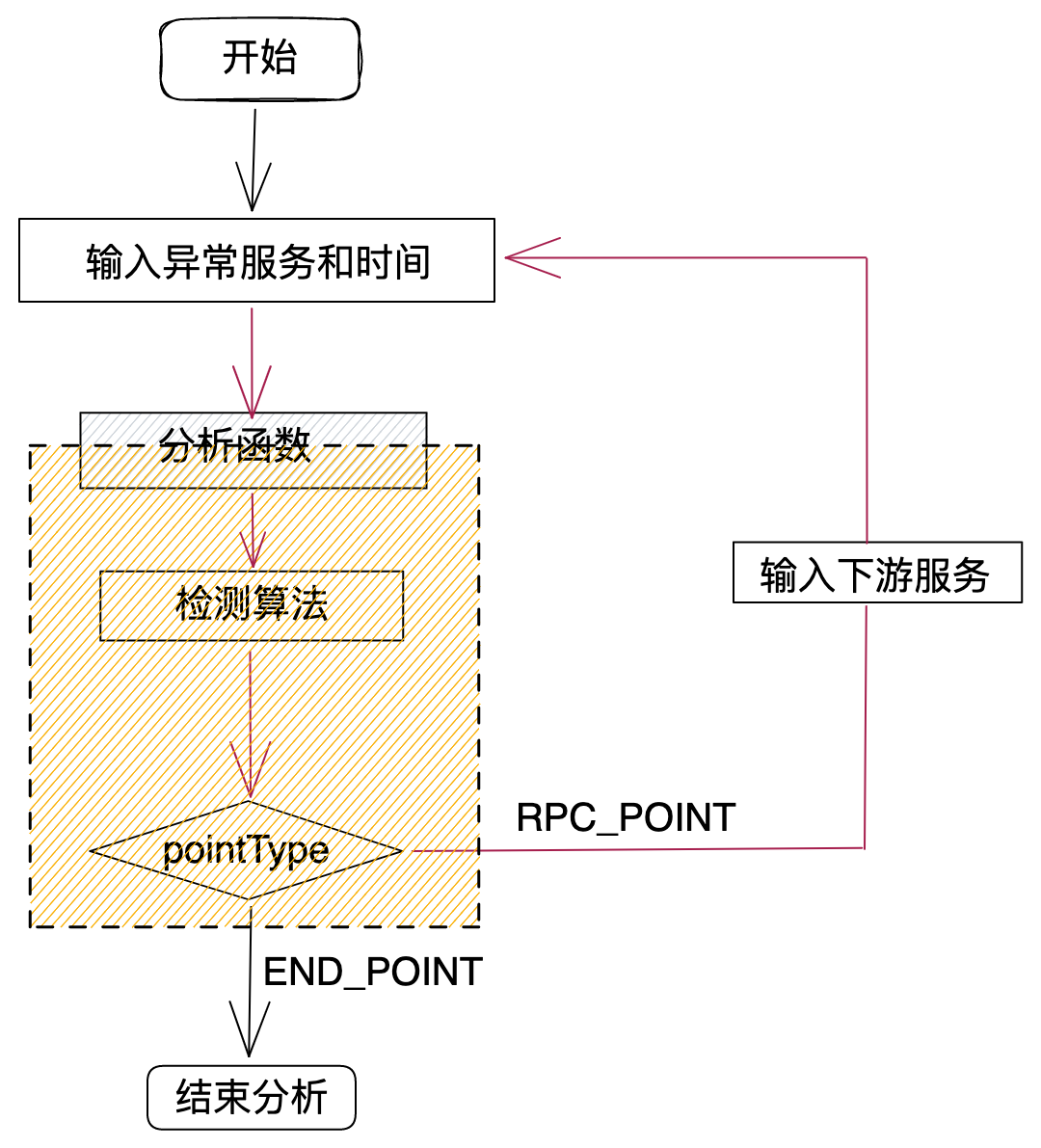
图4是根因分析的主要流程,下面将通过文字详细描述:
第一步:前端将异常服务名和时间作为参数通过接口传递到后端;
第二步:后端执行分析函数,分析函数调用检测算法,检测算法分析后,返回一组下游数据给分析函数(包括下游服务及组件、波动方差及pointType);
第三步:分析函数根据pointType做不同逻辑处理,如果pointType=END_POINT,则结束分析,如果pointType=RPC_POINT,则将下游服务作为入参,继续执行分析函数,形成递归。
RPC_POINT包含组件:HTTP、DUBBO、TARS
END_POINT包含组件:MYSQL、REDIS、ES、MONGODB、MQ
最终分析结果展示了造成服务A异常的主要链路及原因,如下图所示:

在整个分析过程中,分析函数负责调用检测算法,并根据返回结果决定是否继续下钻分析。而核心逻辑是在检测算法中实现的,接下来我们看下检测算法是如何做的。
四、检测算法
4.1 算法逻辑
检测算法的大体逻辑是:先分析异常服务,标记出起始时间、波动开始时间、波动结束时间。然后根据起始时间~波动结束时间,对异常服务按组件和服务名下钻,将得到的下游服务时间线分成两个区域:正常区域(起始时间~波动开始时间)和异常区域(波动开始时间~波动结束时间),最后计算出每个下游服务的波动方差。大体过程如下图所示:
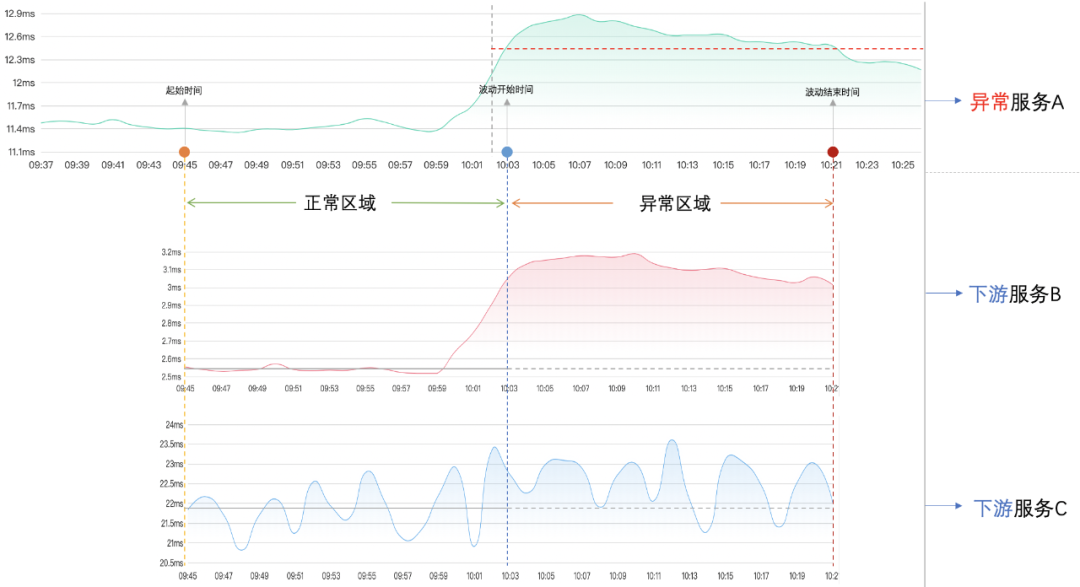
图中异常服务A调用了两个下游服务B和C,先标记出服务A的起始时间、波动开始时间、波动结束时间。然后将下游服务按时间线分成两个正常区域和异常区域,标准是起始时间 到 波动开始时间属于正常区域,波动开始时间 到 波动结束时间属于异常区域。
那么波动方差和异常原因之间有什么关联呢?
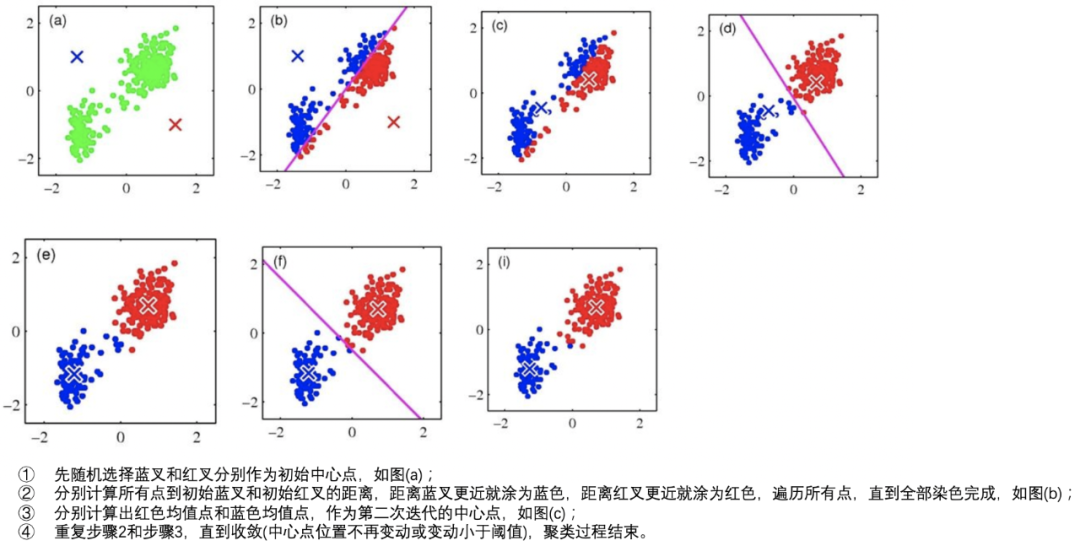
其实波动方差代表当前服务波动的一个量化值,有了这个量化值后,我们利用K-Means聚类算法,将波动方差值分类,波动大的放一起聚成一类,波动小的放一起聚成一类。如下图:
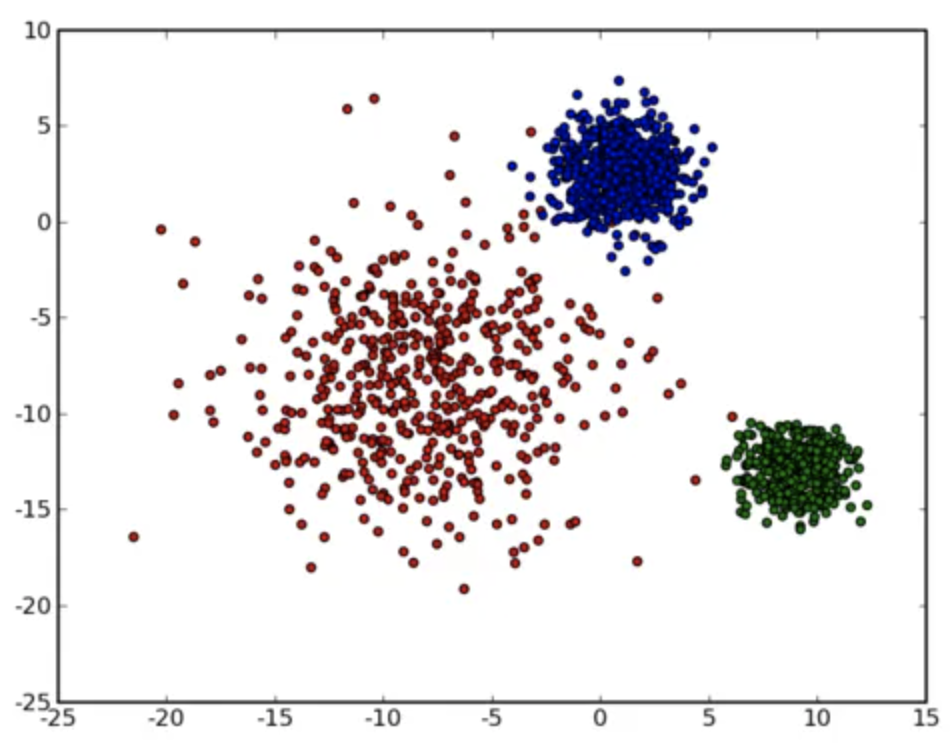
最后我们通过聚成类的波动方差,过滤掉波动小的聚类,找到最可能造成异常服务的原因。以上是对算法原理的简要介绍,接下来我们更进一步,深入到算法实现细节。
4.2 算法实现
(1)切分时间线:将异常时间线从中点一分为二,如下图:

(2) 计算波动标准差:运用二级指数平滑算法对前半段进行数据预测,然后根据观测值与预测值计算出波动标准差,如下图:
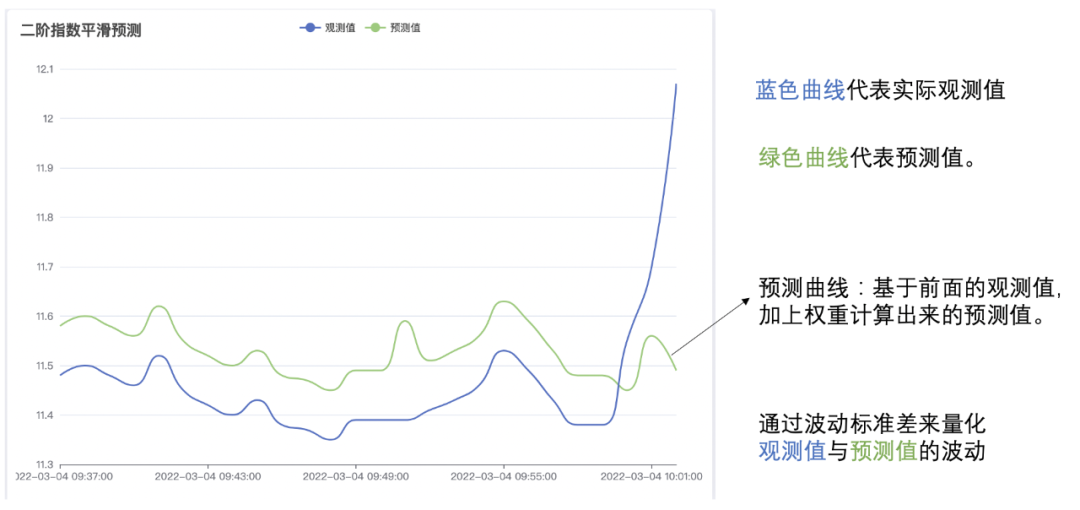
(3)计算异常波动范围:后半段大于3倍波动标准差的时间线属于异常波动,下图红线代表3倍波动标准差,所以异常波动是红线以上的时间线,如下图:

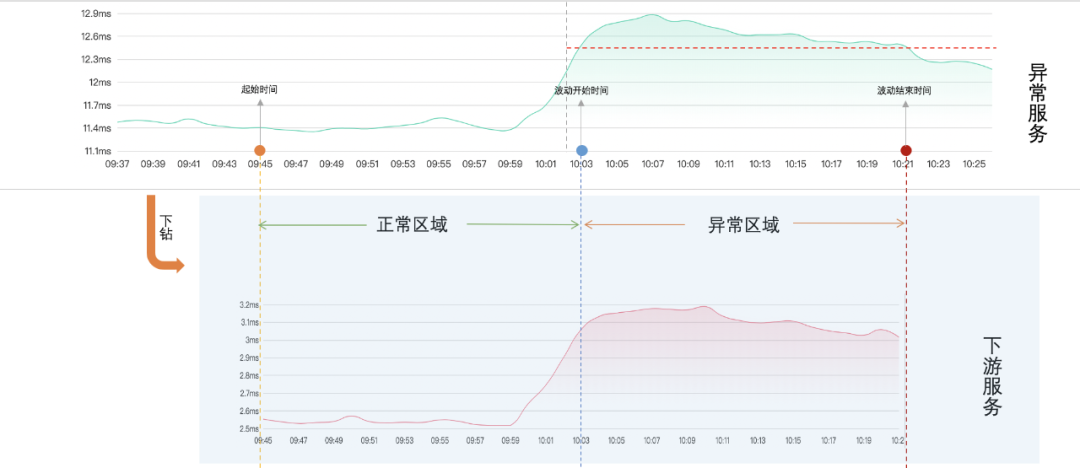
(4)时间点标记:红线与时间线第一次相交的时间点是波动开始时间,红线与时间线最后一次相交的时间点是波动结束时间,起始时间和波动结束时间关于波动开始时间对称,如下图:

(5)服务下钻:根据起始时间~波动结束时间,对异常服务按组件和服务名下钻,得到下游服务时间线,如下图:
(6)计算正常区域平均值:下游服务的前半段是正常区域,后半段是异常区域,先求出正常区域的平均值,如下图:
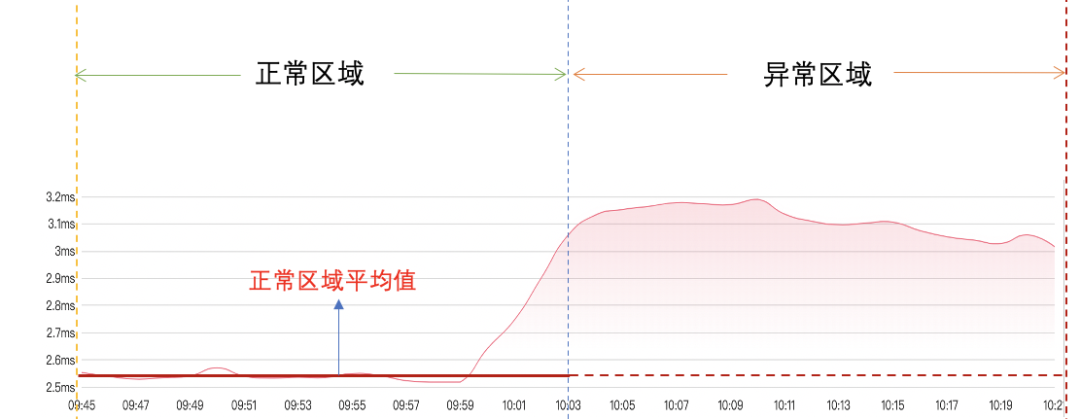
(7)计算异常区域波动方差:根据异常区域波动点与正常区域均值之间的波动计算波动方差和波动比率,如下图:
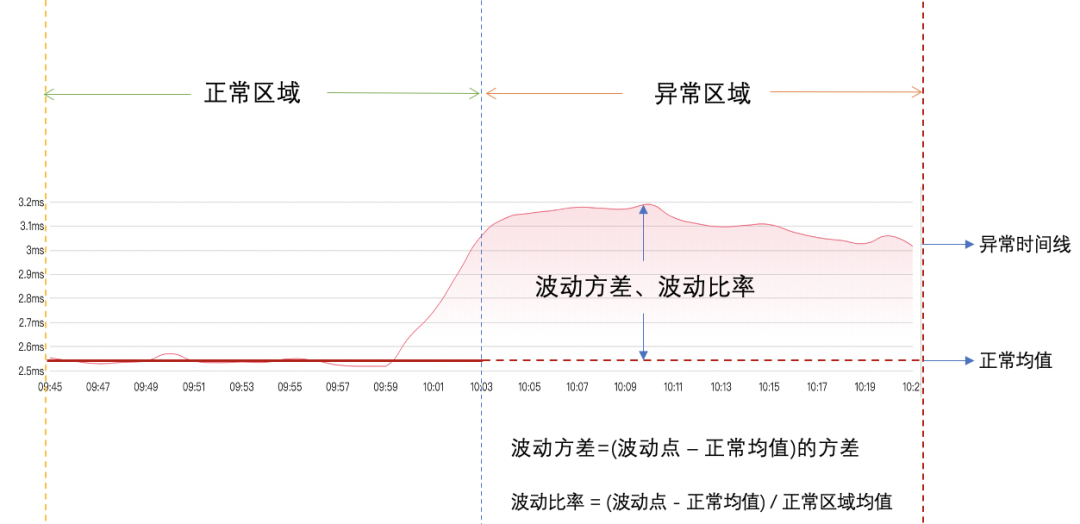
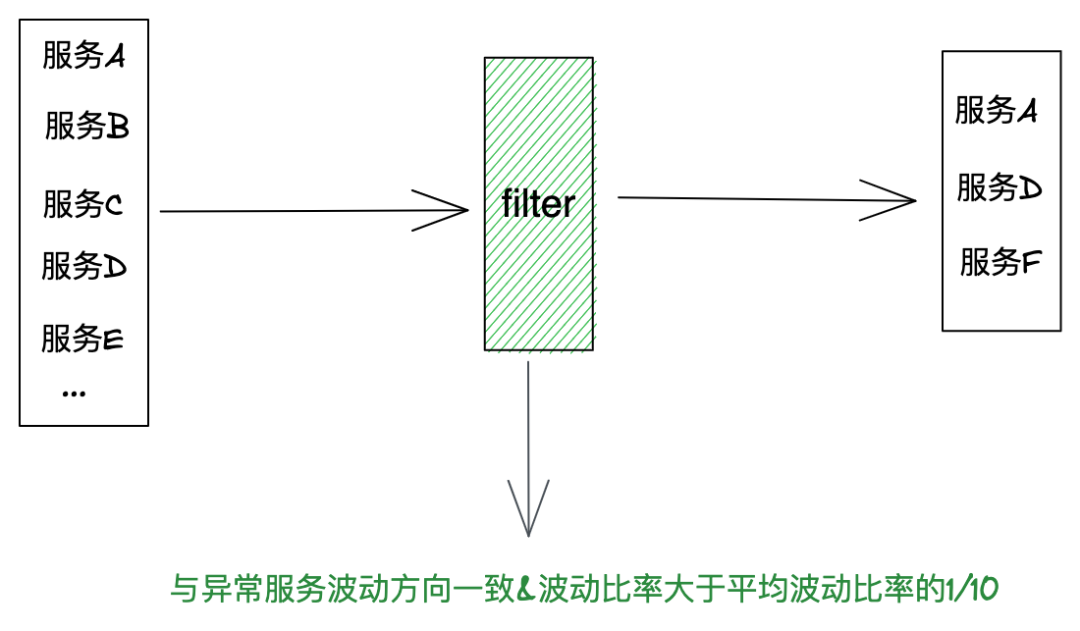
(8)时间线过滤:过滤掉波动方向相反、波动比率小于总波动比率的1/10的时间线,排除正常时间线,如下图:
(9)对剩余下钻时间线进行KMeans聚类,如下图:
五、简要总结
1、一种小而美的根因定位算法,利用方差量化波动,再通过排除法过滤掉波动小的下游,留下可能的下游作为原因。这种算法可以利用我们较完善的链路数据,可实现的成本低;
2、针对下游依赖场景的原因定位,准确率可达85%以上。但没有覆盖自身原因造成的故障(如GC、变更、机器问题等);
3、分析结果只能提供大概的线索,最后一公里还是需要人工介入;
4、故障定位算是AI领域的项目,开发方式与传统的敏捷开发有一定的区别:
角色职责:领域专家(提出问题) → AI专家(算法预研) → 算法专家(算法实现和优化) → 应用专家(工程化开发)
操作步骤:调研论文和git(业界、学界、同行) → 交流 → 实践 → 验证
项目实施:复杂问题简单化,先做简单部分;通用问题特例化,找出具体案例,先解决具体问题。
六、未来展望
1、故障预测:当前我们主要关注服务出现异常后,如何检测异常和定位根因,未来是否能够通过一些现象提前预判故障,将介入的时间点左移,防患于未然;
2、数据质量治理:当前我们的监控数据都有,但数据质量却参差不齐,而且数据格式的差异很大(比如日志数据和指标数据),我们在做机器学习或AIOps时,想要从中找出一些有价值的规律,其实挺难的;
3、经验知识化:当前我们的专家经验很多都在运维和开发同学的脑海中,如果将这些经验知识化,对于机器学习或AIOps将是一笔宝贵的财富;
4、从统计算法往AI算法演进:我们故障定位现在实际用的是统计算法,并没有用到AI。统计往往是一种强关系描述,而AI偏向弱关系,可以以统计算法为主,然后通过AI算法优化的方式。
参考资料
[1]Dapper, a Large-Scale Distributed Systems Tracing Infrastructure[EB/OL],2010-04-01.
[2]Holt-Winters Forecasting for Dummies (or Developers)[EB/OL],2016-01-29.
vivo 故障定位平台的探索与实践的更多相关文章
- 公有云上构建云原生 AI 平台的探索与实践 - GOTC 技术论坛分享回顾
7 月 9 日,GOTC 2021 全球开源技术峰会上海站与 WAIC 世界人工智能大会共同举办,峰会聚焦 AI 与云原生两大以开源驱动的前沿技术领域,邀请国家级研究机构与顶级互联网公司的一线技术专家 ...
- DataPipeline丨新型企业数据融合平台的探索与实践
文 |刘瀚林 DataPipeline后端研发负责人 交流微信 | datapipeline2018 一.关于数据融合和企业数据融合平台 数据融合是把不同来源.格式.特点性质的数据在逻辑上或物理上有机 ...
- vivo互联网机器学习平台的建设与实践
vivo 互联网产品团队 - Wang xiao 随着广告和内容等推荐场景的扩展,算法模型也在不断演进迭代中.业务的不断增长,模型的训练.产出迫切需要进行平台化管理.vivo互联网机器学习平台主要业务 ...
- 涂鸦基于OAuth2在开发者平台上的探索与实践
前言 开发授权(OAuth2)是一个开放标准,允许用户让第三方应用访问该用户在某一网站上存储的私密的资料(如照片.视频.联系人列表),而无需将用户名和密码提供给第三方应用. OAuth2允许用户提供一 ...
- 美团外卖Android平台化的复用实践
美团外卖平台化复用主要是指多端代码复用,正如美团外卖iOS多端复用的推动.支撑与思考文章所述,多端包含有两层意思:其一是相同业务的多入口,指美团外卖业务需要在美团外卖App(下文简称外卖App)和美团 ...
- FPGA加速:面向数据中心和云服务的探索和实践
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由columneditor 发表于云+社区专栏 作者介绍:章恒--腾讯云FPGA专家,目前在腾讯架构平台部负责FPGA云的研发工作,探索 ...
- 从C10K到C10M高性能网络的探索与实践
在高性能网络的场景下,C10K是一个具有里程碑意义的场景,15年前它给互联网领域带来了非常大的挑战.发展至今,我们已经进入C10M的场景进行网络性能优化. 这期间有怎样的发展和趋势?环绕着各类指标分别 ...
- zz深度学习在美团配送 ETA 预估中的探索与实践
深度学习在美团配送 ETA 预估中的探索与实践 比前一版本有改进: 基泽 周越 显杰 阅读数:32952019 年 4 月 20 日 1. 背景 ETA(Estimated Time of A ...
- 国产开源数据库:腾讯云TBase在分布式HTAP领域的探索与实践
导语 | TBase 是腾讯TEG数据平台团队在开源 PostgreSQL 的基础上研发的企业级分布式 HTAP 数据库系统,可在同一数据库集群中同时为客户提供强一致高并发的分布式在线事务能力以及高 ...
- 网络Devops探索与实践 流程管理分析师
https://mp.weixin.qq.com/s/OKLiDi78uB8ZkPG2kUVxvA 网络Devops探索与实践 王镇 鹅厂网事 2020-09-23 9月16日举办的2020 ODC ...
随机推荐
- 基于纯前端类Excel表格控件实现在线损益表应用
财务报表也称对外会计报表,是会计主体对外提供的反映企业或预算单位一定时期资金.利润状况的会计报表,由资产负债表.损益表.现金流量表或财务状况变动表.附表和附注构成.财务报表是财务报告的主要部分,不包括 ...
- 驱动开发:内核枚举LoadImage映像回调
在笔者之前的文章<驱动开发:内核特征码搜索函数封装>中我们封装实现了特征码定位功能,本章将继续使用该功能,本次我们需要枚举内核LoadImage映像回调,在Win64环境下我们可以设置一个 ...
- 微服务开发框架-----Apache Dubbo
文章目录 一.简介 二.概念与架构 一.简介 Apache Dubbo 是一款微服务开发框架,提供了RPC通信与微服务治理两大关键能力.使用Dubbo开发的微服务,将具备相互之间的远程发现与通信能力, ...
- Mockito使用方法(Kotlin)
一.为什么要使用Mockito 1.实际案例 1.1 遇到的问题 对于经常维护的项目,经常遇到一个实际问题:需求不停改变,导致架构经常需要修改某些概念的定义. 对于某些十分基础又十分常用的概念,常常牵 ...
- Windows7下驱动开发与调试体系构建——3.调试体系概述
目录/参考资料:https://www.cnblogs.com/railgunRG/p/14412321.html 调试体系概述 0.什么是自建调试体系? 就是复写windows的调试api,使得调试 ...
- VS2022连接Oracle数据库所需包和连接字符串
VS连接ORACLE数据库 l VS2022连接ORACLE数据库时,需要引入Oracle.ManagedDataAccess.Core包. l 引入方式:打开VS2022==>项目==&g ...
- HPL Study 2
1.并行编程 (1)并行程序的逻辑: 1)将当前问题划分为多个子任务 2)考虑任务间所需要的通信通道 3)将任务聚合成复合任务 4)将复合任务分配到核上 (2)共享内存编程: 路障 ----> ...
- mysql是如何实现mvcc的
mvcc的概念 mvcc即多版本并发控制,是一种并发控制的策略,能让数据库在高并发下做到安全高效的读写,提升数据库的并发性能; 是一种用来解决并发下读写冲突的无锁解决方案,为事务分配单向增长时间戳,为 ...
- jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一)
jdk线程池ThreadPoolExecutor工作原理解析(自己动手实现线程池)(一) 线程池介绍 在日常开发中经常会遇到需要使用其它线程将大量任务异步处理的场景(异步化以及提升系统的吞吐量),而在 ...
- 嵌入式-C语言基础:字符串拼接函数strcat
#include<stdio.h> #include <string.h> //实现字符串拼接 char * mystrcat(char * dest,char * src) ...