UVA 1401 Remember the Word(用Trie加速动态规划)
Remember the Word
Neal is very curious about combinatorial problems, and now here comes a problem about words. Knowing that Ray has a photographic memory and this may not trouble him, Neal gives it to Jiejie.
Since Jiejie can't remember numbers clearly, he just uses sticks to help himself. Allowing for Jiejie's only 20071027 sticks, he can only record the remainders of the numbers divided by total amount of sticks.
The problem is as follows: a word needs to be divided into small pieces in such a way that each piece is from some given set of words. Given a word and the set of words, Jiejie should calculate the number of ways the given word can be divided, using the words in the set.
Input
The input file contains multiple test cases. For each test case: the first line contains the given word whose length is no more than 300 000.
The second line contains an integer S <tex2html_verbatim_mark>, 1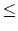 S4000 <tex2html_verbatim_mark>.
S4000 <tex2html_verbatim_mark>.
Each of the following S <tex2html_verbatim_mark>lines contains one word from the set. Each word will be at most 100 characters long. There will be no two identical words and all letters in the words will be lowercase.
There is a blank line between consecutive test cases.
You should proceed to the end of file.
Output
For each test case, output the number, as described above, from the task description modulo 20071027.
Sample Input
abcd
4
a
b
cd
ab
Sample Output
Case 1: 2
题目大意:背单词。给出一个由S个不同单词组成的字典和一个长字符串。把这个字符串分解成若干个单词的连接(单词可以重复使用),有多少种方法?比如,有4个单词a,b,cd,ab,则abcd有两种分解方法:a+b+cd和ab+cd.
分析:不难想到这样的递推法:令d(i)表示从字符i开始的字符串(即后缀S[i..L])的分解方案数,则d(i)=sum{d(i+len(x))|单词x是S[i..L]的前缀}。
如果先枚举x,再判断它是否为S[i..L]的前缀,时间无法承受(最多可能有4000个单词,判断还需要一定的时间)。可以换一个思路,先把所有单词组织成Trie,然后试着在Trie中“查找”S[i..L]。查找过程中每经过一个单词结点,就找到一个上述状态转移方程中的x,最多只需要比较100次就能能找到所有的x。
代码如下:
#include<cstring>
#include<vector>
using namespace std; const int maxnode = * + ;
const int sigma_size = ; // 字母表为全体小写字母的Trie
struct Trie {
int ch[maxnode][sigma_size];
int val[maxnode];
int sz; // 结点总数
void clear() { sz = ; memset(ch[], , sizeof(ch[])); } // 初始时只有一个根结点
int idx(char c) { return c - 'a'; } // 字符c的编号 // 插入字符串s,附加信息为v。注意v必须非0,因为0代表“本结点不是单词结点”
void insert(const char *s, int v) {
int u = , n = strlen(s);
for(int i = ; i < n; i++) {
int c = idx(s[i]);
if(!ch[u][c]) { // 结点不存在
memset(ch[sz], , sizeof(ch[sz]));
val[sz] = ; // 中间结点的附加信息为0
ch[u][c] = sz++; // 新建结点
}
u = ch[u][c]; // 往下走
}
val[u] = v; // 字符串的最后一个字符的附加信息为v
} // 找字符串s的长度不超过len的前缀
void find_prefixes(const char *s, int len, vector<int>& ans) {
int u = ;
for(int i = ; i < len; i++) {
if(s[i] == '\0') break;
int c = idx(s[i]);
if(!ch[u][c]) break;
u = ch[u][c];
if(val[u] != ) ans.push_back(val[u]); // 找到一个前缀
}
}
}; #include<cstdio>
const int maxl = + ; // 文本串最大长度
const int maxw = + ; // 单词最大个数
const int maxwl = + ; // 每个单词最大长度
const int MOD = ; int d[maxl], len[maxw], S;
char text[maxl], word[maxwl];
Trie trie; int main() {
int kase = ;
while(scanf("%s%d", text, &S) == ) {
trie.clear();
for(int i = ; i <= S; i++) {
scanf("%s", word);
len[i] = strlen(word);
trie.insert(word, i);
}
memset(d, , sizeof(d));
int L = strlen(text);
d[L] = ;
for(int i = L-; i >= ; i--) {
vector<int> p;
trie.find_prefixes(text+i, L-i, p);
for(int j = ; j < p.size(); j++)
d[i] = (d[i] + d[i+len[p[j]]]) % MOD;
}
printf("Case %d: %d\n", kase++, d[]);
}
return ;
}
UVA 1401 Remember the Word(用Trie加速动态规划)的更多相关文章
- UVA - 1401 Remember the Word(trie+dp)
1.给一个串,在给一个单词集合,求用这个单词集合组成串,共有多少种组法. 例如:串 abcd, 单词集合 a, b, cd, ab 组合方式:2种: a,b,cd ab,cd 2.把单词集合建立字典树 ...
- UVA 1401 - Remember the Word(Trie+DP)
UVA 1401 - Remember the Word [题目链接] 题意:给定一些单词.和一个长串.问这个长串拆分成已有单词,能拆分成几种方式 思路:Trie,先把单词建成Trie.然后进行dp. ...
- LA 3942 && UVa 1401 Remember the Word (Trie + DP)
题意:给你一个由s个不同单词组成的字典和一个长字符串L,让你把这个长字符串分解成若干个单词连接(单词是可以重复使用的),求有多少种.(算法入门训练指南-P209) 析:我个去,一看这不是一个DP吗?刚 ...
- UVA 1401 Remember the Word
字典树优化DP Remember the Word Time Limit: 3000MS Memory Limit: Unknown ...
- UVA 3942 Remember the Word (Trie+DP)题解
思路: 大白里Trie的例题,开篇就是一句很容易推出....orz 这里需要Trie+DP解决. 仔细想想我们可以得到dp[i]=sum(dp[i+len[x]]). 这里需要解释一下:dp是从最后一 ...
- UVA - 1401 | LA 3942 - Remember the Word(dp+trie)
https://vjudge.net/problem/UVA-1401 题意 给出S个不同的单词作为字典,还有一个长度最长为3e5的字符串.求有多少种方案可以把这个字符串分解为字典中的单词. 分析 首 ...
- POJ 3342 Party at Hali-Bula / HDU 2412 Party at Hali-Bula / UVAlive 3794 Party at Hali-Bula / UVA 1220 Party at Hali-Bula(树型动态规划)
POJ 3342 Party at Hali-Bula / HDU 2412 Party at Hali-Bula / UVAlive 3794 Party at Hali-Bula / UVA 12 ...
- uva 1401 dp+Trie
http://uva.onlinejudge.org/index.php? option=com_onlinejudge&Itemid=8&page=show_problem& ...
- UVa 1401 (Tire树) Remember the Word
d(i)表示从i开始的后缀即S[i, L-1]的分解方法数,字符串为S[0, L-1] 则有d(i) = sum{ d(i+len(x)) | 单词x是S[i, L-1]的前缀 } 递推边界为d(L) ...
随机推荐
- Struts2使用拦截器完成权限控制示例
http://aumy2008.iteye.com/blog/146952 Struts2使用拦截器完成权限控制示例 示例需求: 要求用户登录,且必须为指定用户名才可以查看系统中某个视图资源:否 ...
- 【Java基础】Java中的代码块
什么是代码块 在Java中,用{}括起来的代码称之为代码块. 代码块分类 局部代码块:在局部变量位置且用{}括起来的代码,用于限制局部变量的生命周期. 构造代码块:在类中的成员变量位置并用{}括起来的 ...
- tail -f logfile.log 一直监控某个文件,若该文件有改动,立即在屏幕上输出
tail -f logfile.log 可以一直监控某个文件,只要文件有改动,就立即在屏幕上输出
- hdu1839之二分+邻接表+Dijkstra+队列优化
Delay Constrained Maximum Capacity Path Time Limit: 10000/10000 MS (Java/Others) Memory Limit: 65 ...
- C++下字符串转换
引用自:http://blog.sina.com.cn/s/blog_a98e39a20101ari9.html 把最近用到的各种unicode下类型转换总结了一下,今后遇到其他的再补充: 1.str ...
- Android中解析JSON格式数据常见方法合集
待解析的JSON格式的文件如下: [{"id":"5", "version":"1.0", "name&quo ...
- 在Visual Studio中使用Pseudovariables来帮助调试
博客搬到了fresky.github.io - Dawei XU,请各位看官挪步.最新的一篇是:在Visual Studio中使用Pseudovariables来帮助调试.
- cookie的存值和取值方式
最近在开发中存储用户名信息,为了方便就使用了sessionStorage,但是写好才想到sessionStorage在IE下面是不支持的,所以无奈还是使用了cookie 那么接下来就谈谈怎么使用coo ...
- Delphi 读取CPU Id
在网上找了很久,终于找了一段能读出正确CPU ID 的代码,以下代码经过Delphi7测试 procedure TForm1.Button1Click(Sender: TObject); var _e ...
- sort函数的例子
10.11编写程序,使用stable_sort和isShorter将传递给你的elimDups版本的vector排序.打印vector的内容. #include<algorithm> #i ...