python运维开发之第二天
一、模块初识:
1、模块定义
python是由一系列的模块组成的,每个模块就是一个py为后缀的文件,同时模块也是一个命名空间,从而避免了变量名称冲突的问题。模块我们就可以理解为lib库,如果需要使用某个模块中的函数或对象,则要导入这个模块才可以使用,除了系统默认的模块不需要导入外。
2、os,sys,paltform模块
模块导入import module
import sys,os
print('------打印环境变量------')
print('打印sys.path结果',sys.path)
print('------打印脚本相对路径,在cmd中执行可以看出来------')
print('打印sys.argv结果',sys.argv)
print('----------------------#执行命令不保存结果,只返回执行状态-----------------------------------------')
cmd_output = os.system("dir")
print('打印os.system("dir")结果',cmd_output)
print('-----------#输出内存地址,需要read读取出结果--------------------')
rmd_res = os.popen("dir").read()
print("打印os.popen('dir').read()结果",rmd_res)
print('------------ 创建新文件夹(目录)------------------------------------------')
os.mkdir('new_dir')
os,sys模块
a、 os模块拓展
Python的标准库中的os模块主要涉及普遍的操作系统功能。可以在Linux和Windows下运行,与平台无关。
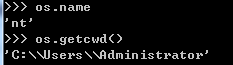
os.name字符串指示你正在使用的平台。比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'。
os.getcwd()函数得到当前工作目录,即当前Python脚本工作的目录路径。
os.getenv()和os.putenv()函数分别用来读取和设置环境变量。

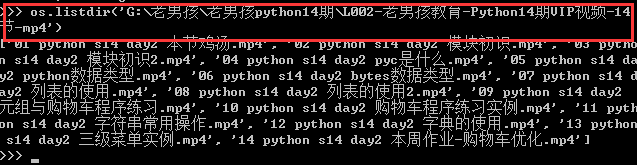
os.listdir()返回指定目录下的所有文件和目录名。
os.remove()函数用来删除一个文件。
os.system()函数用来运行shell命令。
 清屏
清屏

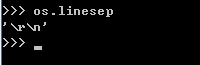
os.linesep字符串给出当前平台使用的行终止符。例如,Windows使用'\r\n',Linux使用'\n'而Mac使用'\r'。
os.path.split()函数返回一个路径的目录名和文件名。

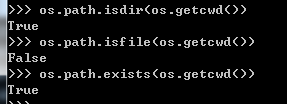
os.path.isfile()和os.path.isdir()函数分别检验给出的路径是一个文件还是目录。
os.path.exists()函数用来检验给出的路径是否真地存在
os.listdir(dirname):列出dirname下的目录和文件

os.chdir(dirname):改变工作目录到dirname

os.path.getsize(name):获得文件大小,如果name是目录返回0L

os.path.abspath(name):获得绝对路径

os.path.normpath(path):规范path字符串形式
os.path.split(name):分割文件名与目录(事实上,如果你完全使用目录,它也会将最后一个目录作为文件名而分离,同时它不会判断文件或目录是否存在)

os.path.splitext():分离文件名与扩展名
os.path.join(path,name):连接目录与文件名或目录
os.path.basename(path):返回文件名
os.path.dirname(path):返回文件路径

b、sys模块拓展
sys.argv 命令行参数List,第一个元素是程序本身路径
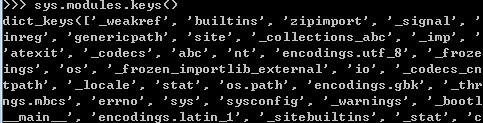
sys.modules.keys() 返回所有已经导入的模块列表
sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息

sys.exit(n) 退出程序,正常退出时exit(0)
sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
sys.version 获取Python解释程序的版本信息

sys.maxint 最大的Int值
sys.maxunicode 最大的Unicode值
sys.modules 返回系统导入的模块字段,key是模块名,value是模块
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息
sys.exec_prefix 返回平台独立的python文件安装的位置

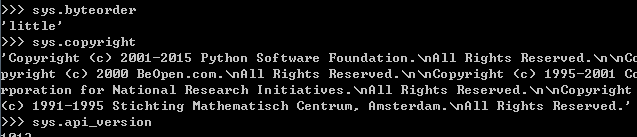
sys.byteorder 本地字节规则的指示器,big-endian平台的值是'big',little-endian平台的值是'little'
sys.copyright 记录python版权相关的东西
sys.api_version 解释器的C的API版本
sys.stdin,sys.stdout,sys.stderr变量包含与标准I/O流对应的流对象.如果需要更好地控制输出,而print不能满足你的要求,它们就是你所需要的.你也可以替换它们,这时候你就可以重定向输出和输入到其它设备(device),或者以非标准的方式处理它们
c、platform模块
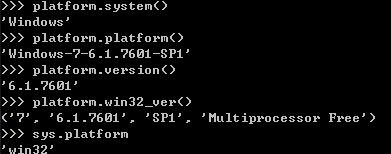
platform.system()获取操作系统类型,windows、linux等
platform.platform()获取操作系统,Darwin-9.8.0-i386-32bit
platform.version()获取系统版本信息6.2.0
platform.mac_ver()
platform.win32_ver()('post2008Server','6.2.9200','',u'MultiprocessorFree')
二 、 .pyc文件
1、什么是pyc文件
pyc是由py文件经过编译后二进制文件,py文件变成pyc文件后,加载的速度有所提高,而且pyc是一种跨平台的字节码,是由python的虚 拟机来执行的。pyc的内容,是跟python的版本相关的,不同版本编译后的pyc文件是不同的,2.5编译的pyc文件,2.4版本的 python是无法执行的。pyc文件也是可以反编译的,不同版本编译后的pyc文件是不同。
2、为什么需要pyc文件
这个需求太明显了,因为py文件是可以直接看到源码的,如果你是开发商业软件的话,不可能把源码也泄漏出去吧?所以就需要编译为pyc后,再发布出去。
3、pycodeobject与pyc文件关系
[CodeObject.py]
class A :
pass
def Fun():
pass
a = A()
Fun()
在Python编译完成后,一共会创建3个PyCodeObject对象,一个是对应CodeObject.py的,一个是对应class A这段Code(作用域),而最后一个是对应def Fun这段Code的。每一个PyCodeObject对象中都包含了每一个代码块经过编译后得到的byte code。但是不幸的是,Python在执行完这些byte code后,会销毁PyCodeObject,所以下次再次执行这个.py文件时,Python需要重新编译源代码,创建三个PyCodeObject,然后执行byte code。
很不爽,对不对?Python应该提供一种机制,保存编译的中间结果,即byte code,或者更准确地说,保存PyCodeObject。事实上,Python确实提供了这样一种机制——Pyc文件。
参考地址:http://my.oschina.net/renwofei423/blog/17404
三、数据类型
1、数字(整型,长整型,浮点型)(int,long,float)
x的值22,y的值3
#######################返回绝对值######################
abs(-x)
22
#######################加减乘除#######################
x+y,x-y,x*y,x/y
25 19 66 7.333333333333333
###################取商,浮点数相除保留余数###################
x/y
7.333333333333333
###################取商,浮点数相除余数为0###################
x//y
7
########################取余########################
x%y
1
########################幂次方#######################
x**y
10648 ####################################################
def __cmp__(self, y):
""" 比较两个数大小 """
""" x.__cmp__(y) <==> cmp(x,y) """
pass def __coerce__(self, y):
""" 强制生成一个元组 """
""" x.__coerce__(y) <==> coerce(x, y) """
pass def __divmod__(self, y):
""" 相除,得到商和余数组成的元组 """
""" x.__divmod__(y) <==> divmod(x, y) """
pass ######################转换为浮点型######################
float(33)
33.0
######################转换为字符串######################
<class 'int'>
str(x)
<class 'str'>
######################转换为16进制#####################
x=22,x数据类型<class 'int'>
hex(x)
0x16
######################转换为8进制######################
x=22,x数据类型<class 'int'>
oct(x)
0o26
运算
2、字符串(string)
name='abcdefg abcd'
#######################首字母大写######################
name.capitalize()
Abcdefg abcd
###################### 长度20居中#####################
name.center(20)
abcdefg abcd
################## 长度20里居中,其他用*填充#################
name.center(20,"*")
****abcdefg abcd****
#################长度20居左,rjust()居右#################
name.ljust(20)
abcdefg abcd
#####################字符串里a的个数#####################
name.count('a')
2
###################字符串指定区域里a的个数###################
name.count('a',0,10)
2
####################字符串是否以bc为结尾###################
name.endswith('bc')
False
#################把tab键转换为空格,默认8个空格################
name.expandtabs(8)
abcdefg abcd
############找字符b的下标,找不到返回-1,如果有多个只找第一个############
name.find('b')
1
###################找字符b的下标,找不到报错##################
name.index('b')
1
####################判断是否为字母或数字####################
name.isalnum()
False
######################判断是否为字母#####################
name.isalpha()
False
######################判断是否为数字#####################
name.isdigit()
False
######################判断是否小写######################
name.islower()
True
#####################判断是否都是空格#####################
name.isspace()
False
#####################判断是否全是大写#####################
name.isupper()
False
#######################全变小写#######################
name.lower()
abcdefg abcd
###########全变大写,name值并没变,name.upper()输出大写#########
name.upper()
ABCDEFG ABCD
print(name)的值
abcdefg abcd
####################大写变小写,小写变大写###################
name.swapcase()
abcdefg abcd
##################### 符合的全部替换#####################
name.replace('c','d')
abddefg abdd
####################移除空格字符两边空格####################
name.strip()
abcdefg abcd
#######################以b为分割######################
name.split('b')
['a', 'cdefg a', 'cd']
###################### #join######################
###################把列表的元素用*连接起来###################
li=["aa","bb"]
'*'.join(li)
aa*bb
###############变为标题,标题(所有首字母大写就是标题)###############
name.title()
Abcdefg Abcd
######################判断是不是标题#####################
name.istitle()
False
#####################partition####################
name='aaccbb'
#################分割成3部分 (aa,bb,cc)################
name.partition("cc")
('aa', 'cc', 'bb')
字符串方法
3、列表(list)
列表是Python中最基本的数据结构,列表是最常用的Python数据类型,列表的数据项不需要具有相同的类型。列表中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
Python有6个序列的内置类型,但最常见的是列表和元组。序列都可以进行的操作包括索引,切片,加,乘,检查成员。此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
a、切片
names = ["xzmly","cjk","wtl","bdyjy"]
#打印列表索引位第二个
names[1]
cjk
#打印列表第一个到第二个位置的元素 也可以写成 print(names[:2])
names[0:2]
['xzmly', 'cjk']
#打印列表倒数第三和第二个元素,这里的-1不能够省略
names[-3:-1]
['cjk', 'wtl']
#打印列表倒数3个元素
names[-3:]
['cjk', 'wtl', 'bdyjy']
#打印整个列表隔个打印,即步长为2,也可以写成print(names[::2])
names[0:-1:2]
['xzmly', 'wtl']
b、追加
names = ["xzmly","cjk","wtl","bdyjy"]
-----------#追加-------------
#列表最后添加一个元素"lzll"
names.append("lzll")
names值
['xzmly', 'cjk', 'wtl', 'bdyjy', 'lzll']
#列表索引位1前,插入“jzmb”,即原来的元素索引位1变为2
names.insert(1,"jzmb")
names值
['xzmly', 'jzmb', 'cjk', 'wtl', 'bdyjy', 'lzll']
c、改
names = ["xzmly","cjk","wtl","bdyjy"]
----------#修改--------------
names[0] = "wangdana"
查看names第一个元素变为"wangdana"
['wangdana', 'cjk', 'wtl', 'bdyjy']
d、删
names = ["xzmly","cjk","wtl","bdyjy"]
-----------#删除------------
-----------#这里删除里面是要知道具体的元素------------
names.remove("bdyjy")
#以下删除的是索引对应的元素,也可以写成names.pop(0)
del names[0]
names值
['cjk', 'wtl']
#删除names中索引为1的元素,不加索引,默认是删除最后一个元素
names.pop(1)
names值
['cjk']
e、查
names = ["xzmly","cjk","wtl","bdyjy"]
#查,索引 print(names.index())
----------#查询打印出'bdyjy'的索引号--------------
print(names.index("bdyjy"))
3
['xzmly', 'cjk', 'wtl', 'bdyjy']
names.count("bdyjy")是统计列表names中"bdyjy"有1个
f、Python列表操作的函数和方法
列表操作包含以下函数:
(1)、len(list):列表元素个数
#!/usr/bin/python list1, list2 = [123, 'xyz', 'zara'], [456, 'abc'] print "First list length : ", len(list1);
print "Second list length : ", len(list2);
实例
First list length : 3
Second lsit length : 2
结果
(2)、max(list):返回列表元素最大值
#!/usr/bin/python list1, list2 = [123, 'xyz', 'zara', 'abc'], [456, 700, 200] print "Max value element : ", max(list1);
print "Max value element : ", max(list2);
实例
Max value element : zara
Max value element : 700
结果
(3)、min(list):返回列表元素最小值
#!/usr/bin/python list1, list2 = [123, 'xyz', 'zara', 'abc'], [456, 700, 200] print "min value element : ", min(list1);
print "min value element : ", min(list2);
实例
min value element : 123
min value element : 200
结果
(4)、list(seq):将元组转换为列表
#!/usr/bin/python
# -*- coding: UTF-8 -*- aTuple = (123, 'xyz', 'zara', 'abc')
aList = list(aTuple) print "列表元素 : ", aList
实例
列表元素 : [123, 'xyz', 'zara', 'abc']
结果
列表操作包含以下方法:
(1)、list.append(obj):在列表末尾添加新的对象
(2)、list.count(obj):统计某个元素在列表中出现的次数
(3)、list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
(4)、list.index(obj):从列表中找出某个值第一个匹配项的索引位置
(5)、list.insert(index, obj):将对象插入列表
(6)、list.pop(obj=list[-1]):移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
(7)、list.remove(obj):移除列表中某个值的第一个匹配项
(8)、list.reverse():反转列表中元素顺序
(9)、list.sort([func]):对原列表进行排序,按ascii码排序
关于列表您可能感兴趣的文章:
- python中对list去重的多种方法
- python list 合并连接字符串的方法
- python中list循环语句用法实例
- Python求两个list的差集、交集与并集的方法
- Python列表list数组array用法实例解析
- python里对list中的整数求平均并排序
- python list语法学习(带例子)
- Python中字典(dict)和列表(list)的排序方法实例
- Python中列表(list)操作方法汇总
- Python实现list反转实例汇总
- Python找出list中最常出现元素的方法
4、元组(tuple)
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
a、创建空元组
元组中只包含一个元素时,需要在元素后面添加逗号;元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
tup1 = ()
tup1 = (50,)
b、元组的查跟列表相似,参考(3、列表(list));其中元组中的元素是不可变的,因此没有增删改元素。删除整个元组用 del tup1
c、元组函数有
(1)len(tuple)计算元组元素个数。(看3、列表)
(2)max(tuple)返回元组中元素最大值。(看3、列表)
(3)min(tuple)返回元组中元素最小值。(看3、列表)
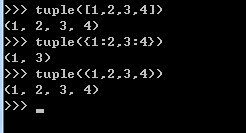
(4)tuple(seq)将列表转换为元组。
实例1:针对字典 会返回字典的key组成的tuple,元组返回自身
实例2:
aList = [123, 'xyz', 'zara', 'abc']
aTuple = tuple(aList)
print ("Tuple elements : ", aTuple)
#结果
Tuple elements : (123, 'xyz', 'zara', 'abc')
5、字典(dictionary)
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号{}中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组
a、字典查询
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print("dict['Name']: ", dict['Name'])
print("dict['Age']: ", dict['Age'])
print("dict['Alice']: ", dict['Alice'])
dict['Name']: Zara
dict['Age']: 7 #查询dict['Alice'],查询字典里没有的键时,会报错如下 Traceback (most recent call last): File "D:/Users/Administrator/PycharmProjects/s14/day2/test/dictionary.py", line 9, in <module> print("dict['Alice']: ", dict['Alice']) KeyError: 'Alice'
b、增加及修改字典元素
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
dict['Age'] = 8 # update existing entry
dict['School'] = "DPS School" # Add new entry
print("dict['Age']: ", dict['Age'])
print("dict['School']: ", dict['School'])
#结果
dict['Age']: 8
dict['School']: DPS School
c、删(del)
dict1 = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
del dict1['Name'] # 删除键是'Name'的条目
print(dict1)
dict1.clear() # 清空词典所有条目
print(dict1)
del dict1 # 删除词典
print(dict1)
实例
{'Age': 7, 'Class': 'First'}
{}
File "D:/Users/Administrator/PycharmProjects/s14/day2/test/dictionary.py", line 26, in <module>
print(dict1)
NameError: name 'dict1' is not defined
结果
d、字典特性
(1)不允许同一个键出现两次(无序性)
(2)键必须不可变,所以可以用数字,字符串或元组充当,但是用列表就不行。
dict = {['Name']: 'Zara', 'Age': 7}
输出结果
Traceback (most recent call last):
File "D:/Users/Administrator/PycharmProjects/s14/day2/test/dictionary.py", line 27, in <module>
dict = {['Name']: 'Zara', 'Age': 7};
TypeError: unhashable type: 'list'
实例及结果
e、字典内置函数及方法
(1)len(dict) 计算字典元素个数,即键的总数
(2)str(dict) 及type(dict)
dict1 = {'Name': 'Zara', 'Age': 7}
print(dict1)
print(type(dict1))
print(type(str(dict1)))
#结果
{'Name': 'Zara', 'Age': 7}
<class 'dict'>
<class 'str'>
实例及结果
(3)clear(dict) 删除字典中的所有元素
dict = {'Name': 'Zara', 'Age': 7}
print ("Start Len : %d" % len(dict))
dict.clear()
print ("End Len : %d" % len(dict))
#结果
Start Len : 2
End Len : 0
(4)dict.fromkeys(seq[,value]) 用于创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值。
seq = ('name', 'age', 'sex') #或者seq = ['name', 'age', 'sex']
dict = dict.fromkeys(seq)
print ("New Dictionary : %s" % str(dict))
dict = dict.fromkeys(seq,'')
print ("New Dictionary : %s" % str(dict))
#结果
New Dictionary : {'sex': None, 'age': None, 'name': None}
New Dictionary : {'sex': '', 'age': '', 'name': ''}
(5)dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回默认值。
dict = {'Name': 'Zara', 'Age': 27}
print ("Value : %s" % dict.get('Age'))
print ("Value : %s" % dict.get('Sex'))
#结果
Value : 27
Value : None
(6)dict.items() 以列表返回可遍历的(键, 值) 元组数组。
dict = {'Name': 'Zara', 'Age': 7}
print ("Value : %s" % dict.items())
#结果
Value : dict_items([('Age', 7), ('Name', 'Zara')])
(7)dict.keys() 函数以列表返回一个字典所有的键。
dict = {'Name': 'Zara', 'Age': 7}
print ("Value : %s" % dict.keys())
#结果
Value : dict_keys(['Name', 'Age'])
(8)dict.setdefault(key, default=None) 和get()方法类似, 如果键不已经存在于字典中,将会添加键并将值设为默认值。
dict = {'Name': 'Zara', 'Age': 7}
print ("Value : %s" % dict.setdefault('Age', None))
print ("Value : %s" % dict.setdefault('Sex', None))
print(dict)
#结果
Value : 7
Value : None
{'Age': 7, 'Sex': None, 'Name': 'Zara'}
(9)dict.update(dict2) 把字典dict2的键/值对更新到dict里;存在即替换,不存在即添加。
dict = {'Name': 'Zara', 'Age': 7}
dict2 = {"Name":"John",'Sex': 'female' }
dict.update(dict2)
print("Value : %s" % dict)
#结果
Value : {'Sex': 'female', 'Age': 7, 'Name': 'John'}
三、bytes
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。这是件好事。
a = '我是谁!'
print(a.encode(encoding='utf-8'))
print('-------------------------------')
print(a.encode(encoding='utf-8').decode(encoding='utf-8'))
#结果
b'\xe6\x88\x91\xe6\x98\xaf\xe8\xb0\x81\xef\xbc\x81'
-------------------------------
我是谁!
四、三元运算
result = 值1 if 条件 else 值2

如果a<b ,d的值等于a,否则d的值等于c
五、python中的赋值、深浅拷贝
python中关于对象复制有三种类型的使用方式,赋值、浅拷贝与深拷贝。
1、赋值
在python中,对象的赋值就是简单的对象引用,如下:
list_1 = ["Will", 28, ["Python", "C#", "JavaScript"]]
list_2 = list_1
print(id(list_1))
print(id(list_2))
print(list_1 is list_2)
#结果
10752520
10752520
True
赋值操作(包括对象作为参数、返回值)不会开辟新的内存空间,只是复制了对象的引用。
我们使用id(list_1)和id(list_2),可以看到内存地址一样;
并且用list_1 is list_b 来判断,返回值为True。
所以修改了list_1,就相当于修改了list_2,反之亦然!如下:
list_1 = ["Will", 28, ["Python", "C#", "JavaScript"]]
list_2 = list_1
list_2[0] = "Power"
print(list_1)
print(list_2)
#结果
['Power', 28, ['Python', 'C#', 'JavaScript']]
['Power', 28, ['Python', 'C#', 'JavaScript']]
2、浅拷贝
浅拷贝只是拷贝了第一层,
浅拷贝有三种形式:切片操作,工厂函数,copy模块中的copy函数
(1)切片操作
list_1 = ["Will", 28, ["Python", "C#", "JavaScript"]]
list_2 = list_1[:] #或者 list_2 = list_1[each for each in list_1]
print(list_2)
#结果
['Will', 28, ['Python', 'C#', 'JavaScript']]
(2)工厂函数
list_1 = ["Will", 28, ["Python", "C#", "JavaScript"]]
list_2 = list(list_1)
print(list_2)
#结果
['Will', 28, ['Python', 'C#', 'JavaScript']]
(3)copy.copy函数,需要import copy函数
import copy
list_1 = ["Will", 28, ["Python", "C#", "JavaScript"]]
list_2 = copy.copy(list_1)
print(list_2)
#结果
['Will', 28, ['Python', 'C#', 'JavaScript']]
浅拷贝产生的list_2不再是list_1了,使用is可以发现他们不是同一个对象,使用id查看,发现它们也不指向同一片内存。但是当我们使用 id(x) for x in list_1 和 id(x) for x in list_2 时,可以看到二者包含的元素的地址是相同的。验证如下:
import copy
list_1 = ["Will", 28, ["Python", "C#", "JavaScript"]]
list_2 = copy.copy(list_1)
print(list_1 is list_2)
print(id(list_1))
print(id(list_2))
print ([id(ele) for ele in list_1])
print ([id(ele) for ele in list_2])
#结果
False #is验证
17478472 #id(list_1)结果
17069192 #id(list_2)结果
[17019712, 1647571600, 17480264]
[17019712, 1647571600, 17480264]
如果我们修改了list_2中嵌套的那个list,情况就不一样了,验证如下:
import copy
list_1 = ["Will", 28, ["Python", "C#", "JavaScript"]]
list_2 = copy.copy(list_1)
list_2[0] = "Power"
print(list_1)
print(list_2)
list_2[2][0]="修改列表中嵌套列表中元素python"
print(list_1)
print(list_2)
#结果
['Will', 28, ['Python', 'C#', 'JavaScript']]
['Power', 28, ['Python', 'C#', 'JavaScript']]
['Will', 28, ['修改列表中嵌套列表中元素python', 'C#', 'JavaScript']]
['Power', 28, ['修改列表中嵌套列表中元素python', 'C#', 'JavaScript']]
3、深拷贝(copy模块中的deepcopy)
深拷贝就是对象的所有元素,包括多层嵌套的元素。验证如下:
import copy
list_1 = ["Will", 28, ["Python", "C#", "JavaScript"]]
list_2 = copy.deepcopy(list_1)
list_2[0] = "Power"
list_2[2][0]="修改列表中嵌套列表中元素python"
print(list_1)
print(list_2)
#结果
['Will', 28, ['Python', 'C#', 'JavaScript']]
['Power', 28, ['修改列表中嵌套列表中元素python', 'C#', 'JavaScript']]
所以深拷贝出来的对象list_2根本就是一个全新的对象,不再与原来的对象list_1有任何关联。
注:慎用深拷贝!!!
python运维开发之第二天的更多相关文章
- Python运维开发基础06-语法基础【转】
上节作业回顾 (讲解+温习120分钟) #!/usr/bin/env python3 # -*- coding:utf-8 -*- # author:Mr.chen # 添加商家入口和用户入口并实现物 ...
- Python运维开发基础03-语法基础 【转】
上节作业回顾(讲解+温习60分钟) #!/usr/bin/env python3 # -*- coding:utf-8 -*- # author:Mr.chen #只用变量和字符串+循环实现“用户登陆 ...
- 重磅|0元学 Python运维开发,别再错过了
51reboot 运维开发又双叒叕的搞活动了,鉴于之前 51reboot 的活动反馈,每次活动结束后(或者已经结束了很长时间)还有人在问活动的事情.这一次小编先声明一下真的不想在此次活动结束后再听到类 ...
- Python运维开发基础10-函数基础【转】
一,函数的非固定参数 1.1 默认参数 在定义形参的时候,提前给形参赋一个固定的值. #代码演示: def test(x,y=2): #形参里有一个默认参数 print (x) print (y) t ...
- Python运维开发基础09-函数基础【转】
上节作业回顾 #!/usr/bin/env python3 # -*- coding:utf-8 -*- # author:Mr.chen # 实现简单的shell命令sed的替换功能 import ...
- Python运维开发基础08-文件基础【转】
一,文件的其他打开模式 "+"表示可以同时读写某个文件: r+,可读写文件(可读:可写:可追加) w+,写读(不常用) a+,同a(不常用 "U"表示在读取时, ...
- Python运维开发基础07-文件基础【转】
一,文件的基础操作 对文件操作的流程 [x] :打开文件,得到文件句柄并赋值给一个变量 [x] :通过句柄对文件进行操作 [x] :关闭文件 创建初始操作模板文件 [root@localhost sc ...
- Python运维开发基础05-语法基础【转】
上节作业回顾(讲解+温习90分钟) #!/usr/bin/env python # -*- coding:utf-8 -*- # author:Mr.chen import os,time Tag = ...
- Python运维开发基础04-语法基础【转】
上节作业回顾(讲解+温习90分钟) #!/usr/bin/env python3 # -*- coding:utf-8 -*- # author:Mr.chen # 仅用列表+循环实现“简单的购物车程 ...
随机推荐
- 中文乱码问题(使用Servlet3.0新特性实现文件上传——上传文件名中文乱码问题)
问题描述:就是文件传送过来的文件名等是乱码 解决方法:将传送的JSP页面(即含有表单的页面)的页面编码方式改为: <%@ page contentType="text/html; ch ...
- apache启动目录(禁止目录)与设置默认入口文件的方法
设置默认入口文件的方法: 打开apache的conf目录,找到httpd.conf文件,打开这个文件,搜索dir_module,找到以下截图修改位置进行修改,注意重启apache服务器,修改位置才会生 ...
- lcx源代码以及免杀的研究
之前和Random大神讨论了一下免杀的问题,他给出了一个比较不错的想法,使用debug版本发布可以过很多杀软.顺便看了下lcx的源码,发现其代码不算特别复杂,于是乎就在这分析一下. 报毒情况 因为使用 ...
- mybatis01
mybatis是一个java持久层框架,java中操作关系型 数据库用的是jdbc,mybatis是对jdbc的一个封装. jdk1..0_72 eclipse:eclipse-3.7-indigo ...
- 重新格式化namenode后,出现java.io.IOException Incompatible clusterIDs
错误: java.io.IOException: Incompatible clusterIDs in /data/dfs/data: namenode clusterID = CID-d1448b9 ...
- 常用JDBC连接字符串
1.MySQL Class.forName( " org.gjt.mm.mysql.Driver " ); Connection conn = DriverManager.getC ...
- oracle合并查询
1). Union 该操作符用于取得两个结果集的并集.当使用该操作符时,会自动去掉结果集中重复行. 2).union all 该操作符与union相似,但是它不会取消重复行,而且不会排序. 3). I ...
- linux下实现redis共享session的tomcat集群
为了实现主域名与子域名的下不同的产品间一次登录,到处访问的效果,因此采用rediss实现tomcat的集群效果.基于redis能够异步讲缓存内容固化到磁盘上,从而当服务器意外重启后,仍然能够让sess ...
- jQuery给CheckBox添加事件
<asp:CheckBox ID="ckbTable" runat="server" Checked="false" /> &l ...
- app抓包
http://www.360doc.com/content/14/1126/11/9200790_428168701.shtml 记得下载证书 不然有些网站是抓不到的