<<attention is all you need>>速读笔记
背景
在seq2seq中,一般是有一个encoder 一个decoder ,一般是rnn/cnn 但是rnn 计算缓慢,所以提出了纯用注意力机制来实现编码解码。
模型结构
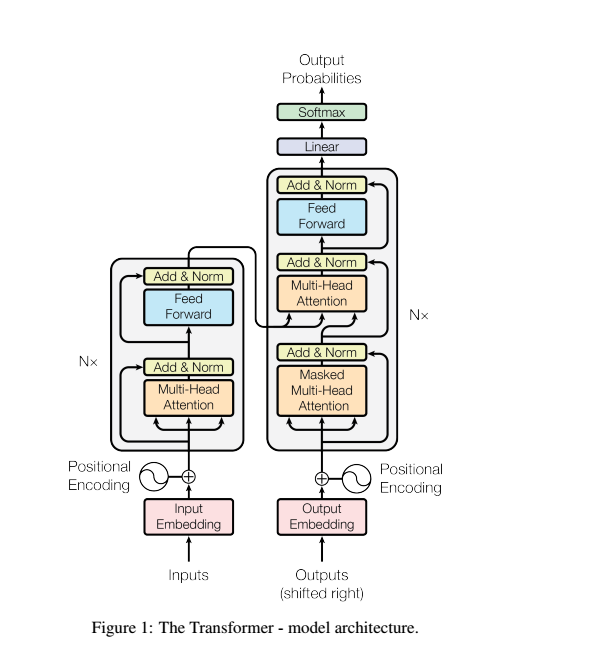
大部分神经序列转导模型都有一个编码器-解码器结构。这里,编码器映射一个用符号表示的输入序列(x1,...,xn) 到一个连续的表示z = (z1,...,zn)。 根据z,解码器生成符号的一个输出序列(y1,...,ym) ,
一次一个元素。 当生成下一个时,消耗先前生成的符号作为附加输入。
Encoder and Decoder Stack
Encoder
6个完全相同的层组成,每层包含2个sub层,分别是multi-head self-attention mechanism 、position wise fully connected feed-forward network.
用residual connection 连接2个sub层,再加入normalization.所以最后每层的输出是每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x) 是由子层本身实现的函数。
为了方便这些残差连接,模型中的所有子层以及嵌入层产生的输出维度都为dmodel = 512。
decoder
解码器同样由N = 6 个完全相同的层堆叠而成。 除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该层对编码器堆栈的输出执行multi-head attention。
与编码器类似,我们在每个子层再采用残差连接,然后进行层标准化。 我们还修改解码器堆栈中的self-attention子层,以防止位置关注到后面的位置。
这种掩码结合将输出嵌入偏移一个位置,确保对位置的预测 i 只能依赖小于i 的已知输出。
Attention
Attention函数可以描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向量。 输出为value的加权和,其中分配给每个value的权重通过query与相应key的兼容函数来计算。
query 与key 的match 度得到权重,权重加在val 上 ,val加权和是输出。
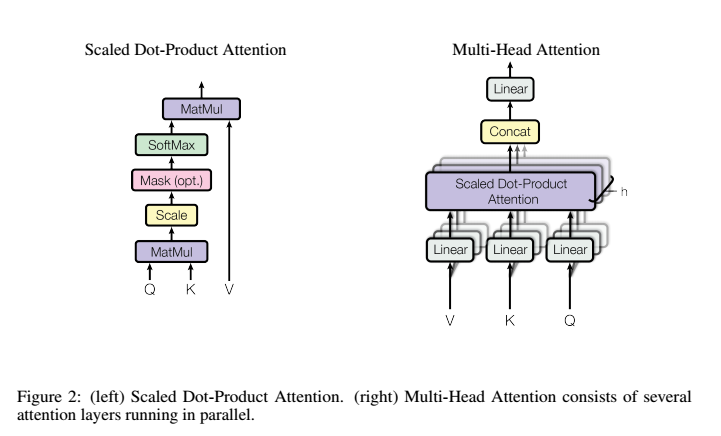
3.2.1 Scaled Dot-Product Attention
输入由query、dk 维的key和dv 维的value组成。 我们计算query和所有key的点积、用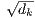 相除,然后应用一个softmax函数以获得值的权重。
相除,然后应用一个softmax函数以获得值的权重。
在实践中,我们同时计算一组query的attention函数,并将它们组合成一个矩阵Q。 key和value也一起打包成矩阵 K 和 V 。 我们计算输出矩阵为:
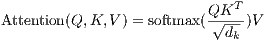 |
(1) |
两个最常用的attention函数是加法attention和点积(乘法)attention。 除了缩放因子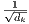 之外,点积attention与我们的算法相同。 加法attention使用具有单个隐藏层的前馈网络计算兼容性函数。 虽然两者在理论上的复杂性相似,但在实践中点积attention的速度更快、更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
之外,点积attention与我们的算法相同。 加法attention使用具有单个隐藏层的前馈网络计算兼容性函数。 虽然两者在理论上的复杂性相似,但在实践中点积attention的速度更快、更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
当dk的值比较小的时候,这两个机制的性能相差相近,当dk比较大时,加法attention比不带缩放的点积attention性能好。 我们怀疑,对于很大的dk值,点积大幅度增长,将softmax函数推向具有极小梯度的区域4。 为了抵消这种影响,我们缩小点积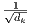 倍。
倍。
3.2.2 Multi-Head Attention
我们发现将query、key和value分别用不同的、学到的线性映射h次到dk、dk和dv维效果更好,而不是用d model维的query、key和value执行单个attention函数。 基于每个映射版本的query、key和value,我们并行执行attention函数,产生dv 维输出值。 将它们连接并再次映射,产生最终值,如图所示 2。
Multi-head attention允许模型的不同表示子空间联合关注不同位置的信息。 如果只有一个attention head,它的平均值会削弱这个信息。

在这项工作中,我们采用h = 8 个并行attention层或head。 对每个head,我们使用dk =dv =dmodel ∕ h = 64。 由于每个head的大小减小,总的计算成本与具有全部维度的单个head attention相似。其中,映射为参数矩阵WiQ ∈ ℝdmodel×dk , WiK ∈ ℝdmodel×dk , WiV ∈ ℝdmodel×dv 及W O ∈ ℝhdv×dmodel。
3.2.3 Applications of Attention in our Model
Transformer使用以3种方式使用multi-head attention:
- 在“编码器—解码器attention”层,query来自前一个解码器层,key和value来自编码器的输出。 这允许解码器中的每个位置能关注到输入序列中的所有位置。 这模仿序列到序列模型中典型的编码器—解码器的attention机制,例如[38, 2, 9]。
- 编码器包含self-attention层。 在self-attention层中,所有的key、value和query来自同一个地方,在这里是编码器中前一层的输出。 编码器中的每个位置都可以关注编码器上一层的所有位置。
- 类似地,解码器中的self-attention层允许解码器中的每个位置都关注解码器中直到并包括该位置的所有位置。 我们需要防止解码器中的向左信息流来保持自回归属性。 通过屏蔽softmax的输入中所有不合法连接的值(设置为-∞),我们在缩放版的点积attention中实现。 见图 2.
3.3 Position-wise Feed-Forward Networks
除了attention子层之外,我们的编码器和解码器中的每个层都包含一个完全连接的前馈网络,该前馈网络单独且相同地应用于每个位置。 它由两个线性变换组成,之间有一个ReLU激活。
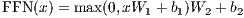 |
(2) |
尽管线性变换在不同位置上是相同的,但它们层与层之间使用不同的参数。 它的另一种描述方式是两个内核大小为1的卷积。 输入和输出的维度为dmodel = 512,内部层的维度为dff = 2048。
3.4 Embeddings and Softmax
与其他序列转导模型类似,我们使用学习到的嵌入将输入词符和输出词符转换为维度为dmodel的向量。 我们还使用普通的线性变换和softmax函数将解码器输出转换为预测的下一个词符的概率。 在我们的模型中,两个嵌入层之间和pre-softmax线性变换共享相同的权重矩阵,类似于[30]。 在嵌入层中,我们将这些权重乘以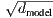 。
。
3.5 Positional Encoding
由于我们的模型不包含循环和卷积,为了让模型利用序列的顺序,我们必须注入序列中关于词符相对或者绝对位置的一些信息。 为此,我们将“位置编码”添加到编码器和解码器堆栈底部的输入嵌入中。 位置编码和嵌入的维度dmodel相同,所以它们俩可以相加。有多种位置编码可以选择,例如通过学习得到的位置编码和固定的位置编码[9]。
在这项工作中,我们使用不同频率的正弦和余弦函数:
| PE(pos,2i) = sin(pos ∕ 100002i ∕ dmodel) | ||
| PE(pos,2i+1) = cos(pos ∕ 100002i ∕ dmodel) |
其中pos 是位置,i 是维度。 也就是说,位置编码的每个维度对应于一个正弦曲线。 这些波长形成一个几何级数,从2π 到10000 ⋅2π。 我们选择这个函数是因为我们假设它允许模型很容易学习对相对位置的关注,因为对任意确定的偏移k, PEpos+k可以表示为PEpos的线性函数。
我们还使用学习到的位置嵌入9进行了试验,发现这两个版本产生几乎相同的结果(参见表 3 行(E))。 我们选择了正弦曲线,因为它可以允许模型推断比训练期间遇到的更长的序列。
每个位置对应一个向量,不可训练的。
对于每个句子,位置向量是相同的。
参考:
https://www.yiyibooks.cn/yiyibooks/Attention_Is_All_You_Need/index.html
https://www.jianshu.com/p/3f2d4bc126e6
<<attention is all you need>>速读笔记的更多相关文章
- 写shell脚本速查笔记
linux shell脚本的语法蛋疼,而且对于java开发人员来说又不常用,常常是学了一次等到下次用的时候又忘记了.因此制作这个速查笔记,用于要写shell脚本时快速回忆&速查. 获取当前脚本 ...
- 提升 composer 的执行速读
常常遇到 php composer.phar update 等待一二十分钟还没有更新完成的情况. 提升速读的方法: 1. 升级PHP 版本到5.4以上 2. 删除文件夹Vender(或者重命名),之后 ...
- 沈逸老师ubuntu速学笔记(2)-- ubuntu16.04下 apache2.4和php7结合编译安装,并安裝PDOmysql扩展
1.编译安装apache2.4.20 第一步: ./configure --prefix=/usr/local/httpd --enable-so 第二步: make 第三步: sudo make i ...
- 沈逸老师ubuntu速学笔记(1)--安装flashplayer,配置中文输入法以及常用命令
开篇首先感谢程序员在囧途(www.jtthink.com)以及沈逸老师,此主题笔记主要来源于沈老师课程.同时也感谢少年郎,秦少.花旦等同学分享大家的学习笔记. 1.安装flash player ctr ...
- java字节码速查笔记
java字节码速查笔记 发表于 2018-01-27 | 阅读次数: 0 | 字数统计: | 阅读时长 ≍ 执行原理 java文件到通过编译器编译成java字节码文件(也就是.class文件) ...
- Makefile速查笔记
Makefile速查笔记 Makefile中的几个调试方法 一. 使用 info/warning/error 增加调试信息 a. $(info "some text")打印 &qu ...
- spring-cloud-square源码速读(spring-cloud-square-okhttp篇)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- spring-cloud-square源码速读(retrofit + okhttp篇)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos spring-cloud-square系列文章 五分钟 ...
- 【论文速读】Pan He_ICCV2017_Single Shot Text Detector With Regional Attention
Pan He_ICCV2017_Single Shot Text Detector With Regional Attention 作者和代码 caffe代码 关键词 文字检测.多方向.SSD.$$x ...
随机推荐
- openssl编译参数选项
执行Configure是常见参数选项如下: 安装参数: --openssldir=OPENSSLDIR 安装目录,默认是 /usr/local/ssl . --prefix=PREFIX 设置 lib ...
- 【Python全栈-后端开发】嵩天老师-Django
嵩天老师-Python云端系统开发入门教程(Django) 视频地址:https://www.bilibili.com/video/av19801429 课前知识储备: 一.课程介绍: 分久必合.合久 ...
- nodejs 学习五 单元测试一
一. chai chai 自身是依赖nodejs的 assert,让检测更加语义化. chai 采用两种模式,TDD和BDD, TDD是类似自然语言方式 BDD是结构主义 chai文旦地址 二.moc ...
- C#-1-2-C#基础
1-注释符 1).单行注释符:// 2).多行注释符:/**/ 3).文档注释符:// 2-常用快捷键 3-变量类型 4-转义字符 5-语句 1.将相应内容打印到控制台:Console.WriteLi ...
- (1.7)mysql profiles分析
mysql profiles分析 作用:记录会话查询SQL所用时间 1.开启 2.使用 [2.1]先使用一个查询 [2.2]然后再运行 show profiles; [2.3]查看执行过程中每个状态和 ...
- wamp设置本地访问路径为a.com
我们在用wamp进行本地建站时经常会碰到页面样式无法正常加载,这是因为没有正确加载css路径,那我们就用wamp设置本地访问路径为a.com指向本地的一个虚拟空间,如何操作呢?下面就跟随ytkah一起 ...
- OC常用控件封装
#import <Foundation/Foundation.h> #import <UIKit/UIKit.h> @interface CreateUI : NSObject ...
- docker安装fastdfs单机版
docker search fastdfs INDEX NAME DESCRIPTION STARS OFFICIAL AUTOMATED docker.io docker.io/season/fas ...
- 20171018 在小程序页面去获取用户的OpenID
1. 在小程序的.js 文件中增加代码 //加载页面时到后台服务去获取openID onLoad: function (options) { //OpenId wx.login({ //获取code ...
- Python3学习之路~2.8 文件操作实现简单的shell sed替换功能
程序:实现简单的shell sed替换功能 #实现简单的shell sed替换功能,保存为file_sed.py #打开命令行输入python file_sed.py 我 Alex,回车后会把文件中的 ...