李宏毅机器学习笔记1:Regression、Error
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube、网易云课堂、B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对这些知识内容的理解与补充。(本笔记配合李宏毅老师的视频一起使用效果更佳!)
今天这篇文章的主要内容是第1-2课的笔记。
ML Lecture 1: Regression - Demo
1.Machine Learning最主要有三个步骤:(1)选择a set of function,也就是选择一个合适的model。(2)评价你选择的function。:因为有许多的函数,我们要通过一个确定的方式去挑选出最好的函数,通常我们用loss function 去评价一个函数的好坏。(3)通过评价和测试,选择出Best function。
2.课程中提供的主要例子是预测宝可梦进化后的CP值,一只宝可梦可由5个参数表示,x=(x_cp, x_s, x_hp, x_w, x_h)。我们在选择 model 的时候先选择linear model。接下来评价goodness of function ,它类似于函数的函数,我们输入一个函数,输出的是how bad it is,这就需要定义一个loss function。在所选的model中,随着参数的不同,有着无数个function(即,model确定之后,function是由参数所决定的),每个function都有其loss,选择best function即是选择loss最小的function(参数),求解最优参数的方法可以是gradient descent!
3.gradient descent 的步骤是:(1)随机初始化参数。(2)再向损失函数对参数的负梯度方向迭代更新。(3)learning rate控制步子大小、学习速度。梯度方向是损失函数等高线的法线方向。
4.gradient descent可能带来的问题:(1)得到的是局部最小值,而不是全局最小值。(2)若存在鞍点,也不容易得到最佳解。不过在线性回归中利用梯度下降算法得到的解一定是全局最小值,因为线性回归中的损失函数是凸的。(有关梯度下降的原理、分类等具体看下一篇文章)
5.很容易想到,刚刚我们用了一次方程作为model,二次方程会不会更好一些呢,三次方程、四次方程呢?于是我们做了以下实验,用同样的方法,放到多次方程中。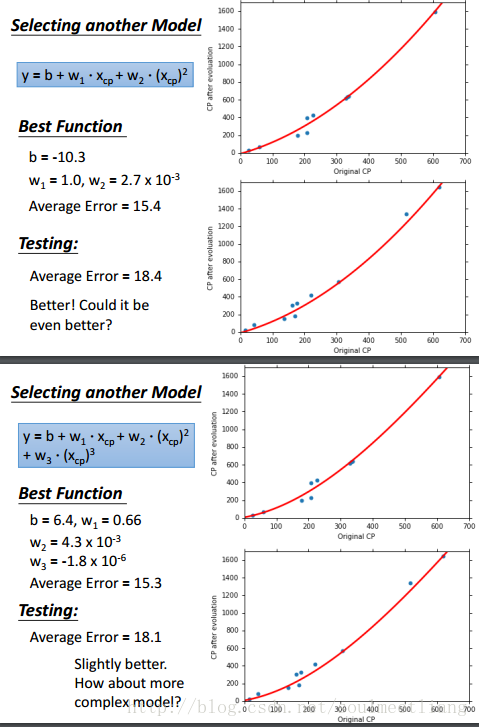
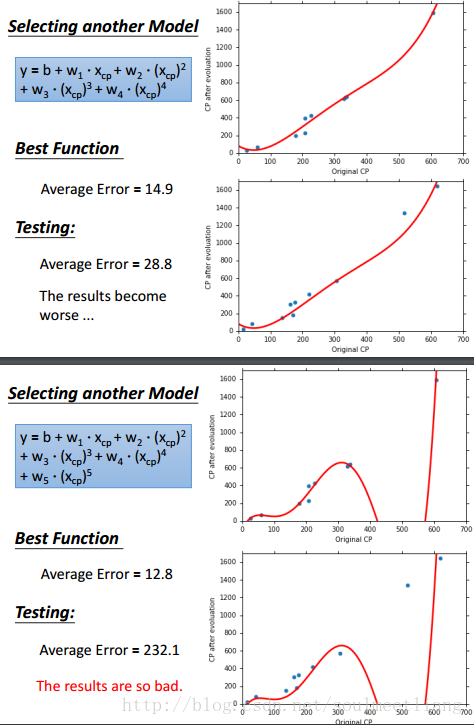
6.通过上面四幅图可以看出,虽然当我们增加函数次数时,可以使training data的Average Error越来越小,但是Test data的表现却不尽如人意,甚至在五次方程时,大大超出了我们的预估,那么这种现象就叫做overfitting。在得到best function之后,我们真正在意的是它在testing data上的表现。选择不同的model,会得到不同 的best function,它们在testing data 上有不同表现。复杂模型的model space涵盖了简单模型的model space,因此在training data上的错误率更小,但并不意味着在testing data 上错误率更小。模型太复杂会出现overfitting。
7.解决Overfitting的两种方法:(1)Redesign the Model Again。(2)Regularization,对线性模型来讲,希望选出的best function 能 smooth一些,也就是权重系数小一些,因为这样的话,在测试数据受噪声影响时,预测值所受的影响会更小。 所以在损失函数中加一个正则项 λΣ(w_i)^2。 越大的λ,对training error影响不大,主要是用于降低testing error, 我们希望函数smooth,但也不能太smooth。 调整λ,选择使testing error最小的λ.如下图所示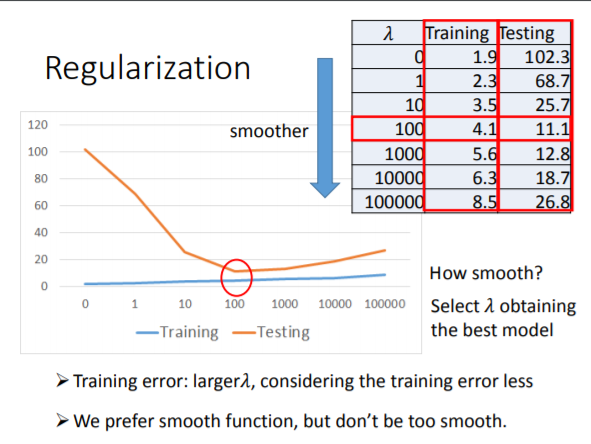
ML Lecture 2: Where does the error come from?
1.error主要有两种来源:(1)bias(偏差)。(2)variance(方差)
2.对于bias和variance的个人理解:
(1)bias :度量了某种学习算法的平均估计结果所能逼近学习目标的程度;(一个高的偏差意味着一个坏的匹配)
variance :则度量了在面对同样规模的不同训练集时分散程度。(一个高的方差意味着一个弱的匹配,数据比较分散)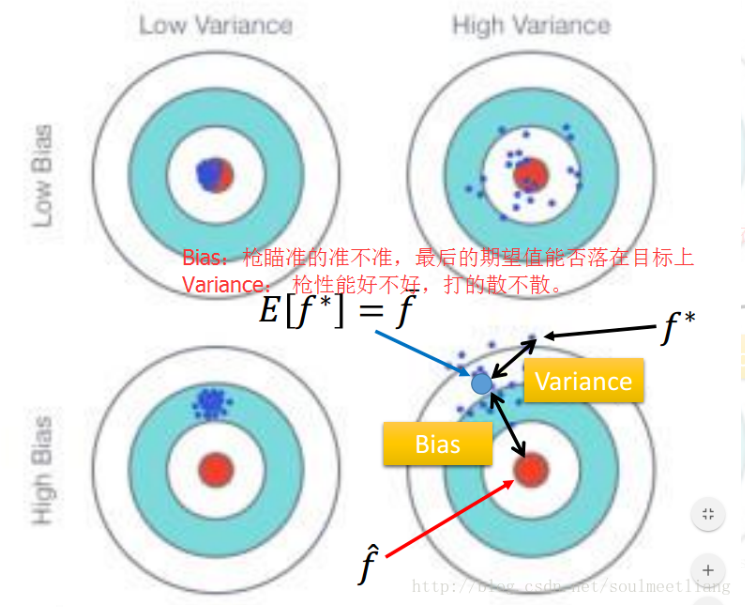
(2)如上图所示,靶心为某个能完美预测的模型,离靶心越远,则准确率随之降低。靶上的点代表某次对某个数据集上学习某个模型。纵向上,高低的bias:高的Bias表示离目标较远,低bias表示离靶心越近;横向上,高低的variance,高的variance表示多次的“学习过程”越分散,反之越集中。
所以bias表示预测值的均值与实际值的差值;而variance表示预测结果作为一个随机变量时的方差。
3.简单模型,variance小。复杂模型,variance大。(简单模型更少受训练数据影响。复杂模型会尽力去拟合训练数据的变化。)
bias代表f¯与 f^的距离。简单模型,bias大。复杂模型,bias小。
simple model的model space较小,可能没有包含target。
在underfitting的情况下,error大部分来自bias。
在overfitting的情况下,error大部分来自variance。
如果model连训练样本都fit得不好,那就是underfitting, bias大。
如果model可以fit训练样本,但是testing error大,那就是overfitting, variance大。
4.解决bias与variance偏大问题:在bias大的情况下,需要重新设计model,比如增加更多的feature,或者让model更complex。而此时more data是没有帮助的。 在variance大的情况下,需要more data,或者regularization。more data指的是,之前100个f∗,每个f∗抓10只宝可梦,现在还是100个f∗,每个f∗抓100只宝可梦。more data很有效,但不一定可行。regularization希望曲线平滑,但它可能伤害bias,造成model space无法包含target f^。在选择模型时,要考虑两种error的折中,使total error最小。或者在训练数据上面,我们可以进行交叉验证(Cross-Validation)。
5.bias与Variance的区别:首先 Error = Bias + Variance Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望(平均值)之间的误差,即模型的稳定性,数据是否集中。方差是多个模型间的比较,而非对一个模型而言的;偏差可以是单个数据集中的,也可以是多个数据集中的。
参考:https://blog.csdn.net/qq_16365849/article/details/50635700
李宏毅机器学习笔记1:Regression、Error的更多相关文章
- 李宏毅机器学习笔记3:Classification、Logistic Regression
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习笔记6:Why deep、Semi-supervised
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习笔记5:CNN卷积神经网络
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习笔记4:Brief Introduction of Deep Learning、Backpropagation(后向传播算法)
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习笔记2:Gradient Descent(附带详细的原理推导过程)
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 【ML入门】李宏毅机器学习笔记01-Learning Map
版权声明:小博主水平有限,希望大家多多指导.本文仅代表作者本人观点,转载请联系知乎原作者——BG大龍. 目录 1 什么是机器学习? 2 机器学习的3个步骤 3 李宏毅老师的机器学习课程 4 按“模型的 ...
- Python机器学习笔记 Logistic Regression
Logistic回归公式推导和代码实现 1,引言 logistic回归是机器学习中最常用最经典的分类方法之一,有人称之为逻辑回归或者逻辑斯蒂回归.虽然他称为回归模型,但是却处理的是分类问题,这主要是因 ...
- 李宏毅机器学习笔记——新手感悟——PM2.5作业
python也不会,计算机也不会,啥都不会,只带了个脑子考了计算机研究生.研究生选了人工智能方向.看来注定是漫长的学习之旅. PM2.5作业,我是一个字都看不懂.所以我采用了直接看答案的方案.把答案看 ...
- 李宏毅机器学习课程---2、Regression - Case Study
李宏毅机器学习课程---2.Regression - Case Study 一.总结 一句话总结: 分类讨论可能是比较好的找最佳函数的方法:如果 有这样的因素存在的话 模型不够好,可能是因素没有找全 ...
随机推荐
- centos7入门
yum install net-tools 设置IP和掩码 ifconfig eth0 1.1.1.20 netmask 255.255.255.0 设置网关 route add default gw ...
- Arduino语法详解_含示例详解
Arduino 的程序可以划分为三个主要部分:结构.变量(变量与常量).函数. 结构部分 一.结构 1.1 setup() 1.2 loop() 二.结构控制 2.1 if 2.2 if...else ...
- c# 创建项目时提示:未能正确加载“microsoft.data.entity.design.bootstrappackage
vs 2005 ,vs 2008, vs 2010,安装后有时出现这个错误(我的机器装的x64的win7),很烦人.找了很多地方都不能解决.其实说起来还是开发国家牛,轻易就解决了这个问题.其实出现这个 ...
- gamma校正
1 gamma校正背景 在电视和图形监视器中,显像管发生的电子束及其生成的图像亮度并不是随显像管的输入电压线性变化,电子流与输入电压相比是按照指数曲线变化的,输入电压的指数要大于电子束的指数.这说明暗 ...
- Linux下rsyslog日志收集服务环境部署记录【转】
rsyslog 可以理解为多线程增强版的syslog. 在syslog的基础上扩展了很多其他功能,如数据库支持(MySQL.PostgreSQL.Oracle等).日志内容筛选.定义日志格式模板等.目 ...
- vuejs初学入门环境搭建
一.Nodejs: 1.安装下载:http://nodejs.cn/download/ 2.Node.js安装配置: http://www.runoob.com/nodejs/nodejs ...
- Ex 6_21 最小点覆盖问题_第八次作业
子问题定义: 对于图中的每个结点,有两种状态,即属于最小点覆盖和不属于最小点覆盖,定义minSet[i][0]表示结点i属于点覆盖,并且以i为根的树的最小点覆盖的大小.minSet[i][1]表示点i ...
- sklearn 岭回归
可以理解的原理描述: [机器学习]岭回归(L2正则) 最小二乘法与岭回归的介绍与对比 多重共线性的解决方法之——岭回归与LASSO
- IntelliJ IDEA使用教程
注:本文来源:李学凯 的<IntelliJ IDEA使用教程 (总目录篇)> 一:(总目录篇)_1:硬件要求 IntelliJ IDEA 对硬件的要求看上去不是很高.可是实际在开发中其实并 ...
- PHP: POST Content-Length of xxx bytes exceeds the limit of 8388608 bytes
用户上传了 4 个附件,每个小于 5M,但是总大小超过了 15 M. 在 Nginx 日志中找到了如下错误信息,还没有到 Laravel 日志那一层. 2018/08/13 10:14:38 [err ...