Annoy 近邻算法
Annoy
随机选择两个点,以这两个节点为初始中心节点,执行聚类数为2的kmeans过程,最终产生收敛后两个聚类中心点
二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息


但是上述描述存在两个问题:
(1)查询过程最终落到叶子节点的数据节点数小于 我们需要的Top N相似邻居节点数目怎么办?
(2)两个相近的数据节点划分到二叉树不同分支上怎么办?
针对这个问题可以通过两个方法来解决:
(1)如果分割超平面的两边都很相似,那可以两边都遍历
(2) 建立多棵二叉树树,构成一个森林
(3)所有树返回近邻点都插入到优先队列中,求并集去重, 然后计算和查询点距离, 最终根据距离值从近距离到远距离排序, 返回Top N近邻节点集合
Summary of features
- Euclidean distance, Manhattan distance, cosine distance, Hamming distance, or Dot (Inner) Product distance
- Cosine distance is equivalent to Euclidean distance of normalized vectors = sqrt(2-2*cos(u, v))
- Works better if you don't have too many dimensions (like <100) but seems to perform surprisingly well even up to 1,000 dimensions
- Small memory usage
- Lets you share memory between multiple processes
- Index creation is separate from lookup (in particular you can not add more items once the tree has been created)
- Native Python support, tested with 2.7, 3.6, and 3.7.
- Build index on disk to enable indexing big datasets that won't fit into memory (contributed by Rene Hollander)
build(-1)的树的颗数问题
:所有节点的个数是trainning data的2倍左右:https://github.com/spotify/annoy/issues/338
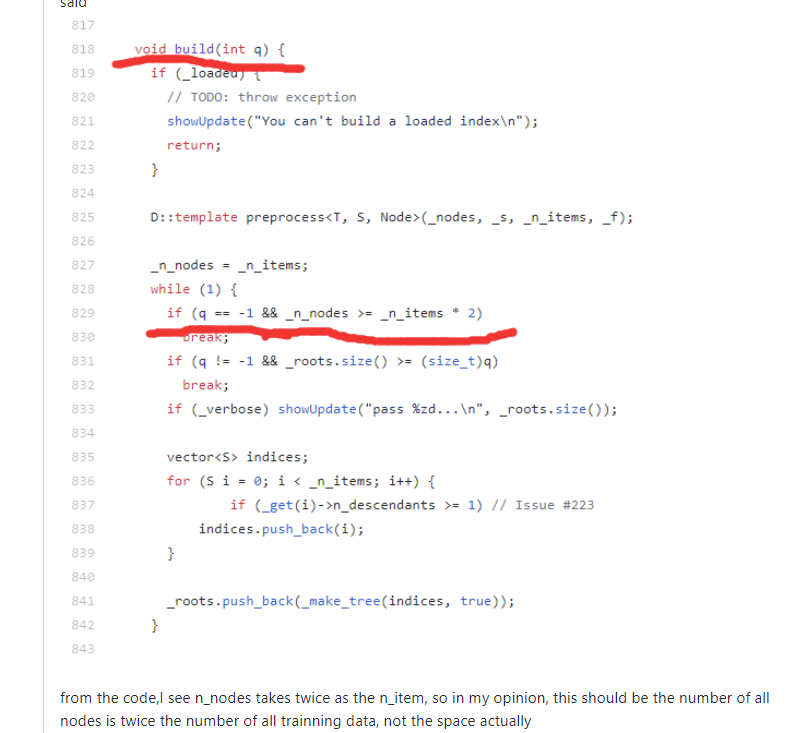
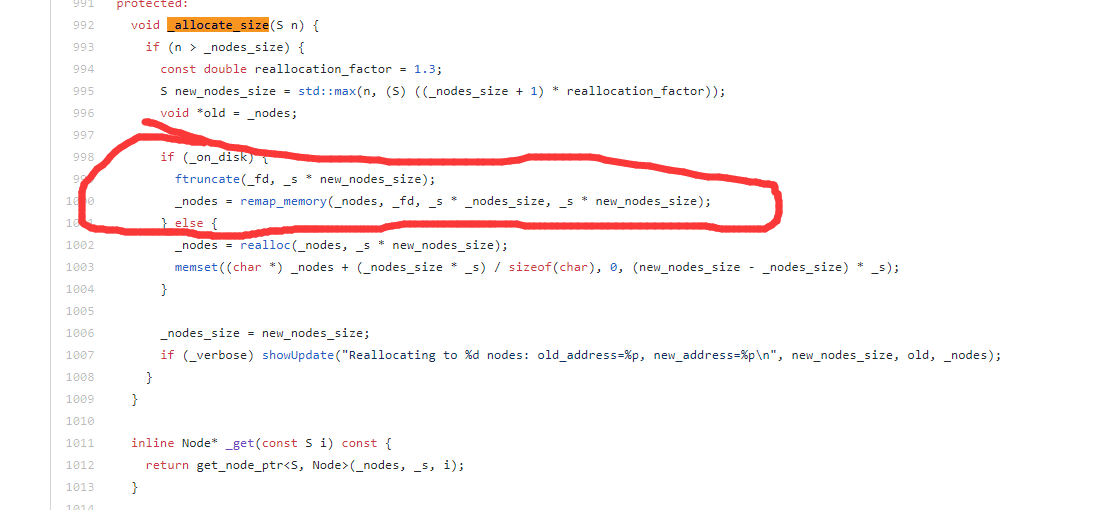
build_on_disk 问题
写文件时候,会向磁盘写
Annoy 近邻算法的更多相关文章
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- KNN近邻算法
K近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.kNN算法的核 ...
- k近邻算法的Java实现
k近邻算法是机器学习算法中最简单的算法之一,工作原理是:存在一个样本数据集合,即训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据和所属分类的对应关系.输入没有标签的新数据之后, ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- k近邻算法
k 近邻算法是一种基本分类与回归方法.我现在只是想讨论分类问题中的k近邻法.k近邻算法的输入为实例的特征向量,对应于特征空间的点,输出的为实例的类别.k邻近法假设给定一个训练数据集,其中实例类别已定. ...
- KNN K~近邻算法笔记
K~近邻算法是最简单的机器学习算法.工作原理就是:将新数据的每一个特征与样本集中数据相应的特征进行比較.然后算法提取样本集中特征最相似的数据的分类标签.一般来说.仅仅提取样本数据集中前K个最相似的数据 ...
随机推荐
- 泛型List小项目
页面设计: 显示图书列表运行效果: 添加集合元素运行效果: 插入集合元素运行效果: 删除选中对象: 项目我已经上传到我的百度云盘,下载链接:http://pan.baidu.com/s/1mi3BjY ...
- shiro中自定义realm实现md5散列算法加密的模拟
shiro中自定义realm实现md5散列算法加密的模拟.首先:我这里是做了一下shiro 自定义realm散列模拟,并没有真正链接数据库,因为那样东西就更多了,相信学到shiro的人对连接数据库的一 ...
- OS + CentOS 7 / centos 7 / VirtualBox /vegrant
s VirtualBox:解决VirtualBox安装时libSDL-1.2.so.0()错误的问题. http://www.sklinux.com/983 为Centos6.2安装VirtualBo ...
- 数据结构(六)查找---平衡二叉树(ASL)
前提 我们之前的二叉排序树的插入(构建)是按照我们输入的数据来进行的,若是我们的数据分布不同,那么就会构造不同的二叉树 { , , , , , , , , , } { , , , , , , , , ...
- JAVA-集合类型Set常用操作例子(基础必备)
package com.net.xinfang.reflect; import java.util.Comparator; import java.util.HashSet; import java. ...
- mySql插入网页地址失败
如题:插入的网页地址失败,只显示了开头10位字符.以为是特殊字符的问题. 后来发现是字符串长度不够: ALTER TABLE `news` MODIFY COLUMN `from` VARCHAR( ...
- cdqz2017-test11-占卜的准备
#include<cstdio> #include<iostream> #include<algorithm> using namespace std; #defi ...
- Git合并一次commit到指定分支
1 在当前分支,查看要合并的分支版本号 git log 需要合并的commit版本号 16b7df3aa1e64e00554a8a3c871e59db8cd87b16 2 切换到 指定分支 git c ...
- printf 函数的实现原理
/* * ===================================================================================== * * Filen ...
- 最小费用流(km的另一种使用思路)
题目链接:https://cn.vjudge.net/contest/242366#problem/L 大体意思就是:h代表旅馆,m代表人,人每走动一个需要一个金币,行动只有两个方向,水平或者竖直.问 ...