目标提取深度神经网络分析权衡 trade offs
- RCNN: 直接使用object proposal 方法得到image crops 送入神经网络中,但是crops 的大小不一样,因此使用 ROI Pooling,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量,这个ROI pooling 类似普通的pooling, 但是图像大小不固定。比如某个ROI区域坐标为 (x1,y1,x2,y2) ,那么输入size为 (y2−y1)∗(x2−x1) ,如果pooling的输出size为 pooled_height∗pooled_width ,那么每个网格的size为 (y2−y1)pooled_height∗(x2−x1)/pooled_width. 但是这些 crops 之间要重复计算特征。 (代码见roi_pooling_layer.cpp中的Forward_cpu,对于backward 见下图)
- Fast RCNN: 解决RCNN中重复计算的问题,将整幅图像(push the entire image once through a feature extractor) 送入一个特征提取器中,对object proposals 在得到的feature上进行crop。 因此share the feature extraction.

但是RCNN 和 Fast RCNN都依赖于 额外的object proposal 方法。接下来,就有各种大牛提出的使用神经网络进行object proposal 的方法,然后对这些proposals(论文中叫anchors)进行分类和回归shift to fit the GT(通常通过最小化分类和回归结合的损失函数),对于一个anchor a, 首先找最好匹配的ground truth box, 如果找到了,则为‘positive anchor’,我们赋予对应的class label, encode 这个box 。如果没有找到匹配的,这个anchor的label set to 0.
。如果没有找到匹配的,这个anchor的label set to 0.
if an anchor is encoding as  , the loss of the anchor is:
, the loss of the anchor is:
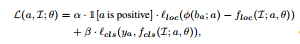 第一部分loss 是 regression of localization 的 loss, 第二部分loss 是 classification 的loss。
第一部分loss 是 regression of localization 的 loss, 第二部分loss 是 classification 的loss。
通俗地讲,SSD,YOLO,Faster RCNN等都是在原图上预先画了很多个框框,然后判断这些框框是不是前景.这和传统的滑窗有点像,anchor代表了不同size和比例的滑窗.但feature map的感受野更大一点,特征提取的也更好.
- SSD:这个方法中使用了multibox 和 RPN(faster rcnn)进行 box proposal。faster R-CNN是通过改变Anchor的大小来实现scalable的,SSD是改变Feature map大小来实现的。 将输出一系列 或者 4×4 之后的一个个 格子;而 default box 就是每一个格子上,一系列固定大小的 box,即图中虚线所形成的一系列 boxes。产生一系列 固定大小(fixed-size) 的 bounding boxes,以及每一个 box 中包含物体实例的可能性。

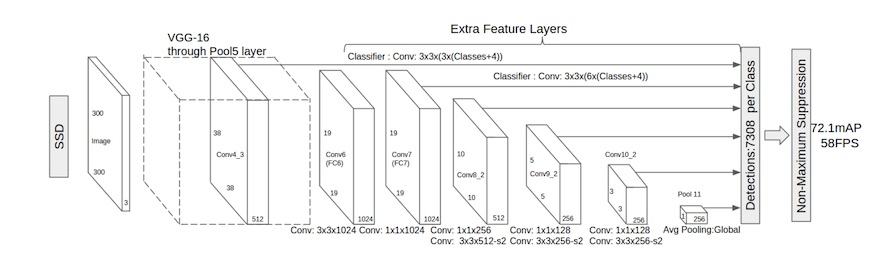
损失函数:这个与Faster R-CNN中的RPN是一样的,不过RPN是预测box里面有object或者没有,所以,没有分类,SSD直接用的softmax分类。location的损失,还是一样,都是用predict box和default box/Anchor的差 与 ground truth box和default box/Anchor的差 进行对比,求损失。

YOLO 和 SSD

- Faster RCNN: detection happens in two stages. the first one is region proposal network(RPN). the second stage, the box proposals are used to crop features from the conv5 to feed to the remainder nets(fc6 and fc7) in order to predict the class and box refinement. (each anchors obtained by RPN, would be duplicated computated. so the running time depends on the number of regions proposed by RPN).
RPN 详解:
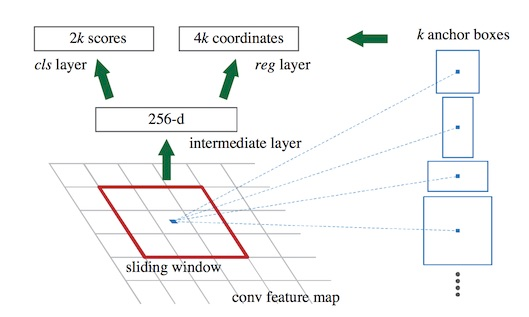
论文中将 conv5 得到的feature map手动划分为n*n的矩形框(从SSD 学习得到)(论文中设为n=3,3虽然很小,但是在高层feature map的size也很小,因此矩形框可以感知很大范围)。 准备后续选取proposals,对每个矩形窗口的中心点当做一个基准点, 然后绕着这个基准点选取k(k=9)个不同scale , aspect ratio 的anchor(论文中3个scale,3个aspect ratio)对于每个anchor在后面使用softmax进行二分类, 有两个score输出用来表示是一个物体的概率和不是一个物体的概率, 然后再接上一个bounding box 的regressor。
但是RPN也有缺点,最大的问题就是对小物体检测效果很差,假设输入为512*512,经过网络后得到的feature map是32*32,那么feature map上的一个点就要负责周围至少是16*16的一个区域的特征表达,那对于在原图上很小的物体它的特征就难以得到充分的表示,因此检测效果比较差。但是 SSD相当好一些,因为它可以理解有multi-scale 的RPN。而最后一层的feature map往往都比较抽象,对于小物体不能很好地表达特征,而SSD允许从CNN各个level的feature map预测检测结果,这样就能很好地适应不同scale的物体,对于小物体可以由更底层的feature map做预测。这就是SSD和RPN最大的不同,其他地方几乎一样。
rpn二分类,是在conv4 这一层feature map上再进行1x1的卷积生成512-d或256-d的向量判断当前9个anchor是不是有Object.
SSD细分类,然后会在多层feature map上面预测,预测预先确定好了'anchor'是什么Object.弥补了yolo只在最后一层分成7x7的框,捡了许多漏检的.
RPN的loss函数可以表示为:

在训练时,要选择正负样本,不然负样本过多,对正样本的预测准确率很低。多任务训练,提出来不同的方法:
1)alternating training训练时,先独立训练RPN,然后用RPN的网络权重对Fast RCNN网络进行初始化,并用RPN输出的proposal作为Fast RCNN的输入,不断迭代这个过程。
2) approximate joint training: 将RPN与 Fast RCNN 融入一起训练。 ignore the derivative of the proposal boxes
3) Non- approximate training: 对立与上一种方法。不ignore。

- YOLO: Faster RCNN需要对anchor box进行判断是否是物体,然后再进行物体识别,分成了两步。
YOLO(You Only Look Once)则把物体框的选择与识别进行了结合,一步输出,即变成”You Only Look Once”。 加快速度的YOLO带来了一定的局限性,由于出事图片需要被缩放到固定大小,可能对不同缩放比例的物体覆盖不全,每一个单元格只能用来选择一个物体框,并只预测一个类别,所以当多个物体中心落入一个单元格使,YOLO无法识别到小物体。 - 把缩放成统一大小的图片分割成S×S的单元格
- 每一个单元格负责输出B个矩形框,每一个框带四个位置信息(x, y, w, h),与一个该框是物体的概率,用Pr(Object)或者C(Confidence)表示
- 每一个单元格再负责输出C个类别的概率,用Pr(Class∣Object)表示
- 最终输出层应有S×S×(B∗5+C)个单元
- R-FCN
Faster RCNN 中最后fc6 和 fc7 的特征计算是重复计算,在R-FCN提出了一种提高的方法。将Crop放在网络的最后相当于网络中没有fully connect layer,所有都是用convolutional layer 实现。
目标提取深度神经网络分析权衡 trade offs的更多相关文章
- (转载)微软数据挖掘算法:Microsoft 神经网络分析算法(10)
前言 有段时间没有进行我们的微软数据挖掘算法系列了,最近手头有点忙,鉴于上一篇的神经网络分析算法原理篇后,本篇将是一个实操篇,当然前面我们总结了其它的微软一系列算法,为了方便大家阅读,我特地整理了一篇 ...
- (转载)微软数据挖掘算法:Microsoft 神经网络分析算法原理篇(9)
前言 本篇文章继续我们的微软挖掘系列算法总结,前几篇文章已经将相关的主要算法做了详细的介绍,我为了展示方便,特地的整理了一个目录提纲篇:大数据时代:深入浅出微软数据挖掘算法总结连载,有兴趣的童鞋可以点 ...
- 深度神经网络结构以及Pre-Training的理解
Logistic回归.传统多层神经网络 1.1 线性回归.线性神经网络.Logistic/Softmax回归 线性回归是用于数据拟合的常规手段,其任务是优化目标函数:$h(\theta )=\thet ...
- 目标检测——深度学习下的小目标检测(检测难的原因和Tricks)
小目标难检测原因 主要原因 (1)小目标在原图中尺寸比较小,通用目标检测模型中,一般的基础骨干神经网络(VGG系列和Resnet系列)都有几次下采样处理,导致小目标在特征图的尺寸基本上只有个位数的像素 ...
- 以resnet作为前置网络的ssd目标提取检测
http://blog.csdn.net/zhangjunbob/article/details/53119959
- 转pytorch中训练深度神经网络模型的关键知识点
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/weixin_42279044/articl ...
- Scriptable Render Pipeline
Scriptable Render Pipeline SRP的核心是一堆API集合,使得整个渲染过程及相关配置暴露给用户,使得用户可以精确地控制项目的渲染流程. SRP API为原有的Unity构件提 ...
- 深度学习 + OpenCV,Python实现实时视频目标检测
使用 OpenCV 和 Python 对实时视频流进行深度学习目标检测是非常简单的,我们只需要组合一些合适的代码,接入实时视频,随后加入原有的目标检测功能. 在本文中我们将学习如何扩展原有的目标检测项 ...
- Video Target Tracking Based on Online Learning—深度学习在目标跟踪中的应用
摘要 近年来,深度学习方法在物体跟踪领域有不少成功应用,并逐渐在性能上超越传统方法.本文先对现有基于深度学习的目标跟踪算法进行了分类梳理,后续会分篇对各个算法进行详细描述. 看上方给出的3张图片,它们 ...
随机推荐
- hive分区表
分区表创建 row format delimited fields terminated by ',';指明以逗号作为分隔符 依靠插入表创建分区表 从表sample_table选择 满足分区条件的 ...
- Java 数组实现 stack
首先定义 IStack package cn.com.example.stack; /** * Created by Jack on 2017/3/8. */ public interface ISt ...
- Spark_RDD之RDD基础
1.什么是RDD RDD(resilient distributed dataset)弹性分布式数据集,每一个RDD都被分为多个分区,分布在集群的不同节点上. 2.RDD的操作 Spark对于数据的操 ...
- js md5 中文
最近手机端通过js对请求数据加密,发现针对中文加密的结果和asp.net的webapi加密结果不一致 网上搜索了一下,发现以下js可用 function md5(string) { var x = A ...
- 【POI每日题解 #6】KRA-The Disks
题目链接 : [POI2006]KRA-The Disks 好有既视感啊... 注意一下输入输出 输入是从上到下输入箱子的宽度 输出是最上面的积木停在哪一层 即 箱子高度 - 积木高度 + 1 在初始 ...
- 【Luogu1937】仓配置(贪心,线段树)
[Luogu1937]仓配置 题面 直接找洛谷把... 题解 很明显的贪心吧 按照线段的右端点为第一关键字,左端点第二关键字排序 然后线段树维护区间最小就可以啦 #include<iostrea ...
- anaconda python no module named 'past'的解决方法
如上图所示,错误就是:No module named 'past' 解决办法不是下载‘past’包,而是下载‘future’包: 我是安装了anaconda集成环境,python的单独环境应该也是同样 ...
- Android 手势&触摸事件
在刚开始学Android的时候,就觉得Google的文档不咋样,在研究手势时,更加的感觉Google的文档写得实在是太差了.很多常量,属性和方法,居然连个描述都没有. 没有描述也就罢了,但是OnGes ...
- Git中设置代理和取消代理
设置Socks5代理 git config --global http.proxy 'socks5://127.0.0.1:1080' && git config --global h ...
- 【数学】NOIP数论内容整理
NOIP数论内容整理 注:特别感谢sdsy的zxy神仙以及lcez的tsr筮安帮助审稿 一.整除: 对于\(a,b~\in~Z\),若\(\exists~k~\in~Z\),\(s.t.~b~=~k~ ...