1、Python中的正则表达式(0601)
回顾:
1、文件对象:
- open('file','mode','bufsize')
- read,readline,readlines,write,writelines,flush,seek,tell
2、模块:os
- 文件系统接口
3、模块:os.path
4、对象流失化,持久化:
- pickle
文件本身在python内部是可迭代对象:

获取当前系统的所有模块
help有两种模式,一个是函数方式调用,另一个是交互式模式调用
help('modules') 或者
help() 是交互式接口


python的正则表达式:
re:
元字符
. 匹配任意单个字符
[.....] 匹配指定范围内的字符
[^.....] 匹配指定范围以外的字符
? 匹配此前的字符0次或一次
+ 匹配此前的字符1次或多次
{m} 匹配前面的字符m次
{m,n} 匹配至少m次,至多n次
{0,n} 匹配至多n次,也可以没有
{m,} 匹配至少m次,至多不限
^ 牟定行首
$ 牟定行尾
pat1|pat2 两种模式取其一
(.....) 分组
\b 可以牟定一个单词
[0-9]: \d 匹配任意数字
[0-9a-zA-Z] 匹配任意数字和字符
[0-9a-zA-Z]:\w,\W对\w取反 \w是字符集
\s:任意空白字符,[\n\t\f\v\r], 大S \S 和小s相反,表示空白字符以外的任意字符
\s是它们的集合:\n表空白,\t制表符,空白 \f表空白、\v垂直制表符,空白、\r换行符
\nn 可以实现后向引用,引用(.....) 分组中的匹配到的内容
(*|+|?|{})?:使用非贪婪模式
re.match
match对象:在re中可以指定起始位置,结束位置,匹配到的字符等
re本身有很多内置方法和属性

re.match对象有很多内置属性

match方法匹配到的结果会生成match对象,必须在获取match对象之后,才能获取内部信息,
如果利用re内部的方法match或search匹配到字符串内容了,就可以对某些match对象使用function获取
在abc字串中找a,匹配到后就返回一个match对象,并告诉在内存什么位置,此对象必须使用变量名引用,
因为任何对象都是保存在内存中,要想引用,必须将内存对象保存在变量名的引用中,否则创建完就消失了
定义一个变量引用m1,这时候m1就是匹配对象,m1本身内部就会有一些方法
match对象是一次正则表达式匹配查询的结果,包含了很多关于此次匹配的信息,要通过内部的属性和方法来获取这些信息


re是匹配时使用的pattern对象,需要说明的是re这个模块在实现使用模式匹配所使用的文本时,会首先将字符 (a) 编译compile,编译完之后再去做匹配,如果没有手动编译,它会自动编译。
因此所使用的re即正则表达式,不再是模式本身(a),而是下面被编译的模式
括号中的 r 表示是正则表达式的模式,

手动编译匹配模式
在abcdefg中查找bc
第一种方式手动编译,模式为bc
pat = re.compile('bc') 手动编译模式bc,这里pat是一个模式对象,
match = pat.match('abcdefg') 使用模式对象去执行一些匹配类的操作,这里pat调用compile('bc') 这个模式,来调用'abcdefg'这个字符串,

第二种模式是自动编译
group解析:
要想实现分组,得在正则表达式中使用()括起来,即(.....) ,第一个()称为group1,第二个()称为group2,因此要想使用group和groups来获取分组结果,一定是这个模式在匹配到结果中的本身进行分组
匹配次数可能是多次,每次匹配有可能会分为多个组
例子:hellopr world:在这个字符串中匹配o会出现两次
(o):如果对这个模式加(),就表示在()中的模式表示第一个分组,即o是第一个分组;
(0(.)):如果o后面可以出现任意字符,且将点加括号--> (.),那么(.)就表示模式中的第二个分组;
利用(0(.))这个模式在hellopr world字串中总共有两次匹配,即op和or;那么对第一次匹配来讲,匹配的是op,那么第一个()中的内容0(.)即group1匹配的是op,第二个括号中的内容 . 即group2匹配的是p;
在字符串中进行模式匹配可能不止一次匹配(op,or),因此每一次匹配都会有分组,而且分组可能不止一个(group1、group2、......)
因此对于上述第一次匹配内容op会分为group1即op,和group2即p,
(0(.)):是一个模式,这个模式第一次匹配到的就是op,
group1表示外面的()匹配到的内容即o(.),所以匹配到的内容为op;
group2表示里面的()中的内容匹配的内容即点号 . 匹配的内容,. 匹配到的是o后面的字符p,即group2为p
groups就表示每一次匹配中多个分组的集合
第二次匹配时,匹配的是or,那么group1是or,group2是r
使用group1时,就是使用模式(0(.))中第一个左括号 ( 和它右括号)中的内容----即o(.)----进行匹配
使用group2时,就是使用模式(0(.))中第二个左括号 ( 和它右括号)中的内容----即 . ----进行匹配
例子解析:hellopr world
定义字符串str1,手动编译模式(0(.)),利用search搜索字符串str1,这个结果会生成一个匹配对象,把匹配对象保存在变量mat1中,
然后获取mat1的分组,直接给group(),会返回第一次匹配到的整个串即op,


groups 每一次匹配都可能由多个分组,把一次匹配到的多个分组以元组的方式返回叫groups


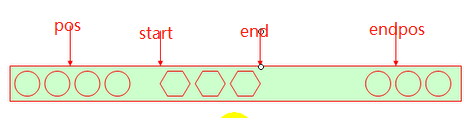
pos和endpos
pos是搜索字串时,是在原串的哪个位置开始搜索,一直到哪个位置结束搜索的,默认是搜索串的整个组成部分。
指定了模式被匹配到的串本身(模式是a,串本身是abc),是从原串的哪个字符位置开始匹配的
endpos表示使用模式 a 搜索字串 abc 时,从哪个位置搜索,一直到哪个位置结束搜索
(一般都是从头开始,到结尾,可以看出原串的大小)
模式匹配位置即搜索位置是可以指定的,默认时从头开始,到最后结束

start和end
start、end 模式 a 在原串 abc 中匹配时所匹配到的那个串的第一次和结束位置
(即匹配时,模式 a 被匹配到,a 在原串中第一次被搜索到和最后一次被搜索到这两个位置)

pos和endpos是属性,start和end是方法
re.search search(pattern, string, flags=0)
search的意义:在字符串string中,按照pattern进行搜索,并返回第一次初步匹配到的结果,如果有其他匹配,即使在同一行也不做匹配。
search只返回第一次匹配到的结果,返回结果是匹配对象。


findall
findall返回多次,返回结果仍然是一个匹配对象,如果匹配对象是多个,则以列表的方式来返回所有的匹配对象。

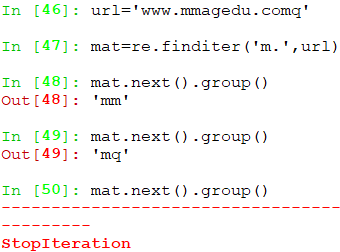
finditer(pattern, string, flags=0)
finditer和findall相同,区别在于findall返回的是列表,finditer返回的是迭代器
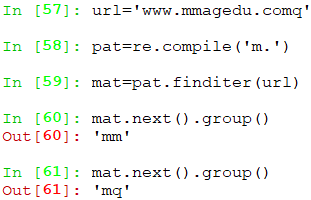
re.slipt

re.sub
sub(pattern, repl, string, count=0, flags=0) 把pattern在string中匹配的内容由repl替换,count是指替换次数
直接返回由repl替换的字符串
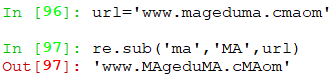

subn 和sub相同,区别在subn返回的是替换的次数
subn返回的是元组,sub返回的是一个字串

re.search:返回一个macth对象
match对象的属性和方法
- 属性:
- string 字符串本身
- re 正则表达式
- pos
- endpos 搜索字符串起始位置
- 方法:
- group()
- start()
- end()
re.findall:返回一个列表
re.sub:返回替换后的整个串
re.subn:返回元组:替换后的串及替换次数
re.compile:模式对象,手动编译出来
对象都是保存在内存中的,所以要想访问match对象,得使用对象进行获取,获取后在对象是上施加一些操作,但如果回复的对象是空的,就没办法执行了,所以需要提前判断

flags:
I或IGNORECASE:忽略字符大小写
M或MULTILINE:多行匹配
A或ASCII:仅执行8位ASCII码匹配
U或UNICODE:执行unicode匹配
pat2 = re.compile('.(o(.))',re.I) 手动编译匹配模式,re.I表示匹配时忽略大小
pat2 = re.compile('.(o(.))',re.I|re.M) | 表示或者 re.M:表示跨多行匹配


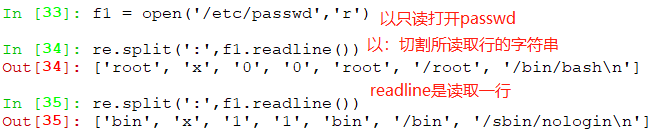
思考:复制/etc/passwd到/tmp,如何替换/tmp/passwd中的/bin/bash为/BIN/BASH?

1、Python中的正则表达式(0601)的更多相关文章
- Python::re 模块 -- 在Python中使用正则表达式
前言 这篇文章,并不是对正则表达式的介绍,而是对Python中如何结合re模块使用正则表达式的介绍.文章的侧重点是如何使用re模块在Python语言中使用正则表达式,对于Python表达式的语法和详细 ...
- 在Python中使用正则表达式同时匹配邮箱和电话并进行简单的分类
在Python使用正则表达式需要使用re(regular exprssion)模块,使用正则表达式的难点就在于如何写好p=re.compile(r' 正则表达式')的内容. 下面是在Python中使用 ...
- python模块 re模块与python中运用正则表达式的特点 模块知识详解
1.re模块和基础方法 2.在python中使用正则表达式的特点和问题 3.使用正则表达式的技巧 4.简单爬虫例子 一.re模块 模块引入; import re 相关知识: 1.查找: (1)find ...
- Python学习-38.Python中的正则表达式(二)
在Python中,正则表达式还有较其他编程语言有特色的地方.那就是支持松散正则表达式了. 在某些情况,正则表达式会写得十分的长,这时候,维护就成问题了.而松散正则表达式就是解决这一问题的办法. 用上一 ...
- Python学习-37.Python中的正则表达式
作为一门现代语言,正则表达式是必不可缺的,在Python中,正则表达式位于re模块. import re 这里不说正则表达式怎样去匹配,例如\d代表数字,^代表开头(也代表非,例如^a-z则不匹配任何 ...
- [Python]网络爬虫(七):Python中的正则表达式教程
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8929576#t4 接下来准备用糗百做一个爬虫的小例子. 但是在这之前,先详细的整理一 ...
- [Python]网络爬虫(七):Python中的正则表达式教程(转)
接下来准备用糗百做一个爬虫的小例子. 但是在这之前,先详细的整理一下Python中的正则表达式的相关内容. 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器. ...
- 在python中使用正则表达式(转载)
https://www.cnblogs.com/hanmk/p/9143514.html 在python中使用正则表达式(一) 在python中通过内置的re库来使用正则表达式,它提供了所有正则表 ...
- python中的正则表达式(re模块)
一.简介 正则表达式本身是一种小型的.高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配.正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎 ...
随机推荐
- python3安装scrapy教程
2.1xm1http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml3. PyOpensslhttps://pypi.python.org/pypi/pyOpen ...
- php冒泡排序实现方法,传入几个数字排序后 输出实战例子
php冒泡排序实现方法,传入几个数字排序后 输出实战例子 算法和数据结构是一个编程工作人员的内功.四种入门级排序算法: 冒泡排序.选择排序.插入排序.快速排序. 一.冒泡排序 原理:对一组数据,比较相 ...
- 自制TFT-Usart通信小项目资料打包
2010-05-08 15:05:00 用orcad画的原理图如下.
- JustOJ1500: 蛇行矩阵
题目链接:https://oj.ismdeep.com/problem?id=1500 题目描述 蛇形矩阵是由1开始的自然数依次排列成的一个矩阵上三角形. 输入 本题有多组数据,每组数据由一个正整数N ...
- NFS客户端阻塞睡眠问题与配置调研
Linux NFS客户端需要很小心地配置,否则在NFS服务器崩溃时,访问NFS的程序会被挂起,用ps查看,进程状态(STAT)处于D,意为(由于IO阻塞而进入)不可中断睡眠(如果是D+,+号表示程序运 ...
- Object.defineProperty的理解
一.Object.defineProperty:给一个对象定义一个新的属性或修改一个对象现有的属性,并且返回这个对象 1.语法:Object.defineProperty(参数1,参数2,参数3) 参 ...
- camera理论基础和工作原理(转)
源: camera理论基础和工作原理
- spring中的springSecurity安全框架的环境搭建
首先在web.xml文件中配置监听器和过滤器 <!--监听器 加载安全框架的核心配置文件到spring容器中--> <context-param> <param-name ...
- python通过sftp远程传输文件
python提供了一个第三方模块paramiko,通过这个模块可以实现两台机器之间的网络连接,sftp是paramiko的一个方法,使用sftp可以在两台机器之间互相传输 拷贝文件.然而paramik ...
- MyBatis批量更新
逐条更新 这种方式显然是最简单,也最不容易出错的,即便出错也只是影响到当条出错的数据,而且可以对每条数据都比较可控. 代码 updateBatch(List<MyData> datas){ ...