【java多线程】队列系统之LinkedBlockingQueue源码
转载:https://blog.csdn.net/tonywu1992/article/details/83419448
http://benjaminwhx.com/archives/
1、简介
上篇我们介绍了ArrayBlockingQueue的相关方法的原理,这一篇我们来学习一下ArrayBlockingQueue的“亲戚” LinkedBlockingQueue。在集合框架里,想必大家都用过ArrayList和LinkedList,也经常在面试中问到他们之间的区别。ArrayList和ArrayBlockingQueue一样,内部基于数组来存放元素,而LinkedBlockingQueue则和LinkedList一样,内部基于链表来存放元素。
LinkedBlockingQueue实现了BlockingQueue接口,这里放一张类的继承关系图(图片来自之前的文章:说说队列Queue)

LinkedBlockingQueue不同于ArrayBlockingQueue,它如果不指定容量,默认为Integer.MAX_VALUE,也就是无界队列。所以为了避免队列过大造成机器负载或者内存爆满的情况出现,我们在使用的时候建议手动传一个队列的大小。
2、源码分析
2.1、属性
/**
* 节点类,用于存储数据
*/
static class Node<E> {
E item;
Node<E> next; Node(E x) { item = x; }
} /** 阻塞队列的大小,默认为Integer.MAX_VALUE */
private final int capacity; /** 当前阻塞队列中的元素个数 */
private final AtomicInteger count = new AtomicInteger(); /**
* 阻塞队列的头结点
*/
transient Node<E> head; /**
* 阻塞队列的尾节点
*/
private transient Node<E> last; /** 获取并移除元素时使用的锁,如take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock(); /** notEmpty条件对象,当队列没有数据时用于挂起执行删除的线程 */
private final Condition notEmpty = takeLock.newCondition(); /** 添加元素时使用的锁如 put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock(); /** notFull条件对象,当队列数据已满时用于挂起执行添加的线程 */
private final Condition notFull = putLock.newCondition();
从上面的属性我们知道,每个添加到LinkedBlockingQueue队列中的数据都将被封装成Node节点,添加的链表队列中,其中head和last分别指向队列的头结点和尾结点。与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制,也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。
这里如果不指定队列的容量大小,也就是使用默认的Integer.MAX_VALUE,如果存在添加速度大于删除速度时候,有可能会内存溢出,这点在使用前希望慎重考虑。
另外,LinkedBlockingQueue对每一个lock锁都提供了一个Condition用来挂起和唤醒其他线程。
2.2、构造函数
public LinkedBlockingQueue() {
// 默认大小为Integer.MAX_VALUE
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
count.set(n);
} finally {
putLock.unlock();
}
}
默认的构造函数和最后一个构造函数创建的队列大小都为Integer.MAX_VALUE,只有第二个构造函数用户可以指定队列的大小。第二个构造函数最后初始化了last和head节点,让它们都指向了一个元素为null的节点。

最后一个构造函数使用了putLock来进行加锁,但是这里并不是为了多线程的竞争而加锁,只是为了放入的元素能立即对其他线程可见。
2.3、方法
同样,LinkedBlockingQueue也有着和ArrayBlockingQueue一样的方法,我们先来看看入队列的方法。
2.3.1、入队方法
LinkedBlockingQueue提供了多种入队操作的实现来满足不同情况下的需求,入队操作有如下几种:
- void put(E e);
- boolean offer(E e);
- boolean offer(E e, long timeout, TimeUnit unit)。
put(E e)
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
// 获取锁中断
putLock.lockInterruptibly();
try {
//判断队列是否已满,如果已满阻塞等待
while (count.get() == capacity) {
notFull.await();
}
// 把node放入队列中
enqueue(node);
c = count.getAndIncrement();
// 再次判断队列是否有可用空间,如果有唤醒下一个线程进行添加操作
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// 如果队列中有一条数据,唤醒消费线程进行消费
if (c == 0)
signalNotEmpty();
}
小结put方法来看,它总共做了以下情况的考虑:
- 队列已满,阻塞等待。
- 队列未满,创建一个node节点放入队列中,如果放完以后队列还有剩余空间,继续唤醒下一个添加线程进行添加。如果放之前队列中没有元素,放完以后要唤醒消费线程进行消费。
很清晰明了是不是?
我们来看看该方法中用到的几个其他方法,先来看看enqueue(Node node)方法:
private void enqueue(Node<E> node) {
last = last.next = node;
}
该方法可能有些同学看不太懂,我们用一张图来看看往队列里依次放入元素A和元素B,毕竟无图无真相:
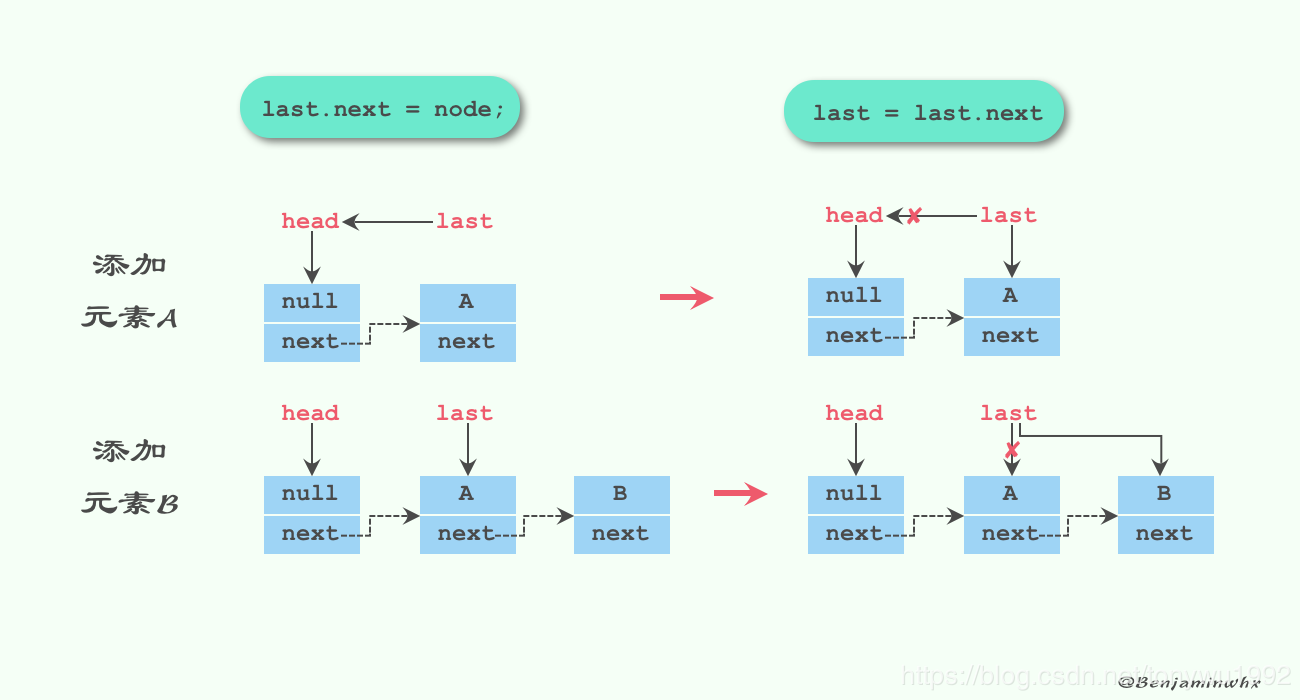
接下来我们看看signalNotEmpty,顺带着看signalNotFull方法。
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
private void signalNotFull() {
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
notFull.signal();
} finally {
putLock.unlock();
}
}
为什么要这么写?因为signal的时候要获取到该signal对应的Condition对象的锁才行。
offer(E e)
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final AtomicInteger count = this.count;
if (count.get() == capacity)
return false;
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
// 队列有可用空间,放入node节点,判断放入元素后是否还有可用空间,
// 如果有,唤醒下一个添加线程进行添加操作。
if (count.get() < capacity) {
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
}
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return c >= 0;
}
可以看到offer仅仅对put方法改动了一点点,当队列没有可用元素的时候,不同于put方法的阻塞等待,offer方法直接方法false。
offer(E e, long timeout, TimeUnit unit)
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException { if (e == null) throw new NullPointerException();
long nanos = unit.toNanos(timeout);
int c = -1;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
// 等待超时时间nanos,超时时间到了返回false
while (count.get() == capacity) {
if (nanos <= 0)
return false;
nanos = notFull.awaitNanos(nanos);
}
enqueue(new Node<E>(e));
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
return true;
}
该方法只是对offer方法进行了阻塞超时处理,使用了Condition的awaitNanos来进行超时等待,这里为什么要用while循环?因为awaitNanos方法是可中断的,为了防止在等待过程中线程被中断,这里使用while循环进行等待过程中中断的处理,继续等待剩下需等待的时间。
2.3.2、出队方法
入队列的方法说完后,我们来说说出队列的方法。LinkedBlockingQueue提供了多种出队操作的实现来满足不同情况下的需求,如下:
- E take();
- E poll();
- E poll(long timeout, TimeUnit unit);
take()
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
// 队列为空,阻塞等待
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
// 队列中还有元素,唤醒下一个消费线程进行消费
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
// 移除元素之前队列是满的,唤醒生产线程进行添加元素
if (c == capacity)
signalNotFull();
return x;
}
take方法看起来就是put方法的逆向操作,它总共做了以下情况的考虑:
- 队列为空,阻塞等待。
- 队列不为空,从队首获取并移除一个元素,如果消费后还有元素在队列中,继续唤醒下一个消费线程进行元素移除。如果放之前队列是满元素的情况,移除完后要唤醒生产线程进行添加元素。
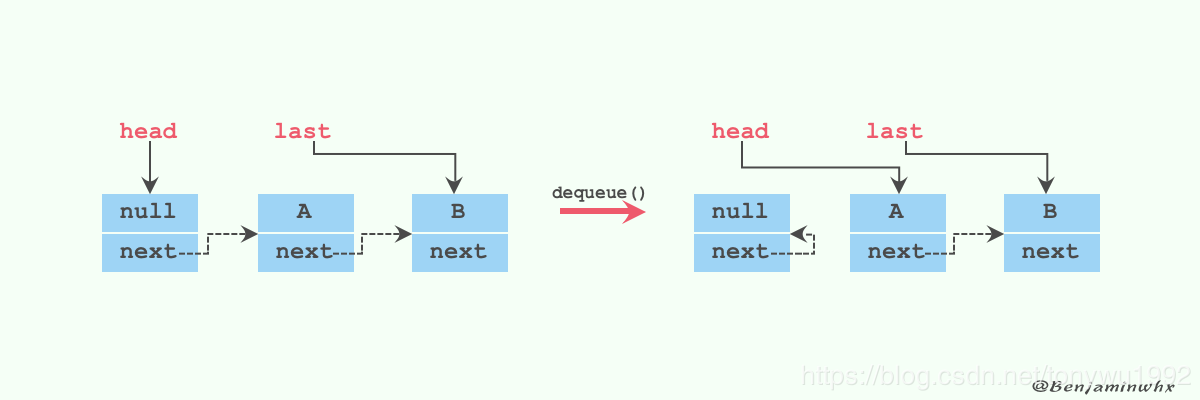
我们来看看dequeue方法
private E dequeue() {
// 获取到head节点
Node<E> h = head;
// 获取到head节点指向的下一个节点
Node<E> first = h.next;
// head节点原来指向的节点的next指向自己,等待下次gc回收
h.next = h; // help GC
// head节点指向新的节点
head = first;
// 获取到新的head节点的item值
E x = first.item;
// 新head节点的item值设置为null
first.item = null;
return x;
}
可能有些童鞋链表算法不是很熟悉,我们可以结合注释和图来看就清晰很多了。
其实这个写法看起来很绕,我们其实也可以这么写:
private E dequeue() {
// 获取到head节点
Node<E> h = head;
// 获取到head节点指向的下一个节点,也就是节点A
Node<E> first = h.next;
// 获取到下下个节点,也就是节点B
Node<E> next = first.next;
// head的next指向下下个节点,也就是图中的B节点
h.next = next;
// 得到节点A的值
E x = first.item;
first.item = null; // help GC
first.next = first; // help GC
return x;
}
poll()
public E poll() {
final AtomicInteger count = this.count;
if (count.get() == 0)
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
if (count.get() > 0) {
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
}
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
poll方法去除了take方法中元素为空后阻塞等待这一步骤,这里也就不详细说了。同理,poll(long timeout, TimeUnit unit)也和offer(E e, long timeout, TimeUnit unit)一样,利用了Condition的awaitNanos方法来进行阻塞等待直至超时。这里就不列出来说了。
2.3.3、获取元素方法
public E peek() {
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
Node<E> first = head.next;
if (first == null)
return null;
else
return first.item;
} finally {
takeLock.unlock();
}
}
加锁后,获取到head节点的next节点,如果为空返回null,如果不为空,返回next节点的item值。
2.3.4、删除元素方法
public boolean remove(Object o) {
if (o == null) return false;
// 两个lock全部上锁
fullyLock();
try {
// 从head开始遍历元素,直到最后一个元素
for (Node<E> trail = head, p = trail.next;
p != null;
trail = p, p = p.next) {
// 如果找到相等的元素,调用unlink方法删除元素
if (o.equals(p.item)) {
unlink(p, trail);
return true;
}
}
return false;
} finally {
// 两个lock全部解锁
fullyUnlock();
}
}
void fullyLock() {
putLock.lock();
takeLock.lock();
}
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}
因为remove方法使用两个锁全部上锁,所以其他操作都需要等待它完成,而该方法需要从head节点遍历到尾节点,所以时间复杂度为O(n)。我们来看看unlink方法。
void unlink(Node<E> p, Node<E> trail) {
// p的元素置为null
p.item = null;
// p的前一个节点的next指向p的next,也就是把p从链表中去除了
trail.next = p.next;
// 如果last指向p,删除p后让last指向trail
if (last == p)
last = trail;
// 如果删除之前元素是满的,删除之后就有空间了,唤醒生产线程放入元素
if (count.getAndDecrement() == capacity)
notFull.signal();
}
3、问题
看源码的时候,我给自己抛出了一个问题。
- 为什么dequeue里的h.next不指向null,而指向h?
- 为什么unlink里没有p.next = null或者p.next = p这样的操作?
这个疑问一直困扰着我,直到我看了迭代器的部分源码后才豁然开朗,下面放出部分迭代器的源码:
private Node<E> current;
private Node<E> lastRet;
private E currentElement; Itr() {
fullyLock();
try {
current = head.next;
if (current != null)
currentElement = current.item;
} finally {
fullyUnlock();
}
} private Node<E> nextNode(Node<E> p) {
for (;;) {
// 解决了问题1
Node<E> s = p.next;
if (s == p)
return head.next;
if (s == null || s.item != null)
return s;
p = s;
}
}
迭代器的遍历分为两步,第一步加双锁把元素放入临时变量中,第二部遍历临时变量的元素。也就是说remove可能和迭代元素同时进行,很有可能remove的时候,有线程在进行迭代操作,而如果unlink中改变了p的next,很有可能在迭代的时候会造成错误,造成不一致问题。这个解决了问题2。
而问题1其实在nextNode方法中也能找到,为了正确遍历,nextNode使用了 s == p的判断,当下一个元素是自己本身时,返回head的下一个节点。
4、总结
LinkedBlockingQueue是一个阻塞队列,内部由两个ReentrantLock来实现出入队列的线程安全,由各自的Condition对象的await和signal来实现等待和唤醒功能。它和ArrayBlockingQueue的不同点在于:
- 队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE),对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
- 数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
- 由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
- 两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
【java多线程】队列系统之LinkedBlockingQueue源码的更多相关文章
- Java并发包源码学习系列:阻塞队列实现之LinkedBlockingQueue源码解析
目录 LinkedBlockingQueue概述 类图结构及重要字段 构造器 出队和入队操作 入队enqueue 出队dequeue 阻塞式操作 E take() 阻塞式获取 void put(E e ...
- Java并发编程笔记之LinkedBlockingQueue源码探究
JDK 中基于链表的阻塞队列 LinkedBlockingQueue 原理剖析,LinkedBlockingQueue 内部是如何使用两个独占锁 ReentrantLock 以及对应的条件变量保证多线 ...
- 【java多线程】队列系统之LinkedBlockingDeque源码
1.简介 上一篇我们介绍了 LinkedBlockingDeque 的兄弟篇 LinkedBlockingQueue .听名字也知道一个实现了 Queue 接口,一个实现了 Deque 接口,由于 D ...
- 【java多线程】队列系统之ArrayBlockingQueue源码
1.简介 ArrayBlockingQueue,顾名思义:基于数组的阻塞队列.数组是要指定长度的,所以使用ArrayBlockingQueue时必须指定长度,也就是它是一个有界队列. 它实现了Bloc ...
- lesson2:java阻塞队列的demo及源码分析
本文向大家展示了java阻塞队列的使用场景.源码分析及特定场景下的使用方式.java的阻塞队列是jdk1.5之后在并发包中提供的一组队列,主要的使用场景是在需要使用生产者消费者模式时,用户不必再通过多 ...
- Java多线程学习之线程池源码详解
0.使用线程池的必要性 在生产环境中,如果为每个任务分配一个线程,会造成许多问题: 线程生命周期的开销非常高.线程的创建和销毁都要付出代价.比如,线程的创建需要时间,延迟处理请求.如果请求的到达率非常 ...
- 并发队列ConcurrentLinkedQueue与LinkedBlockingQueue源码分析与对比
目录 前言 ConcurrentLinkedQueue 使用方法 存储结构 初始化 入队 出队 获取容器元素数量 LinkedBlockingQueue 使用方法 存储结构 初始化 入队 出队 获取容 ...
- 【java多线程】队列系统之DelayQueue源码
一.延迟队列 延迟队列,底层依赖了优先级队列PriorityBlockingQueue 二.延迟队列案例 (1)延迟队列的任务 public class DelayTask implements De ...
- 【java多线程】队列系统之PriorityBlockingQueue源码
一.二叉堆 如题,二叉堆是一种基础数据结构 事实上支持的操作也是挺有限的(相对于其他数据结构而言),也就插入,查询,删除这一类 对了这篇文章中讲到的堆都是二叉堆,而不是斜堆,左偏树,斐波那契堆什么的 ...
随机推荐
- POST提交表单时EnType设置问题
POST提交表单时EnType设置问题 首先知道enctype这个属性管理的是表单的MIME编码.共有三个值可选: 1.application/x-www-form-urlencoded 2.mult ...
- opencv3.0+vs2013安装记录
为了能够更好的学习图像,我觉得opencv是一个必不可少的库,因此在以后的研究上使用opencv作为研究工具,与大家共同进步. 话归正题:先搭建opencv的环境. 1.下载安装包3.0 a,官网打开 ...
- Calendar获取当前年份、月份、日期
import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Date; public class Te ...
- FIFO的使用总结
使用FIFO积累 FIFO是在FPGA设计中使用的非常频繁,也是影响FPGA设计代码稳定性以及效率等得关键因素.我总结一下我在使用FIFO过程中的一些心得,与大家分享. 我本人是做有线 ...
- Centos7防范SYN
我们这里应用的是CentOS5.3,并内核使用的是2.6.18-128.el5PAE #1 SMP .修改部分TCP ,有的是为了提高性能与负载,但是存在降低稳定性的风险.有的则是安全方面的配置,则有 ...
- java 设计模式参考资料
参考博客 http://www.cnblogs.com/lin3615/p/3783272.html 设计模式之责任链模式http://www.cnblogs.com/draem0507/p/3784 ...
- r-mq实现顺序消费,不重复消费
根据订单号,同一订单号的消息,会被发送到同一个topic下的同一个queue,发送端的有序,会导致topic中消息的有序,而consumer和queue是一对多?的关系.可以保证topic中的有顺序的 ...
- 使用FileResult导出Excel数据文件
用的是Html拼接成Table表格的方式,返回 FileResult 输出一个二进制的文件. 第一种:使用FileContentResult // 通过使用文件内容,内容类型,文件名称创建一个File ...
- day12作业答案
2.1 # lst=['asdgg','as','drtysr'] # lst2=[i.upper() for i in lst if len(i) >3 ] # print(lst2) # 2 ...
- Python 通过队列实现一个生产者消费者模型
import time from multiprocessing import Process,Queue #生产者 def producer(q): for i in range(10): time ...