day07 eclipse使用本地 库文件 访问HDFS
常用命令
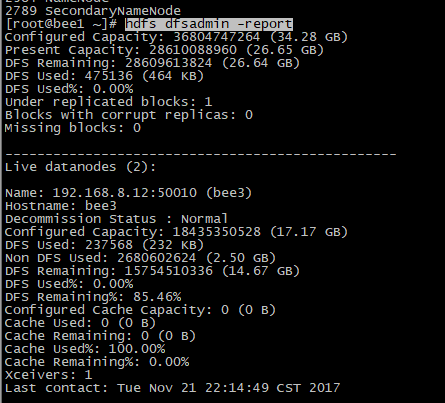
1. hdfs dfsadmin -report 查看系统的各台机器状态
- HDFS的概念和特性
- 首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
- 其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
- 重要特性如下:
- (1)HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
- (2)HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
- (3)目录结构及文件分块信息(元数据)的管理由namenode节点承担
- ——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
- (4)文件的各个block的存储管理由datanode节点承担
- ---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
- (5)HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
1. 把haddop文件放在某I个位置用来引用

2.
3.

4.进行jar包的添加
其中把所有的common lib添加,然后添加

接着把hdfs的所有lib添加 和 添加

------------------------------------------在Windows系统端配置HDFS环境------------------

- PS:因为系统的不同平台问题, 首先把 windos系统编译好的bin和lib文件替换掉,然后再到系统环境变量 里配置HADOOP_HOME环境变量,可以测试代码
- package cn.itcast.bigdata.hdfs;
- import java.io.IOException;
- import java.net.URI;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.junit.Before;
- import org.junit.Test;
- /**
- *
- * 客户端去操作hdfs时,是有一个用户身份的
- * 默认情况下,hdfs客户端api会从jvm中获取一个参数来作为自己的用户身份:-DHADOOP_USER_NAME=hadoop
- *
- * 也可以在构造客户端fs对象时,通过参数传递进去
- * @author
- *
- */
- public class Study {
- FileSystem fs = null;
- Configuration conf = null;
- @Before
- public void init() throws Exception{
- conf = new Configuration();
- //拿到一个文件系统的客户端实例
- // fs = FileSystem.get(conf );
- conf.set("fs.defaultFS", "hdfs://192.168.8.10:9000"); //其实这个ip就是我的bee1
- //拿到一个文件系统操作的客户端实例对象
- /*fs = FileSystem.get(conf);*/
- //可以直接传入 uri和用户身份
- fs = FileSystem.get(new URI("hdfs://192.168.8.10:9000"),conf,"root"); //最后一个参数为用户名
- }
- @Test
- public void testUpload() throws Exception, IOException{
- Thread.sleep(2000);
- fs.copyFromLocalFile(false,new Path("D:/contact.xml"), new Path("/contact.xml.copy"));//这个false,是因为使用了win10系统
- fs.close();
- }
- }

******HDFS原理篇******
4. hdfs的工作机制
1. HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)
2. NameNode负责管理整个文件系统的元数据(文件放置的位置,和切分大小)
3. DataNode 负责管理用户的文件数据块
4. 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
5. 每一个文件块可以有多个副本,并存放在不同的datanode上
6. Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
7. HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
-
HDFS的概念和特性
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
重要特性如下:
(1)HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
(2)HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
(3)目录结构及文件分块信息(元数据)的管理由namenode节点承担
——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
(4)文件的各个block的存储管理由datanode节点承担
---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
(5)HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
-----------------
4.2 HDFS写数据流程
4.2.1 概述
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本
4.2.2 详细步骤图
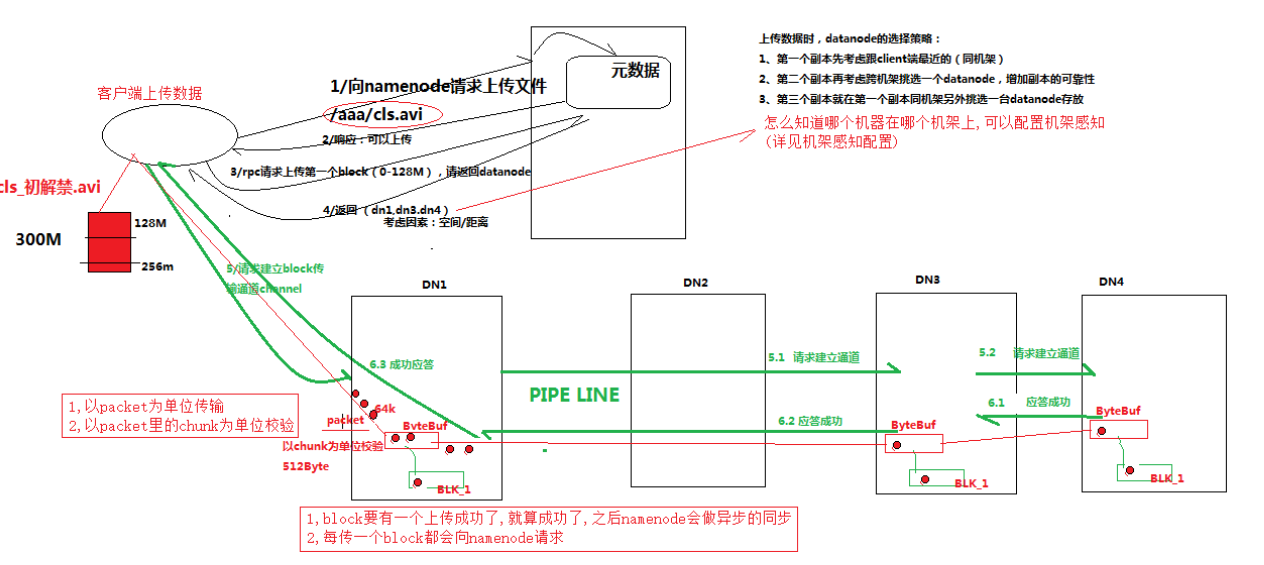
4.2.3 详细步骤解析
- PS:比如说要上次一个300M的电影。
1.想namenode请求说,你要上传的文件与路径。 namenode查找过以后说ok,然后就可以响应上传了
2.请求第一个block,请返回打ndatanode,返回相应相应的设备(这里选择的选择策略还是比较复杂的,总之是为了数据的安全性)
3.上面都好了,就可以传输了,他们会建好管道线,以packet传(每一个64k),中间有读写的缓冲层。
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
--------------------
4.3. HDFS读数据流程
4.3.1 概述
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件
4.3.2 详细步骤图

- PS:客户端请求文件时,namenode会根据元数据进行查找 block的位置然后返回给客户端,然后客户端就可以根据文件的位置进行下载了。
5. NAMENODE工作机制-------主要看/home/hadoop/hdpdata1文件
5.1 NAMENODE职责
NAMENODE职责:
1 . 负责客户端请求的响应
2 . 元数据的管理(查询,修改)
5.2 元数据管理
namenode对数据的管理采用了三种存储形式:
1.内存元数据(NameSystem)
2.磁盘元数据镜像文件
3.数据操作日志文件(可通过日志运算出元数据)
5.2.1 元数据存储机制
A、内存中有一份完整的元数据(内存meta data) 序列化
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
C、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中
注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中
5.2.2 元数据手动查看
可以通过hdfs的一个工具来查看edits中的信息
- bin/hdfs oev -i edits -o edits.xml
- bin/hdfs oiv -i fsimage_0000000000000000087 -p XML -o fsimage.xml
5.2.3 元数据的checkpoint
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,
并加载到内存进行merge(这个过程称为checkpoint)
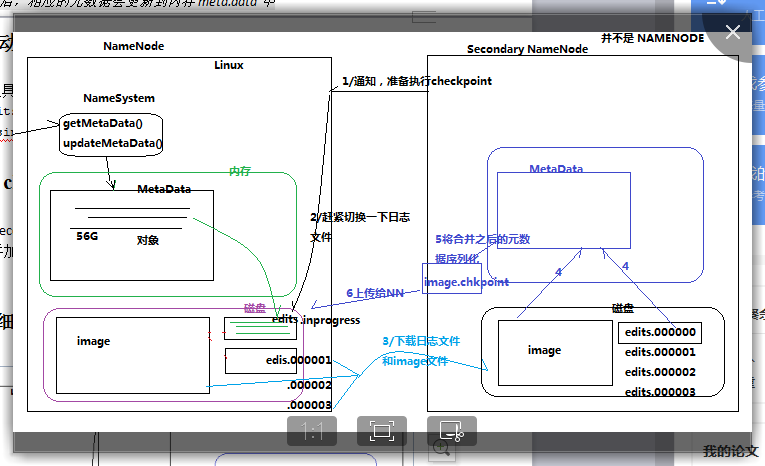
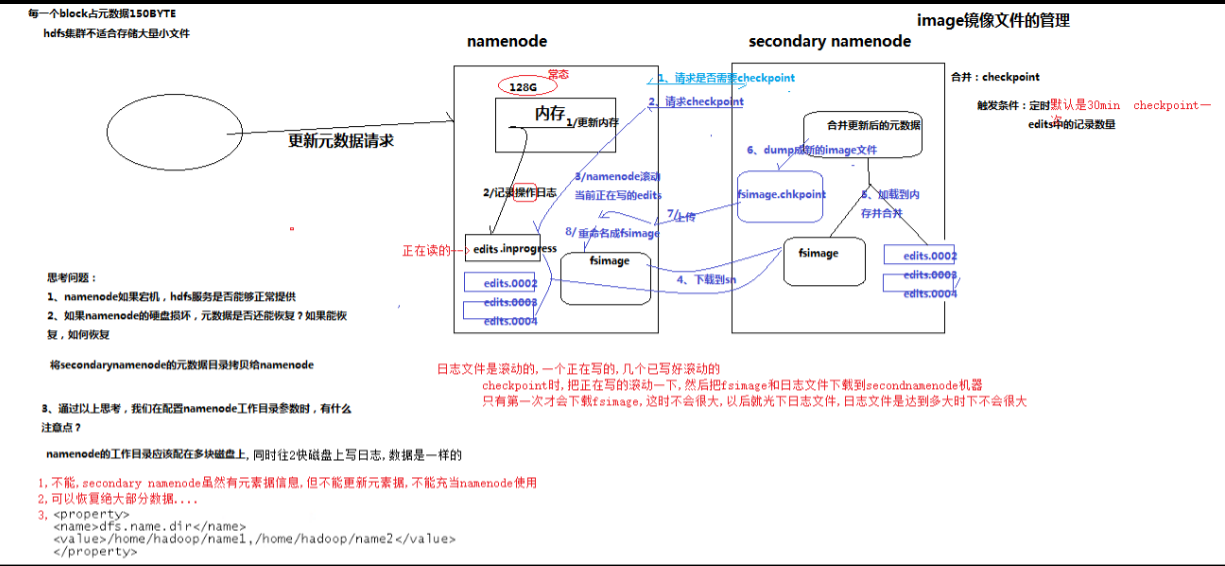

- PS: namenode是怎样工作的呢? 看上图,每当有新的文件上传的时候,namenode都会查询和返回,这件放置的位置都放在fsimage这个镜像文件中,但不是实时的。
namenode会把正在执行的操作,放入edits这个日志文件中。为了安全备份考虑,secondary namenode 它为 镜像文件和日志记录重新生成新的镜像,来跟新以前的镜像。
namenode丢失的话,可以从secondary namenode找回来。但是找到也是之前的数据,终有一些是丢失的,所以要在多台设备上配置dfs.name.dir,保证数据的不丢失
PS:可以看到namenode有128g大小 , hdfs适合放置大文件。
--------------------------------------------------------------------------
PS : hdpdata是防止 元数据的位置,如下图
tree hdpdata

dfs.namenode.name.dir属性可以配置多个目录,
如/data1/dfs/name,/data2/dfs/name,/data3/dfs/name,....。各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到Hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
下面对$dfs.namenode.name.dir/current/目录下的文件进行解释。
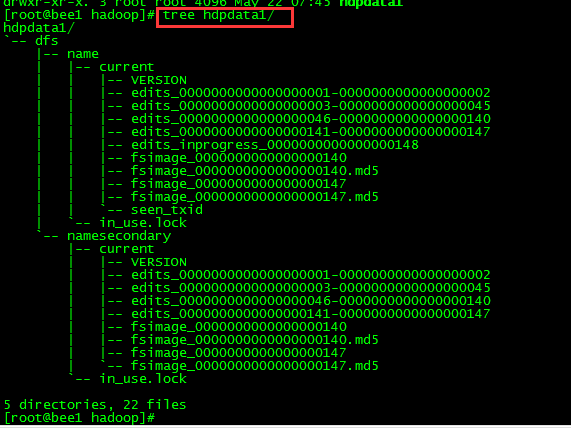
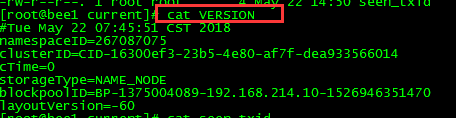
1、VERSION文件是Java属性文件,内容大致如下:
|
其中
(1)namespaceID是文件系统的唯一标识符,在文件系统首次格式化之后生成的;
(2)storageType说明这个文件存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE);
(3)cTime表示NameNode存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳;
(4)ayoutVersion表示HDFS永久性数据结构的版本信息, 只要数据结构变更,版本号也要递减,此时的HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的NameNode无法使用;
(5)clusterID是系统生成或手动指定的集群ID,在-clusterid选项中可以使用它;如下说明
a、使用如下命令格式化一个Namenode:
$HADOOP_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
选择一个唯一的cluster_id,并且这个cluster_id不能与环境中其他集群有冲突。如果没有提供cluster_id,则会自动生成一个唯一的ClusterID。
b、使用如下命令格式化其他Namenode:
$HADOOP_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
c、升级集群至最新版本。在升级过程中需要提供一个ClusterID,例如:
$HADOOP_PREFIX_HOME/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID>
如果没有提供ClusterID,则会自动生成一个ClusterID。
(6)blockpoolID:是针对每一个Namespace所对应的blockpool的ID,上面的这个BP-893790215-192.168.24.72-1383809616115就是在我的ns1的namespace下的存储块池的ID,这个ID包括了其对应的NameNode节点的ip地址。
2、$dfs.namenode.name.dir/current/seen_txid非常重要,是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,循序从头跑edits_0000001~到seen_txid的数字。所以当你的hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生建置namenode时metaData的资料有缺少,导致误删Datanode上多余Block的资讯。
3、$dfs.namenode.name.dir/current目录下在format的同时也会生成fsimage和edits文件,及其对应的md5校验文件。

补充:seen_txid
文件中记录的是edits滚动的序号,每次重启namenode时,namenode就知道要将哪些edits进行加载edits

6. DATANODE的工作机制
6.1 概述
1、Datanode工作职责:
a. 存储管理用户的文件块数据
b.定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
(这点很重要,因为,当集群中发生某些block副本失效时,集群如何恢复block初始副本数量的问题)
|
<property> <name>dfs.blockreport.intervalMsec</name> <value>3600000</value> /**36000向namenode汇报一次信息*/ <description>Determines block reporting interval in milliseconds.</description> </property> |
2、Datanode掉线判断时限参数
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
|
/*内部的配置如图*/ <property> <name>heartbeat.recheck.interval</name> <value>2000</value> </property> <property> <name>dfs.heartbeat.interval</name> <value>1</value> </property> |
6.2 观察验证DATANODE功能-----复习时可以忽略
上传一个文件,观察文件的block具体的物理存放情况:
在每一台datanode机器上的这个目录中能找到文件的切块:
/home/hadoop/app/hadoop-2.4.1/tmp/dfs/data/current/BP-193442119-192.168.2.120-1432457
---------------------------HDFS访问API----------------------------------------------------------------------------------------------------
- package cn.itcast.bigdata.hdfs;
- import java.io.FileInputStream;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.net.URI;
- import java.util.Iterator;
- import java.util.Map.Entry;
- import org.apache.commons.io.IOUtils;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.BlockLocation;
- import org.apache.hadoop.fs.FSDataInputStream;
- import org.apache.hadoop.fs.FSDataOutputStream;
- import org.apache.hadoop.fs.FileStatus;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.LocatedFileStatus;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.fs.RemoteIterator;
- import org.junit.Before;
- import org.junit.Test;
- /**
- *
- * 客户端去操作hdfs时,是有一个用户身份的
- * 默认情况下,hdfs客户端api会从jvm中获取一个参数来作为自己的用户身份:-DHADOOP_USER_NAME=root
- *
- * 也可以在构造客户端fs对象时,通过参数传递进去
- * @author
- *
- */
- public class Study {
- FileSystem fs = null;
- Configuration conf = null;
- @Before
- public void init() throws Exception{
- conf = new Configuration();
- //拿到一个文件系统的客户端实例
- // fs = FileSystem.get(conf );
- conf.set("fs.defaultFS", "hdfs://192.168.8.10:9000");
- //拿到一个文件系统操作的客户端实例对象
- /*fs = FileSystem.get(conf);*/
- //可以直接传入 uri和用户身份
- fs = FileSystem.get(new URI("hdfs://192.168.8.10:9000"),conf,"root"); //最后一个参数为用户名
- }
- /**
- * 上传文件
- * @throws Exception
- * @throws IOException
- */
- @Test
- public void testUpload() throws Exception, IOException{
- Thread.sleep(2000);
- fs.copyFromLocalFile(false,new Path("D:/contact.xml"), new Path("/contact.xml.copy"));//这个false,是因为使用了win10系统
- fs.close();
- }
- /**
- * 下载文件
- * @throws Exception
- */
- @Test
- public void testDownload() throws Exception {
- fs.copyToLocalFile(false,new Path("/contact.xml.copy"), new Path("d:/"));
- fs.close();
- }
- /**
- * 测试conf的参数,输出的都是 配置的信息
- */
- @Test
- public void testConf(){
- Iterator<Entry<String, String>> it = conf.iterator();
- while(it.hasNext()){
- Entry<String, String> entry = it.next();
- System.out.println(entry.getKey()+":"+entry.getValue());
- }
- }
- /***
- * 创建文件
- * @throws Exception
- */
- @Test
- public void testMkdir() throws Exception {
- boolean flag = fs.mkdirs(new Path("/testmkdir/aaa/bbb"));
- System.out.println(flag);
- }
- @Test
- public void testDelete() throws Exception {
- boolean flag = fs.delete(new Path("/testmkdir/aaa"), true);
- System.out.println(flag);
- }
- /**
- * 递归列出指定目录下所有子文件夹中的文件
- * @throws Exception
- */
- @Test
- public void testLs() throws Exception {
- RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);//true是否迭代循环
- while(listFiles.hasNext()){
- LocatedFileStatus fileStatus = listFiles.next();//文件状态
- System.out.println("blocksize: " +fileStatus.getBlockSize());//
- System.out.println("owner: " +fileStatus.getOwner());
- System.out.println("Replication: " +fileStatus.getReplication());
- System.out.println("Permission: " +fileStatus.getPermission());
- System.out.println("Name: " +fileStatus.getPath().getName());
- System.out.println("------------------");
- BlockLocation[] blockLocations = fileStatus.getBlockLocations();
- for(BlockLocation b:blockLocations){
- System.out.println("块起始偏移量: " +b.getOffset());
- System.out.println("块长度:" + b.getLength());
- //块所在的datanode节点
- String[] datanodes = b.getHosts();
- for(String dn:datanodes){
- System.out.println("datanode:" + dn);
- }
- }
- }
- }
- /**
- * 手动遍历
- * @throws Exception
- */
- @Test
- public void testLs2() throws Exception {//手动遍历,一层一层遍历
- FileStatus[] listStatus = fs.listStatus(new Path("/"));
- for(FileStatus file :listStatus){
- System.out.println("name: " + file.getPath().getName());
- System.out.println((file.isFile()?"file":"directory"));
- }
- }
----------------------------通过流的方式访问hdfs
/**
* 用流的方式来操作hdfs上的文件
* 可以实现读取指定偏移量范围的数据
* @author
*
*/-------------------------------------------------------下面是另一个文件了- /**
- * 通过流的方式上传文件到hdfs
- * @throws Exception
- */
- @Test
- public void testUpload1() throws Exception {
- FSDataOutputStream outputStream = fs.create(new Path("/angelababy.love"), true);//true是否重写
- FileInputStream inputStream = new FileInputStream("d:/angelababy.love");
- IOUtils.copy(inputStream, outputStream);
- }
- /**
- * 通过流的方式获取hdfs上数据
- * @throws Exception
- */
- @Test
- public void testDownLoad1() throws Exception {
- FSDataInputStream inputStream = fs.open(new Path("/angelababy.love"));
- FileOutputStream outputStream = new FileOutputStream("d:/angelababy.txt");
- IOUtils.copy(inputStream, outputStream);
- }
- /**
- * 读取流的一部分
- * @throws Exception
- */
- @Test
- public void testRandomAccess() throws Exception{
- FSDataInputStream inputStream = fs.open(new Path("/angelababy.love"));
- inputStream.seek(12);
- FileOutputStream outputStream = new FileOutputStream("d:/angelababy.love.txt");
- IOUtils.copy(inputStream, outputStream);
- }
- /**
- * 显示hdfs上文件的内容
- * @throws IOException
- * @throws IllegalArgumentException
- */
- @Test
- public void testCat() throws IllegalArgumentException, IOException{
- FSDataInputStream in = fs.open(new Path("/angelababy.love"));
- IOUtils.copy(in, System.out);
- // IOUtils.copyBytes(in, System.out, 1024);
- }
- }

---------------------------------这个没有做
9. 案例2:开发JAVA采集程序
9.1 需求
从外部购买数据,数据提供方会实时将数据推送到6台FTP服务器上,我方部署6台接口采集机来对接采集数据,并上传到HDFS中
提供商在FTP上生成数据的规则是以小时为单位建立文件夹(2016-03-11-10),每分钟生成一个文件(00.dat,01.data,02.dat,........)
提供方不提供数据备份,推送到FTP服务器的数据如果丢失,不再重新提供,且FTP服务器磁盘空间有限,最多存储最近10小时内的数据
由于每一个文件比较小,只有150M左右,因此,我方在上传到HDFS过程中,需要将15分钟时段的数据合并成一个文件上传到HDFS
为了区分数据丢失的责任,我方在下载数据时最好进行校验
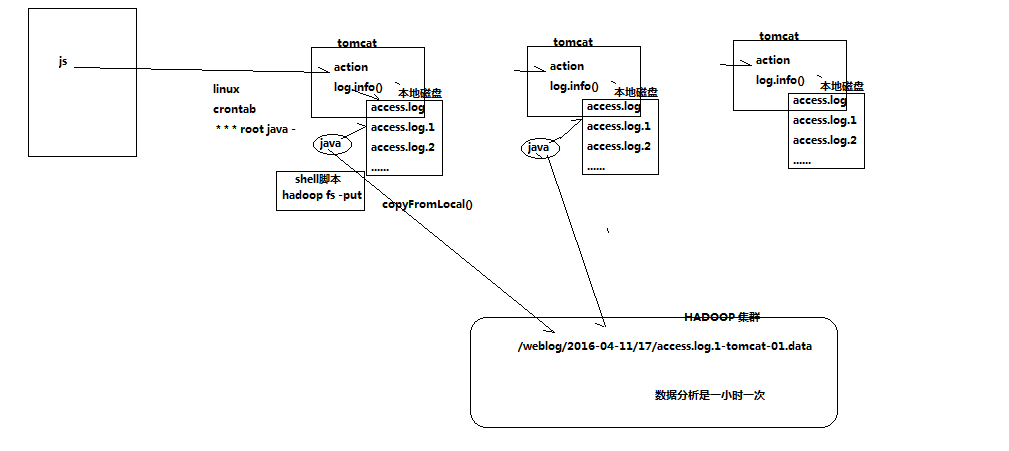
- PS :就是收集起群上日志合并文件,根据下面的文件创建目录,弄个程序一直生成日志,最后跑脚本
===============================
#!/bin/bash- #set java env
- export JAVA_HOME=/home/hadoop/app/jdk1.7.0_51
- export JRE_HOME=${JAVA_HOME}/jre
- export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
- export PATH=${JAVA_HOME}/bin:$PATH
- #set hadoop env
- export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.4
- export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
- #版本1的问题:
- #虽然上传到Hadoop集群上了,但是原始文件还在。如何处理?
- #日志文件的名称都是xxxx.log1,再次上传文件时,因为hdfs上已经存在了,会报错。如何处理?
- #如何解决版本1的问题
- # 1、先将需要上传的文件移动到待上传目录
- # 2、在讲文件移动到待上传目录时,将文件按照一定的格式重名名
- # /export/software/hadoop.log1 /export/data/click_log/xxxxx_click_log_{date}
- #日志文件存放的目录
- log_src_dir=/home/hadoop/logs/log/
- #待上传文件存放的目录
- log_toupload_dir=/home/hadoop/logs/toupload/
- #日志文件上传到hdfs的根路径
- hdfs_root_dir=/data/clickLog/20151226/
- #打印环境变量信息
- echo "envs: hadoop_home: $HADOOP_HOME"
- #读取日志文件的目录,判断是否有需要上传的文件
- echo "log_src_dir:"$log_src_dir
- ls $log_src_dir | while read fileName
- do
- if [[ "$fileName" == access.log.* ]]; then
- # if [ "access.log" = "$fileName" ];then
- date=`date +%Y_%m_%d_%H_%M_%S`
- #将文件移动到待上传目录并重命名
- #打印信息
- echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
- mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
- #将待上传的文件path写入一个列表文件willDoing
- echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
- fi
- done
- #找到列表文件willDoing
- ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while read line
- do
- #打印信息
- echo "toupload is in file:"$line
- #将待上传文件列表willDoing改名为willDoing_COPY_
- mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
- #读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
- cat $log_toupload_dir$line"_COPY_" |while read line
- do
- #打印信息
- echo "puting...$line to hdfs path.....$hdfs_root_dir"
- hadoop fs -put $line $hdfs_root_dir
- done
- mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
- done
day07 eclipse使用本地 库文件 访问HDFS的更多相关文章
- Eclipse中新建jsp文件访问页面时乱码问题
新建.jsp文件,charset和pageEncoding默认是ISO-8859-1,这样的话访问页面时会出现乱码,解决办法:将charset和pageEncoding改为UTF-8(或者GBK/GB ...
- 关于Eclipse 和 IDEA 导入library库文件 的步骤
这里我们以PullToRefresh(上拉刷新下拉加载)组件的library为例 下载地址: https://github.com/chrisbanes/Android-PullToRefresh 现 ...
- 【HDFS API编程】从本地拷贝文件,从本地拷贝大文件,拷贝HDFS文件到本地
接着之前继续API操作的学习 CopyFromLocalFile: 顾名思义,从本地文件拷贝 /** * 使用Java API操作HDFS文件系统 * 关键点: * 1)create Configur ...
- 访问hdfs里的文件
准备工作: 给hdfs里上传一份用于测试的文件 [root@master ~]# cat hello.txt hello 1 hello 2 hello 3 hello 4 [root@master ...
- maven的安装、路径配置、修改库文件路径和eclipse中的配置、创建maven工程。
注:本文来源于:杨四郎2018 <maven的安装.路径配置.修改库文件路径和eclipse中的配置.创建maven工程> 一.maven的安装 首先,先到官网去下载maven.这里是官 ...
- 访问本地json文件因跨域导致的问题
我使用jquery的getJSON的方法获取本地的json文件,并进行操作,获取json 数据代码如下: $.getJSON("invite_panel.json",functio ...
- hadoop的API对HDFS上的文件访问
这篇文章主要介绍了使用hadoop的API对HDFS上的文件访问,其中包括上传文件到HDFS上.从HDFS上下载文件和删除HDFS上的文件,需要的朋友可以参考下hdfs文件操作操作示例,包括上传文件到 ...
- ios获取本地音乐库音乐很详细 扫描IPHONE本地音乐文件,获得音乐名,歌手名代码示例
//扫描本地音乐文件,返回艺术家列表 需要库MediaPlayer.framework -(NSArray*) findArtistList { NSMutableArray *artistList ...
- 利用JavaAPI访问HDFS的文件
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
随机推荐
- JavaScript -基础- 函数与对象(三)数组对象
一.数组对象 1.创建方式 1)创建方式一 var arr=[1,2,3]; 2)创建方式二 var arr2=new Array(1,2,3); 注意: 数组中可以存储任何数据类型.方法类型(Jav ...
- 每天CSS学习之transform
transform是CSS3的一个属性,其作用是用来进行2D或3D变换. 一.2D变换 1. translate(x-offset , y-offset) translate的作用就是用作位置的移动. ...
- 每天CSS学习之text-shadow
今天学习的是CSS3的一个属性text-shadow.该属性能映射出文字的阴影. text-shadow一共就四个属性: text-shadow: h-shadow v-shadow [blur] ...
- Find the Missing Number II
Giving a string with number from 1-n in random order, but miss 1 number.Find that number. Notice n & ...
- Linux学习 :多线程编程
1.Linux进程与线程() 进程:通过fork创建子进程与创建线程之间是有区别的:fork创建出该进程的一份拷贝,创建时额外申请了新的内存空间以及存储代码段.数据段.BSS段.堆.栈空间, ...
- SQL-22 统计各个部门对应员工涨幅的次数总和,给出部门编码dept_no、部门名称dept_name以及次数sum
题目描述 统计各个部门对应员工涨幅的次数总和,给出部门编码dept_no.部门名称dept_name以及次数sumCREATE TABLE `departments` (`dept_no` char( ...
- SQL-13 从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
题目描述 从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t.CREATE TABLE IF NOT EXISTS "titles" ( ...
- 关于vivado implement后clock interaction报告的理解(更新中)
对于较大工程很难避免遇到CDC问题,vivado自带的分析工具可以报告跨时钟状态. 详情参看手册UG906-Design Analysis and Closure Techniques. (1)关于p ...
- shiro学习(二)身份验证
身份验证,即在应用中谁能证明他就是他本人.一般提供如他们的身份ID一些标识信息来表明他就是他本人,如提供身份证,用户名/密码来证明. 在shiro中,用户需要提供principals (身份)和cre ...
- 莫烦tensorflow(2)-Session
import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2' import tensorflow as tfmatrix1 = tf.constant([[3,3] ...