Flume 在有赞大数据的实践
https://mp.weixin.qq.com/s/gd0KMAt7z0WbrJL0RkMEtA
文 | hujiahua on 大数据
一、前言
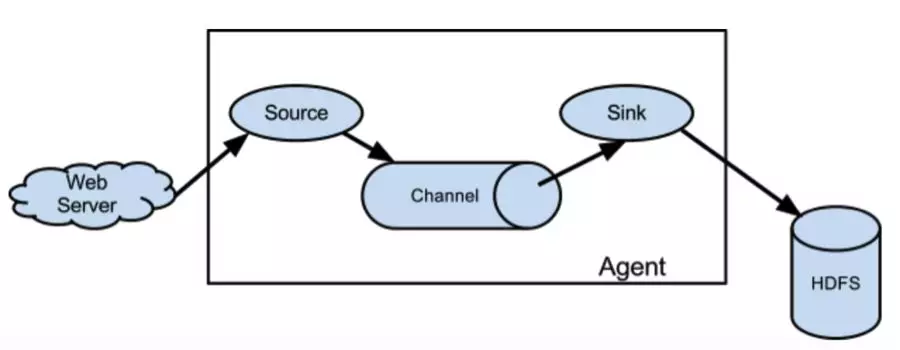
Flume 是一个分布式的高可靠,可扩展的数据采集服务。
Flume 在有赞的大数据业务中一直扮演着一个稳定可靠的日志数据“搬运工”的角色。本文主要讲一下有赞大数据部门在 Flume 的应用实践,同时也穿插着我们对 Flume 的一些理解。
二、Delivery 保证
认识 Flume 对事件投递的可靠性保证是非常重要的,它往往是我们是否使用 Flume 来解决问题的决定因素之一。
消息投递的可靠保证有三种:
At-least-once
At-most-once
Exactly-once
基本上所有工具的使用用户都希望工具框架能保证消息 Exactly-once ,这样就不必在设计实现上考虑消息的丢失或者重复的处理场景。但是事实上很少有工具和框架能做到这一点,真正能做到这一点所付出的成本往往很大,或者带来的额外影响反而让你觉得不值得。假设 Flume 真的做到了Exactly-once ,那势必降低了稳定性和吞吐量,所以 Flume 选择的策略是 At-least-once 。
当然这里的 At-least-once 需要加上引号,并不是说用上 Flume 的随便哪个组件组成一个实例,运行过程中就能保存消息不会丢失。事实上 At-least-once 原则只是说的是 Source 、 Channel和 Sink 三者之间上下投递消息的保证。而当你选择 MemoryChannel 时,实例如果异常挂了再重启,在 channel 中的未被 sink 所消费的残留数据也就丢失了,从而没办法保证整条链路的 At-least-once。
Flume 的 At-least-once 保证的实现基础是建立了自身的 Transaction 机制。Flume 的 Transaction 有4个生命周期函数,分别是 start、 commit、 rollback 和 close。 当 Source 往 Channel 批量投递事件时首先调用 start 开启事务,批量 put 完事件后通过 commit 来提交事务,如果 commit 异常则 rollback ,然后 close 事务,最后 Source 将刚才提交的一批消息事件向源服务 ack(比如 kafka 提交新的 offset )。 Sink消费 Channel 也是相同的模式,唯一的区别就是 Sink 需要在向目标源完成写入之后才对事务进行 commit。两个组件的相同做法都是只有向下游成功投递了消息才会向上游 ack,从而保证了数据能 At-least-once 向下投递。
三、datay 应用场景
基于 mysql binlog 的数仓增量同步( datay 业务)是大数据这边使用 Flume 中一个比较经典的应用场景,datay 具体业务不详细说明,需要强调的是它对Flume的一个要求是必须保证在 nsq(消息队列)的 binlog消息能可靠的落地到 hdfs ,不允许一条消息的丢失,需要绝对的 At-least-once。
Flume 模型本身是基于 At-least-once 原则来传递事件,所以需要需要考虑是在各种异常情况(比如进程异常挂了)下的 At-least-once 保证。显然 MemoryChannel 无法满足,所以我们用 FlieChannel 做代替。由于公司目前是使用 nsq 作为 binlog 的消息中转服务,故我们没有办法使用现有的 KafkaSource,所以基于公司的 nsq sdk 扩展了 NsqSource。这里需要说明的是为了保证 At-least-once, Source 源必须支持消息接收的 ack 机制,比如 kafka 客户端只有认为消费了消息后,才对 offset 进行提交,不然就需要接受重复的消息。
于是我们第一个版本上线了,看上去很有保障了,即使进程异常挂了重启也不会丢数据。
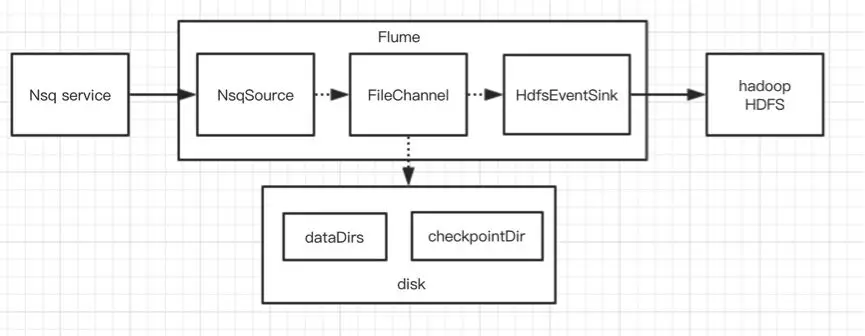
可能有同学想到一个关键性的问题:如果某一天磁盘坏了而进程异常退出,而 FileChannel 刚好又有未被消费的事件数据,这个时候不就丢数据了吗?虽然磁盘坏了是一个极低的概率,但这确实是一个需要考虑的问题。
在 Flume 现有组件中比 FlieChannel 更可靠的,可能想到的是 KafkaChannel ,kafka 可以对消息保留多个副本,从而增强了数据的可靠性。但是我们第二版本的方案没有选择它,而是直接扩展出 NsqChannel 。于是第二个版本就有了。
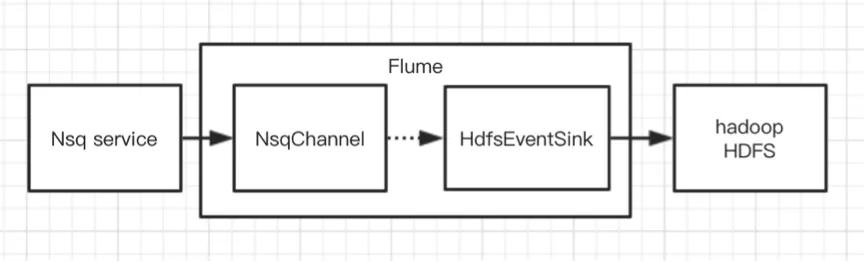
初次使用 Flume 的用户往往陷入到必须搭配 Source + Channel + Sink 三个组件的固有模式,事实上我们不一定要三个组件都使用上。另外直接 NsqChannel 到 HDFSEventSink 的有几个好处:
每个消息的传递只需要一次事务,而非两次,性能上更佳。
避免引入了新的 kafka 服务,减少了资源成本的同时保持架构上更简单从而更稳定。
四、定制化扩展
Flume 在各个组件的扩展性支持具有非常好的设计考虑。
当无法满足我们的自定义需求,我们可以选择合适的组件上进行扩展。下面就讲讲我们扩展的一些内容。
NsqSource。
在 Flume 定制化一个 Source 比较简单,继承一个已有通用实现的抽象类,实现相对几个生命周期方法即可。这里说明注意的是 Flume 组件的生命周期在可能被会调用多次,比如 Flume 具有自动发现实例配置发生变化并 restart 各个组件,这种情况需要考虑资源的正确释放。
HdfsEventSink扩展配置。
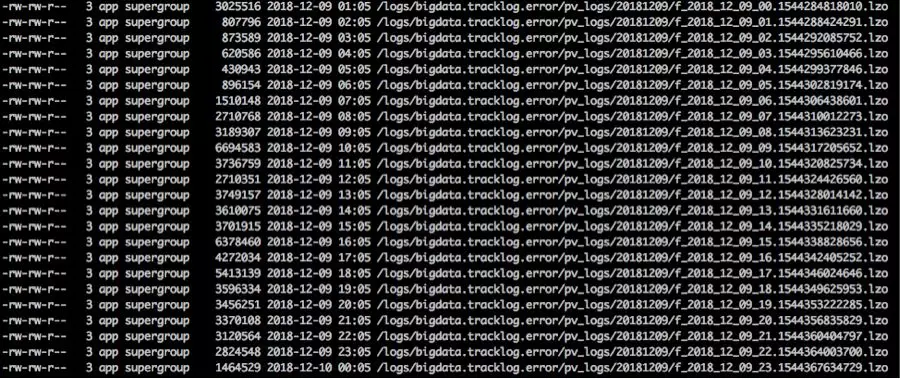
它本身就具有 role file 功能,比如当 Sink 是按小时生成文件,有这一个小时的第一个事件创建新的文件,然后经过固定的 role 配置时间(比如一小时)关闭文件。这里存在的问题就是如果源平时的数据量不大,比如8点这个小时的第一个事件是在8点25分来临,那就是说需要9点25才能关闭这个文件。由于没有关闭的tmp文件会被离线数据任务的计算引擎所忽略,在小时级的数据离线任务就没办法得到实时的数据。而我们做的改造就是 roll file 基于整点时间,而不是第一次事件的时间,比如固定的05分关闭上一次小时的文件,而离线任务调度时间设置在每小时的05分之后就能解决这个问题。最终的效果给下图:
MetricsReportServer。
当我们需要收集 Flume 实例运行时的各个组件 counter metric ,就需要开启 MonitorService服务。自定义了一个定期发生 http 请求汇报 metric 到一个集中的 web 服务。原生的 HTTPMetricsServer 也是基于 http 服务,区别在于它将 Flume 作为 http 服务端,而我们将很多实例部署在一台机器上,端口分配成了比较头疼的问题。
当我们收集到以下的 counter metric 时,就可以利用它来实现一些监控报警。
{
"identity":"olap_offline_daily_olap_druid_test_timezone_4@49",
"startTime":1544287799839,
"reportCount":4933,
"metrics":{
"SINK.olap_offline_daily_olap_druid_test_timezone_4_snk":{
"ConnectionCreatedCount":"9",
"ConnectionClosedCount":"8",
"Type":"SINK",
"BatchCompleteCount":"6335",
"BatchEmptyCount":"2",
"EventDrainAttemptCount":"686278",
"StartTime":"1544287799837",
"EventDrainSuccessCount":"686267",
"BatchUnderflowCount":"5269",
"StopTime":"0",
"ConnectionFailedCount":"48460"
},
"SOURCE.olap_offline_daily_olap_druid_test_timezone_4_src":{
"KafkaEventGetTimer":"26344146",
"AppendBatchAcceptedCount":"0",
"EventAcceptedCount":"686278",
"AppendReceivedCount":"0",
"StartTime":"1544287800219",
"AppendBatchReceivedCount":"0",
"KafkaCommitTimer":"14295",
"EventReceivedCount":"15882278",
"Type":"SOURCE",
"OpenConnectionCount":"0",
"AppendAcceptedCount":"0",
"KafkaEmptyCount":"0",
"StopTime":"0"
},
"CHANNEL.olap_offline_daily_olap_druid_test_timezone_4_cha":{
"ChannelCapacity":"10000",
"ChannelFillPercentage":"0.11",
"Type":"CHANNEL",
"ChannelSize":"11",
"EventTakeSuccessCount":"686267",
"StartTime":"1544287799332",
"EventTakeAttemptCount":"715780",
"EventPutAttemptCount":"15882278",
"EventPutSuccessCount":"686278",
"StopTime":"0"
}
}
}
事件时间戳拦截。有一些 hdfs sink 业务对消息事件的时间比较敏感,同一小时的数据必须放在同一个目录里,这就要求使用
HdfsEventSink的时候不能使用系统时间来计算文件目录,而是应该基于消息内容中的某个时间戳字段。这个可以通过扩展Interceptor来解决。Interceptor用于在Source投递事件给Channel前的一个拦截处理,一般都是用来对事件丰富header信息。强烈不建议在Source中直接处理,实现一个Interceptor可以满足其他Source类似需求的复用性。
五、性能调优
Flume 实例进行性能调优最常见的配置是 事务batch 和 ChannelCapacity。
事务 batch 指的是合理设置 batch 配置,可以明显的改善实例的吞吐量。上面已经讲到
Source对Channel进行 put 或者Sink对Channel进行 take 都是通过开启事务来操作,所以调大两个组件的 batch 配置可以降低 cpu 消耗,减少网络 IO 等待等。Channel的 capacity 大小直接影响着 source 和 sink 两端的事件生产和消费。capacity 越大,吞吐量越好,但是其他因素制约着不能设置的很大。比如MemoryChannel,直接表现着对内存的消耗,以及进程异常退出所丢失的事件数量。不同的Channel需要不同的考虑,最终 trade-off 是难免的。
六、总结和展望
Flume 是一个非常稳定的服务,这一点在我们生产环境中得到充分验证。
同时它的模型设计也非常清晰易懂,每一种组件类型都有很多现成的实现,同时特考虑到各个扩展点,所以我们很容易找到或者定制化我们所需要的数据管道的解决方案。
随着用户越来越多,需要有一个统一的平台来集中管理所有的 Flume 实例。 有以下几点好处:
降低用户对 Flume 的成本。尽可能在不太了解 Flume 的情况下就可以享受到它带来的价值。
有效对机器的资源进行合理协调使用。
完善的监控让 FLume 运行的更加稳定可靠。
当然这一步我们也才刚启动,希望它未来的价值变得越来越大。
扩展阅读
Flume 在有赞大数据的实践的更多相关文章
- 从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进
点击上方 蓝字关注我们 作者 | 宋哲琦 ✎ 编 者 按 在不久前的 Apache DolphinScheduler Meetup 2021 上,有赞大数据开发平台负责人 宋哲琦 带来了平台调度系统 ...
- 大数据项目实践:基于hadoop+spark+mongodb+mysql+c#开发医院临床知识库系统
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- 流式大数据计算实践(1)----Hadoop单机模式
一.前言 1.从今天开始进行流式大数据计算的实践之路,需要完成一个车辆实时热力图 2.技术选型:HBase作为数据仓库,Storm作为流式计算框架,ECharts作为热力图的展示 3.计划使用两台虚拟 ...
- Flume+Kafka+Storm+Redis 大数据在线实时分析
1.实时处理框架 即从上面的架构中我们可以看出,其由下面的几部分构成: Flume集群 Kafka集群 Storm集群 从构建实时处理系统的角度出发,我们需要做的是,如何让数据在各个不同的集群系统之间 ...
- 流式大数据计算实践(7)----Hive安装
一.前言 1.这一文学习使用Hive 二.Hive介绍与安装 Hive介绍:Hive是基于Hadoop的一个数据仓库工具,可以通过HQL语句(类似SQL)来操作HDFS上面的数据,其原理就是将用户写的 ...
- 流式大数据计算实践(6)----Storm简介&使用&安装
一.前言 1.这一文开始进入Storm流式计算框架的学习 二.Storm简介 1.Storm与Hadoop的区别就是,Hadoop是一个离线执行的作业,执行完毕就结束了,而Storm是可以源源不断的接 ...
- 流式大数据计算实践(5)----HBase使用&SpringBoot集成
一.前言 1.上文中我们搭建好了一套HBase集群环境,这一文我们学习一下HBase的基本操作和客户端API的使用 二.shell操作 先通过命令进入HBase的命令行操作 /work/soft/hb ...
- 流式大数据计算实践(4)----HBase安装
一.前言 1.前面我们搭建好了高可用的Hadoop集群,本文正式开始搭建HBase 2.HBase简介 (1)Master节点负责管理数据,类似Hadoop里面的namenode,但是他只负责建表改表 ...
- 流式大数据计算实践(3)----高可用的Hadoop集群
一.前言 1.上文中我们已经搭建好了Hadoop和Zookeeper的集群,这一文来将Hadoop集群变得高可用 2.由于Hadoop集群是主从节点的模式,如果集群中的namenode主节点挂掉,那么 ...
随机推荐
- Zabbix-2.X/3.X监控工具监控Redis以及zabbix Redis监控模板下载
为了监控Redis3的运行状况,去zabbix官网查找资料,根据提示,找到了这个项目:https://github.com/blacked/zbx_redis_template 但是文档和内容已经不匹 ...
- Android使用腾讯浏览服务X5内核
[前期准备] 腾讯X5 jar包下载地址 [点击打开] 本次完整DEMO源码 [打开Github] [集成步骤] 第一步:下载jar包添加到项目 第二步:添加权限 <uses-permissio ...
- 我对android开发的一点小感悟小看法
“Android”,“Android开发”等等这些词成了时下最热的词,也是时下大众最关注最吸引人眼球的话题,当然,最热门的行业也意味着高薪,好的就业环境,但同时也意味着强大的竞争力! Android系 ...
- linux删除软连接
#mkdir test_chk #touch test_chk/test.txt #vim test_chk/test.txt (这一步随便在这个test.txt里写点东东即可) 下面我们来创建tes ...
- Atitit 错误处理机制:(1)静默模式(2)警告模式 (3)异常模式
Atitit 错误处理机制:(1)静默模式(2)警告模式 (3)异常模式 三. PDO的错误处理机制: (1)静默模式 默认情况下与mysql处理方式一致,不现实错误信息(静默模式 ...
- Android开发(十三)——全屏滚动与listview
Android全屏滚动使用scrollview,其中有需要采用listview进输出的内容,scrollview与listview冲突. 开始的思维是使用一个Scrollview加上一个ListVie ...
- MXNET:分类模型
线性回归模型适用于输出为连续值的情景,例如输出为房价.在其他情景中,模型输出还可以是一个离散值,例如图片类别.对于这样的分类问题,我们可以使用分类模型,例如softmax回归. 为了便于讨论,让我们假 ...
- Serializable接口
Serializable这个接口起啥作用呢?? 这个接口没有提供任何方法,我们实现它有什么意义呢? Serializable接口是启用其序列化功能的接口.Serializable接口中没有任何方法,一 ...
- java.util.concurrent介绍【转】
java.util.concurrent介绍 java.util.concurrent 包含许多线程安全.测试良好.高性能的并发构建块.不客气地说,创建 java.util.concurrent ...
- hdoj:2045
#include <iostream> using namespace std; ]; int main() { int n; a[] = ; a[] = ; a[] = ; ; i &l ...