<YARN><MRv2><Spark on YARN>
MRv1 VS MRv2
MRv1:
- JobTracker: 资源管理 & 作业控制
- 每个作业由一个JobInProgress控制,每个任务由一个TaskInProgress控制。由于每个任务可能有多个运行实例,因此,TaskInProgress实际管理了多个运行实例TaskAttempt,每个运行实例可能运行了一个MapTask或ReduceTask。每个Map/Reduce Task会通过RPC协议将状态汇报给TaskTracker,再由TaskTracker进一步汇报给JobTracker。MRv2 / YARN:
- ResourceManager: 资源管理
- MRAppMaster:作业控制。MRAppMaster只负责管理一个作业,包括该作业的资源申请、作业运行过程监控和作业容错等。MRAppMaster会与ResourceManager、NodeManager通信,以申请资源和启动任务。
MRv1的不足
- JobTracker是MR框架的中心,存在单点故障。它需要与集群中的机器定时通信(heartbeat),需要管理哪些程序应该运行在哪些机器上,管理所有job失败,重启等。
- JobTracker完成了太多的任务,造成了过多的资源消耗,当job过多时,造成了很大的内存消耗,潜在地也增加了JobTracker的风险。【所以MRv2的重构思想是分离JobTracker-->资源管理 + 任务调度】
- 在TaskTracker端,仅仅以map/reduce task数目作为资源的表示过于简单。未考虑到cpu&内存的占用情况。若两个大内存消耗的task被调度到一块的话,很容易出现OOM(out of memory)。【因此MRv2的改进就是:为Application分配container,资源包括内存、CPU、磁盘、网络等等。】
- 在TaskTracker端,把资源强制划分为map task slot & reduce task slot。当系统中只要map task或只有reduce task时,会造成资源的浪费。
YARN架构

- Client:提交分布式程序的客户端,上传资源文件和JAR包到HDFS集群;
- ResourceManager:负责将集群的资源分配给各个应用使用;【RM是一个中心的服务,它调度、启动每一个Job所属的AM,监控AM的存在情况。】
- Container:资源分配和调度的基本单元,其中封装了的资源如内存、CPU、磁盘、网络带宽等。每个任务会被分配一个Container,并在该Container中执行且只能使用其封装的资源。
- NodeManager:计算节点,负责启动Container,同时通过心跳不断地与RM通信,描述该Worker节点的资源( CPU,内存,硬盘和网络带宽等)状况。【NM的功能比较专一,即负责Container状态的维护,并向RM保持心跳。】
- AppMaster:对应client提交的一个应用。客户端每提交一个应用,RM会在Worker节点上给它分配一个全局唯一的App master,App master可以在任何一台Worker节点上启动,负责管理作业的整个生命周期,包括通知NM创建Container,管理Container等。【AM负责一个Job生命周期内的所有工作。】
- YARN中分离出AM,还使得AM变成一个可变更的部分,用户可以对不同的编程模型写自己的AM,让更多类型的编程模型能够跑在Hadoop集群上。
MRv2工作流程
- RM收到client请求后,会在全局查看资源,如果哪台worker合适,其上运行的NM就为该作业生成container实例。生成的第一个Container实例内运行的就是AppMaster。AppMaster运行成功的时候要向RM进行注册。
- AppMaster向RM申请资源(eg:10个Container),得到消息反馈后,控制NM启动Container并运行任务,Container启动后直接对App Master负责(作业的调度中心是App Master,极大的减轻的RM的负担)。
- Tip:如果没有足够的container可以被申请,则会进行等待其他作业完成任务,空出Container后进行分配。
- App Master监控容器上任务的执行情况,反馈作业的执行状态信息和完成状态。
MRAppMaster
- MRAppMaster是MR的ApplicationMaster实现,它使得MR计算框架可以运行于YARN之上。
- 在YARN中,MRAppMaster负责管理MapReduce作业的生命周期,包括创建MapReduce作业,向ResourceManager申请资源,与NodeManage通信要求其启动Container,监控作业的运行状态,当任务失败时重新启动任务等。
整体框架
- YARN使用了基于事件驱动的异步编程模型,它通过事件将各个组件联系起来,并由一个中央事件调度器统一将各种事件分配给对应的事件处理器。
- TBD...
作业生命周期
- MRAppMaster类中的作业创建入口
public class MRAppMaster extends CompositeService{
public void start(){
...
job = createJob(getConfig()); // 创建Job
...
}- 作业初始化:
- 作业启动:
- TBD...
Protocal Buffer
- Hadoop2.x中已经将Protocal Buffer作为默认的序列化/反序列化框架,原来的自己实现的基于Writable的方式已经被淘汰了。
- PB是Google开源的一种轻量级的结构化数据存储格式,可以用于结构化数据的序列化/反序列化,很适合做数据存储或 RPC 数据交换格式。
- 优点是序列化/反序列化速度快,网络或者磁盘IO传输的数据少,支持向后兼容,这在可扩展地数据密集型应用中是非常重要的。
- 关于PB: TBD...
Resource Manager
- 在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager)。
- RM主要由以下几个部分组成:
- 用户交互:
- NM管理:
- NMLivelinessMonitor:监控NM是否alive。若一个NM在一定时间内(默认10min)未汇报信条信息,则认为NM dead,将其移除集群。
- NodesListManager:维护正常节点和异常节点列表,管理exlude(类似于黑名单)和inlude(类似于白名单)节点列表,这两个列表均是在配置文件中设置的,可以动态加载。
- ResourceTackerService:处理来自NM的请求,主要包括两种请求:注册和心跳。其中,注册是NodeManager启动S时发生的行为,请求包中包含节点ID,可用的资源上限等信息,而心跳是周期性行为,包含各个Container运行状态,运行的Application列表、节点健康状况(可通过一个脚本设置),而ResourceTrackerService则为NM返回待释放的Container列表、Application列表等。
- AM管理:
- AMLivelinessMonitor:监控AM是否alive,如果一个ApplicationMaster在一定时间(默认为10min)内未汇报心跳信息,则认为它dead,它上面所有正在运行的Container将被认为死亡,AM本身会被重新分配到另外一个节点上(用户可指定每个ApplicationMaster的尝试次数,默认是1次)执行。
- ApplicationMasterLauncher:与NodeManager通信,要求它为某个应用程序启动ApplicationMaster。
- ApplicationMasterService:处理来自ApplicationMaster的请求,主要包括两种请求:注册和心跳,其中,注册是ApplicationMaster启动时发生的行为,包括请求包中包含所在节点,RPC端口号和tracking URL等信息,而心跳是周期性 行为,包含请求资源的类型描述、待释放的Container列表等,而AMS则为之返回新分配的Container、失败的Container等信息。
- TBD...
Spark on YARN
- Spark on YARN模式的优点:与其他计算框架共享集群资源(eg:Spark框架与MapReduce框架同时运行,如果不用Yarn进行资源分配,MapReduce分到的内存资源会很少,效率低下);资源按需分配,进而提高集群资源利用率等。
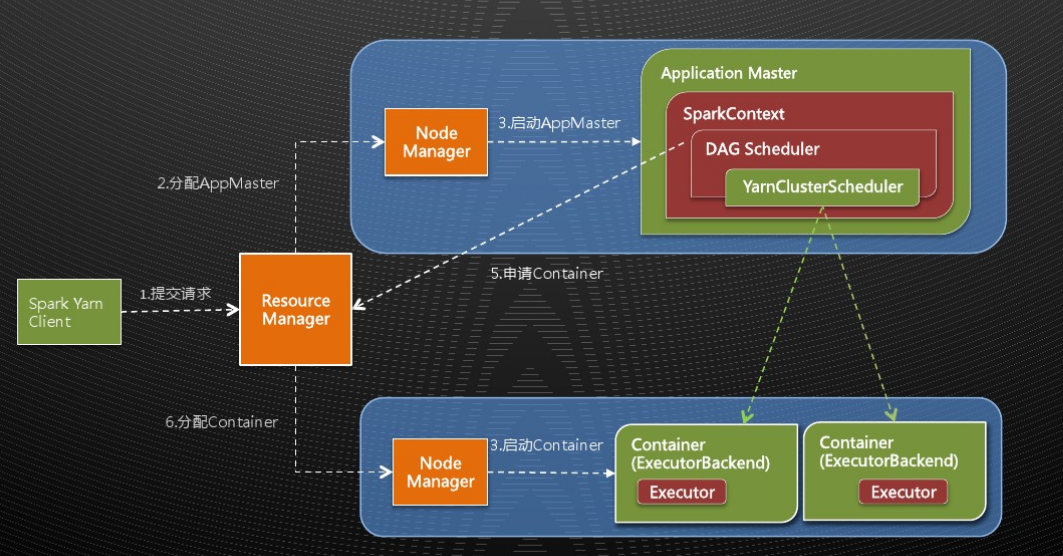
Yarn中的App Master可以理解为Spark中Standalone模式中的driver。
Container中运行着Executor,在Executor中以多线程并行的方式运行Task。工作流程大体与MRv2相同。
Usage
- official doc.
- spark on yarn包含两种模式:
- cluster mode:在Application master内运行spark driver,也就是在任务提交之后client就go away 了。
- client:在client内运行driver,那么application master就只是从yarn申请资源。
- 运行实例
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
--queue thequeue \
lib/spark-examples*.jar \
10上述例子会 start a yarn client program which starts the default Application Master. 该client会周期地从Application Master拉取状态更新信息显示到console,并在程序结束运行的时候立即退出。
- 为了使spark runtime jars对yarn端可用,需要指定 spark.yarn.archive or spark.yarn.jars。如果两者都未指定,则spark会在$SPARK_HOME/jars 下create a zip file,然后upload it to the distributed cache.
- For debug: yarn logs -applicationId <app ID> 注意此功能首先要enable日志聚合。 同时可以配置log4j(从spark默认层面 or app层面)。
FYI
<YARN><MRv2><Spark on YARN>的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- Problem F. Grab The Tree HDU - 6324
题意:给出一棵n个节点的树,每个节点有一个权值,Q和T玩游戏,Q先选一些不相邻的节点,T选剩下的节点,每个人的分数是所选节点的权值的异或和,权值大的胜出,问胜出的是谁. 题解: 话说,这题后面的边跟解 ...
- Ugly Number II leetcode java
问题描述: Write a program to find the n-th ugly number. Ugly numbers are positive numbers whose prime fa ...
- 根据id获取某一类的最大最小值
->selectRaw('max(marking_price) as maxPrice, min(marking_price) as minPrice, product_id') ->gr ...
- BZOJ 1833 数字计数 数位DP
题目链接 做的第一道数位DP题,听说是最基础的模板题,但还是花了好长时间才写出来..... 想深入了解下数位DP的请点这里 先设dp数组dp[i][j][k]表示数位是i,以j开头的数k出现的次数 有 ...
- position属性的总结
static 默认.位置设置为 static 的元素,它始终会处于页面流给予的位置(static 元素会忽略任何 top.bottom.left 或 right 声明). relative 位置被设置 ...
- 前端VUE框架
一.什么是VUE? 它是一个构建用户界面的JAVASCRIPt框架 vue不关心你页面上的是什么标签,它操作的是变量或属性 为什么要使用VUE? 在前后端分离的时候,后端只返回json数据,再没有 ...
- linux平台的oracle11201借用expdp定时备份数据库
备份脚本如下: #!/bin/bashexport ORACLE_BASE=/data/oracle export ORACLE_HOME=$ORACLE_BASE/product/11.2.0/db ...
- 重写nyoj2——括号匹配
#include "bits/stdc++.h" using namespace std; int comp(char s1,char s2){ ; ; } int main() ...
- Git的各种状态
考:http://blog.csdn.net/wirelessqa/article/details/19548057 按照文件的存放位置分: 在你自建的Git本地仓库中,有三个区域:本地目录.暂存区. ...
- #pragma 处理警告 clang diagnostic 的使用
首先#pragma在本质上是声明,常用的功能就是注释,尤其是给Code分段注释:而且它还有另一个强大的功能是处理编译器警告,但却没有上一个功能用的那么多. clang diagnostic 是#pra ...