GoldenGate实时投递数据到大数据平台(5) - Kafka
Oracle GoldenGate是Oracle公司的实时数据复制软件,支持关系型数据库和多种大数据平台。从GoldenGate 12.2开始,GoldenGate支持直接投递数据到Kafka等平台,而不用通过Java二次开发。在数据复制过程中,GoldenGate充当Kafka Producer的角色,从关系 型数据库解析增量数据,再实时往Kafka平台写入。当前最新的GoldenGate版本是12.3.1.1.1。
从下图可以看出,GoldenGate不仅支持Kafka投递,也支持其它大数据平台的投递。
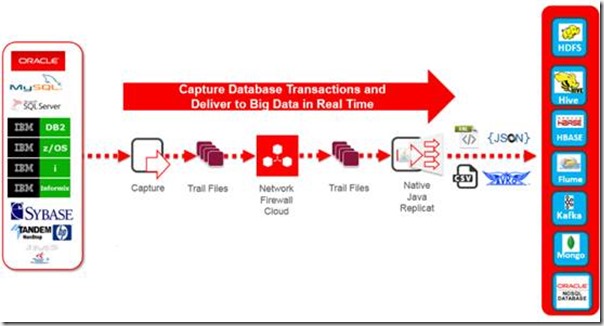
本文主要讲述如何将增量数据投递到Kafka平台。
环境准备
介质准备
GoldenGate介质下载
http://www.oracle.com/technetwork/middleware/goldengate/downloads/index.html
kafka的介质可以从kafka,apache.org官网下载。
软件安装
基于 GoldenGate的复制链路中,一般分为源端和目标端,在GoldenGate for kafka场景中,源端一般是关系型数据库,目标端包括GoldenGate for kafka的节点,以及kafka集群。
Kafka的运行需要先安装Zookeeper软件。zookeeper和Kafka的安装步骤可在网络上搜索,不在此赘述。
本文重点讲解GoldenGate for Kafka的功能,GoldenGate for DB的安装配置在此略过。目标端GoldenGate for big data 的安装需要有JDK环境,要求至少1.7及以上版本。安装完JDK之后,需要指定相应的JAVA_HOME环境变量,并将$JAVA_HOME/bin添加到PATH环境变量。
安装GoldenGate的节点要求能访问kafka集群,因此,安装GoldenGate的节点要有kafka lib,并在后面的kafka.props文件中设置对应的路径。
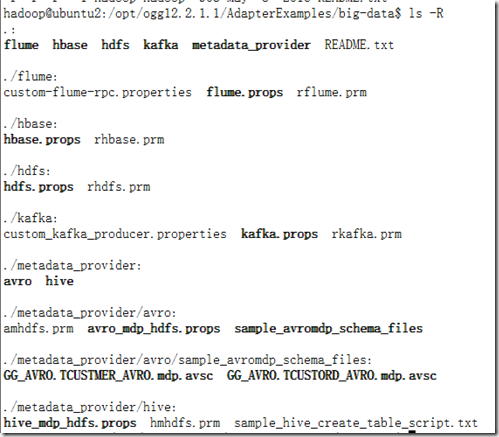
GoldenGate的安装介质是一个ZIP压缩包,解压之后,再继续解压对应的tar即安装完成。安装之后的目录下有示例可供参考:
GoldenGate for kafka配置
GoldenGate投递进程参数
|
REPLICAT myka -- add replicat myka, exttrail ./dirdat/ea TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 10000 MAP gg_src.*, TARGET gg_src.*; |
Kafka相关的属性
hadoop@ubuntu2:/opt/GoldenGate12.2.1.1/dirprm$ more kafka.props
|
gg.handlerlist = kafkahandler gg.handler.kafkahandler.type = kafka gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties gg.handler.kafkahandler.TopicName =mykaf4 gg.handler.kafkahandler.format =avro_op gg.handler.kafkahandler.SchemaTopicName=mySchemaTopic gg.handler.kafkahandler.BlockingSend =false gg.handler.kafkahandler.includeTokens=false gg.handler.kafkahandler.mode =tx goldengate.userexit.timestamp=utc goldengate.userexit.writers=javawriter javawriter.stats.display=TRUE javawriter.stats.full=TRUE gg.log=log4j gg.log.level=INFO gg.report.time=30sec gg.classpath=dirprm/:/opt/kafka/libs/*: javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar hadoop@ubuntu2:/opt/GoldenGate12.2.1.1/dirprm$ more custom_kafka_producer.properties bootstrap.servers=localhost:9092 acks=1 compression.type=gzip reconnect.backoff.ms=1000 value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer # 100KB per partition batch.size=102400 linger.ms=10000 |
测试
确保zookeeper, kafka相关进程是正常运行的。
启动GoldenGate投递进程
GGSCI (ubuntu2) 12> start myka
Sending START request to MANAGER ...
REPLICAT MYKA starting
查看状态
GGSCI (ubuntu2) 21> info myka
REPLICAT MYKA Last Started 2017-12-18 12:59 Status RUNNING
Checkpoint Lag 00:00:00 (updated 00:00:01 ago)
Process ID 42206
Log Read Checkpoint File ./dirdat/ea000000038
2016-08-28 21:18:20.980481 RBA 2478
统计增量数据,已经写入3条记录。
GGSCI (ubuntu2) 22> stats myka, total
| Sending STATS request to REPLICAT MYKA ...
Start of Statistics at 2017-12-18 13:05:09. Replicating from GG_SRC.TB_HIVE to gg_src.TB_HIVE: *** Total statistics since 2017-12-18 12:59:05 *** Total inserts 3.00 Total updates 0.00 Total deletes 0.00 Total discards 0.00 Total operations 3.00 End of Statistics. |
查看kafka集群,使用consumer命令行查看
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic mykaf4
输出如下3条记录,除字段数据外,还有其它辅助信息,如源表结构信息、源端commit时间、当前插入时间等,输出的信息可以在kafka.props文件中控制。
| GG_SRC.TB_HIVEI42016-08-28 12:43:21.97963642017-12-18T12:59:05.368000(00000000380000001916ID1cd&2016-02-08:00:00:00:2016-12-11:11:00:02.000000000 GG_SRC.TB_HIVEI42016-08-28 12:47:24.98154442017-12-18T12:59:05.462000(00000000380000002103IDcd22&2016-02-08:00:00:00:2016-12-11:11:00:02.000000000 GG_SRC.TB_HIVEI42016-08-28 13:18:20.98048142017-12-18T12:59:05.462001(00000000380000002292IDcd22&2016-02-08:00:00:00:2016-12-11:11:00:02.000000000 |
调整输出的格式为XML,修改kafka.props文件,重新执行刚才的投递进程。
gg.handler.kafkahandler.format =xml
GGSCI>stop myka
GGSCI>alter myka, extrba 0
GGSCI>start myka, NOFILTERDUPTRANSACTIONS
使用NOFILTERDUPTRANSACTIONS的目的是禁止OGG跳过已经处理过的事务。
再查看kafka-consumer的输出结果:
可以看到,数据的格式已经变成xml,而且源端每个操作的详细信息都已经记录。
|
<operation table='GG_SRC.TB_HIVE' type='I' ts='2016-08-28 12:43:21.979636' current_ts='2017-12-18T16:49:00.995000' pos='00000000380000001916' numCols='4'> <col name='ID' index='0'> <before missing='true'/> <after><![CDATA[1]]></after> </col> <col name='NAME' index='1'> <before missing='true'/> <after><![CDATA[cd]]></after> </col> <col name='BIRTH_DT' index='2'> <before missing='true'/> <after><![CDATA[2016-02-08:00:00:00]]></after> </col> <col name='CR_TM' index='3'> <before missing='true'/> <after><![CDATA[2016-12-11:11:00:02.000000000]]></after> </col> </operation> <operation table='GG_SRC.TB_HIVE' type='I' ts='2016-08-28 12:47:24.981544' current_ts='2017-12-18T16:49:00.996000' pos='00000000380000002103' numCols='4'> <col name='ID' index='0'> <before missing='true'/> <after><![CDATA[2]]></after> </col> <col name='NAME' index='1'> <before missing='true'/> <after><![CDATA[cd22]]></after> </col> <col name='BIRTH_DT' index='2'> <before missing='true'/> <after><![CDATA[2016-02-08:00:00:00]]></after> </col> <col name='CR_TM' index='3'> <before missing='true'/> <after><![CDATA[2016-12-11:11:00:02.000000000]]></after> </col> </operation> <operation table='GG_SRC.TB_HIVE' type='I' ts='2016-08-28 13:18:20.980481' current_ts='2017-12-18T16:49:00.996001' pos='00000000380000002292' numCols='4'> <col name='ID' index='0'> <before missing='true'/> <after><![CDATA[3]]></after> </col> <col name='NAME' index='1'> <before missing='true'/> <after><![CDATA[cd22]]></after> </col> <col name='BIRTH_DT' index='2'> <before missing='true'/> <after><![CDATA[2016-02-08:00:00:00]]></after> </col> <col name='CR_TM' index='3'> <before missing='true'/> <after><![CDATA[2016-12-11:11:00:02.000000000]]></after> </col> </operation> |
最后,再修改输出格式为json。
gg.handler.kafkahandler.format =json
GGSCI>stop myka
GGSCI>alter myka, extrba 0
GGSCI>start myka, NOFILTERDUPTRANSACTIONS
检查kafka的输出结果:
|
{"table":"GG_SRC.TB_HIVE","op_type":"I","op_ts":"2016-08-28 12:43:21.979636","current_ts":"2017-12-18T16:46:23.860000","pos":"00000000380000001916","after":{"ID":"1","NAME":"cd","BIRTH_DT":"2016-02-08:00:00:00","CR_TM":"2016-12-11:11:00:02.000000000"}} {"table":"GG_SRC.TB_HIVE","op_type":"I","op_ts":"2016-08-28 12:47:24.981544","current_ts":"2017-12-18T16:46:23.914000","pos":"00000000380000002103","after":{"ID":"2","NAME":"cd22","BIRTH_DT":"2016-02-08:00:00:00","CR_TM":"2016-12-11:11:00:02.000000000"}} {"table":"GG_SRC.TB_HIVE","op_type":"I","op_ts":"2016-08-28 13:18:20.980481","current_ts":"2017-12-18T16:46:23.914001","pos":"00000000380000002292","after":{"ID":"3","NAME":"cd22","BIRTH_DT":"2016-02-08:00:00:00","CR_TM":"2016-12-11:11:00:02.000000000"}} |
可以看到,kafka上已经是JSON格式的数据,而且包含了相关的时间戳和其它辅助信息。
至此,测试完成。
最后,如果有必要,也可以使用GoldenGate针对现有存量数据的初始化,即将关系型数据库的现有数据使用GoldenGate投递到Kafka平台,从而省去使用java程序初始化的工作。
GoldenGate实时投递数据到大数据平台(5) - Kafka的更多相关文章
- GoldenGate实时投递数据到大数据平台(2)- Cassandra
简介 GoldenGate是一款可以实时投递数据到大数据平台的软件,针对apache cassandra,经过简单配置,即可实现从关系型数据将增量数据实时投递到Cassandra,以下介绍配置过程. ...
- GoldenGate实时投递数据到大数据平台(3)- Apache Flume
Apache Flume Flume NG是一个分布式.可靠.可用的系统,它能够将不同数据源的海量日志数据进行高效收集.聚合,最后存储到一个中心化数据存储系统中,方便进行数据分析.事实上flume也可 ...
- 大数据学习---大数据的学习【all】
大数据介绍 什么是大数据以及有什么特点 大数据:是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合. 大数据是一种方法论:“一切都被记录,一切都被数字化,从数据中寻找需求,寻找知 ...
- 转 开启“大数据”时代--大数据挑战与NoSQL数据库技术 iteye
一直觉得“大数据”这个名词离我很近,却又很遥远.最近不管是微博上,还是各种技术博客.论坛,碎碎念大数据概念的不胜枚举. 在我的理解里,从概念理解上来讲,大数据的目的在于更好的数据分析,否则如此大数据的 ...
- GoldenGate实时投递数据到大数据平台(6)– HDFS
GoldenGate可以实时将RDBMS的数据投递到HDFS中,在前面的文章中,已经配置过投递到kafka, mongodb等数据平台,本文通过OGG for bigdata的介质中自带的示例演示实时 ...
- GoldenGate实时投递数据到大数据平台(7)– Apache Hbase
Apache Hbase安装及运行 安装hbase1.4,确保在这之前hadoop是正常运行的.设置相应的环境变量, export HADOOP_HOME=/u01/hadoop export HBA ...
- GoldenGate实时投递数据到大数据平台(4)- ElasticSearch 2.x
ES 2.x ES 2.x安装 下载elasticSearch 2.4.5, https://www.elastic.co/downloads/elasticsearch 解压下载后的压缩包,启动ES ...
- GoldenGate实时投递数据到大数据平台(1)-MongoDB
mongodb安装 安装 linux下可使用apt-get install mongodb-server 或 yum install mongodb-server 进行安装. 也可以在windows上 ...
- [转载] 使用 Twitter Storm 处理实时的大数据
转载自http://www.ibm.com/developerworks/cn/opensource/os-twitterstorm/ 流式处理大数据简介 Storm 是一个开源的.大数据处理系统,与 ...
随机推荐
- asp.net中Request请求参数的自动封装
这两天在测一个小Demo的时候发现一个很蛋疼的问题----请求参数的获取和封装,例: 方便测试用所以这里是一个很简单的表单. <!DOCTYPE html> <html xmlns= ...
- visual tudio 2017--发布
- golang 中创建daemon的方法
https://github.com/takama/daemon https://github.com/immortal/immortal/blob/master/fork.go ...
- 构造器初始化(static)
package demo; /* * 在类 的内部,变量定义的先后顺序决定了初始化的顺序.即使变量定义散布于方法定义之间, * 它们仍旧会在任何方法(包括构造器)被调用之前得到初始化. */ publ ...
- 【UML】-NO.43.EBook.5.UML.1.003-【UML 大战需求分析】- 状态机图(State Machine Diagram)
1.0.0 Summary Tittle:[UML]-NO.43.EBook.1.UML.1.003-[UML 大战需求分析]- 状态机图(State Machine Diagram) Style:D ...
- JS快速入门
字符串 模板字符串 需要特别注意的是,字符串是不可变的,如果对字符串的某个索引赋值,不会有任何错误,但是,也没有任何效果: var s = 'Test'; s[0] = 'X'; alert(s); ...
- VirtualBox 在Win10上的蓝屏问题
今天也是第一次使用VirtualBox ,因为比VM更轻量,当然主要还是版权,结果装完虚拟机后,每次打开虚拟机就蓝屏,系统报错. 这是出现在WIN10上的问题啊. 解决办法: 找到Control Pa ...
- 配置opensips经验总结
主要参考https://www.cnblogs.com/Forever-Kenlen-Ja/p/7741776.html (ubuntu),还有https://blog.csdn.net/sunyun ...
- GO language for windows
我记得我们已经下载完成了windows 下Go 的安装包 go1.9.windows-amd64.msi下面接着说吧 GO 在Windows 上也是按照linux 惯例来编程的,所以,你还需要一个wi ...
- EntityFrameworkCore概览
.NET Core 中 EntityFrameworkCore的支持库主要有: Script-migration 级联删除 protected override void OnConfiguring( ...