Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐
MapReduce分析明星微博数据
自定义输入格式,将明星微博数据排序后按粉丝数 关注数 微博数 分别输出到不同文件中。

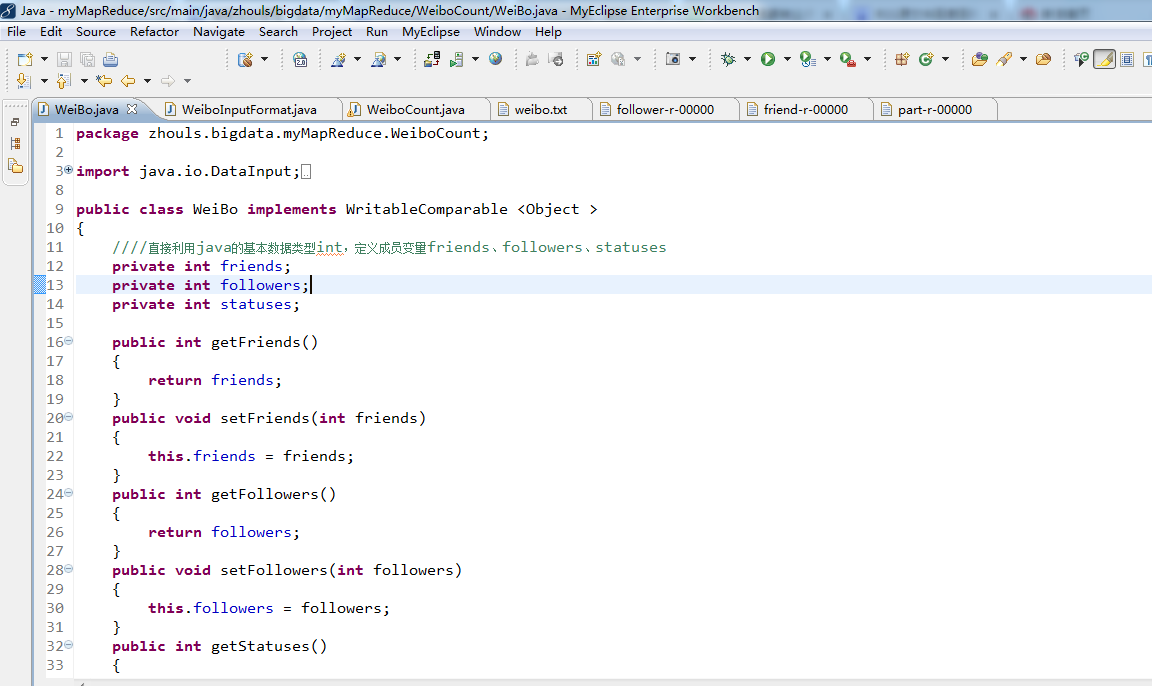



代码
package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* 学习成绩读写类
* 数据格式参考:19020090017 小讲 90 99 100 89 95
* @author Bertron
* 需要自定义一个 ScoreWritable 类实现 WritableComparable 接口,将学生各门成绩封装起来。
*/
public class ScoreWritable implements WritableComparable< Object > {//其实这里,跟TVPlayData一样的
// 注意: Hadoop通过Writable接口实现的序列化机制,不过没有提供比较功能,所以和java中的Comparable接口合并,提供一个接口WritableComparable。(自定义比较)
// Writable接口提供两个方法(write和readFields)。 private float Chinese;
private float Math;
private float English;
private float Physics;
private float Chemistry; // 问:这里我们自己编程时,是一定要创建一个带有参的构造方法,为什么还要显式的写出来一个带无参的构造方法呢?
// 答:构造器其实就是构造对象实例的方法,无参数的构造方法是默认的,但是如果你创造了一个带有参数的构造方法,那么无参的构造方法必须显式的写出来,否则会编译失败。 public ScoreWritable(){}//java里的无参构造函数,是用来在创建对象时初始化对象
//在hadoop的每个自定义类型代码里,好比,现在的ScoreWritable,都必须要写无参构造函数。 //问:为什么我们在编程的时候,需要创建一个带有参的构造方法?
//答:就是能让赋值更灵活。构造一般就是初始化数值,你不想别人用你这个类的时候每次实例化都能用另一个构造动态初始化一些信息么(当然没有需要额外赋值就用默认的)。 public ScoreWritable(float Chinese,float Math,float English,float Physics,float Chemistry){//java里的有参构造函数,是用来在创建对象时初始化对象
this.Chinese = Chinese;
this.Math = Math;
this.English = English;
this.Physics = Physics;
this.Chemistry = Chemistry;
} //问:其实set和get方法,这两个方法只是类中的setxxx和getxxx方法的总称,
// 那么,为什么在编程时,有set和set***两个,只有get***一个呢? public void set(float Chinese,float Math,float English,float Physics,float Chemistry){
this.Chinese = Chinese;//即float Chinese赋值给private float Chinese;
this.Math = Math;
this.English = English;
this.Physics = Physics;
this.Chemistry = Chemistry;
}
// public float get(float Chinese,float Math,float English,float Physics,float Chemistry){因为这是错误的,所以对于set可以分开,get只能是get***
// return Chinese;
// return Math;
// return English;
// return Physics;
// return Chemistry;
// } public float getChinese() {//拿值,得返回,所以需有返回类型float
return Chinese;
}
public void setChinese(float Chinese){//设值,不需,所以空返回类型
this.Chinese = Chinese;
}
public float getMath() {//拿值
return Math;
}
public void setMath(float Math){//设值
this.Math = Math;
}
public float getEnglish() {//拿值
return English;
}
public void setEnglish(float English){//设值
this.English = English;
}
public float getPhysics() {//拿值
return Physics;
}
public void setPhysics(float Physics){//设值
this.Physics = Physics;
}
public float getChemistry() {//拿值
return Chemistry;
}
public void setChemistry(float Chemistry) {//拿值
this.Chemistry = Chemistry;
} // 实现WritableComparable的readFields()方法
// 对象不能传输的,需要转化成字节流!
// 将对象转换为字节流并写入到输出流out中是序列化,write 的过程(最好记!!!)
// 从输入流in中读取字节流反序列化为对象 是反序列化,readFields的过程(最好记!!!)
public void readFields(DataInput in) throws IOException {//拿代码来说的话,对象就是比如Chinese、Math。。。。
Chinese = in.readFloat();//因为,我们这里的对象是float类型,所以是readFloat()
Math = in.readFloat();
English = in.readFloat();//注意:反序列化里,需要生成对象对吧,所以,是用到的是get那边对象
Physics = in.readFloat();
Chemistry = in.readFloat();
// in.readByte()
// in.readChar()
// in.readDouble()
// in.readLine()
// in.readFloat()
// in.readLong()
// in.readShort()
} // 实现WritableComparable的write()方法,以便该数据能被序列化后完成网络传输或文件输出
// 将对象转换为字节流并写入到输出流out中是序列化,write 的过程(最好记!!!)
// 从输入流in中读取字节流反序列化为对象 是反序列化,readFields的过程(最好记!!!)
public void write(DataOutput out) throws IOException {//拿代码来说的话,对象就是比如Chinese、Math。。。。
out.writeFloat(Chinese);//因为,我们这里的对象是float类型,所以是writeFloat()
out.writeFloat(Math);
out.writeFloat(English);//注意:序列化里,需要对象对吧,所以,用到的是set那边的对象
out.writeFloat(Physics);
out.writeFloat(Chemistry);
// out.writeByte()
// out.writeChar()
// out.writeDouble()
// out.writeFloat()
// out.writeLong()
// out.writeShort()
// out.writeUTF()
} public int compareTo(Object o) {//java里的比较,Java String.compareTo()
return 0;
} // Hadoop中定义了两个序列化相关的接口:Writable 接口和 Comparable 接口,这两个接口可以合并成一个接口 WritableComparable。
// Writable 接口中定义了两个方法,分别为write(DataOutput out)和readFields(DataInput in)
// 所有实现了Comparable接口的对象都可以和自身相同类型的对象比较大小 // Hadoop中定义了两个序列化相关的接口:Writable 接口和 Comparable 接口,这两个接口可以合并成一个接口 WritableComparable。
// Writable 接口中定义了两个方法,分别为write(DataOutput out)和readFields(DataInput in)
// 所有实现了Comparable接口的对象都可以和自身相同类型的对象比较大小 // 源码是
// package java.lang;
// import java.util.*;
// public interface Comparable {
// /**
// * 将this对象和对象o进行比较,约定:返回负数为小于,零为大于,整数为大于
// */
// public int compareTo(T o);
// } }
package zhouls.bigdata.myMapReduce.WeiboCount; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.LineReader; //其实这个程序,就是在实现InputFormat接口,TVPlayInputFormat是InputFormat接口的实现类
//比如 WeiboInputFormat extends FileInputFormat implements InputFormat。 //问:自定义输入格式 WeiboInputFormat 类,首先继承 FileInputFormat,然后分别重写 isSplitable() 方法和 createRecordReader() 方法。 public class WeiboInputFormat extends FileInputFormat<Text,WeiBo>{ // 线路是: boolean isSplitable() -> RecordReader<Text,WeiBo> createRecordReader() -> WeiboRecordReader extends RecordReader<Text, WeiBo > @Override
protected boolean isSplitable(JobContext context, Path filename) {//这是InputFormat的isSplitable方法
//isSplitable方法就是是否要切分文件,这个方法显示如果是压缩文件就不切分,非压缩文件就切分。
// 如果不允许分割,则isSplitable==false,则将第一个block、文件目录、开始位置为0,长度为整个文件的长度封装到一个InputSplit,加入splits中
// 如果文件长度不为0且支持分割,则isSplitable==true,获取block大小,默认是64MB
return false; //整个文件封装到一个InputSplit
//要么就是return true; //切分64MB大小的一块一块,再封装到InputSplit
} @Override
public RecordReader<Text, WeiBo> createRecordReader(InputSplit arg0,TaskAttemptContext arg1) throws IOException, InterruptedException{
// RecordReader<k1, v1>是返回类型,返回的RecordReader对象的封装
// createRecordReader是方法,在这里是,WeiboInputFormat.createRecordReader。WeiboInputFormat是InputFormat类的实例
// InputSplit input和TaskAttemptContext context是传入参数 // isSplitable(),如果是压缩文件就不切分,整个文件封装到一个InputSplit
// isSplitable(),如果是非压缩文件就切,切分64MB大小的一块一块,再封装到InputSplit //这里默认是系统实现的的RecordReader,按行读取,下面我们自定义这个类WeiboRecordReader。
//类似与Excel、WeiBo、TVPlayData代码写法
return new WeiboRecordReader();//新建一个ScoreRecordReader实例,所有才有了上面RecordReader<Text,ScoreWritable>,所以才如下ScoreRecordReader,写我们自己的
} public class WeiboRecordReader extends RecordReader<Text, WeiBo>{
//LineReader in是1,行号。
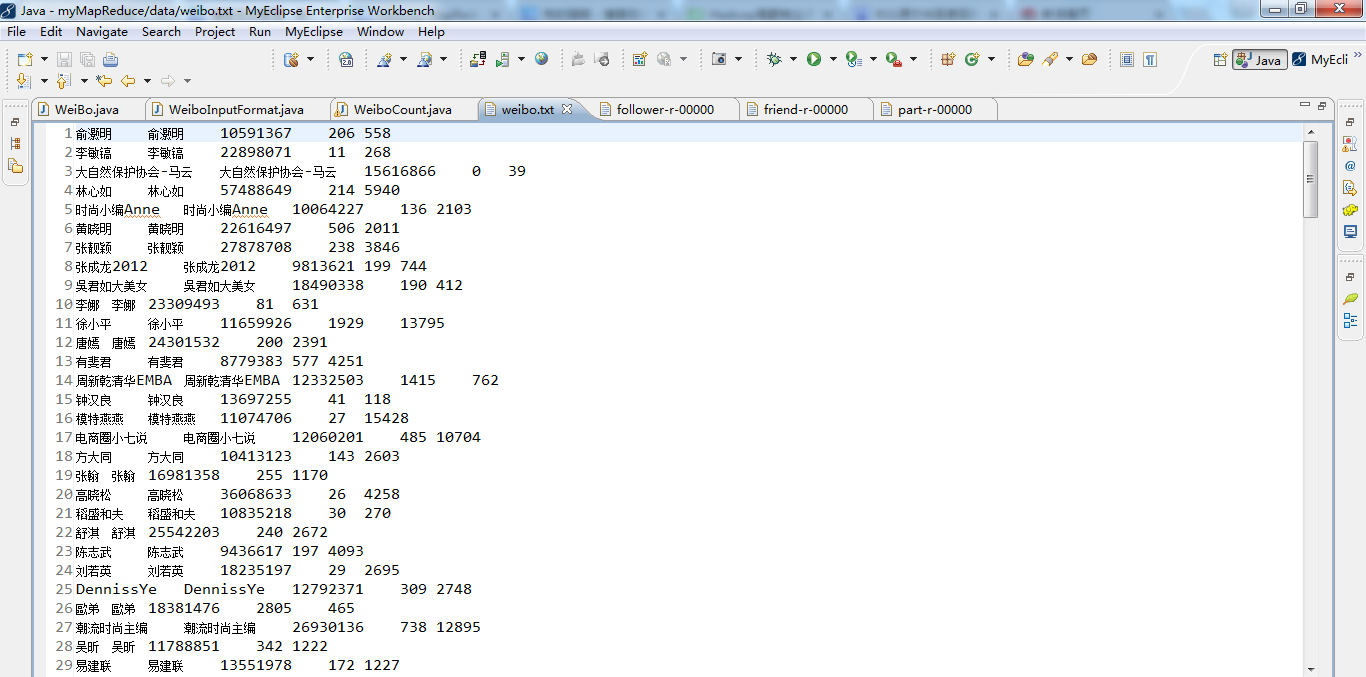
//Text line; 俞灏明 俞灏明 10591367 206 558,每行的相关记录
public LineReader in;//行读取器
public Text line;//每行数据类型
public Text lineKey;//自定义key类型,即k1
public WeiBo lineValue;//自定义value类型,即v1 @Override
public void close() throws IOException {//关闭输入流
if(in !=null){
in.close();
}
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {//获取当前的key,即CurrentKey
return lineKey;//返回类型是Text,即Text lineKey
}
@Override
public WeiBo getCurrentValue() throws IOException,InterruptedException {//获取当前的Value,即CurrentValue
return lineValue;//返回类型是WeiBo,即WeiBo lineValue
}
@Override
public float getProgress() throws IOException, InterruptedException {//获取进程,即Progress
return 0;//返回类型是float,即float 0
} @Override
public void initialize(InputSplit input, TaskAttemptContext context)throws IOException, InterruptedException{//初始化,都是模板
FileSplit split=(FileSplit)input;//获取split
Configuration job=context.getConfiguration();
Path file=split.getPath();//得到文件路径
FileSystem fs=file.getFileSystem(job); FSDataInputStream filein=fs.open(file);//打开文件
in=new LineReader(filein,job); //输入流in
line=new Text();//每行数据类型
lineKey=new Text();//自定义key类型,即k1。//新建一个Text实例作为自定义格式输入的key
lineValue = new WeiBo();//自定义value类型,即v1。//新建一个TVPlayData实例作为自定义格式输入的value
} //此方法读取每行数据,完成自定义的key和value
@Override
public boolean nextKeyValue() throws IOException, InterruptedException{//这里面,才是篡改的重点
int linesize=in.readLine(line); //line是每行数据,我们这里用到的是in.readLine(str)这个构造函数,默认读完读到文件末尾。其实这里有三种。 // 是SplitLineReader.readLine -> SplitLineReader extends LineReader -> org.apache.hadoop.util.LineReader // in.readLine(str)//这个构造方法执行时,会首先将value原来的值清空。默认读完读到文件末尾
// in.readLine(str, maxLineLength)//只读到maxLineLength行
// in.readLine(str, maxLineLength, maxBytesToConsume)//这个构造方法来实现不清空,前面读取的行的值 if(linesize==0) return false; //通过分隔符'\t',将每行的数据解析成数组 pieces
String[] pieces = line.toString().split("\t");
//因为,我们这里是。默认读完读到文件末尾。line是Text类型。pieces是String[],即String数组。 if(pieces.length != 5){
throw new IOException("Invalid record received");
} int a,b,c; try{
a = Integer.parseInt(pieces[2].trim());//粉丝,//将String类型,如pieces[2]转换成,float类型,给a
b = Integer.parseInt(pieces[3].trim());//关注
c = Integer.parseInt(pieces[4].trim());//微博数
}catch(NumberFormatException nfe)
{
throw new IOException("Error parsing floating poing value in record");
} //自定义key和value值
lineKey.set(pieces[0]); //完成自定义key数据
lineValue.set(b, a, c);//完成自定义value数据
// 或者写
// lineValue.set(Integer.parseInt(pieces[2].trim()),Integer.parseInt(pieces[3].trim()),Integer.parseInt(pieces[4].trim())); // pieces[0] pieces[1] pieces[2] ... pieces[4]
// 俞灏明 俞灏明 10591367 206 558
// 李敏镐 李敏镐 22898071 11 268
// 大自然保护协会-马云 大自然保护协会-马云 15616866 0 39
// 林心如 林心如 57488649 214 5940
// 时尚小编Anne 时尚小编Anne 10064227 136 2103
// 黄晓明 黄晓明 22616497 506 2011
// 张靓颖 张靓颖 27878708 238 3846
// 张成龙2012 张成龙2012 9813621 199 744
// 吳君如大美女 吳君如大美女 18490338 190 412
// 李娜 李娜 23309493 81 631
// 徐小平 徐小平 11659926 1929 13795
// 唐嫣 唐嫣 24301532 200 2391
// 有斐君 有斐君 8779383 577 4251 return true;
} }
}
package zhouls.bigdata.myMapReduce.WeiboCount; import java.io.IOException;
import java.util.Arrays;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Set;
import java.util.Map; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class WeiboCount extends Configured implements Tool{
public static class WeiBoMapper extends Mapper<Text, WeiBo, Text, Text>{
@Override
protected void map(Text key, WeiBo value, Context context) throws IOException, InterruptedException{
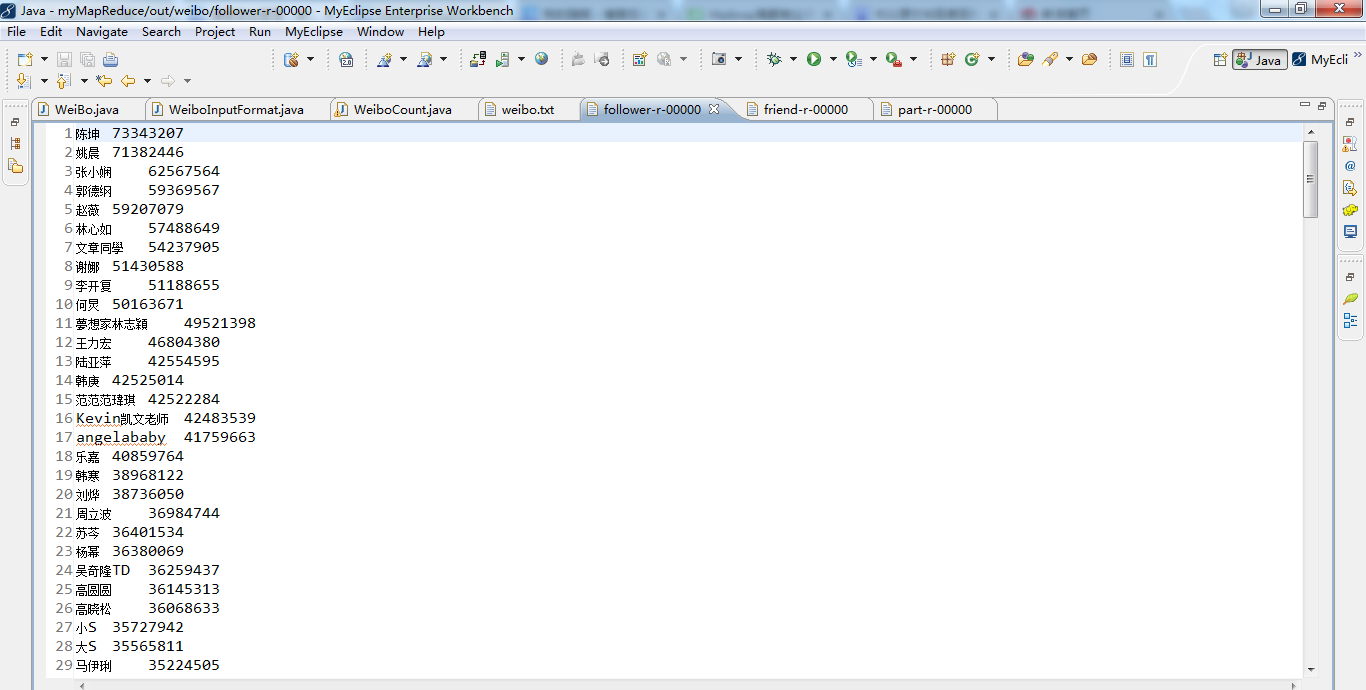
context.write(new Text("follower"),new Text(key.toString() + "\t" + value.getFollowers()));
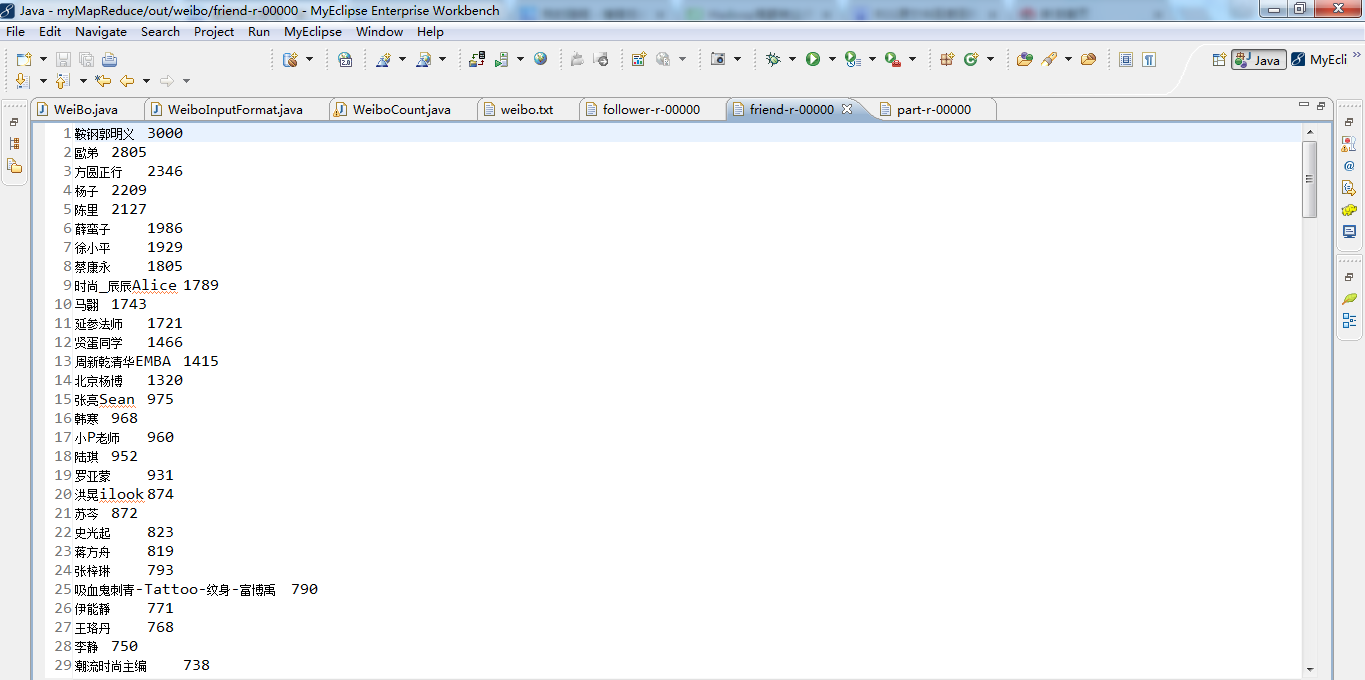
context.write(new Text("friend"),new Text(key.toString() + "\t" + value.getFriends()));
context.write(new Text("statuses"),new Text(key.toString() + "\t" + value.getStatuses()));
}
} public static class WeiBoReducer extends Reducer<Text, Text, Text, IntWritable> {
private MultipleOutputs<Text, IntWritable> mos; protected void setup(Context context) throws IOException,InterruptedException{
mos = new MultipleOutputs<Text, IntWritable>(context);
} private Text text = new Text(); protected void reduce(Text Key, Iterable<Text> Values,Context context) throws IOException, InterruptedException{
int N = context.getConfiguration().getInt("reduceHasMaxLength", Integer.MAX_VALUE);
Map<String,Integer> m = new HashMap<String,Integer>();
for(Text value:Values){//星型for循环,意思是把Values的值传给Text value
//value=名称+(粉丝数 或 关注数 或 微博数)
String[] records = value.toString().split("\t");
m.put(records[0],Integer.parseInt(records[1].toString()));
} //对Map内的数据进行排序
Map.Entry<String, Integer>[] entries = getSortedHashtableByValue(m);
for(int i = 0; i< N && i< entries.length;i++){
if(Key.toString().equals("follower")){
mos.write("follower",entries[i].getKey(), entries[i].getValue());
}else if(Key.toString().equals("friend")){
mos.write("friend", entries[i].getKey(), entries[i].getValue());
}else if(Key.toString().equals("status")){
mos.write("statuses", entries[i].getKey(), entries[i].getValue());
}
}
} protected void cleanup(Context context) throws IOException,InterruptedException {
mos.close();
}
} public int run(String[] args) throws Exception{
Configuration conf = new Configuration();// 配置文件对象
Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);// 创建输出路径
if (hdfs.isDirectory(mypath)){
hdfs.delete(mypath, true);
} Job job = new Job(conf, "weibo");// 构造任务
job.setJarByClass(WeiboCount.class);// 主类 job.setMapperClass(WeiBoMapper.class);// Mapper
job.setMapOutputKeyClass(Text.class);// Mapper key输出类型
job.setMapOutputValueClass(Text.class);// Mapper value输出类型 job.setReducerClass(WeiBoReducer.class);// Reducer
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径
job.setInputFormatClass(WeiboInputFormat.class);// 自定义输入格式
//自定义文件输出类别
MultipleOutputs.addNamedOutput(job, "follower", TextOutputFormat.class,Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, "friend", TextOutputFormat.class,Text.class, IntWritable.class);
MultipleOutputs.addNamedOutput(job, "status", TextOutputFormat.class,Text.class, IntWritable.class);
job.waitForCompletion(true);
return 0;
} //对Map内的数据进行排序(只适合小数据量)
public static Map.Entry[] getSortedHashtableByValue(Map h){
Set set = h.entrySet();
Map.Entry[] entries = (Map.Entry[]) set.toArray(new Map.Entry[set.size()]);
Arrays.sort(entries, new Comparator(){
public int compare(Object arg0, Object arg1){
Long key1 = Long.valueOf(((Map.Entry) arg0).getValue().toString());
Long key2 = Long.valueOf(((Map.Entry) arg1).getValue().toString());
return key2.compareTo(key1);
} });
return entries;
} public static void main(String[] args) throws Exception{
// String[] args0 = { "hdfs://HadoopMaster:9000/weibo/weibo.txt",
// "hdfs://HadoopMaster:9000/out/weibo/" }; String[] args0 = { "./data/weibo/weibo.txt",
"./out/weibo/" }; int ec = ToolRunner.run(new Configuration(), new WeiboCount(), args0);
System.exit(ec);
}
}
Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)的更多相关文章
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之Crime数据分析(二十五)(未完)
不多说,直接上代码. 一共12列,我们只需提取有用的列:第二列(犯罪类型).第四列(一周的哪一天).第五列(具体时间)和第七列(犯罪场所). 思路分析 基于项目的需求,我们通过以下几步完成: 1.首先 ...
- Hadoop MapReduce编程 API入门系列之计数器(二十七)
不多说,直接上代码. MapReduce 计数器是什么? 计数器是用来记录job的执行进度和状态的.它的作用可以理解为日志.我们可以在程序的某个位置插入计数器,记录数据或者进度的变化情况. Ma ...
- Hadoop MapReduce编程 API入门系列之FOF(Fund of Fund)(二十三)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.friend; import org.apache.hadoop.io.Text; public cl ...
- Hadoop MapReduce编程 API入门系列之网页流量版本1(二十二)
不多说,直接上代码. 对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件. 代码 package zhouls.bigdata.myMapReduce.flowsum; import ...
随机推荐
- OpenCV:OpenCV目标检测Adaboost+haar源代码分析
使用OpenCV作图像检测, Adaboost+haar决策过程,其中一部分源代码如下: 函数调用堆栈的底层为: 1.使用有序决策桩进行预测 template<class FEval> i ...
- 备份-泛函编程(23)-泛函数据类型-Monad
泛函编程(23)-泛函数据类型-Monad http://www.cnblogs.com/tiger-xc/p/4461807.html https://blog.csdn.net/samsai100 ...
- python 生成测试报告并发送邮件
前言: 使用unittest编写自动化测试脚本,执行脚本后可以很方便看到测试用例的执行情况. 但如果想向领导汇报工作,就需要提供更直观的测试报告. 思路: 使用unittest编写测试用例,HTMLT ...
- vue路由中的 Meta
在项目中肯定有这样的需求,那就是在某个页面的时候,顶部展示 现在当前的页面路径,如下图: 这个在vue中其实很好实现. 首先出现这个肯定是相对应不同的页面,也就是说对应不同的路由,我们在定义路由的时候 ...
- 【转载】InputStreamReader和OutputStreamWriter 的区别和用法
一.InputStreamReader 用于将一个字节流中的字节解码成字符 , 用法如下: @Test public void Test19() throws Exception { InputStr ...
- TCP/IP数据包结构详解
一般来说,网络编程我们只需要调用一些封装好的函数或者组件就能完成大部分的工作,但是一些特殊的情况下,就需要深入的理解网络数据包的结构,以及协议分析.如:网络监控,故障排查等…… IP包是不安全的,但是 ...
- 【JavaScript】不使用正则表达式和字符串的方式来解析浏览器的URl地址信息
1.比如我们要获取的网站URl地址是:https://music.163.com/#/playlist?id=2384581760 一般我们能够想到的方式是直接使用正则表达式获取使用字符串直接解析的方 ...
- Idea 类注释和方法注释
类注释 先打开Settings > Editor > File and Code Templates Includes Includes File Header 再随机新建个类就有类注释 ...
- Java核心技术读书笔记01
Volume I Chapter 1 An Introduction to Java • 1.1 Java as a Programming Platform• 1.2 The Java ‘Whi ...
- 爬虫写法进阶:普通函数--->函数类--->Scrapy框架
本文转载自以下网站: 从 Class 类到 Scrapy https://www.makcyun.top/web_scraping_withpython12.html 普通函数爬虫: https:// ...