【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
好早的时候就打算写这篇文章,可是还是參加阿里大数据竞赛的第一季三月份的时候实验就完毕了。硬生生是拖到了十一假期。自己也是醉了。。。
找工作不是非常顺利,希望写点东西回想一下知识。然后再攒点人品吧,仅仅能如此了。
一、问题背景
二、基于用户的协同过滤算法介绍
三、数据结构和实验过程设计
四、代码
一、问题背景
首先介绍一下问题的背景。如今我有四个月的用户、品牌数据<user,brand>。即用户在这四个月中的某一天购买了某个品牌(当然为了简化算法模型。将购买时间省去,后面再说)。
即如今有这四个月的数据。怎样为用户推荐他们感兴趣的产品下个月购买?当然解决问题的算法和模型有非常多非常多种。如今就解释一下协同过滤算法。
二、基于用户的协同过滤算法介绍(User Collaborative Filter)
基于邻域的算法是推荐系统中最主要的算法,该算法不仅在学术界得到了深入的研究。并且在工业界也有广泛的应用。
基于邻域的算法分为两大类,一类是基于用户的协同过滤算法。还有一类是基于物品的协同过滤算法。
这里仅仅介绍一种基于用户的协同过滤算法。
在一个在线个性化推荐系统中,当一个用户A须要个性化推荐时,能够先找到和他有相似兴趣的其它用户。然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A。这样的方法称为基于用户的协同过滤算法。
从上面的描写叙述能够看到。基于用户的协同过滤算法主要包含两个步骤:
(1)找到和目标用户相似的用户集合。
(2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
步骤1的关键就是计算两个用户的兴趣相似度。
这里,协同过滤算法主要利用行为的相似度计算兴趣的相似度。给定用户u和用户v,令N(u)表示用户u以前有过正反馈的物品集合(在我们的问题背景之下也就是用户u以前买过的物品集合),令N(v)为用户v以前有过正反馈的物品集合。那么。我们能够通过例如以下的Jaccard公式简单的计算u和v的兴趣相似度:

或者通过余弦相似度计算:

对于下图的用户行为记录:

在该例中,用户A对物品{a,b,c}有过行为,用户B对物品{a,c}有过行为,利用余弦相似度公式计算用户A和用户B的兴趣相似度,以及A和C、D的相似度:


那么,假设两两用户都利用余弦相似度计算相似度。
这样的方法的时间复杂度是O(|U|*|U|),这在用户数非常大的情况下十分耗时。其实。非常多用户相互之间并没有同样的物品产生行为,即非常多时候N(u)和N(v)的交集为0。
那么,一种高效的算法就是首先计算出交集不为0的用户对{u,v}。然后再对这样的情况除以分母|N(u)UN(v)|(或者还有一种根号形式)。
为此。能够首先建立物品到用户的倒查表,对于每一个物品都保存对该物品产生过行为的用户列表。令系数矩阵C[u][v]=|N(u)并N(v)|。那么,如果用户u和用户v同一时候属于倒排表中K个物品相应的用户列表,就有C[u][v]=K。
从而。能够扫描倒查表中每一个物品相应的用户列表,将用户列表中的两两用户相应的C[u][v]加1,终于就能够得到全部用户之间不为0的C[u][v]。
对于上图的用户行为记录建立物品-用户的倒排表:

建立一个4*4的用户相似度矩阵W,对于物品a。将W[A][B]和W[B][A]加1。对于物品b,将W[A][C]和W[C][A]加1,以此类推。
扫描全然部物品后,我们能够得到终于的W矩阵。这里的W是余弦相似度中的分子部分,然后将W除以分母能够得到终于的用户兴趣相似度。
得到用户之间的兴趣相似度后。UserCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品。例如以下的公式度量了UserCF算法中用户u对物品i的感兴趣程度:
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvbGF2b3Jhbmdl/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast" alt="">
S(u,K):包括和用户u兴趣最接近的K个用户。
N(i):对物品i有过行为的用户集合
Wuv:用户u和用户v的兴趣相似度
Rvi:用户v对物品i的兴趣(这里都为1)
说明:i物品是用户u之前没有接触过的。那么用户u对物品i的感性却程度的计算过程能够分为几个步骤:
①找到与用户u近期的K个用户(通过用户相似度矩阵)
②通过K个用户和N(i)(对物品i有过购买的用户集合)的交集得到K个用户中对i感兴趣的若干用户集合v[]。
③将用户u和集合v[]中每个用户v[i]之间的相似度累加的总和即为用户u对于物品i的感兴趣程度。
三、数据结构和实验过程设计
3.1:输入输出
准确率: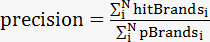
注:
N 为參赛队预測的用户数
pBrandsi为对用户i 预測他(她)会购买的品牌列表个数
hitBrandsi对用户i预測的品牌列表与用户i真实购买的品牌交集的个数
召回率: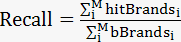
注:
M 为实际产生成交的用户数量
bBrandsi为用户i 真实购买的品牌个数
hitBrandsi预測的品牌列表与用户i真实购买的品牌交集的个数
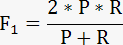
3.2:数据结构设计
map< int,int > userid_id:将userid映射到从0開始的依次递增的数值(id:0~n-1),为兴许映射成矩阵做准备。
map< int,int > id_userid:与userid_id正好相反
map< int , set<int> > user_brands:用户-物品表:用户以及用户相应购买的物品列表
map< int , set<int> > id_brands:将user_brands根据userid_id转换成为id_brands
map< int , set<int> > brand_ids:物品-用户倒排表
set<int> brand_all :全部品牌的集合
map< int , set<int> > user_brand_rec :为用户推荐的品牌集合
3.3:算法过程:
<span style="font-size:14px;">1).读入数据。将数据用user_brands存起来,同一时候建立userid_id,再建立id_brands
2).遍历id_brands得到物品-用户倒排表brand_ids,依据倒排表得到用户的类似矩阵sim_mat
3).为每个用户推荐产品:
3.1).求用户u买过的brand和全部brand的差集得到用户u没有买过的物品集合brand_unused;
3.2).用户u对每个没用过的物品i的兴趣p(u,i):
3.2.1).找到与用户u近期的k个用户
对于每个没用过的物品i:
3.2.2).找出这k个用户中对物品i有过行为的用户v[]√
3.2.3).将用户u和v[j]的兴趣类似度累加
3.3).取前m个最感兴趣的brand推荐给用户;</span>
四、代码
UCF.cc(用户协同过滤核心代码):
#include<iostream>
#include<fstream>
#include<stdio.h>
#include<map>
#include<set>
#include<vector>
#include<cstdlib>
#include<cmath>
#include<cstring>
#include<algorithm> using namespace std; const int MAX = 1000; class UserCF
{
private:
int k , m ; //k: the most k persons interested in the brand i ; m : choose the former m brands which user u are most interested in
map< int,int > userid_id;
map< int,int > id_userid;
map< int,set<int> > user_brands;
map< int,set<int> > id_brands;
map< int,set<int> > brand_ids;
set<int> brand_all;
map< int,set<int> > user_brand_rec;
ifstream fin;
ofstream fout;
double sim_mat[MAX][MAX];
typedef struct sim_idx
{
double sim;
int idx;
bool operator > (const sim_idx &other) const
{
return sim > other.sim;
}
}sim_idx;
typedef struct brand_interest
{
double Int; // Int = interest
int brand;
bool operator > (const brand_interest &other) const
{
return Int > other.Int;
}
}brand_interest; public:
UserCF(int _k , int _m):k(_k),m(_m)
{
fin.open("user_brand_m123.txt");
fout.open("rec_result_by_m123.txt");
if(!fin||!fout)
{
cout<<"can not open the file"<<endl;
exit(1);
} //userid_id , id_userid , user_brands , brand_all
int userid,brandid,i=0;
while(fin>>userid>>brandid)
{
if( user_brands[userid].empty() )
{
userid_id[userid] = i;
id_userid[i] = userid;
i++;
}
user_brands[userid].insert(brandid);
brand_all.insert(brandid);
} //id_brands
map< int,set<int> > :: iterator it = user_brands.begin();
while( it!=user_brands.end() )
{
id_brands[ userid_id[it->first] ] = it->second;
it++;
}
bzero(sim_mat,0);
} void get_sim_mat()
{
get_reverse_table();
map< int,set<int> > :: iterator it = brand_ids.begin();
while(it!=brand_ids.end())
{
vector<int> tmp( it->second.begin(),it->second.end() );
int len = tmp.size();
//for each brand , traverse all two pair users , sim_mat increment
for(int i=0;i<len;i++)
for(int j=i+1;j<len;j++)
{
sim_mat[ tmp[i] ][ tmp[j] ]+=1;
sim_mat[ tmp[j] ][ tmp[i] ]+=1;
}
it++;
} int len = id_userid.size();
for(int i=0;i<len;i++)
for(int j=0;j<len;j++)
{
sim_mat[i][j] /= sqrt( user_brands[ id_userid[i] ].size() * user_brands[ id_userid[j] ].size() );
sim_mat[j][i] = sim_mat[i][j];
}
cout<<endl;
} //brand_ids - brand : userid1,userid2,userid3...
void get_reverse_table()
{
map< int,set<int> > :: iterator it = id_brands.begin();
while( it!=id_brands.end() )
{
set<int> tmp = it->second;
set<int> :: iterator it2 = tmp.begin();
while(it2!=tmp.end())
{
brand_ids[*it2].insert(it->first);
it2++;
}
it++;
}
} set<int> get_rec_brand_set_by_user(int userid)
{
//3.1
set<int> brand_unused;
/* set_difference:find different set between two set
* function : get brand set that userid has never bought before
*/
set_difference(brand_all.begin(),brand_all.end(),user_brands[userid].begin(),user_brands[userid].end(),inserter( brand_unused , brand_unused.begin() ) ); sim_idx simidx;
vector<sim_idx> vec_sim_idx;
int len = userid_id.size();
int id = userid_id[userid];
for(int i=0;i<len;i++)
{
simidx.sim=sim_mat[id][i];
simidx.idx=i;
vec_sim_idx.push_back(simidx);
}
sort( vec_sim_idx.begin(),vec_sim_idx.end(),greater<sim_idx>() ); //order by desc //3.2.1
set<int> rec_ids;
vector<sim_idx> :: iterator it = vec_sim_idx.begin();
for(int i=0;i<k;i++)
{
rec_ids.insert( (*it).idx );
it++;
} set<int> rec_brand;
set<int> :: iterator itt = brand_unused.begin();
vector<brand_interest> vec_bi; //userid's interest level toward brand
brand_interest bi;
while( itt!=brand_unused.end() )
{
//3.2.2
vector<int> newset; // or set<int> newset
set<int> ids = brand_ids[*itt];
set_intersection(rec_ids.begin(),rec_ids.end(),ids.begin(),ids.end(),inserter( newset,newset.begin() ));
if(newset.empty())
{
itt++;
continue;
}
double interest = 0.0;
int len = newset.size();
for(int i=0;i<len;i++)
{
interest += sim_mat[ userid_id[userid] ][ newset[i] ];
}
//3.2.3
bi.brand = *itt;
bi.Int = interest;
vec_bi.push_back(bi);
itt++;
}//while
//sort(vec_bi.begin(),vec_bi.end(),greater<brand_interest>() );//感谢@chenyadong的改动建议。这行代码要进行加入
//3.3
for(int i=0;i<m&&i<vec_bi.size();i++)
{
rec_brand.insert(vec_bi[i].brand);
} return rec_brand; } void recommend()
{
map< int,int > :: iterator it = userid_id.begin();
while( it!=userid_id.end() )
{
user_brand_rec[it->first] = get_rec_brand_set_by_user(it->first);
it++;
}
}//recommend void print()
{
//write recommendation result <user,brand> to file
map< int,set<int> > :: iterator it = user_brand_rec.begin();
while( it!=user_brand_rec.end() )
{
set<int> tmp = it->second;
set<int> :: iterator it2 = tmp.begin();
while(it2!=tmp.end())
{
fout<<it->first<<" "<<*it2<<endl;
it2++;
}
it++;
} }//print ~UserCF()
{
userid_id.clear();
user_brands.clear();
id_brands.clear();
brand_ids.clear();
brand_all.clear();
user_brand_rec.clear();
fin.close();
fout.close();
} }; int main(int argc , char *argv[])
{
if(argc!=3)
{
cout<<"Usage : ./a.out k m"<<endl;
exit(1);
}
int k = atoi(argv[1]) ;
int m = atoi(argv[2]) ; UserCF ucf(k,m);
ucf.get_sim_mat();
ucf.recommend();
#if 1
ucf.print();
#endif
return 0;
}
cal_precision_recall.cc(计算准确率和召回率代码):
#include<iostream>
#include<fstream>
#include<map>
#include<set>
#include<algorithm> using namespace std; int main()
{
ifstream fin , fin1;
fin.open("rec_result_by_m123.txt");
fin1.open("user_brand_m4.txt");
if(!fin||!fin1)
{
cout<<"can not open file"<<endl;
exit(1);
} map< int,set<int> > fore_user_brands; //recommendation result
map< int,set<int> > real_user_brands; //real result int user , brand;
while(fin>>user>>brand)
{
fore_user_brands[user].insert(brand);
}
while(fin1>>user>>brand)
{
real_user_brands[user].insert(brand);
} double precision = 0 , recall = 0;
double fore_total_brand = 0;
double real_total_brand = 0;
double intersection = 0;
double F = 0; map< int,set<int> > :: iterator it = fore_user_brands.begin();
map< int,set<int> > :: iterator itt = real_user_brands.begin();
while(it!=fore_user_brands.end())
{
fore_total_brand += (it->second).size();
it++;
}
while(itt!=real_user_brands.end())
{
real_total_brand += (itt->second).size();
itt++;
} it = fore_user_brands.begin();
while(it!=fore_user_brands.end())
{
set<int> fore , real , newset;
fore = it->second;
real = real_user_brands[it->first];
//set_intersection:get intersection of two sets
set_intersection(fore.begin(),fore.end(),real.begin(),real.end(),inserter(newset,newset.begin()));
intersection += newset.size();
if(newset.size()!=0)
{
set<int> :: iterator itnew = newset.begin();
cout<<"user : "<<it->first<<" brand : ";
while(itnew!=newset.end())
{
cout<<*itnew<<" ";
itnew++;
}
cout<<endl;
}
it++;
} precision = intersection/fore_total_brand;
recall = intersection/real_total_brand;
F = (2*precision*recall)/(precision+recall);
cout<<"fore_total_brand = "<<fore_total_brand<<endl;
cout<<"real_total_brand = "<<real_total_brand<<endl;
cout<<"intersection = "<<intersection<<endl;
cout<<"precision = "<<precision<<endl;
cout<<"recall = "<<recall<<endl;
cout<<"F = "<<F<<endl; return 0;
}
makefile:
target:
g++ UCF.cc
./a.out 5 5
g++ cal_precision_recall.cc
./a.out clean:
rm result.txt a.out
实验结果:
k=5,m=5(k即对某个品牌最感兴趣的前k个人。m即推荐给用户的前m个品牌):


源码以及数据:http://pan.baidu.com/s/1c1VU1K
UCF临时就介绍到这里,当然这个算法还有非常多能够改进的,比方在计算用户相似度的时候能够加上时间上的因素,还有惩处用户u和用户v共同兴趣列表中热门物品对他们相似度的影响等。
參考资料:
1.《推荐系统实战》
Author:忆之独秀
Email:leaguenew@qq.com
转载注明出处:http://blog.csdn.net/lavorange/article/details/22584373
【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)的更多相关文章
- 推荐召回--基于用户的协同过滤UserCF
目录 1. 前言 2. 原理 3. 数据及相似度计算 4. 根据相似度计算结果 5. 相关问题 5.1 如何提炼用户日志数据? 5.2 用户相似度计算很耗时,有什么好的方法? 5.3 有哪些改进措施? ...
- 基于用户的协同过滤电影推荐user-CF python
协同过滤包括基于物品的协同过滤和基于用户的协同过滤,本文基于电影评分数据做基于用户的推荐 主要做三个部分:1.读取数据:2.构建用户与用户的相似度矩阵:3.进行推荐: 查看数据u.data 主要用到前 ...
- Mahout实现基于用户的协同过滤算法
Mahout中对协同过滤算法进行了封装,看一个简单的基于用户的协同过滤算法. 基于用户:通过用户对物品的偏好程度来计算出用户的在喜好上的近邻,从而根据近邻的喜好推测出用户的喜好并推荐. 图片来源 程序 ...
- 基于用户的协同过滤的电影推荐算法(tensorflow)
数据集: https://grouplens.org/datasets/movielens/ ml-latest-small 协同过滤算法理论基础 https://blog.csdn.net/u012 ...
- (数据挖掘-入门-3)基于用户的协同过滤之k近邻
主要内容: 1.k近邻 2.python实现 1.什么是k近邻(KNN) 在入门-1中,简单地实现了基于用户协同过滤的最近邻算法,所谓最近邻,就是找到距离最近或最相似的用户,将他的物品推荐出来. 而这 ...
- 案例:Spark基于用户的协同过滤算法
https://mp.weixin.qq.com/s?__biz=MzA3MDY0NTMxOQ==&mid=2247484291&idx=1&sn=4599b4e31c2190 ...
- 基于用户的协同过滤(UserCF)
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
- 推荐召回--基于物品的协同过滤:ItemCF
目录 1. 前言 2. 原理&计算&改进 3. 总结 1. 前言 说完基于用户的协同过滤后,趁热打铁,我们来说说基于物品的协同过滤:"看了又看","买了又 ...
随机推荐
- Android开发进度07
1,今日:目标:完成记账功能 2,昨天:账单的增删改查方法 3,收获:无 4,问题:SQLite表单出现问题,提交后软件直接退出
- Vue系列(二):发送Ajax、JSONP请求、Vue生命周期及实例属性和方法、自定义指令与过渡
上一篇:Vue系列(一):简介.起步.常用指令.事件和属性.模板.过滤器 一. 发送AJAX请求 1. 简介 vue本身不支持发送AJAX请求,需要使用vue-resource.axios等插件实现 ...
- 2019-03-15 使用Request POST获取中加基金的PDF文件,并下载到本地
import requests import time base_url='http://www.bobbns.com/common-web/cms/content!getContentsInclud ...
- oracle截取某一个字符之前或之后的值;substr();instr()
函数介绍: 截取的函数: substr(?,?); substr(?,?,?); 获取目标字符出现的位置: instr(? , ? , ? ); instr( ? , ? , ? , ? ) 例: 字 ...
- C语言实现面向对象(转)
1.引言 面向对象编程(OOP)并不是一种特定的语言或者工具,它只是一种设计方法.设计思想. 它表现出来的三个最基本的特性就是封装.继承与多态. 很多面向对象的编程语言已经包含这三个特性了,例如 Sm ...
- Jquery-select元素操作方法
jQuery获取Select元素,并选择的Text和Value: $("#select_id").change(function(){//code...}); //为Select添 ...
- Rails内存的问题 Java内存情况
Rails内存的问题 Java内存情况 一个txt文件,100M,300万行,都是坐标数据: 需要进行坐标的变换.计算.比较: 在Rails中使用Ruby进行计算,会导致内存超过1.5G,最后溢出而亡 ...
- 【MFC设置静态文本框背景为透明】
视图类中加入OnCtlColor()函数: IDC_STATIC1为静态文本框ID HBRUSH CAngleView::OnCtlColor(CDC* pDC, CWnd* pWnd, UINT n ...
- 2 怎样解析XML文件或字符串
1 引用XML文件 2 使用XMLReader解析文本字符串 3 使用XMLReader方法读取XML数据 详细代码实现例如以下: //初始化一个XML字符串 String xmlString = @ ...
- JSP中动态include与静态include的区别介绍
转自:https://m.jb51.net/article/43304.htm 动态INCLUDE 用法:<jsp:include page="included.jsp" f ...