SQL Server-聚焦移除Bookmark Lookup、RID Lookup、Key Lookup提高SQL查询性能
前言
前面几节都是讲的基础内容,本节我们讲讲索引性能优化,当对大数据进行处理时首先想到的就是索引,一旦遇到这样的问题则手忙脚乱,各种查资料,为何平常不扎实基本功呢,我们由浅入深,简短的内容,深入的理解,而非一上来就把问题给框死,立马给出解决方案,抛出问题,再到解决问题,你GET了没有。Always to review the basics。
Bookmark Lookup、RID Lookup、Key Lookup定义
一说到这三者,如果对索引研究不深的童鞋估计是懵逼的,什么玩意,我们姑且将上面三者翻译为:标签查找、行ID查找、键查找。标签查找和键查找是一个意思,在SQL 2005之前叫Key Lookup。怎么解释,如何定义呢?首先我们不看定义,直接看下面一步一步解析,如果你实在忍不住,请看园友【永红】的见解,解释还是非常到位。我们简短的说明下此三者概念。
在查询中,我们对返回的列在查询条件上若建立了非聚集索引,此时将可能尝试使用非聚集索引查找,如果返回的列没有创建非聚集索引,此时会返回到数据页中去获取这些列的数据,即使表中存在聚集索引或者没有,都会返回到表中或者聚集索引中去获取数据。对于以上场景描述,如果表没有创建聚集索引则称为Bookmar Lookup,如果表中没有聚集索引但是存在非聚集索引我们称为RID Lookup。看到这里我们就会想法操作如此耗时,还要返回到基表中去获取数据,所以才有了我们本节来移除以上三者来提高查询性能。接下来我们一起来看看。
抛出Bookmark Lookup、RID Lookup、Key Lookup问题
我们首先创建如下表

USE TSQL2012
GO
CREATE TABLE Sales.Orders
(
[orderid] INT,
[shipaddress] VARCHAR(100),
[shipcity] VARCHAR(100),
[shipregion] VARCHAR(100))
GO
接着进行查询
USE TSQL2012
GO SELECT orderid, shipaddress, shipregion
FROM Sales.Orders
WHERE shipcity = '深圳'

这个不用多讲,没添加任何索引,执行查询计划是全表扫描。接下来我们创建在orderid上创建聚集索引如下:
CREATE CLUSTERED INDEX idx_cls_orderid ON Sales.Orders(orderid)
我们再执行上述查询

此时我们创建了聚集索引,所以此时查询走聚集索引,到这里我们看到情况由全表扫描转换成了索引扫描。我们在查询时一直是带了查询条件的,而对查询条件我们未作任何操作,如果我们此时在查询条件上创建了索引,此时查询的性能又会得到一点改善。我们开始对查询条件创建一个非聚集索引。
CREATE NONCLUSTERED INDEX idx_nc_shipcity ON Sales.Orders(shipcity)
我们再接着执行查询

我们观察到对查询条件创建了非聚集索引,查询计划会使用非聚集索引查找返回结果,但是对于shipaddress, shipcity, shipregion并不是索引的一部分,此时查询引擎会返回到基表中得到这些数据再返回。这种行为就叫做Bookmark Lookup或者Key Lookup。下面我们就如本文标题一样问题出现来解决问题,移除Bookmark Lookup或者Key Lookup。我们尝试用两种不同的方法来解决。
解决Bookmark Lookup、RID Lookup、Key Lookup问题
创建非聚集索引复合索引
我们对查询条件以及检索列创建非聚集索引。
CREATE NONCLUSTERED INDEX idx_all_cover ON Sales.Orders(shipaddress,orderid,shipcity,shipregion)
此时我们对检索列创建了非聚集索引,此时将不会再到数据页中获取数据,而是从索引中直接返回,所以到这里我们算是移除了Key Lookup。但是此时触发另外一个问题,执行查询计划走的却是索引扫描,索引到底是什么呢?我们打个比方,一个索引相当于是数据库中一个本书开始的索引,我们需要快速从书中查找到我们所需要的数据,这个时候书就是我们所说的表。索引扫描意味着要读取表中的所有行,然后返回满足条件的所有数据,当执行索引扫描时,所有行上叶子节点上的所有都会被扫描,这也就意味着索引上的所有行都会被检索一遍而不是直接检索表,和表扫描对比的话,表扫描是直接读取表中数据,所以表扫描和索引扫描还是有一点点不同,而索引查找则是依赖于索引页数据来定位满足条件的所有行,索引查找仅仅只影响满足条件以及页上包含这些满足条件的行,所以说索引查找更加高效。
上述我们稍微讲解了下索引扫描和索引查找,而上述的问题是我们创建了非聚集索引,但是结果执行的查询计划是索引扫描,很是纳闷,对于刚学索引小白的我来说,不知该如何是好,以为是缓存的缘故,清除各种缓存均不好使。于是开始胡思乱想是不是检索列中数据有为NULL引起的,是不是检索列数据重复引起的,尝试了无数次,最终发现某一次居然好使。如下
CREATE NONCLUSTERED INDEX idx_cls_cover ON
Sales.Orders(shipcity,orderid,shipaddress,shipregion)

此时若我们将查询条件进行如下修改。
USE TSQL2012
GO SELECT orderid, shipaddress, shipregion
FROM Sales.Orders
WHERE shipaddress = '深圳'
GO
到这里我们应该发现了,唯一的区别在于我们创建非聚集索引时的顺序和查询条件不同就会导致索引扫描和索引查找的转换,那么到底什么时候才会执行索引查找呢?我们可以进行如下一般性总结:
索引查找的一般性结论:如果条件中包含WHERE或者ON的话,查询条件必须是位于索引集合列中首位,此时索引查找将会被使用。
此时我们穿插一点内容,上述我们创建了覆盖索引,我们来比较下覆盖索引和默认情况下聚集索引查找的性能开销。
覆盖索引与默认聚集索引性能开销比较
FROM Sales.Orders WITH(INDEX([PK_Orders]))
WHERE orderid<11072
go
SELECT orderid, shipaddress, shipregion
FROM Sales.Orders WITH(INDEX([idx_noncls_include_exceptorderid]))
WHERE orderid<11072
GO

从上可知,覆盖索引的开销要比默认主键聚集索引性能开销要好一点,同时我们可以看看如下二者IO代价。

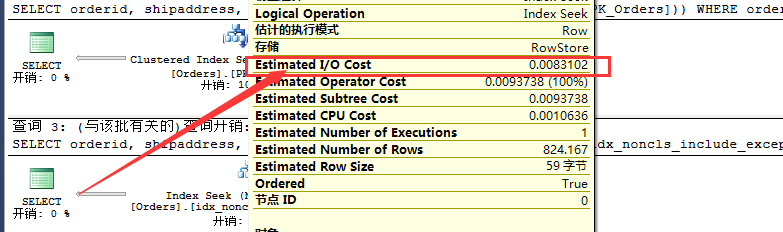
通过上述覆盖索引与默认聚集索引的对比,我们能够有效的减少IO,这一点也是非常明确的,当然下面的INCLUDE索引对比也是另外一种好的方案。
创建INCLUDE非聚集索引
USE TSQL2012
GO CREATE NONCLUSTERED INDEX [ix_noncls_include] ON [TSQL2012].[Sales].[Orders] (
shipcity
) INCLUDE (shipaddress, shipregion, orderid)

至此我们用两种方式来移除了Bookmark Lookup、RID Lookup、Key Lookup,通过使用索引和覆盖索引。
既然有如上两种方式,我们应该有所取舍,二者谁的性能更好呢?我们接下来比较上述二者的开销差异。
比较移除Bookmark Lookup等两种方式差异
USE TSQL2012
GO SELECT orderid, shipaddress, shipcity, shipregion
FROM Sales.Orders WITH(INDEX(idx_all_cover))
WHERE shipcity = '深圳'
GO SELECT orderid, shipaddress, shipcity, shipregion
FROM Sales.Orders WITH(INDEX(ix_noncls_include))
WHERE shipcity = '深圳'
GO
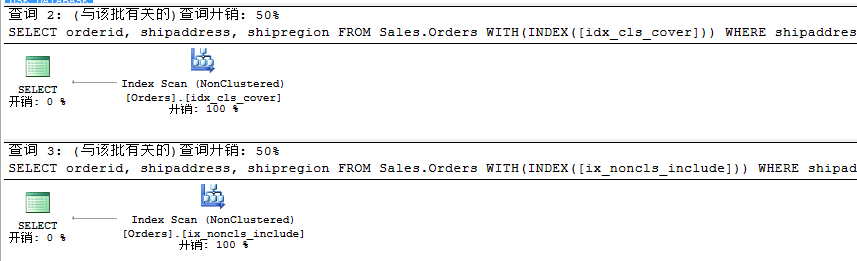
我们从上所知,二者开销一样,并未有什么区别,当然相信我们更倾向于的是将第二种方式作为解决方案。到这里算是基本结束了,但是还有一个小问题,我们在之前已经创建了orderid的聚集索引,后面在解决方案中我们也添加了orderid的非聚集索引,难道非得添加吗,我们去掉试试看。
CREATE NONCLUSTERED INDEX idx_noncls_cover_exceptorderid
ON Sales.Orders(shipcity,shipaddress,shipregion)
CREATE NONCLUSTERED INDEX idx_noncls_include_exceptorderid
ON Sales.Orders(shipcity) INCLUDE(shipaddress,shipregion)
去除orderid比较二者开销差异:
USE TSQL2012
GO SELECT orderid, shipaddress, shipregion
FROM Sales.Orders WITH(INDEX([idx_noncls_cover_exceptorderid]))
WHERE shipaddress = '深圳'
GO SELECT orderid, shipaddress, shipregion
FROM Sales.Orders WITH(INDEX([idx_noncls_include_exceptorderid]))
WHERE shipaddress = '深圳'
GO
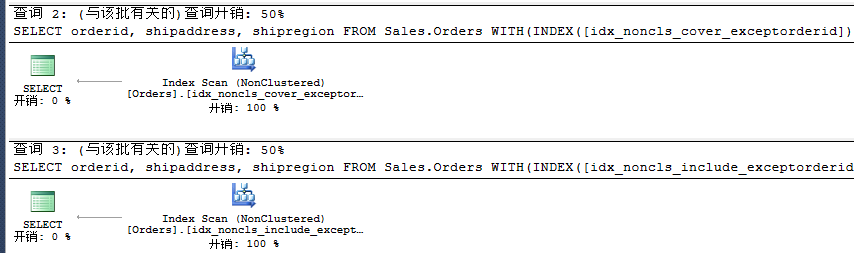
由上知,非聚集索引列不需要包含创建了聚集索引的列,那么事实到底是怎样的呢?
结论:其实对于任何非聚集索引列都不需要包含创建了聚集索引的列,因为创建聚集索引的列是非聚集索引集合列的一部分,也就是说只要一个表上的列创建了聚集索引,那么非聚集索引集合列就包含了这个聚集索引。
总结
本节我们比较详细就问题的抛出到问题的解决,从而来提高查询性能,好了,到此结束,我们下节再会。简短的内容,深入的理解
SQL Server-聚焦移除Bookmark Lookup、RID Lookup、Key Lookup提高SQL查询性能的更多相关文章
- SQL server 创建 修改表格 及表格基本增删改查 及 高级查询 及 (数学、字符串、日期时间)函数[转]
SQL server 创建 修改表格 及表格基本增删改查 及 高级查询 及 (数学.字符串.日期时间)函数 --创建表格 create table aa ( UserName varchar(50 ...
- Sql Server 函数的操作实例!(执行多条语句,返回Select查询后的临时表)
Sql Server 函数的操作实例!(执行多条语句,返回Select查询后的临时表) SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO -- ==== ...
- Sql Server 函数的操作实例!(返回一条Select语句查询后的临时表)
Sql Server 函数的操作实例!(返回一条Select语句查询后的临时表) SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE FUN ...
- SQL SERVER 自动生成 MySQL 表结构及索引 的建表SQL
SQL SERVER的表结构及索引转换为MySQL的表结构及索引,其实在很多第三方工具中有提供,比如navicat.sqlyog等,但是,在处理某些数据类型.默认值及索引转换的时候,总有些 ...
- 看看如何解决“SQL Server只能使用Windows身份登录,不能使用sa等Sql server身份进行登录”的问题
今天安装Sql Server之后,出现SQL Server只能使用Windows身份登录,不能使用sa等Sql server身份进行登录的问题是由于sql server只设置了Windows身份验证, ...
- 已安装 SQL Server 2005 Express 工具。若要继续,请删除 SQL Server 2005 Express 工具
数据库安装sql server2008R2时遇到. 安装sql server 2008 management,提示错误:Sql2005SsmsExpressFacet 检查是否安装了 SQL Serv ...
- SQL Server-聚焦移除Bookmark Lookup、RID Lookup、Key Lookup提高SQL查询性能(六)
前言 前面几节都是讲的基础内容,本节我们讲讲索引性能优化,当对大数据进行处理时首先想到的就是索引,一旦遇到这样的问题则手忙脚乱,各种查资料,为何平常不扎实基本功呢,我们由浅入深,简短的内容,深入的理解 ...
- SQL Server 2005中的分区表(二):如何添加、查询、修改分区表中的数据(转)
在创建完分区表后,可以向分区表中直接插入数据,而不用去管它这些数据放在哪个物理上的数据表中.接上篇文章,我们在创建好的分区表中插入几条数据 insert Sale ([Name],[SaleTime] ...
- SQL Server索引视图以(物化视图)及索引视图与查询重写
本位出处:http://www.cnblogs.com/wy123/p/6041122.html 经常听Oracle的同学说起来物化视图,物化视图的作用之一就是可以实现查询重写,听起来有一种高大上的感 ...
随机推荐
- form表单提交三种方式,demo实例详解
第一种:使用type=submit 可以直接提交 <html> <head> <title>submit直接提交</title> </head& ...
- 洛谷P2678 跳石头
简简单单二分答案,n和m不要写反 Code: #include<cstdio> #include<algorithm> using namespace std; const i ...
- OpenGL中着色器,渲染管线,光栅化
https://www.zhihu.com/question/29163054 光栅(shan一声)化(Rasterize/rasteriztion).这个词儿Adobe官方翻译成栅格化或者像素化 ...
- 在 Windows10 系统中安装 Homestead 本地开发环境
在 windows10 系统中安装 homestead 本地开发环境 在 windows10 环境下安装 homestead 开发环境,网上有很多相关教程其中大多都是 mac 环境,很多大神都是用户的 ...
- String与StringBuffer与StringBuilder
package test; public class Test { public static void main(String[] args) { StringBuffer sb = new Str ...
- mysql数据库优化原则
一.一个例子 数据库需要处理的行数: 189444*1877*13482~~~479亿 如果在关联字段上加上合适的索引: 数据库需要处理的行数:368006*1*3*1~~~110万 MySQL通常是 ...
- css 超出宽度出现省略号
display: block; overflow: hidden; width: 260px; white-space: nowrap; text-overflow: ellipsis;
- 0111mysql如何选择Join的顺序
本文通过一个案例来看看MySQL优化器如何选择索引和JOIN顺序.表结构和数据准备参考本文最后部分"测试环境".这里主要介绍MySQL优化器的主要执行流程,而不是介绍一个优化器的各 ...
- 文件上传前端操作-增加文件与删除文件按钮(jquery实现)
初始 删除与添加 <!DOCTYPE html> <html> <head> <title></title> <meta charse ...
- Java Pattern Matcher 正则表达式需要转义的字符
见:http://blog.csdn.net/bbirdsky/article/details/45368709 /** * 转义正则特殊字符 ($()*+.[]?\^{},|) * * @param ...