Structuring Machine Learning Projects 笔记
1 Machine Learning strategy
1.1 为什么有机器学习调节策略
当你的机器学习系统的性能不佳时,你会想到许多改进的方法。但是选择错误的方向进行改进,会使你花费大量的时间,但是无法得到想要的结果。
这一部分吴恩达老师将讲解一些他在国王总结的经验教训,改进策略,避免南辕北辙。而且现在深度学习的的策略变化日新月异。
1.2 Orthogonalization(正交化)
不耦合的。举例了控制电视屏幕,汽车。
1.2.1 chain of assumption in ML
下面这四个训练时相互正交的,按顺序调整。
训练集表现好
表现好是指约等于人类的表现。
表现不好的改进,如果表现不好,可以使用更大的网络,改变优化方法
开发集表现好
表现不好的改进,正则化,更大的训练集
测试集表现好
表现不好的改进,更大的开发集
实际中表现好
表现不好的改进,调整开发集或者代价函数
吴恩达在训练时一般不适用early stopping,他将会使一些情况耦合。
1.3 单一的评估指标
使用单一的评估指标,可以让你直观的看出来新方法比旧方法更好还是更坏。
查准率(Precision)、查全率(Recall)。F1 Score(可以认为时查准率和查全率的平均)
\[
F_1=\frac{2}{\frac{1}{P}+\frac{1}{R}}
\]
一些机器学习团队会使用一个好的开发集,计算查准率、查全率和一个单一的评估指标。
多个结果的,也可以直接使用平均值。
1.4 Satisficing and Optimizing metric(满足指标和优化指标)
例子,一个分类器需要判断两个指标,准确度和运行时间。这里,准确度就是优化指标,运行时间就是满足指标。
当你需要评价模型时,设定其中一个指标为优化指标,其他指标设置为满足指标,能让你自动的快速评价模型,并选择最佳模型。
1.5 选择dev/test
1.5.1 分布
设定训练集、开发集和测试集将会对机器学习应用产生巨大影响。
这个部分重点讲,开发集和测试集的选择。、
开发集和测试集需要具有相同的分布。不然在开发集上针对一个分布做的调试,无法应用在测试集。
开发集和测试集的选择:能反应将来预计得到的数据和你认为重要的数据。开发集和测试集需要有相同的分布。
1.5.2 尺寸
小尺寸70/30或60/20/20
大尺寸的,比如一百万,需要给训练集更多的数据,给开发集足够的数据从A、B中选择较好的模型;给测试集足够的数据来需要反应系统性能即可。可以这么分98/1/1。
有可能只需要train/dev,有些人可能叫做train/test,但是这么叫并不清晰。
1.6 何时改变dev/test和评估指标
当你发现目标错误的时候,需要改变这些内容。
当你的开发集和评估指标认为A好,但是你和用户认为B好时,需要改变。
定义一个新的评估函数。比如给porn图片加一个惩罚权重。
\[
J=\frac{1}{w^{[i]}}w^{[i]}L(\hat y, y)
\]
在测试集和评估指标上表现的好,并不一定在应用商业表现的好。应用时的情况会不同,如果表现得不好,需要根据应用的情况改变开发集/测试集还有评估函数。
如果不能定义完美的评估函数,也可以定义一个还行的评估函数,这可以加速你的模型训练。
1.7 为什么机器学习和人的表现比较
第一,因为随着深度学习的发展,机器学习算法的效果显著提高,应用到多个领域,所以与人比较。
第二,因为应用机器学习解决问题会比人工更加高效,那么自然要比较人和机器的表现。
随着时间,机器的表现会超过人,但是超过人之后,表现的提升会放缓。而且最终会有一个bayes optimal error。
超过人之后会放缓的原因,1,人和bayes error差距可能很小。2,在机器未超过人时,有很多工具可以提升表现。
当在人更擅长的任务时,人会表现得更好,甚至可以认为人的表现就是bias error,可以从人类获得以下帮助。
- 从人获得标签
- 从人的眼光分析误差
- 更好分析bias/variance
但是当超过了人的表现后,很难从上面获得帮助。
1.8 Avoidable bias
训练集和bias error差距大时,bias问题。差距不大时,这个差距被成为avoidable bias,这时如果开发集和训练集差距被叫做variance,variance很大时,variance问题,这种情况,如果训练集误差比bias error更小,很大可能过拟合。
1.9 理解人类表现
人类表现是贝叶斯误差的代理。所以用人类最佳的表现作为人类表现。具体情况还需要根据目的定义。
当你的误差人类表现很近时,不同的人类表现定义会对你判断bias/variance有影响。很远时没太大影响。
某些情况,贝叶斯误差不等于零,或和人的表现不同,需要去判断。
1.10 超越人类表现
当模型的错误率小于人类的错误率时。而且你不知道贝叶斯误差时,很难确定问题类型bias/varians。很难凭借直觉来判断。
广告、推荐、逻辑回归、贷款发放领域,机器已经比人做得好了。这些领域模型看到的数据会远比人类能看到的多。
自然感知领域(cv/语音识别)人类更擅长。在一些人类擅长的领域,机器也超过了人。这会更困难。但是基于足够的数据,很多深度学习系统一斤超过人类的水平。
1.11 衡量你的模型性能
第一,训练集表现不错。这说明了有较低的avoidable bias。
第二,训练集结果在开发集/测试集上有很强的通用性。这说明了有较低的variance。
1.12 减小bias/variance
人类表现(贝叶斯误差的代理)和训练集之间误差叫做avoidable bias。
训练集和开发集之间的误差叫做variance。
1.12.1 减小avoidable bias
- 训练更大的模型
- 训练更久的时间/使用更好的优化算法(momentum, RMSprop, Adam)
- 搜索不同的神经网络结构(CNN, RNN)/超参数
1.12.2 减小variance
- 更多的数据
- 正则化(L2,dropout,data argumentation[数据增广])
- 搜索不同的神经网络结构/超参数
1.13 误差分析
通过误差分析来判断一个想法对于误差最多能减少多少,来判断是否需要化时间来向这个方向努力。
并行估计多个想法。使用一个类似表格来记录错误的情况是由哪个想法引起的。通过总的占比,最终确认改进方向。
| Image | dog | great cat | bulry | comment |
|---|---|---|---|---|
| 1 | 1 | |||
| 2 | 1 | 1 | ||
| ... | ||||
| % of total | 8% | 43% | 61% |
1.14 清理数据集中错误标签数据
训练集
因为深度学习算法对于随机错误有一定的鲁棒性,如果训练集中的错误标签是随机的,而且占比不多的情况下,则不需要花费太多时间去改正。
开发集、测试集
在误差判断表格里加入一行来判断错误的标签。观察错误标签的比例。观察这个问题对错误率的影响,如果影响不大,则有其他更重要的事情要做,如果影响很大,需要清理错误标签。
如果需要改正,需要遵循:
- 对于开发集和测试集,需要应用相同的改正过程。保证拥有相同的分布。
- 对于错误标签的数据,无论你的模型判断正确与否,都需要改正。
- 训练集和开发/测试集在改正后,可能有不同的分布。
1.15 构造实际系统,并快速迭代
构造实际系统的时候,可能有许多许多方向可以走。应该先构造起实际系统,然后迭代。
- 构造开发集、测试集,设定评估函数
- 快速建造初始的系统
- 使用Bias/Variance系统,然后进行误差分析去判断下一步应该改变什么。
1.16 在不同分布的数据集上训练和测试
当你实际目标的数据量不够多是,可以找不同分布的数据进行补充。例如猫识别程序,你的目标是识别手机拍出来的猫,可能清晰度不够高。但是由于数据不多,你补充了一些爬来的图片,清晰度可能很高。这时需要做的是改变train/dev/test的分配方式。
假设目标的数据有1万个,爬来的数据有25万。
train为25万爬来的+5千目标的。dev为2500目标数据,test为2500目标数据。这样你的优化目标就是判别手机拍的照片是否为猫。
或者将所有目标数据放到dev/test。但是上面的更好些。
不应该把数据全部混合在分配,这样会将大部分的精力用在优化非目标情况。
你并不一定每次都把你拥有的所有数据都用上。
1.16.1 具体例子
Covariate Shift---从一道实际应用题说起 - 阮康睿的文章 - 知乎
(1)数据能不能放在test set上?不行,会造成一定的Covariate Shift,并且,测试集要能直接反应现实目标,本模型的目标是要识别出鸟,所以测试集一定是测试识别鸟。
(2)数据能不能放在Training set上?可以,训练集数据和Dev set, Test set可以不同,从长期来看,训练集更广泛能够让模型拥有更好的泛化能力,以及更加robust。
1.17 Bias/Variance在不匹配的数据分布数据集上
原来判断bias/variance不能完全适应于不匹配时。因为train/dev的区别更大了,差距是因为算法只看到了训练集造成的还是因为训练集和开发集的分布不同。
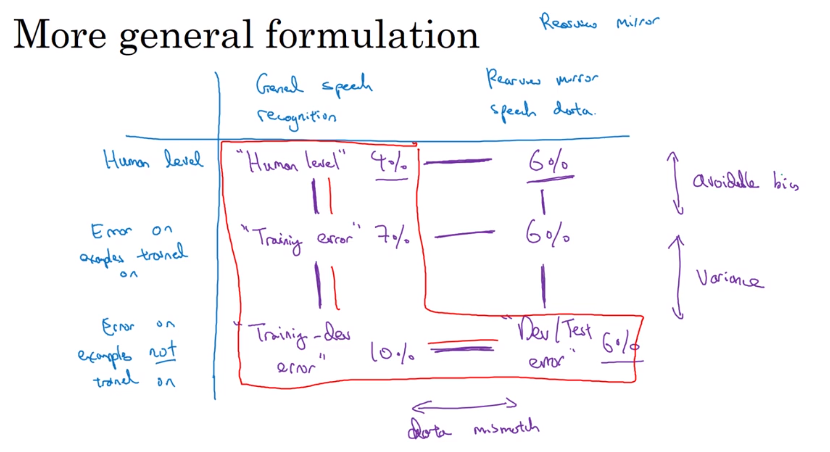
Training-dev set。将train随机打乱,取最后一部分作为train-dev set。最后数据将分为train/train-dev/dev/test。这里,train/train-set来自同一分布,dev/test来自同一分布。只在train上训练。
比较train/train-dev/dev的误差。会出现三种问题,
avoidable bias
如果人类表现和train error差距过大
variance
train和train-dev差距过大。
data mismatch(数据失配)
train-dev和dev差距过大
额外:dev过拟合
dev和test差距过大
上面这几个问题还可能发生组合,四种情况:variance、data mismatch、avoidable bias、bias&data mismatch。
有时候dev和test的误差可能比train还低,可能是因为dev和test过于简单了。
dev/test比train/train-dev高,并不一定是train简单,而是数据失配。
更通用的统计形式,也是上面的总结吧,用表格的形式。
1.18 怎么解决data mismatch(数据失配)
- 人为的去分析误差。去理解训练集、开发集/测试集的不同。例如,两段音频的噪声不同。
- 使训练集数据和开发/测试更相似,或手机更多相似的数据。例如,认为的加入噪声。
1.18.1 人工数据合成
将一个干净的数据加上噪音,合成与开发集/测试集相同的数据。
当噪音远少于数据时,直接重复使用会有过拟合可能性。但是人可能觉得重复的噪声和不重复的没有区别。
1.19 Transfer learning(迁移学习)
pre-training预训练,find-tuning微调
1.19.1 什么是迁移学习?
使用任务A训练一个神经网络,将其输出层改变,或再添加几层网络,新的层的权重随机生成,并使用任务B的数据取训练新的权重,或者所有权重。用新的网络来完成任务B。
1.19.2 何时迁移学习可行?
任务A和B有相同的输入
拥有任务A的数据量远大于任务B
任务A低层次的特征对任务B有帮助
满足上面的三点,迁移学习将可行
1.20 Multi-task learning(多任务学习)
神经网络同时学习多个任务。将输出层变为多层。和softmax只输出一个数字不同。将共同训练多个任务,在前面的将共享一些内容。输入y的标签也可以是不关心的,设置为问号,对于代价函数只统计不是问好的项。
cost function :
\[
\frac{1}{m}\sum^m_{i=1}\sum^4_{j=1}L(\hat y^{(i)}_j,y^{(i)}_j)
\]
1.20.1 什么情况下多任务学习有意义
- 一系列任务可以从彼此获得低层次的特征
- 每个任务的数据彼此相似。比方说100个任务都有1千数据,而且相似,放一起可以增加数据量。
- 可以训练一个足够大的神经网络去在每一个任务上做的足够好。如果不够大的话,可能对每个任务都不好。
迁移学习比多任务学习应用范围更广,用的更多。在cv物体识别上,多任务学习有应用,比分别识别物体更好用。
1.21 end-to-end deep learning(端到端深度学习)
1.21.1 定义
将一个由多个阶段组成的学习系统,变成单个神经网络。
单个神经网络处理一个原先多阶段的任务。
当数据集很大时,端到端学习体现出跟原来的优势。
为什么分步面部识别系统有优势?因为每一步都有大量的数据,而端到端没有足够的数据。maybe有数据,端到端会好用。
机器翻译可以端到端是因为有大量数据。
端到端学习优缺点:
优点:让数据发挥主导作用,更少的手动设计组件。
缺点:需要大量数据,派出了潜在有用的手工设计组件。
1.21.2 什么时候用到端到端学习
关键问题: 你是否有足够的数据去学习出具有能够映射X到Y所需复杂度的方程
自动驾驶方面就很难端到端。
Structuring Machine Learning Projects 笔记的更多相关文章
- 《Structuring Machine Learning Projects》课堂笔记
Lesson 3 Structuring Machine Learning Projects 这篇文章其实是 Coursera 上吴恩达老师的深度学习专业课程的第三门课程的课程笔记. 参考了其他人的笔 ...
- [C5] Andrew Ng - Structuring Machine Learning Projects
About this Course You will learn how to build a successful machine learning project. If you aspire t ...
- 课程三(Structuring Machine Learning Projects),第一周(ML strategy(1)) —— 0.Learning Goals
Learning Goals Understand why Machine Learning strategy is important Apply satisficing and optimizin ...
- 课程三(Structuring Machine Learning Projects),第一周(ML strategy(1)) —— 1.Machine learning Flight simulator:Bird recognition in the city of Peacetopia (case study)
[]To help you practice strategies for machine learning, the following exercise will present an in-de ...
- 吴恩达《深度学习》-课后测验-第三门课 结构化机器学习项目(Structuring Machine Learning Projects)-Week1 Bird recognition in the city of Peacetopia (case study)( 和平之城中的鸟类识别(案例研究))
Week1 Bird recognition in the city of Peacetopia (case study)( 和平之城中的鸟类识别(案例研究)) 1.Problem Statement ...
- 【DL.AI】《Structuring Machine Learning Projects》笔记
一.改进模型的几个方法 Collect more data Collect more diverse training set Train algorithm longer with gradient ...
- 吴恩达《深度学习》-第三门课 结构化机器学习项目(Structuring Machine Learning Projects)-第一周 机器学习(ML)策略(1)(ML strategy(1))-课程笔记
第一周 机器学习(ML)策略(1)(ML strategy(1)) 1.1 为什么是 ML 策略?(Why ML Strategy?) 希望在这门课程中,可以教给一些策略,一些分析机器学习问题的方法, ...
- 课程回顾-Structuring Machine Learning Projects
正交化 Orthogonalization单一评价指标保证训练.验证.测试的数据分布一致不同的错误错误分析数据分布不一致迁移学习 transfer learning多任务学习 Multi-task l ...
- Coursera Deep Learning 3 Structuring Machine Learning Projects, ML Strategy
Why ML stategy 怎么提高预测准确度?有了stategy就知道从哪些地方入手,而不至于找错方向做无用功. Satisficing and Optimizing metric 上图中,run ...
随机推荐
- uCGUI 按键窗口切换机制(更新篇)
在之前文章中,讲述了一个低内存使用量的的窗口切换机制.有人会问,低内存使用量是多低呢,我这里举个例子.我有一个项目中使用到本切换机制,128*64的单色屏,初步计算有105个窗口(后面还会增加),总内 ...
- zookeeper学习与实战(二)集群部署
上一篇介绍了单机版zookeeper安装,这种情况一般用于开发测试.如果是生产环境建议用分布式集群部署,防止单点故障,增加zookeeper服务的高可用. [环境介绍] 三台机器:192. ...
- hd acm2035
求A^B的最后三位数表示的整数.说明:A^B的含义是“A的B次方” 思路:后三位只跟后三位相乘有关,所以可以每乘一次都对1000取余. 代码: #include <stdio.h>#inc ...
- Linux 创建Bridge
安装Bridge工具软件包 Linux可以工作在网桥模式,必须安装网桥工具bridge-utils,运行命令: yum install bridge-utils 或 apt-get install b ...
- FOJ 2213 简单几何
题意:给你两个圆的圆心坐标和半径,判断两个圆公切线数目. 思路:考虑两个圆间公切线的情况,两个圆的位置关系分为相离,相交,外切,内切,内含,重合,公切线数分别为4,2,3,1,0,-1. #inclu ...
- mongodb同步
mongodb同步 py-mongo-sync MongodbSync mongodb 的一个同步工具,具备将一个数据源上的数据,同步到其它 mongodb 上,支持: mongos -> (m ...
- Spring Cloud之Zuul负载均衡
Zuul网关默认是实现负载均衡的,不需要任何配置.默认开启ribbon效果的 可以启启动两个服务端口,访问下.
- JFreeChart的使用示例
示例一,饼图,简单示例: 导入jar,代码文件: 运行结果: 代码: import org.jfree.chart.ChartFactory;import org.jfree.chart.ChartF ...
- Linux- 自动备份MySQL数据库脚本
数据安全很重要,所以日常中需要对数据库进行备份.
- Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析
Office文件的奥秘——.NET平台下不借助Office实现Word.Powerpoint等文件的解析 分类: 技术 2013-07-26 15:38 852人阅读 评论(0) 收藏 举报 Offi ...