namenode和datanode机制
转自:https://www.cnblogs.com/DarrenChan/p/6416043.html?utm_source=itdadao&utm_medium=referral
首先我们看一下NAMENODE:
我们已经知道了NAMENODE作为DATANODE的管理者,其重要性不言而喻,那么NAMENODE是怎么管理数据的呢?

首先,我们看一下上面这张图,每次客户端读写数据都要先经过NAMENODE,其实就是先查询NAMENODE中的元数据,那么问题来了,NAMENODE中的元数据究竟是存在内存中还是存在硬盘中呢?如果存在内存中,一旦断电就意味着数据的丢失;但是存在硬盘中,读写速度必然下降。下面将对其细节进行详尽的阐述。

通过看以上这幅图,我们可以看到NAMENODE中的元数据既存在在内存中,也存在在硬盘中。我们先看一下元数据的存储细节:
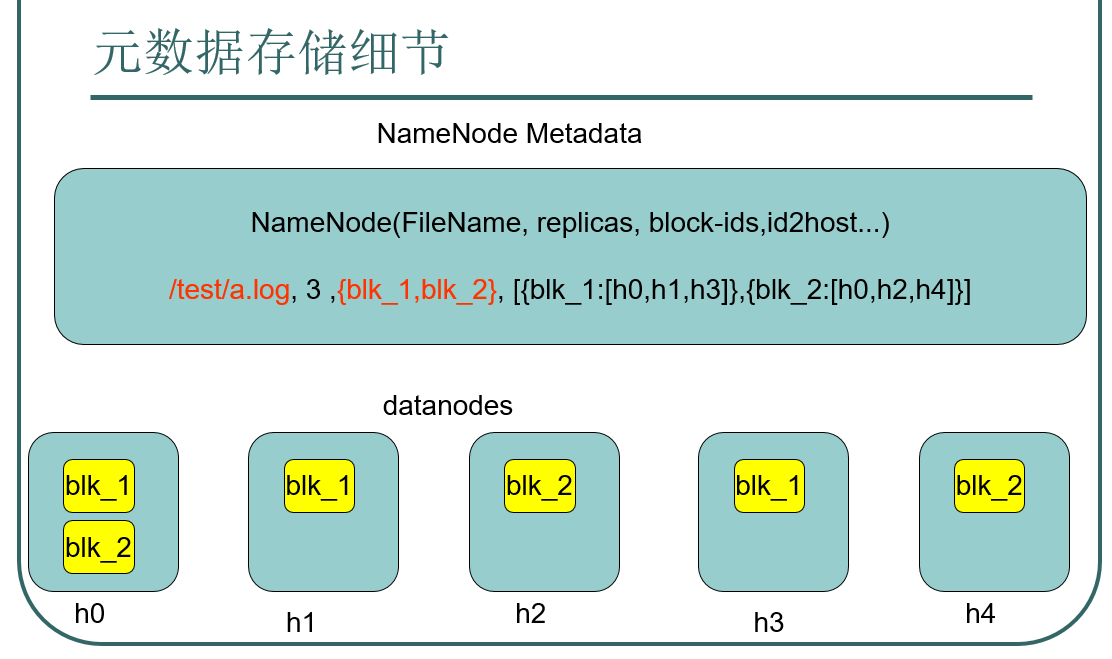
从左到右依次是存储路径,有哪些副本,每个副本在哪些主机上面存储。NAMENODE是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,接受用户的操作请求。
文件包括:
1.fsimage:元数据镜像文件,存储某一时段NAMENODE内存元数据信息。
2.edits:操作日志文件。
3.fstime:保存最近一次checkpoint的时间。
现在我们回到上一幅图,
1.NAMENODE始终在内存中保存meta.data,用于处理“读请求”。
2.到有“写请求”到来时,NAMENODE会首先写edits到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回。
3.Hadoop会维护一个fsimage文件,也就是namenode中meta.data的镜像,但是fsimage不会随时与NAMENODE内存中的meta.data保持一致,而是每隔一段时间通过合并edits文件来更新内容。Secondary NAMENODE就是用来合并fsimage和edits文件来更新NAMENODE的meta.data的。
这里就用到了Secondary NAMENODE,我们再来看一张图:
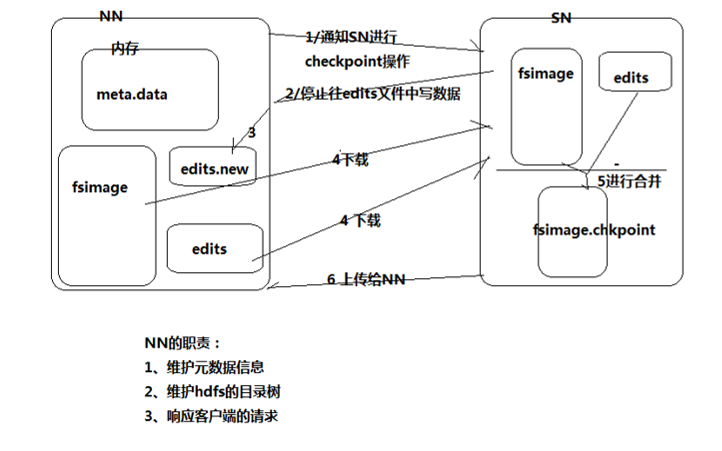
在这张图中,我们可以看到SN的一些作用,当NN通知SN要进行checkpoint操作的时候,NN就停止向edits日志中写数据了,但是写操作又不能停止,这时候就会向一个edits.new日志文件中写数据,而SN会把fsimage和edits里面的内容下载到SN中,在SN中进行合并,说白了,就是将日志格式转化成要存储的文件格式,产生fsimage.chkpoint文件,并将它上传给NN,替换fsimage,并且重命名成fsimage,同时edits.new替换edits,并且重命名成edits。详细过程就是:

那么什么时候checkpoint呢?有两种判别方式:
1.fs.checkpoint.period:指定两次checkpoint的最大时间间隔,默认是3600秒。
2.fs.checkpoint.size:规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否达到最大时间间隔。默认大小是64M。
两种判定方式先达到哪个判定条件,则先采用哪个。
我们再来看一下DATANODE:
DataNode
提供真实文件数据的存储服务
文件块:最基本的存储单位,对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移,按照固定的大小,顺序对文件进行划分并编号。划分好的每一块称为一个Block,默认Block的大小是128M。开始不同于普通文件系统的是HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。datanode与namenode保存心跳机制,当长时间未向namenode报告,则视为该datanode死机,namenode会重新备份该datanode上的数据块。
namenode和datanode机制的更多相关文章
- Hadoop的namenode的管理机制,工作机制和datanode的工作原理
HDFS前言: 1) 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: 2)在大数据系统中作用: 为各类分布式运算框架(如:mapr ...
- NameNode机制和DataNode机制
首先我们看一下NAMENODE: 我们已经知道了NAMENODE作为DATANODE的管理者,其重要性不言而喻,那么NAMENODE是怎么管理数据的呢? 首先,我们看一下上面这张图,每次客户端读写数据 ...
- Hadoop(五)—— HDFS NameNode、DataNode工作机制
一.NN与2NN工作机制 NameNode(NN) 1.当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中. 2-4.当元数据的增删改查请求进来时,NameNode会先将操 ...
- NameNode与DataNode的工作原理剖析
NameNode与DataNode的工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS写数据流程 >.客户端通过Distributed FileSyst ...
- Hadoop介绍-4.Hadoop中NameNode、DataNode、Secondary、NameNode、JobTracker TaskTracker
Hadoop是一个能够对大量数据进行分布式处理的软体框架,实现了Google的MapReduce编程模型和框架,能够把应用程式分割成许多的 小的工作单元,并把这些单元放到任何集群节点上执行.在MapR ...
- HDFS体系结构(NameNode、DataNode详解)
hadoop项目地址:http://hadoop.apache.org/ NameNode.DataNode详解 (一)分布式文件系统概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配 ...
- 初识HDFS(10分钟了解HDFS、NameNode和DataNode)
概览 首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通 ...
- namenode和datanode的高可用性和故障处理
一.Hadoop单点故障问题如何解决 Hadoop 1.0内核主要由两个分支组成:MapReduce和HDFS,众所周知,这两个系统的设计缺陷是单点故障,即MR的JobTracker和HDFS的Nam ...
- hadoop中NameNode、DataNode和Client三者之间协作关系及通信方式介绍
<ignore_js_op> 1)NameNode.DataNode和Client NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间.集群 ...
随机推荐
- VC++异常捕获??
1. std: #include <string> #include<iostream> // for cerr //#include <stdexcept> // ...
- Linux下Apache的安装与配置
本文安装的httpd版本为httpd 2.4.4安装之前确保 Development Libraries与Development tools安装上.安装方法参考:http://www.linuxidc ...
- Lucene.Net 优化索引生成,即搜索显示优化
最近发现站内搜索引擎响应速度很慢,因为刚来公司之前技术员跑了源码什么的都没留下.只好自己手动破解源代码dll查找问题所在! 这个问题代码就暂时不贴了这里只写思路 原逻辑:经过整体分析后发现之前是使用 ...
- 20个PHP面试题及答案
php学了那么久了,先来小试牛刀,看下这些PHP程序员面试题都会不会?初级题目1.问题:请用最简单的语言描述PHP是什么?答:PHP全称:Hypertext Preprocessor,是一种用来开发动 ...
- mac下用brew安装mongodb
分享到:QQ空间新浪微博腾讯微博人人网微信 mac 下安装mongoDB一般俩种方法. (1)下载源码,解压,编译,配置,启动 比较艰难的一种模式. (2)brew install mongodb , ...
- Linux 线程同步的三种方法(互斥锁、条件变量、信号量)
互斥锁 #include <cstdio> #include <cstdlib> #include <unistd.h> #include <pthread. ...
- cocos2dx混合模式应用———制作新手引导高亮区域 (2.2.0)
cocos2dx混合模式应用———制作新手引导高亮区域 转自:http://www.cnblogs.com/mrblue/p/3455775.html 首先,效果预览一下 高亮区域的图片: 示例代码: ...
- itunesconnect如何提交被决绝过了的相同版本号
遇到一次审核被拒,打算再次提交时,不想改变版本号,可以在xcode里把build版本号后面几个.1,比如version上次被拒时是1.1.3,build也是1.1.3,这次送审时version不变,b ...
- Agc019_C Fountain Walk
传送门 题目大意 给定网格图上起点和终点每个格子是长为$100$米的正方形,你可以沿着线走. 平面上还有若干个关键点,以每个关键点为圆心,$10$为半径画圆,表示不能进入圆内的线,但是可以从圆周上走, ...
- pandas中Loc vs. iloc vs. ix vs. at vs. iat?
loc: only work on indexiloc: work on positionix: You can get data from dataframe without it being in ...