01--是时候让我们谈谈一致性hash了
---------------------
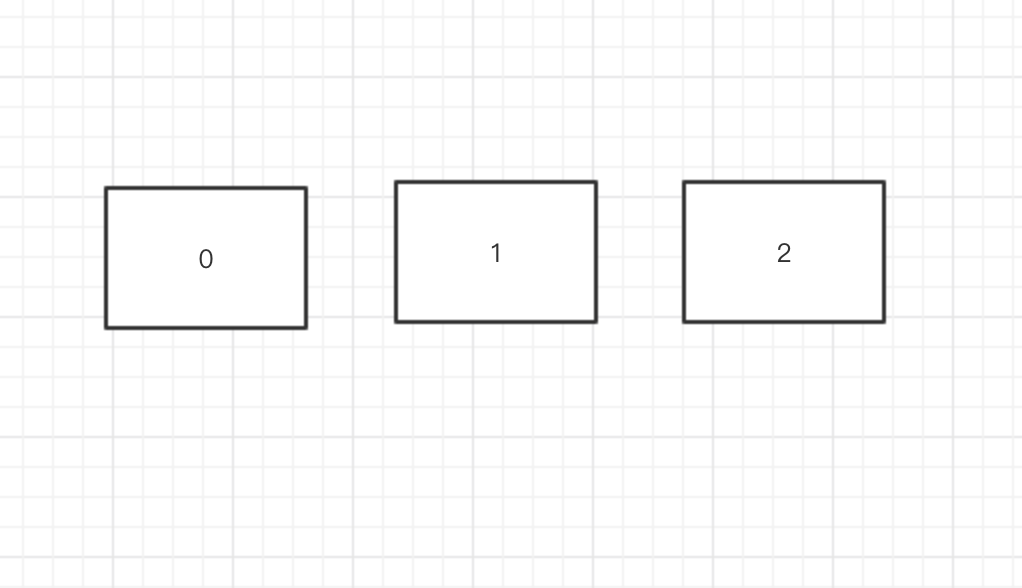
假如你有图中三个盒子,我们有代号为 1,4,5,12 这四样东西 那根据代号作为主键,将东西放到盒子了,该如何放置?
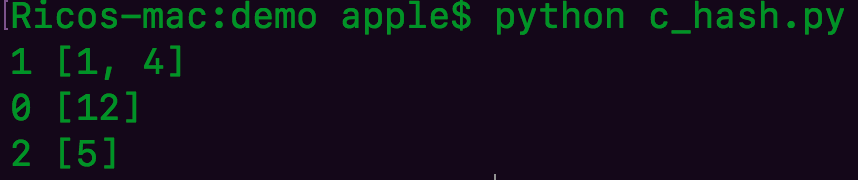
我们可以对代号取模 1 mod 3 = 1 4 mod 3 = 1 5 mod 3 = 2 12mod 3 = 0
这样的话 大家就可以分配好到对应到盒子里
1 #!/usr/bin/env python
2
3 box0 = []
4 box1 = []
5 box2 = []
6 box_home = {
7 '0':[],
8 '1':[],
9 '2':[],
10 }
11 res = [1,4,5,12]
12
13 for i in res:
14 key = i % 3
15 if key == 0:
16 box_home[str(key)].append(i)
17 elif key == 1:
18 box_home[str(key)].append(i)
19 elif key == 2:
20 box_home[str(key)].append(i)
21
22 for k,v in box_home.items():
23 print k,v
~
代码如上
-------------------------------------------------------------
但是如果现在加一个盒子 。
就变成这样了
那么现在就要取模为4了 之前箱子里面的东西都要重新计算重新,重新摆放。
这在很多场景是不能够接受的,比如负载均衡,我不能因为重新加了一个节点,让所有用户的长链接都断开,重新链接。
或许这种还能接受,那么如果是分布式存储呢?
所以这个时候我们不能够这样做。这样子都服务就不是无状态都服务。
这个时候就是一致性hash派上用场的时候了。
我们可以在刚刚分配的时候预留很多空位置。
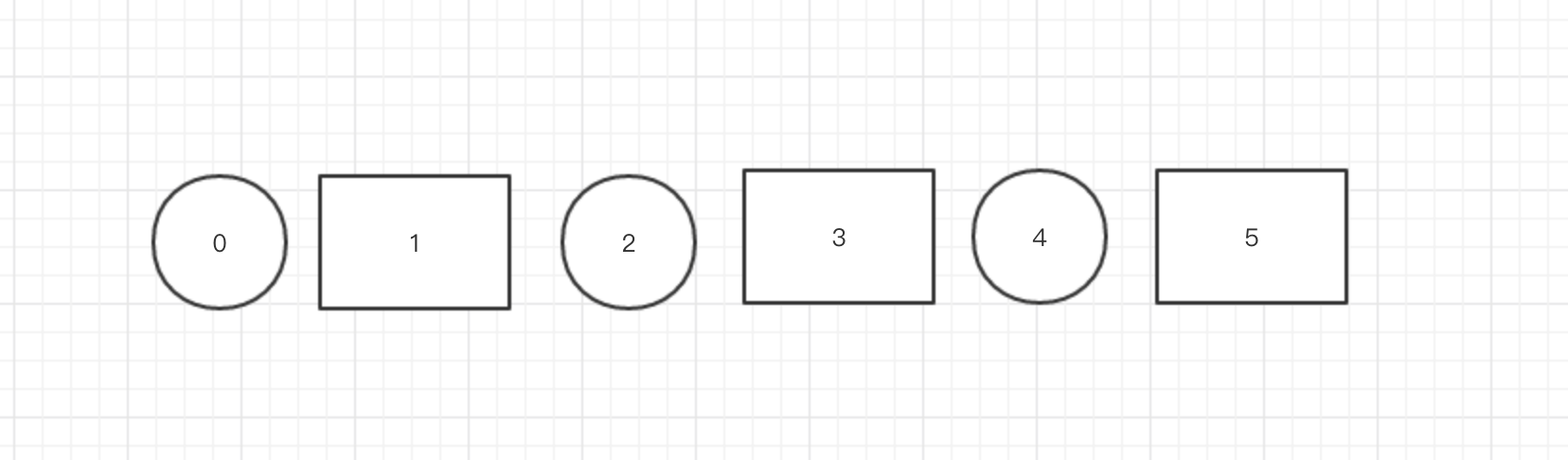
圆形就是是空,矩形就是有箱子的。我们可以在一开始就留很多空白多地方 ,如图上
我们一开始有三个节点,但是我们会分配5个位置,然后有数据就mod6,如果数据分配到到是没有节点到位置
那么我就就把这个数据放到下一个有节点到位置,比如图上我们要分配到是 数据8 那么8mod6 = 2 此时位置2上没有节点。那么将这个数据到下一个有节点到位置
也就是位置3。如果是mod到是最后一个那么就从头开始,也就是说,位置是环形的。
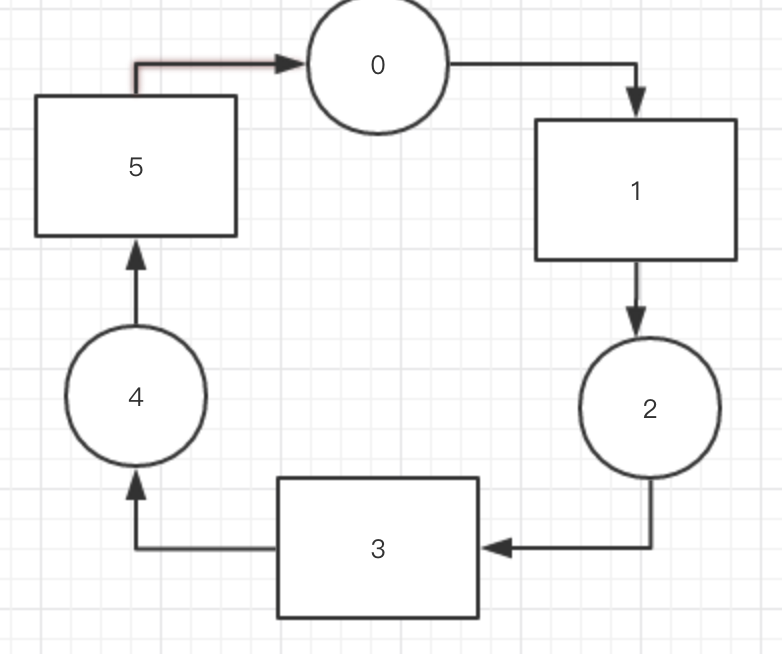
如有新的节点加入,那么直接放到空的位置上,然后将之前的分配在这个位置上的数据转移上去即可,这样子就能避免重新分配。
我们可以通过代码模拟分配情况
#!/usr/bin/env python
#coding:utf-8 class Node():
def __init__(self,data,next_node = None,node_type = 'body',is_online=0): self.data = data
self.next_node = next_node
self.is_online = is_online
self.node_type = node_type
self.self_data = []
self.other_data = [] def get_next_node(self):
return self.next_node def set_next_node(self,next_node):
self.next_node = next_node
return True def set_node_status(self,num):
self.is_onlie = num def get_data(self):
return self.data class boxs():
def __init__(self,head=None):
self.head_node = head
self.size = 0
self.ser_node = None def add_None(self,data,num):
if self.head_node == None:
self.head_node =Node(data,is_online=num)
self.scr_node = self.head_node
self.size +=1
else:
new_node = Node(data,is_online=num)
self.scr_node.set_next_node(new_node)
self.scr_node = new_node
self.size +=1 def print_list(self):
curr = self.head_node
while curr :
print '-----------------------'
print curr.data,'--->',curr.node_type,"---->",curr.is_online
print "data:",curr.self_data
print "other_data",curr.other_data if curr.node_type != 'body':
break
else:
curr = curr.get_next_node() def set_ass_node(self,data,num):
new_node = Node(data,node_type='tail',is_online=num)
new_node.type = 'tail'
self.scr_node.set_next_node(new_node)
new_node.set_next_node(self.head_node) def insert_data(self,key,dick_len):
curr = self.head_node
while curr:
if key % dick_len == curr.data:
if curr.is_online == 1:
curr.self_data.append(key)
else:
while 1:
curr = curr.get_next_node()
if curr.is_online == 1:
curr.other_data.append(key)
break break
else:
curr = curr.get_next_node() def set_node_allot(self,key_dict,dick_len):
for key in key_dict:
self.insert_data(key,dick_len) #设置节点种有盒子的节点
online_node = [1,3,5] #实例化链表
mylist = boxs() #添加节点,如果节点数属于online_node的节点 那么就设定他在线
for i in range(7): now_status = 0
if i in online_node:
now_status =1 if i <6:
mylist.add_None(i,now_status)
else: mylist.set_ass_node(6,now_status)
#模拟数据
key_dict = [2,3,5,6,12,22,23,33] #分配数据
mylist.set_node_allot(key_dict,len(key_dict)-1) #打印分配情况
mylist.print_list()
01--是时候让我们谈谈一致性hash了的更多相关文章
- 转载自lanceyan: 一致性hash和solr千万级数据分布式搜索引擎中的应用
一致性hash和solr千万级数据分布式搜索引擎中的应用 互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中获得 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 一致性hash和solr千万级数据分布式搜索引擎中的应用
互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中 获得成功,这个和当前的开源技术.海量数据架构有着必不可分的关 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- php 实现一致性hash 算法 memcache
散列表的应用 涉及到数据查找比对,首先考虑到使用HashSet.HashSet最大的好处就是实现查找时间复杂度为O(1).使用HashSet需要解决一个重要问题:冲突问题.对比研究了网上一些字符串哈希 ...
- 【转】分布式存储和一致性hash
本文我将对一致性算法作介绍,同时谈谈自己对一致性hash和一般意义上的hash算法的区别 hash是什么 hash即hash算法,又称为散列算法,百度百科的定义是 哈希算法将任意长度的二进制值映射为较 ...
- 给面试官讲明白:一致性Hash的原理和实践
"一致性hash的设计初衷是解决分布式缓存问题,它不仅能起到hash作用,还可以在服务器宕机时,尽量少地迁移数据.因此被广泛用于状态服务的路由功能" 01分布式系统的路由算法 假设 ...
- 一致性 Hash 在负载均衡中的应用
介 一致性Hash是一种特殊的Hash算法,由于其均衡性.持久性的映射特点,被广泛的应用于负载均衡领域,如nginx和memcached都采用了一致性Hash来作为集群负载均衡的方案.本文将介绍一致性 ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
随机推荐
- java连接ssh执行shell脚本
在liunx上写了一个shell脚本,想通过java去调用这个shell脚本,不知道怎么去调用,在网上说使用process这个进程方式,但是我执行机和我shell脚本都不在同一台电脑,老大说java中 ...
- Poj(2240),Floyd求汇率是不是赚钱
题目链接:http://poj.org/problem?id=2240. Floyd算法修改一下,我要最大路径(通过转汇率变到最大)改成max. #include <iostream> # ...
- 20145238-荆玉茗 《Java程序设计》第2次实验
20145238 <Java程序设计>第2次实验报告 实验二 Java面向对象程序设计 一.实验内容 初步掌握单元测试和TDD 理解并掌握面向对象三要素:封装.继承.多态 初步掌握UML建 ...
- Responsive设计 (响应式设计)
一.什么是响应式设计 维基百科是这样对响应式作的描述:“Responsive设计简单的称为RWD,是精心提供各种设备都能浏览网页的一种设计方法,RWD能让你的网页在不同的设备中展现不同的设计风格.” ...
- python中那个断言assert的优化
Python Assert 为何不尽如人意# Python中的断言用起来非常简单,你可以在assert后面跟上任意判断条件,如果断言失败则会抛出异常. Copy >>> assert ...
- 缓冲区溢出实战教程系列(三):利用OllyDbg了解程序运行机制
想要进行缓冲区溢出的分析与利用,当然就要懂得程序运行的机制.今天我们就用动态分析神器ollydbg来了解一下在windows下程序是如何运行的. 戳这里看之前发布的文章: 缓冲区溢出实战教程系列(一) ...
- xml中${}的使用含义(美元符号大括号,以Spring、ibatis、mybatis为例)
项目中,经常会在xml中看到这样的写法: <properties resource="properties/database.properties"/> <dat ...
- caffe安装中opencv的各种库问题
提示有些库 high**** opencv的问题,好像是这几个库版本冲突,不要用anaconda里的lib库,用系统的库就行了,删掉或者从新链接过去.
- docker镜像文件导入与导出 , 支持批量
1. 查看镜像id sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE quay.io/calico/node v1.0.1 c70511a ...
- linux文件访问过程和权限
第1章 文件访问过程详解 1.1 文件访问过程 第2章 权限 2.1 对于文件rwx含义 r读取文件内容 w修改文件内容 需要r权限配合 只有w权限的时候,强制保存退出会导致源文件内容丢失 x权限表示 ...