SuperSpider(简书爬虫JAVA版)
* 建站数据SuperSpider(简书)
* 本项目目的:
* 为练习web开发提供相关的数据;
* 主要数据包括:
* 简书热门专题模块信息、对应模块下的热门文章、
* 文章的详细信息、作者信息、
* 评论区详细信息、评论者信息等...
* 最后存储mysql数据库.
想学习爬虫的同学也可以瞧瞧
整个项目跑完花了近十个小时, 足见数据之多, 个人web开发练习用来充当建站数据也是绰绰有余的(~ ̄▽ ̄)~
代码注释写的挺详细的,我就直接上代码了。
主要代码:
/**
* 此类对简书文章内容页进行了详细的解析爬取;
* 封装后的唯一入口函数 {@link ArticleSpider#run(String, int)}.
*
* author As_
* date 2018-08-21 12:34:23
* github https://github.com/apknet
*/ public class ArticleSpider { /** 长度为4 :阅读量、评论数、点赞数、文章对应的评论id */
private List<Integer> readComLikeList = new ArrayList<>(); /** 文章Id */
private long articleId; /**
* 此类的入口函数;
* 爬虫范围包括文章的详情信息、评论的详细信息;
* 并同时持久化数据;
* key实例:443219930c5b
*
* @param key
* @param flag_type 文章所属分类的索引
*/ public void run(String key, int flag_type){ try {
articleSpider(key, flag_type); // 以下参数由articleSpeder()函数获得
String comUrl = String.format("https://www.jianshu.com/notes/%d/comments?comment_id=&author_only=false&since_id=0&max_id=1586510606000&order_by=desc&page=1", readComLikeList.get(3)); comSpider(comUrl); } catch (Exception e) {
e.printStackTrace();
}
} /**
* 链接实例 https://www.jianshu.com/p/443219930c5b
* 故只接受最后一段关键字
* @param key
* @param flag_type 文章所属分类的索引
* @throws Exception
*/
private void articleSpider(String key, int flag_type) throws Exception { String url = "https://www.jianshu.com/p/" + key; Document document = getDocument(url); IdUtils idUtils = new IdUtils(); List<Integer> list = getReadComLikeList(document); articleId = idUtils.genArticleId();
String title = getTitle(document);
String time = getTime(document);
String imgCover = getImgCover(document);
String brief = getBrief(document);
String content = getContent(document);
String author = idUtils.genUserId();
int type = flag_type;
int readNum = list.get(0);
int comNum = list.get(1);
int likeNum = list.get(2); // 数据库添加对应对象数据
Article article = new Article(articleId, title, time, imgCover, brief, content, author, type, readNum, comNum, likeNum);
new ArticleDao().addArticle(article); User user = new User();
user.setUser(idUtils.genUserId());
user.setName(getAuthorName(document));
user.setImgAvatar(getAuthorAvatar(document));
new UserDao().addUser(user); } private Document getDocument(String url) throws IOException { Document document = Jsoup.connect(url)
.header("User-Agent", "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:61.0) Gecko/20100101 Firefox/61.0")
.header("Content-Type", "application/json; charset=utf-8")
.header("Cookie", "_m7e_session=2e930226548924f569cb27ba833346db;locale=zh-CN;default_font=font2;read_mode=day")
.get();
return document;
} private String getTitle(Document doc){
return doc.select("h1[class=title]").text();
} private String getTime(Document doc){
Element element = doc.select("span[class=publish-time]").first();
return element.text();
} private String getImgCover(Document doc){
Element element = doc.select("img[data-original-format=image/jpeg]").first();
if (element.hasAttr("data-original-src")){
String url = element.attr("data-original-src").trim();
return SpiderUtils.handleUrl(url);
}
return null;
} private String getBrief(Document doc){
return doc.select("meta[name=description]").first().attr("content");
} private String getContent(Document doc){
Element element = doc.select("div[class=show-content-free]").first();
// System.out.println(element.html()); Elements eles = element.select("div[class=image-package]");
for(Element ele: eles){
Element imgEle = ele.select("img").first();
ele.replaceWith(imgEle);
} String result = element.html().replaceAll("data-original-", "");
return result;
} private String getAuthorAvatar(Document doc){
String url = doc.select("div[class=author]").select("img").attr("src");
return SpiderUtils.handleUrl(url);
} private String getAuthorName(Document doc){
Element element = doc.select("script[data-name=page-data]").first();
JSONObject jsonObject = new JSONObject(element.html()).getJSONObject("note").getJSONObject("author");
return jsonObject.getString("nickname");
} private List<Integer> getReadComLikeList(Document doc){
Element element = doc.select("script[data-name=page-data]").first();
JSONObject jsonObject = new JSONObject(element.html()).getJSONObject("note"); readComLikeList.add(jsonObject.getInt("views_count"));
readComLikeList.add(jsonObject.getInt("comments_count"));
readComLikeList.add(jsonObject.getInt("likes_count"));
readComLikeList.add(jsonObject.getInt("id")); System.out.println(Arrays.toString(readComLikeList.toArray()));
return readComLikeList;
} /**
* 评论区爬虫---包括:
* 评论楼层、时间、内容、评论者、评论回复信息等
* 具体可查看{@link Comment}
*
* @param url
* @throws Exception
*/
private void comSpider(String url) throws Exception {
URLConnection connection = new URL(url).openConnection(); // 需加上Accept header,不然导致406
connection.setRequestProperty("Accept", "*/*"); BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream())); String line;
StringBuilder str = new StringBuilder(); while ((line = reader.readLine()) != null) {
str.append(line);
} System.out.println(str.toString()); JSONObject jb = new JSONObject(str.toString()); boolean hasComment = jb.getBoolean("comment_exist");
if(hasComment){
int pages = jb.getInt("total_pages");
if(pages > 20){
// 某些热门文章评论成千上万, 此时没必要全部爬取
pages = 20;
}
int curPage = jb.getInt("page"); JSONArray jsonArray = jb.getJSONArray("comments");
Iterator iterator = jsonArray.iterator();
while(iterator.hasNext()){
JSONObject comment = (JSONObject) iterator.next();
JSONArray comChildren = comment.getJSONArray("children");
JSONObject userObj = comment.getJSONObject("user");
IdUtils idUtils = new IdUtils();
CommentDao commentDao = new CommentDao();
UserDao userDao = new UserDao(); int commentId = idUtils.genCommentId();
String userId = idUtils.genUserId(); System.out.println(comment.toString());
// 评论内容相关
String content = comment.getString("compiled_content");
String time = comment.getString("created_at");
int floor = comment.getInt("floor");
int likeNum = comment.getInt("likes_count");
int parentId = 0; // 评论者信息
String name = userObj.getString("nickname");
String avatar = userObj.getString("avatar"); Comment newCom = new Comment(commentId, articleId, content, time, floor, likeNum, parentId, userId, avatar, name);
commentDao.addComment(newCom); User user = new User();
user.setUser(userId);
user.setName(name);
user.setImgAvatar(avatar); userDao.addUser(user); // 爬取评论中的回复
Iterator childrenIte = comChildren.iterator();
while(childrenIte.hasNext()){
JSONObject child = (JSONObject) childrenIte.next(); Comment childCom = new Comment();
childCom.setId(idUtils.genCommentId());
childCom.setArticleId(articleId);
childCom.setComment(child.getString("compiled_content"));
childCom.setTime(child.getString("created_at"));
childCom.setParentId(child.getInt("parent_id"));
childCom.setFloor(floor);
childCom.setNameAuthor(child.getJSONObject("user").getString("nickname")); commentDao.addComment(childCom); }
} // 实现自动翻页
if(curPage == 1){
for(int i = 2; i <= pages; i++){
System.out.println("page-------------------> " + i);
int index = url.indexOf("page=");
String sub_url = url.substring(0, index + 5);
String nextPage = sub_url + i;
comSpider(nextPage);
}
}
}
}
}
and:
/**
* 模块(简书的专题)爬虫
* 入口:https://www.jianshu.com/recommendations/collections
* 模块实例: https://www.jianshu.com/c/V2CqjW
* 文章实例: https://www.jianshu.com/p/443219930c5b
* 故此爬虫多处直接传递链接后缀的关键字符串(如‘V2CqjW’、‘443219930c5b’)
*
* @author As_
* @date 2018-08-21 12:31:35
* @github https://github.com/apknet
*
*/ public class ModuleSpider { public void run() {
try { List<String> moduleList = getModuleList("https://www.jianshu.com/recommendations/collections"); for (String key: moduleList) {
// 每个Module爬取10页内容的文章
System.out.println((moduleList.indexOf(key) + 1) + "." + key);
for (int page = 1; page < 11; page++) {
String moduleUrl = String.format("https://www.jianshu.com/c/%s?order_by=top&page=%d", key, page); List<String> articleList = getArticleList(moduleUrl); for (String articlekey: articleList) {
new ArticleSpider().run(articlekey, moduleList.indexOf(key) + 1);
}
}
} } catch (Exception e) {
e.printStackTrace();
}
} /**
* 返回Module 关键字符段
* @param url
* @return
* @throws IOException
* @throws SQLException
*/ private List<String> getModuleList(String url) throws IOException, SQLException { List<String> moduleList = new ArrayList<>();
int i = 0; Document document = Jsoup.connect(url).get();
Element container = document.selectFirst("div[id=list-container]");
Elements modules = container.children();
for(Element ele: modules){
String relUrl = ele.select("a[target=_blank]").attr("href");
String moduleKey = relUrl.substring(relUrl.indexOf("/c/") + 3);
moduleList.add(moduleKey); // System.out.println(moduleKey);
// 以下爬取数据创建Module对象并持久化 String name = ele.select("h4[class=name]").text();
String brief = ele.selectFirst("p[class=collection-description]").text();
String imgcover = SpiderUtils.handleUrl(ele.selectFirst("img[class=avatar-collection]").attr("src")); String articleNu = ele.select("a[target=_blank]").get(1).text();
int articleNum = Integer.parseInt(articleNu.substring(0, articleNu.indexOf("篇"))); String userNu = ele.select("div[class=count]").text().replace(articleNu, "");
Matcher matcher = Pattern.compile("(\\D*)(\\d*\\.\\d*)?(\\D*)").matcher(userNu);
matcher.find();
int userNum = (int)(Float.parseFloat(matcher.group(2)) * 1000); Module module = new Module((++i), name, brief, imgcover, userNum, articleNum, "apknet");
new ModuleDao().addModule(module); System.out.println(name + "------------------>");
}
return moduleList;
} /**
* 文章链接实例 https://www.jianshu.com/p/443219930c5b
* 故此处返回List的String为url后的那段字符串
*
* @param url
* @return
*/
private List<String> getArticleList(String url) { System.out.println("getArticleList: --------------------->"); List<String> keyList = new ArrayList<>(); Document document = null;
try {
document = Jsoup.connect(url).get();
} catch (Exception e) {
e.printStackTrace();
}
Element ulElement = document.select("ul[class=note-list]").first(); Elements elements = ulElement.select("li[id]");
for (Element ele : elements) {
String relUrl = ele.select("a[class=title]").attr("href");
String key = relUrl.substring(relUrl.indexOf("/p/") + 3);
keyList.add(key);
System.out.println(key);
} return keyList;
} }
最后附上实验截图:

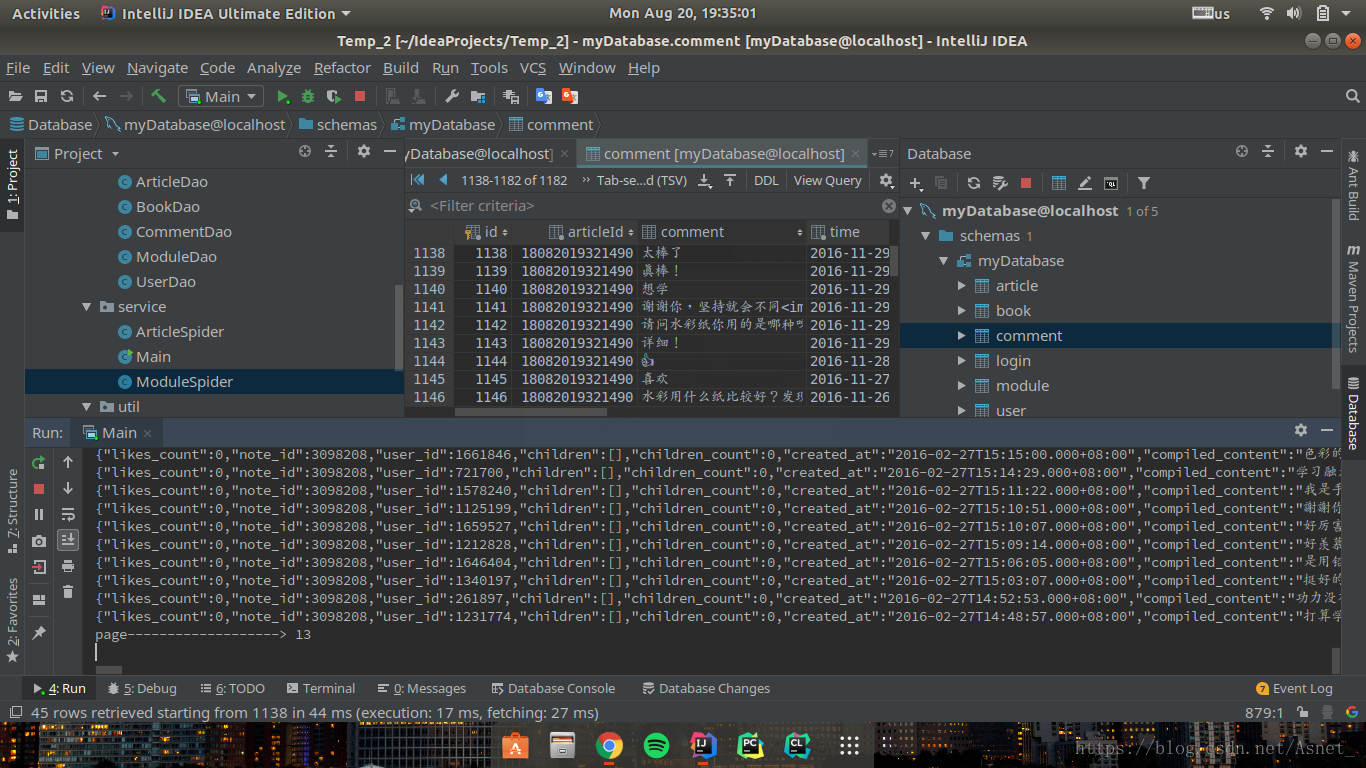
完整项目地址:
https://github.com/apknet/SuperSpider
SuperSpider(简书爬虫JAVA版)的更多相关文章
- jsoup爬虫简书首页数据做个小Demo
代码地址如下:http://www.demodashi.com/demo/11643.html 昨天LZ去面试,遇到一个大牛,被血虐一番,发现自己基础还是很薄弱,对java一些原理掌握的还是不够稳固, ...
- 网页爬虫的设计与实现(Java版)
网页爬虫的设计与实现(Java版) 最近为了练手而且对网页爬虫也挺感兴趣,决定自己写一个网页爬虫程序. 首先看看爬虫都应该有哪些功能. 内容来自(http://www.ibm.com/deve ...
- 《Java核心技术 卷II 高级特性(原书第9版)》
<Java核心技术 卷II 高级特性(原书第9版)> 基本信息 原书名:Core Java Volume II—Advanced Features(Ninth Edition) 作者: ( ...
- Java native代码编译步骤简书
Java native代码编译步骤简书 目的:防止java代码反编译获取密码算法 (1)编写实现类com.godlet.PasswordAuth.java (2)编译java代码javac Passw ...
- 学习PHP爬虫--《Webbots、Spiders和Screen Scrapers:技术解析与应用实践(原书第2版)》
<Webbots.Spiders和Screen Scrapers:技术解析与应用实践(原书第2版)> 译者序 前言 第一部分 基础概念和技术 第1章 本书主要内容3 1.1 发现互联网的真 ...
- [Selenium2+python2.7][Scrap]爬虫和selenium方式下拉滚动条获取简书作者目录并且生成Markdown格式目录
预计阅读时间: 15分钟 环境: win7 + Selenium2.53.6+python2.7 +Firefox 45.2 (具体配置参考 http://www.cnblogs.com/yoyok ...
- Node爬取简书首页文章
Node爬取简书首页文章 博主刚学node,打算写个爬虫练练手,这次的爬虫目标是简书的首页文章 流程分析 使用superagent发送http请求到服务端,获取HTML文本 用cheerio解析获得的 ...
- Python 2.7_发送简书关注的专题作者最新一篇文章及连接到邮件_20161218
最近看简书文章关注了几个专题作者,写的文章都不错,对爬虫和数据分析都写的挺好,因此想到能不能获取最新的文章推送到Ipad网易邮箱大师.邮件发送代码封装成一个函数,从廖雪峰大神那里学的 http:// ...
- PetaPojo —— JAVA版的PetaPoco
背景 由于工作的一些原因,需要从C#转成JAVA.之前PetaPoco用得真是非常舒服,在学习JAVA的过程中熟悉了一下JAVA的数据组件: MyBatis 非常流行,代码生成也很成熟,性能也很好.但 ...
随机推荐
- C#中的线程池使用(二)
线程池是后台线程.每个线程都使用默认的堆栈大小,以默认的优先级运行,并处于多线程单元中.每个进程只有一个线程池对象. 下面说一下线程池中的异常,在线程池中未处理的异常将终止进程.以下为此规则的三种例外 ...
- iTween插件使用
itween插件 itween是一个动画库,作者创建它的目的就是最小的投入实现最大的产出.用它可以轻松实现各种动画,晃动,旋转,移动.褪色.上色.控制音频等. iTween原理: itween的核心是 ...
- passing parameter to an event handler [stackoverflow]
Q: i want to pass my List<string> as parameter using my event public event EventHandler _newFi ...
- CentOS6.5上Zabbix3.0的RPM安装【二】-汉化
六.汉化 zabbix实际是有中文语言的,我们可以通过修改web端源文件来开启中文语言.首先点击zabbix监控页面右上角管理员头像进入“用户基本资料设置页面“. 选择中文语言. 点击“Update” ...
- Hadoop的安装与配置
一.准备环境: 系统:centos6.5 64位 192.168.1.61 master 192.168.1.5 slave 二.在两台服务器上都要配置ssh免密码登录 在192.168. ...
- 与HDFS交互-By shell命令
Shell命令的开头有三种: hadoop fs hadoop dfs hdfs dfs 关于具体命令之前写过 可查看:https://www.cnblogs.com/floakss/p/970344 ...
- Linux_Shell_ Map 的使用和遍历
定义初始化map declare -A map=([") 输出所有key echo ${map[@]} 输出key对应的值 "]} 遍历map for key in ${!map[ ...
- 787. Cheapest Flights Within K Stops
There are n cities connected by m flights. Each fight starts from city u and arrives at v with a pri ...
- (原创)Problem F: WPF的三位数
Description PF哥是一个爱说骚话的骚年,今天他决定要用阿拉伯数字来说骚话,他将1,2,…,9共9个数字分成了三组,分别组成三个三位数,且使这三个三位数构成1:2:3的比例 他要说的骚话就是 ...
- Python 之 装饰器
装饰器 中的“器”代指函数 所以装饰器本质是函数,用来装饰其它函数.例如:为其它函数添加其他功能 实现装饰器需要的知识: 高阶函数+嵌套函数 == 装饰器 1.函数就是“变量” 函数就是“变量”说的 ...