Consumer设计-high/low Level Consumer
1 Producer和Consumer的数据推送拉取方式
Producer Producer通过主动Push的方式将消息发布到Broker n Consumer Consumer通过Pull从Broker消费数据
Push 优势:延时低
劣势:可能造成Consumer来不及处理消息;网络拥塞
Pull 优势:Consumer按实际处理能力获取相应量的数据;Broker实现简单
劣势:如果处理不好,实时性相对不足(例如需要大量不断请求浪费资源,Kafka使用long polling,一次请求无果等待一段时间从而减少请求次数)。
2 High Level Consumer
场景:客户程序只是希望从Kafka顺序读取并处理数据,而不太关心具体的offset。
也希望提供一些语义,例如同一条消息只被某一个Consumer消费(单播)或被所有Consumer消费(广播)。
Kafka High Level API提供了一个从Kafka消费数据的高层抽象,从而屏蔽掉其中的细节,并提供丰富的语义。
(1)Consumer Group 理解consumer group记住下面这三个特性就好了:consumer group下可以有一个或多个consumer instance,consumer instance可以是一个进程,也可以是一个线程;group.id是一个字符串,唯一标识一个consumer group;consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group);
High Level Consumer将从某个Partition读取的最后一条 消息的offset存于Zookeeper中。
这个offset基于客户程序提供给Kafka的名字来保存,这个 名字被称为Consumer Group。
Consumer Group是整个Kafka集群全局唯一的,而非针对某个Topic。
每个High Level Consumer实例都属于一个Consumer Group,若不指定则属于默认的Group。
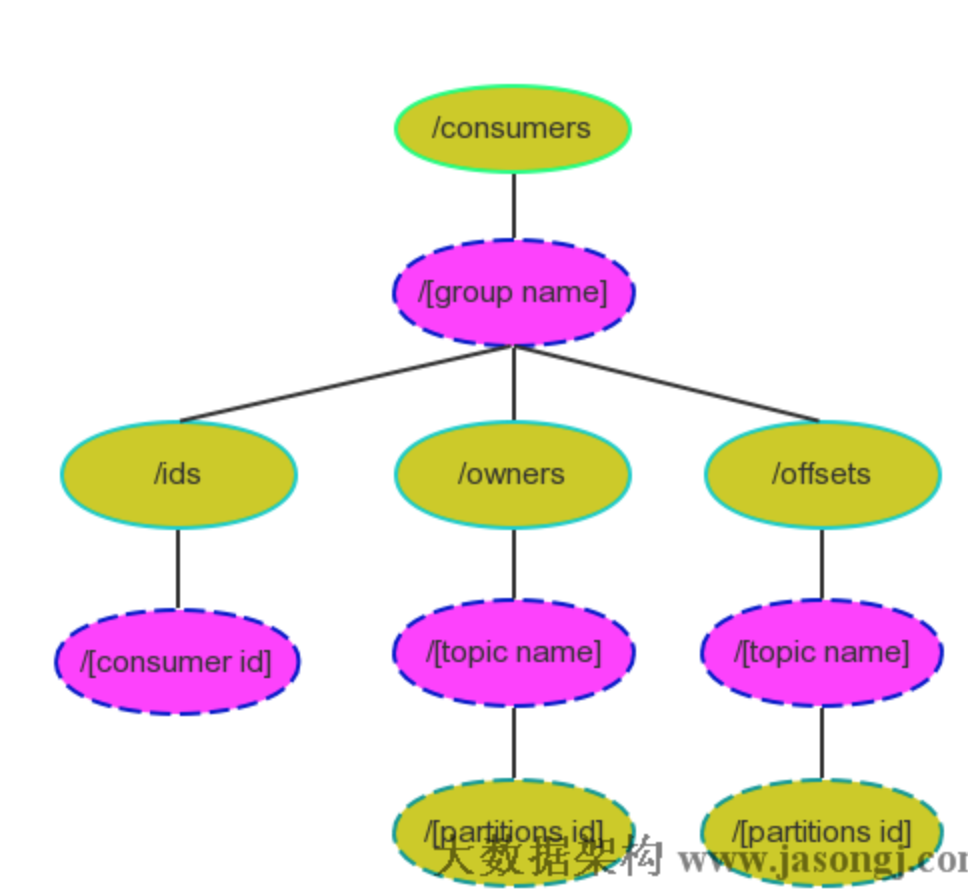
很多传统的Message Queue都会在消息被消费完后将消息删除,一方面避免重复消费,另一方面可以保证Queue的长度比较短,提高效率。kafka会采用两种,
删除(过期或过大)和压缩,压缩如下。
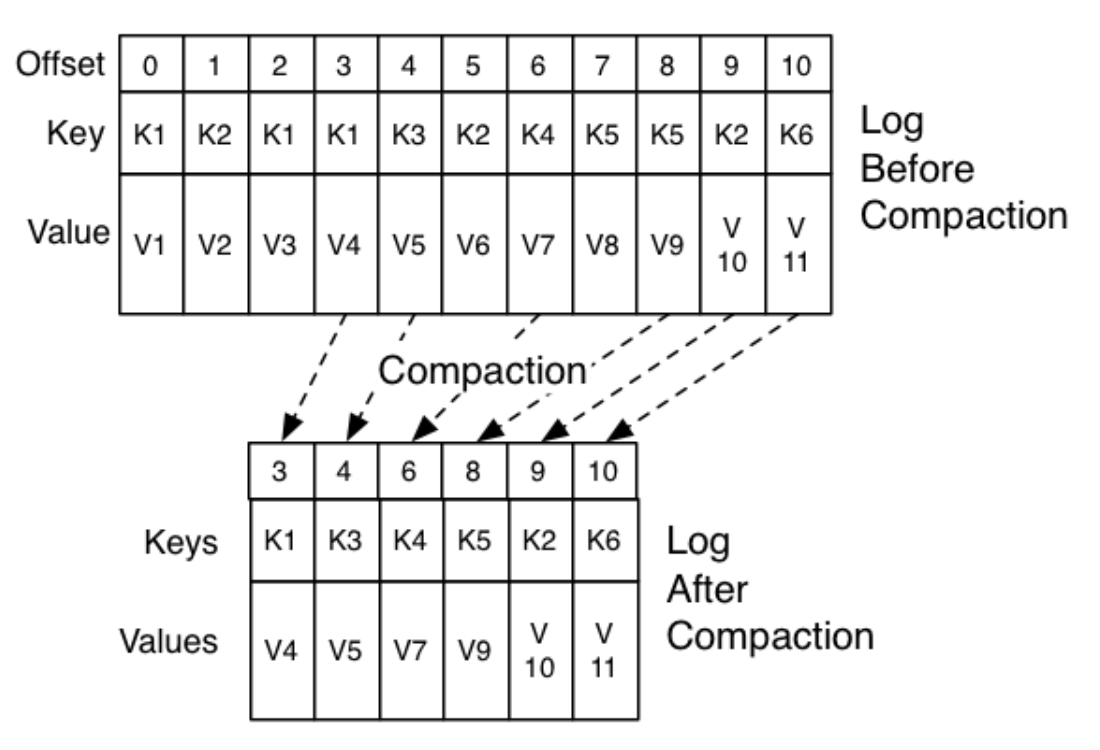
*消息被消费后,并不会被删除,只是相应的offset加一。
*对于每条消息,在同一个Consumer Group里只会被一个Consumer消费
*不同Consumer Group可消费同一条消息 。
(2)High Level Consumer Rebalance
Kafka保证同一Consumer Group中只有一个Consumer会消费某条消息,实际上,Kafka保证的是稳定状态下每一个Consumer实例只会消费某一个或多个特定Partition的数据,而某个Partition的数据只会被某一个特定的Consumer实例所消费。也就是说Kafka对消息的分配是以Partition为单位分配的,而非以每一条消息作为分配单元。这样设计的劣势是无法保证同一个Consumer Group里的Consumer均匀消费数据,优势是每个Consumer不用都跟大量的Broker通信,减少通信开销,同时也降低了分配难度,实现也更简单。另外,因为同一个Partition里的数据是有序的,这种设计可以保证每个Partition里的数据可以被有序消费。
如果某Consumer Group中Consumer(每个Consumer只创建1个MessageStream)数量少于Partition数量,则至少有一个Consumer会消费多个Partition的数据,如果Consumer的数量与Partition数量相同,则正好一个Consumer消费一个Partition的数据。而如果Consumer的数量多于Partition的数量时,会有部分Consumer无法消费该Topic下任何一条消息。
Consumer Rebalance算法
将目标Topic下的所有Partirtion排序,存于PT
对某Consumer Group下所有Consumer排序,存于CG,
第i个Consumer记为Ci
N=size(PT)/size(CG) ,向上取整
解除Ci对原来分配的Partition的消费权(i从0开始)
将第 i∗N 到(i+1)∗N−1个Partition分配给Ci
在这种策略下,每一个Consumer或者Broker的增加或者减少都会触发Consumer Rebalance。因为每个Consumer只负责调整自己所消费的Partition,为了保证整个Consumer Group的一致性,当一个Consumer触发了Rebalance时,该Consumer Group内的其它所有其它Consumer也应该同时触发Rebalance。因此有以下缺点
Herd effect:任何Broker或者Consumer的增减都会触发所有的Consumer的Rebalance
Split Brain:每个Consumer分别单独通过Zookeeper判断哪些Broker和Consumer 宕机了,那么不同Consumer在同一时刻从Zookeeper“看”到的View就可能不一样,这是由Zookeeper的特性决定的,这就会造成不正确的Reblance尝试。
调整结果不可控:所有的Consumer都并不知道其它Consumer的Rebalance是否成功,这可能会导致Kafka工作在一个不正确的状态。
0.9以后的版本,提供了coordinator来解决上述缺点。
3 coordinator 和Rebalance
新consumer加入组、已有consumer主动离开组或已有consumer崩溃的时候,会触发rebalance。每个consumer group都会被分配一个这样的coordinator用于组管理和位移管理。这个group coordinator比原来承担了更多的责任,比如组成员管理、位移提交保护机制等。当新版本consumer group的第一个consumer启动的时候,它会去和kafka server确定谁是它们组的coordinator。之后该group内的所有成员都会和该coordinator进行协调通信。这种coordinator设计不再需要zookeeper了,性能上可以得到很大的提升。
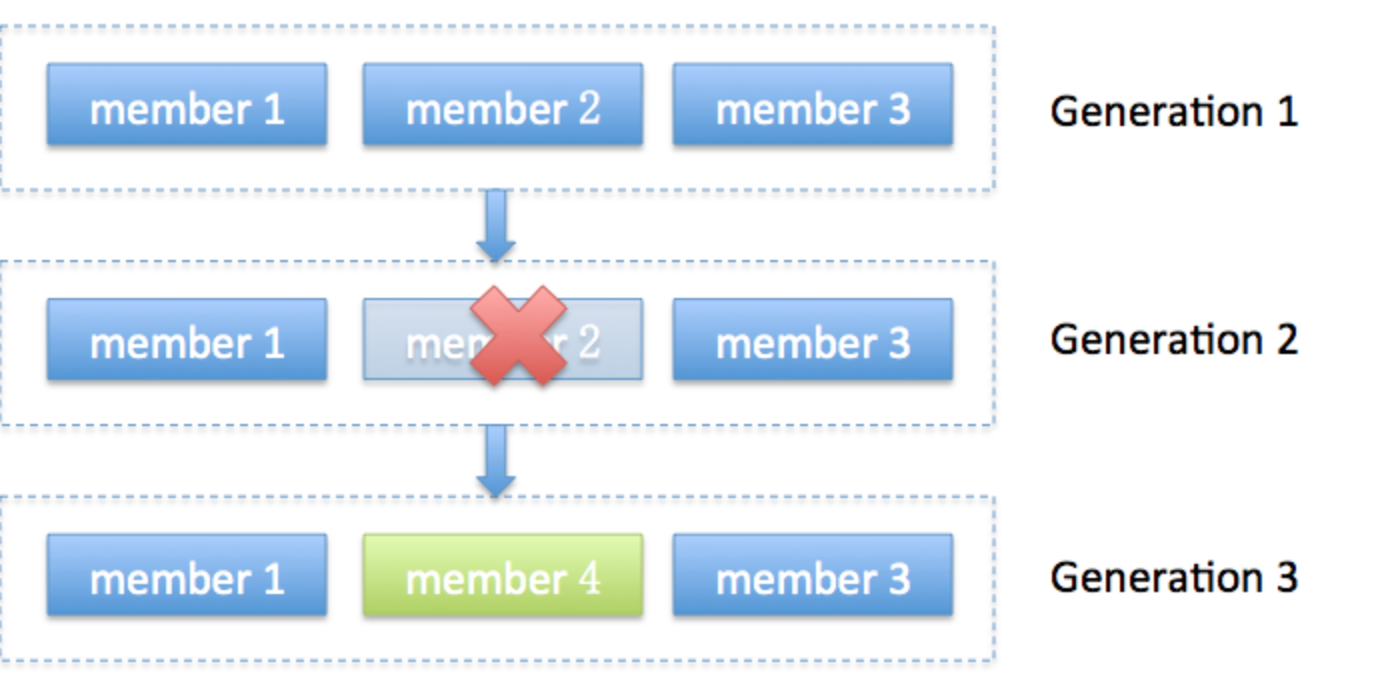
* generation:它表示了rebalance之后的一代成员,主要是用于保护consumer group,隔离无效offset提交的。比如上一代的consumer成员是无法提交位移到新一届的consumer group中。有时候报ILLEGAL_GENERATION的错误就是代错误。每次group进行rebalance之后,generation号都会加1,表示group进入到了一个新的版本,如下图所示: Generation 1时group有3个成员,随后成员2退出组,coordinator触发rebalance,consumer group进入Generation 2,之后成员4加入,再次触发rebalance,group进入Generation 3。
* 协议 :rebalance本质上是一组协议。group与coordinator共同使用它来完成group的rebalance。目前kafka提供了5个协议来处理与consumer group coordination相关的问题。
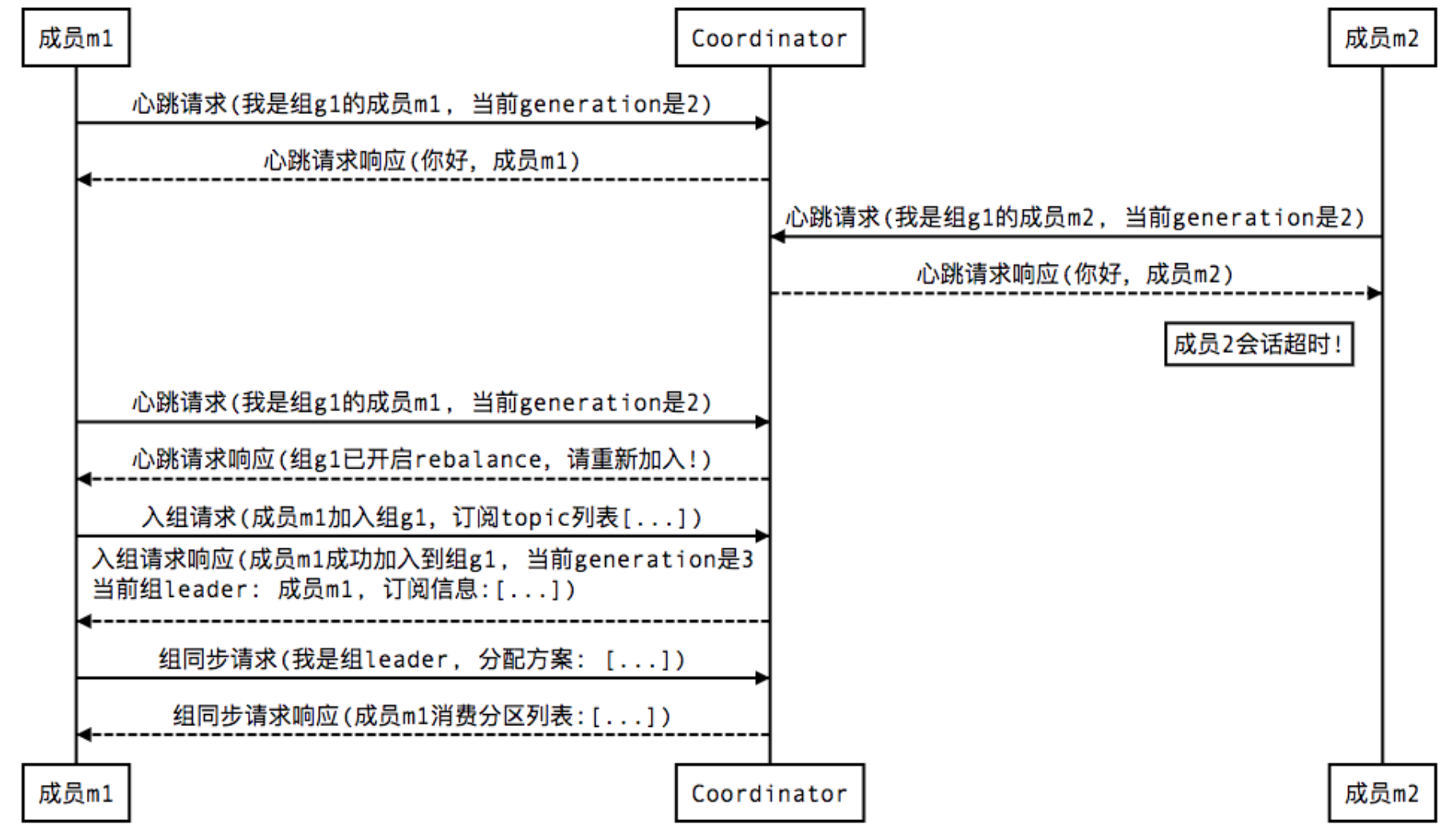
Heartbeat请求:consumer需要定期给coordinator发送心跳来表明自己还活着
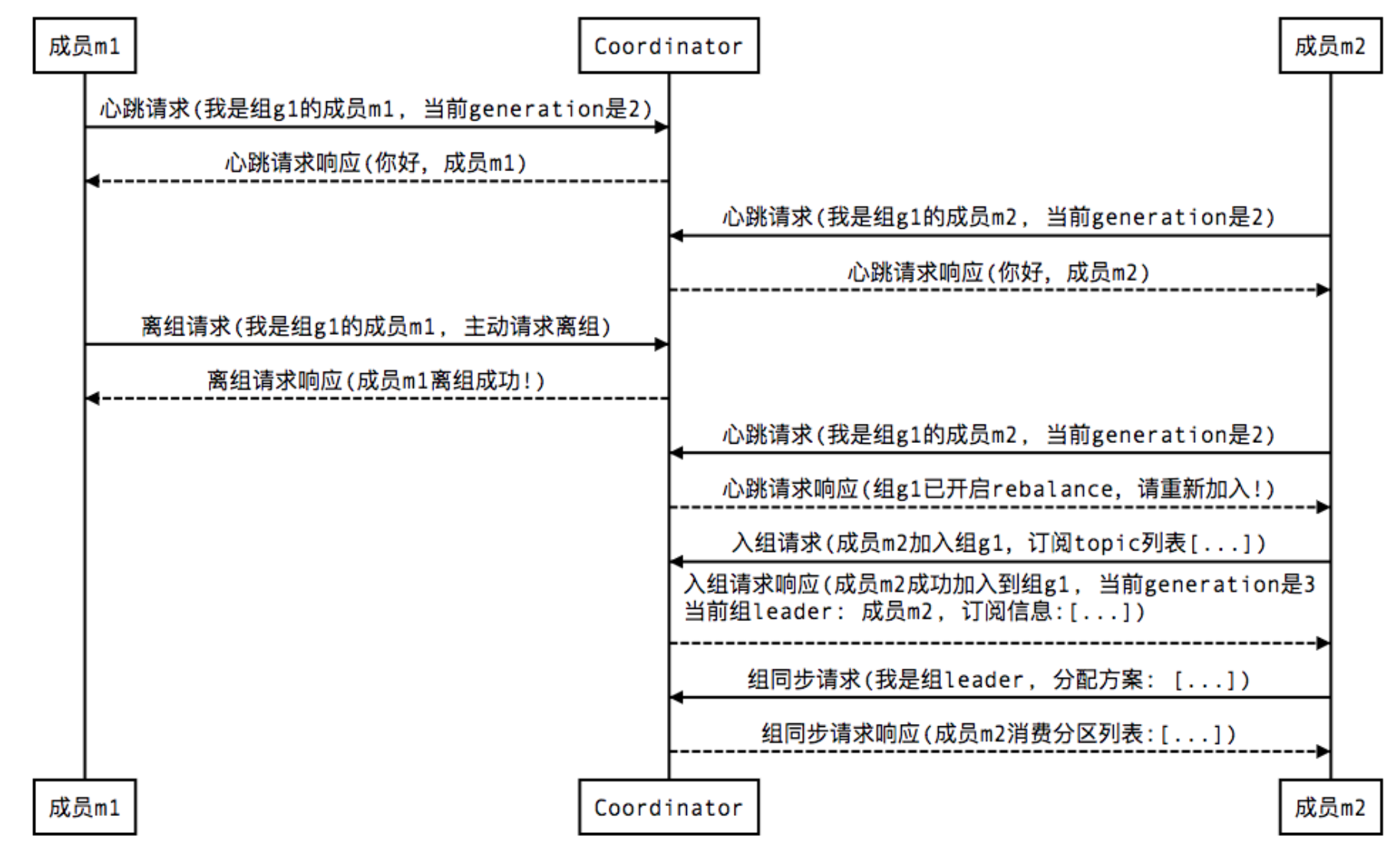
LeaveGroup请求:主动告诉coordinator我要离开consumer group
SyncGroup请求:group leader把分配方案告诉组内所有成员
JoinGroup请求:成员请求加入组
DescribeGroup请求:显示组的所有信息,包括成员信息,协议名称,分配方案,订阅信息等。通常该请求是给管理员使用。
* 状态:和很多kafka组件一样,group也做了个状态机来表明组状态的流转。coordinator根据这个状态机会对consumer group做不同的处理,如下
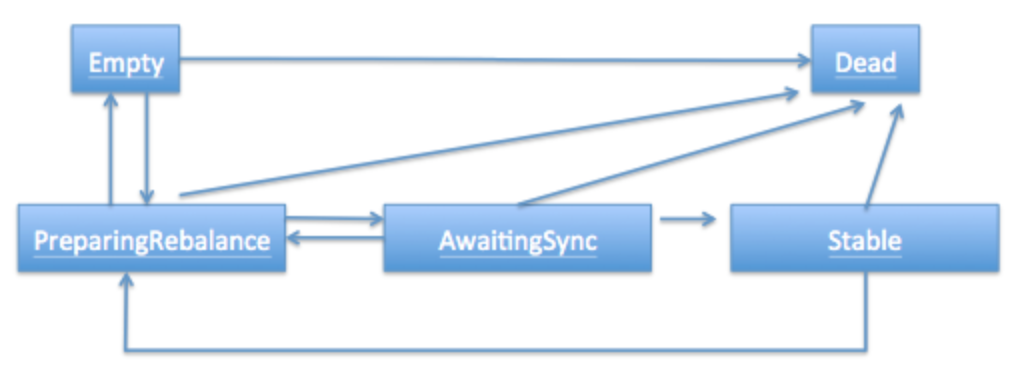
Dead:组内已经没有任何成员的最终状态,组的元数据也已经被coordinator移除了。这种状态响应各种请求都是一个response: UNKNOWN_MEMBER_ID
Empty:组内无成员,但是位移信息还没有过期。这种状态只能响应JoinGroup请求
PreparingRebalance:组准备开启新的rebalance,等待成员加入
AwaitingSync:正在等待leader consumer将分配方案传给各个成员
Stable:rebalance完成可以开始消费
* 过程 :加入,移除,崩溃几种图如下
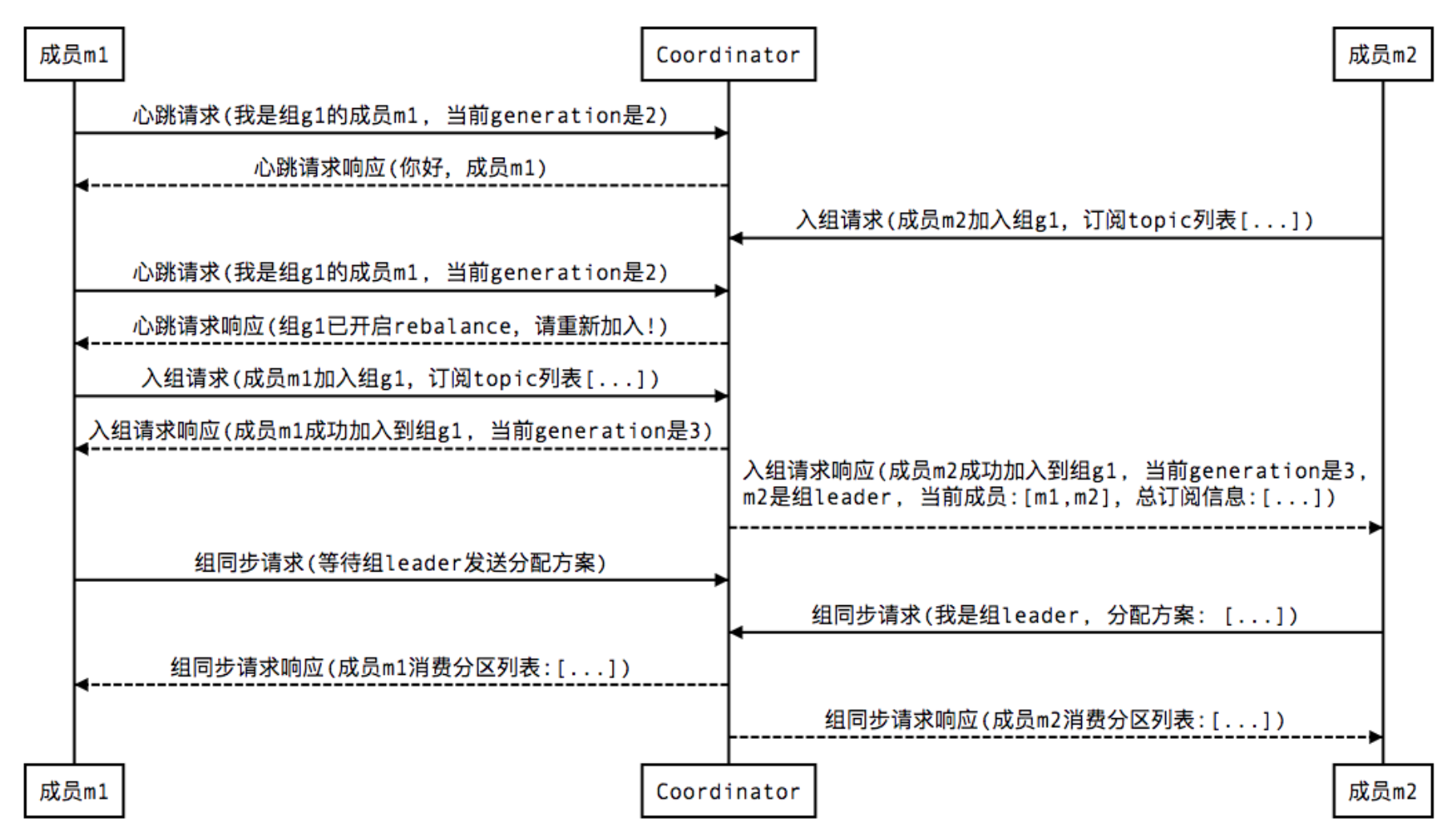
1 Join, 顾名思义就是加入组。这一步中,所有成员都向coordinator发送JoinGroup请求,请求入组。一旦所有成员都发送了JoinGroup请求,coordinator会从中选择一个consumer担任leader的角色,并把组成员信息以及订阅信息发给leader——注意leader和coordinator不是一个概念。leader负责消费分配方案的制定。
2 Sync,这一步leader开始分配消费方案,即哪个consumer负责消费哪些topic的哪些partition。一旦完成分配,leader会将这个方案封装进SyncGroup请求中发给coordinator,非leader也会发SyncGroup请求,只是内容为空。coordinator接收到分配方案之后会把方案塞进SyncGroup的response中发给各个consumer。这样组内的所有成员就都知道自己应该消费哪些分区了。
新增consumer:
移除consumer:
consumer崩掉:
参考:https://www.cnblogs.com/byrhuangqiang/p/6384986.html,https://www.cnblogs.com/huxi2b/p/6223228.html,http://www.jasongj.com/2015/08/09/KafkaColumn4/
4 low consumer
使用Low Level Consumer (Simple Consumer)的主要原因是,用户希望比Consumer Group更好的控制数据的消费, 如
*同一条消息读多次,方便Replay
*只消费某个Topic的部分Partition
*管理事务,从而确保每条消息被处理一次(Exactly once)
*与High Level Consumer相对,Low Level Consumer要求用户做大量的额外工作
*在应用程序中跟踪处理offset,并决定下一条消费哪条消息
*获知每个Partition的Leader
*处理Leader的变化
*处理多Consumer的协作
Consumer设计-high/low Level Consumer的更多相关文章
- Kafka设计解析(四)- Kafka Consumer设计解析
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/08/09/KafkaColumn4 摘要 本文主要介绍了Kafka High Level Con ...
- Kafka设计解析(四)Kafka Consumer设计解析
转载自 技术世界,原文链接 Kafka设计解析(四)- Kafka Consumer设计解析 目录 一.High Level Consumer 1. Consumer Group 2. High Le ...
- Kafka学习笔记之Kafka Consumer设计解析
0x00 摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以 ...
- Kafka 0.8 Consumer设计解析
摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以及适用场景 ...
- 设计Kafka的High Level Consumer
原文:https://cwiki.apache.org/confluence/display/KAFKA/Consumer+Group+Example 为什么使用High Level Consumer ...
- Kafka 学习笔记之 High Level Consumer相关参数
High Level Consumer相关参数 自动管理offset auto.commit.enable = true auto.commit.interval.ms = 60*1000 手动管理o ...
- Solr实现Low Level查询解析(QParser)
Solr实现Low Level查询解析(QParser) Solr基于Lucene提供了方便的查询解析和搜索服务器的功能,可以以插件的方式集成,非常容易的扩展我们自己需要的查询解析方式.其中,Solr ...
- C++ Low level performance optimize
C++ Low level performance optimize 1. May I have 1 bit ? 下面两段代码,哪一个占用空间更少,那个速度更快?思考10秒再继续往下看:) //v1 ...
- C++ Low level performance optimize 2
C++ Low level performance optimize 2 上一篇 文章讨论了一些底层代码的优化技巧,本文继续讨论一些相关的内容. 首先,上一篇文章讨论cache missing的重要性 ...
随机推荐
- phalcon:整合官方多模块功能,方便多表查询
phalcon:整合官方多模块功能,方便多表查询 项目分为: namespace Multiple\Backend; namespace Multiple\Frontend; 目录结构如下: publ ...
- hdu 2490 队列优化dp
http://acm.hdu.edu.cn/showproblem.php?pid=2490 Parade Time Limit: 4000/2000 MS (Java/Others) Memo ...
- Android中如何禁止音量调节至静音
Android中音量按键在调低音量时,如果一直按住Down按钮不放,则系统将音量跳到最小后,又自动调节到静音状态.这个机制和iPhone是不同的,iPhone中无论你怎么按Volume-按钮,只能调到 ...
- url参数的编码解码Demo
为了保证在页面传递数据的安全性,我们通常会对Url传递的参数进行编码解码操作.我们写一个Demo剖析URL编码解码过程. 完整Demo下载地址 1. Url参数如何在服务端进行编码和解码. 1.1 U ...
- [独孤九剑]Oracle知识点梳理(十)%type与%rowtype及常用函数
本系列链接导航: [独孤九剑]Oracle知识点梳理(一)表空间.用户 [独孤九剑]Oracle知识点梳理(二)数据库的连接 [独孤九剑]Oracle知识点梳理(三)导入.导出 [独孤九剑]Oracl ...
- 【LeetCode】075. Sort Colors
Given an array with n objects colored red, white or blue, sort them so that objects of the same colo ...
- 二、python沉淀之路~~字符串属性(str)
1.capitalize的用法:即将输出字符串首字母大写 test = "heLLo" v = test.capitalize() print(v) 结果:Hello. 2.cas ...
- Js中的prototype的用法一
一 prototype介绍 prototype对象是实现面向对象的一个重要机制.每个函数也是一个对象,它们对应的类就是function,每个函数对象都具有一个子对象prototype.Prototyp ...
- mysql之 [ERROR] InnoDB: Unable to lock ./ibdata1, error: 11
问题描述:启动MySQL后,出现连接不上,报 [ERROR] InnoDB: Unable to lock ./ibdata1, error: 11[root@mysql01 ~]# service ...
- tyvj 2054 [Nescafé29]四叶草魔杖——最小生成树+状压dp
题目:http://www.joyoi.cn/problem/tyvj-2054 枚举点集,如果其和为0,则作为一个独立的块求一下最小生成树.因为它可以不和别的块连边. 然后状压dp即可. 别忘了判断 ...