Hadoop中Writable类之三
1.BytesWritable
<1>定义
ByteWritable是对二进制数据组的封装。它的序列化格式为一个用于指定后面数据字节数的整数域(4个字节),后跟字节本身。
举个例子,假如有一个数组bytes,里面有两个byte,bytes[0]=3,bytes[1]=5,那么,数组序列化后,其返回一个字节数组,序列化方面,可以查看我的博客《Hadoop序列化》 ,那么序列化后,其返回一个字节书组byteSeri,byteSeri里面有多少个字节?
分析:
在定义里指出,序列化格式为一个整数域和字节本身,
- 整数域是用来指定后面数据的字节数,我们知道byte[0],和byte[1]是两个字节,所以,整数域的二进制为:00000000 00000000 00000000 00000010(4个字节),以16进制表示:00 00 00 02
- 字节本身就是byte[0]和byte[1]这两个字节,所以,字节本身的二进制表示为:00000011 00000101,以16进制表示为:03 05
- 整个序列化数组的二进制表示为:00000000 00000000 00000000 00000010 00000011 00000101 ,以16进制表示为:00 00 00 02 03 05
那么上述的序列化后数组的长度为字节的个数,也就是 4 + 2 =6;拿例子来验证:
Example:
package cn.roboson.writable; import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException; import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.StringUtils; /**
* 1.定义一个二进制字节数组
* 2.将其序列化
* 3.由其序列化格式分析其内容
* @author roboson
*
*/ public class WritableText05 { public static void main(String[] args) throws IOException {
//定义一个二进制字节数组
BytesWritable b = new BytesWritable(new byte[]{3,5}); //输出其长度,很明显,只有两个字节,其长度肯定是2
System.out.println("二进制数组的长度:"+b.getLength()); //将其序列化,序列化可以查看我的博客《Hadoop序列化》
byte[] bytes=serialize(b);
//在上面的分析中,16进制的输出为:00 00 00 02 03 05
System.out.println("序列化后以16进制表示:"+StringUtils.byteToHexString(bytes)); //在上面的分析中,序列化后的数组长度为:6
System.out.println("序列化后的长度:"+bytes.length);
} public static byte[] serialize(Writable writable) throws IOException{
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
writable.write(dataOut);
return out.toByteArray(); }
}
运行结果:

<2>可变性
和Text相似,BytesWritable是可变的,可以通过set()方法,设置进行修改。BytesWritable的getBytes()方法,返回的是字节数组的容量,而其存储数据的实际大小,需要通过getLong()方法来查看
Example:
package cn.roboson.writable;
import org.apache.hadoop.io.BytesWritable;
public class WritableText06 {
public static void main(String[] args) {
BytesWritable b = new BytesWritable(new byte[]{3,5});
System.out.println("字节数组的实际数据长度:"+b.getLength());
System.out.println("字节数组的容量大小:"+b.getBytes().length);
//改变其容量
b.setCapacity(11);
//getLength()方法,返回的是实际数据的大小
System.out.println("改变容量后实际数据的大小:"+b.getLength());
//getBytes().length返回的是容量大小
System.out.println("改变容量后容量的大小:"+b.getBytes().length);
}
}
运行结果:

2.NullWritable
NullWritable是Writable的一个特殊类型,它的序列化长度为0.它并不从数据流中读取数据,也不写入数据。它充当占位符;在MapReduce中,如果不需要使用健或者值,就可以将健或者值声明为NullWritable——结果是存储常量空值。
NullWritable是一个单例实例类型,可以通过静态方法get()获得其实例,public static NullWritable get() ;
Example:
package cn.roboson.writable; import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Writable;
/**
* 1.获得一个NullWritable
* 2.序列化后,查看其长度
* @author roboson
*
*/ public class Writable02 { public static void main(String[] args) throws IOException { NullWritable writable = NullWritable.get();
byte[] bytes = serialize(writable);
System.out.println("NullWritable序列化后的长度:"+bytes.length);
} public static byte[] serialize(Writable writable) throws IOException{
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
writable.write(dataOut);
return out.toByteArray(); }
}
运行结果:

3.ObjectWritable
ObjectWritable是对Java基本类型(String、enum,Writable,null或这些类型组成的数组)的通用封装。在Hadoop RPC中用于对方法的参数和返回类型进行封装和解封装。当一个字段中包含多个类型时,ObjectWritable是非常有用的,可以直接将类型声明为ObjectWritable,但是,缺陷是非常浪费空间。举个例子来看看,就知道有多么浪费!
Example:
package cn.roboson.writable; import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException; import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.ObjectWritable;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.StringUtils; /**
* 1.新建一个ObjectWritable
* 2.将其序列化并查看其大小
* @author roboson
*
*/
public class Writable03 { public static void main(String[] args) throws IOException { BytesWritable bytes = new BytesWritable(new byte[]{3,5});
byte[] byte1 = serialize(bytes);
//前面的介绍,可以知道,长度为6
System.out.println("bytes数组序列化后的长度:"+byte1.length);
System.out.println("bytes数组序列化的16进制表示:"+StringUtils.byteToHexString(byte1)); ObjectWritable object = new ObjectWritable();
object.set(new byte[]{3,5});
byte[] byte2 = serialize(object);
System.out.println("ObjectWritable序列化后的长度:"+byte2.length);
System.out.println("ObjectWritable列化的16进制表示:"+StringUtils.byteToHexString(byte2));
} public static byte[] serialize(Writable writable) throws IOException{
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
writable.write(dataOut);
return out.toByteArray(); }
}
运行结果:

4.GenericWritable
通过上面的运行结果,已经知道ObjectWritable类是非常浪费空间的,如果封装的类型数量比较少,这种情况下,可以用GenericWritable类来代替。它的效率更高一些。因为对序列化后的类型的引用加入位置索引。查看HadoopAPI帮助文档,发现GenericWritable是一个抽象类:
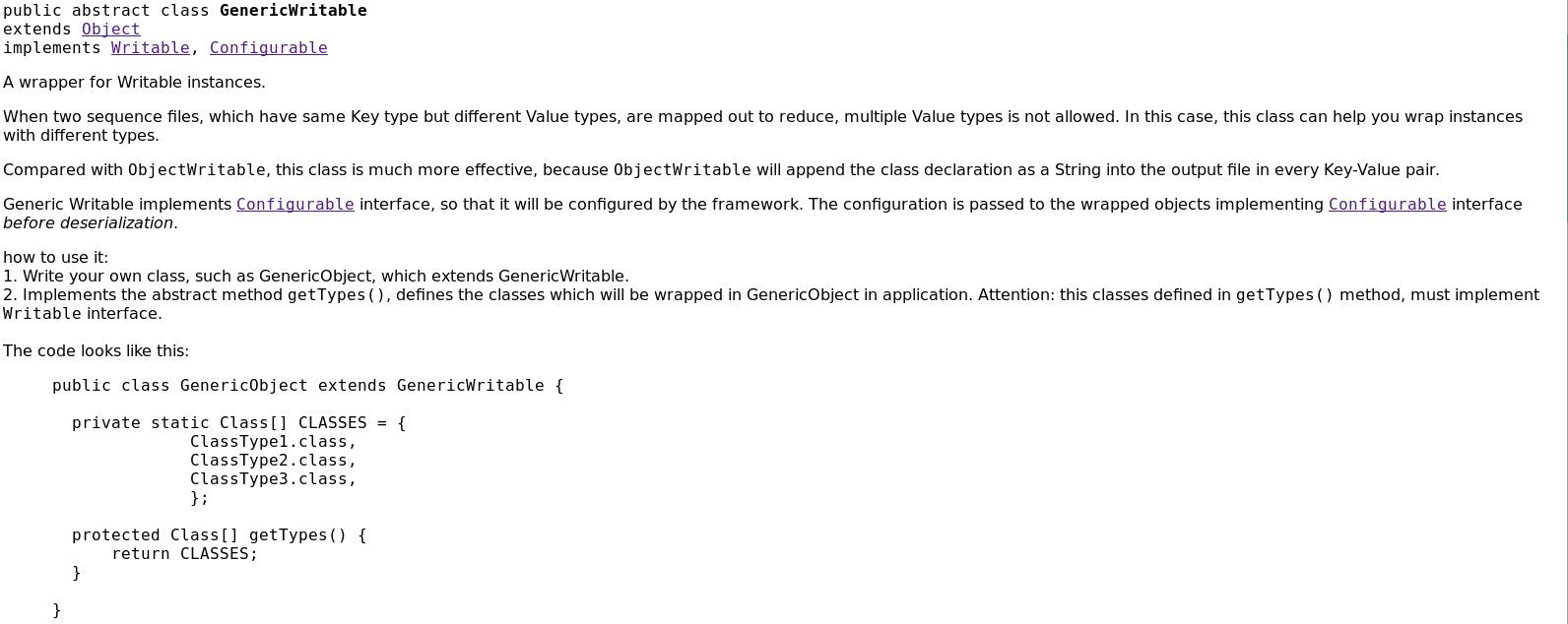
那么如何使用它:
- 写一个类,继承自GenericWritable
- 重写getTypes()方法
- 指定静态类型数组中的值
Example:
MyGenericWritable.java
package cn.roboson.writable; import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.GenericWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable; public class MyGenericWritable extends GenericWritable{ private static Class[] CLASSES={
Text.class,
BytesWritable.class,
IntWritable.class
};
@Override
protected Class<? extends Writable>[] getTypes() {
// TODO Auto-generated method stub
return CLASSES;
} }
Writable04.java
package cn.roboson.writable; import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException; import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.StringUtils; public class Writable04 { public static void main(String[] args) throws IOException { Text t = new Text("Hadoop");
byte[] byte0 = serialize(t);
System.out.println("Text序列化后的长度:"+byte0.length);
System.out.println("Text序列化的16进制表示:"+StringUtils.byteToHexString(byte0)); MyGenericWritable genericText = new MyGenericWritable();
genericText.set(t);
byte[] byteText = serialize(genericText);
System.out.println("TextGenericWritable序列化后的长度:"+byteText.length);
System.out.println("TextGenericWritable列化的16进制表示:"+StringUtils.byteToHexString(byteText)); BytesWritable bytes = new BytesWritable(new byte[]{3,5});
byte[] byte1 = serialize(bytes);
//前面的介绍,可以知道,长度为6
System.out.println("bytes数组序列化后的长度:"+byte1.length);
System.out.println("bytes数组序列化的16进制表示:"+StringUtils.byteToHexString(byte1)); MyGenericWritable generic = new MyGenericWritable();
generic.set(bytes);
byte[] byteBytes = serialize(generic);
System.out.println("GenericWritable序列化后的长度:"+byteBytes.length);
System.out.println("GenericWritable列化的16进制表示:"+StringUtils.byteToHexString(byteBytes)); IntWritable intWritable = new IntWritable(2);
byte[] byte2 = serialize(intWritable);
System.out.println("IntWritable序列化后的长度:"+byte2.length);
System.out.println("IntWritable序列化的16进制表示:"+StringUtils.byteToHexString(byte2)); MyGenericWritable genericInt = new MyGenericWritable();
genericInt.set(intWritable);
byte[] byteInt = serialize(genericInt);
System.out.println("IntGenericWritable序列化后的长度:"+byteInt.length);
System.out.println("IntGenericWritable列化的16进制表示:"+StringUtils.byteToHexString(byteInt)); }
public static byte[] serialize(Writable writable) throws IOException{
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
writable.write(dataOut);
return out.toByteArray(); }
}
运行结果:

可以发现,GenericWritable比ObjectWritable更节省空间,和本来的相比,只增加了一个字节,并且这个字节是其在静态数组CLASSES的下标号!
Hadoop中Writable类之三的更多相关文章
- Hadoop中Writable类之四
1.定制Writable类型 Hadoop中有一套Writable实现,例如:IntWritable.Text等,但是,有时候可能并不能满足自己的需求,这个时候,就需要自己定制Writable类型. ...
- Hadoop中Writable类之二
1.ASCII.Unicode.UFT-8 在看Text类型的时候,里面出现了上面三种编码,先看看这三种编码: ASCII是基于拉丁字母的一套电脑编码系统.它主要用于显示现代英语和其他西欧语言.它是现 ...
- Hadoop中Writable类
1.Writable简单介绍 在前面的博客中,经常出现IntWritable,ByteWritable.....光从字面上,就可以看出,给人的感觉是基本数据类型 和 序列化!在Hadoop中自带的or ...
- hadoop中Text类 与 java中String类的区别
hadoop 中 的Text类与java中的String类感觉上用法是相似的,但两者在编码格式和访问方式上还是有些差别的,要说明这个问题,首先得了解几个概念: 字符集: 是一个系统支持的所有抽象字符的 ...
- hadoop中典型Writable类详解
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable.html,转载请注明源地址. Hadoop将很多Writable类归入org.apac ...
- hadoop中实现定制Writable类
Hadoop中有一套Writable实现可以满足大部分需求,但是在有些情况下,我们需要根据自己的需要构造一个新的实现,有了定制的Writable,我们就可以完全控制二进制表示和排序顺序. 为了演示如何 ...
- hadoop中的序列化与Writable类
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-class.html,转载请注明源地址. hadoop中自带的org.apache.h ...
- hadoop中的序列化与Writable接口
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable-interface.html,转载请注明源地址. 简介 序列化和反序列化就是结构化对象 ...
- Hadoop中序列化与Writable接口
学习笔记,整理自<Hadoop权威指南 第3版> 一.序列化 序列化:序列化是将 内存 中的结构化数据 转化为 能在网络上传输 或 磁盘中进行永久保存的二进制流的过程:反序列化:序列化的逆 ...
随机推荐
- Python yield详解***
yield的英文单词意思是生产,有时候感到非常困惑,一直没弄明白yield的用法. 只是粗略的知道yield可以用来为一个函数返回值塞数据,比如下面的例子: def addlist(alist): f ...
- WebService返回json格式数据供苹果或者安卓程序调用
1.新建一个WebService. 2. /// <summary> /// DemoToJson 的摘要说明 /// </summary> [WebService(Names ...
- HDU 1251 统计难题(字典树)
统计难题 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131070/65535 K (Java/Others)Total Submi ...
- Train-Alypay-Cloud:蚂蚁大数据平台培训开课通知(第三次)
ylbtech-Train-Alypay-Cloud:蚂蚁大数据平台培训开课通知(第三次) 1.返回顶部 1. 您好! 很高兴通知您,您已经成功报名将于蚂蚁金服计划在2018年2月28日- 2018年 ...
- [Android] 开发第十一天
MainActivity.java 代码如下: package com.oazzz.test9; import android.support.annotation.Nullable; import ...
- 揭秘 Python 中的 enumerate() 函数
原文:https://mp.weixin.qq.com/s/Jm7YiCA20RDSTrF4dHeykQ 如何以去写以及为什么你应该使用Python中的内置枚举函数来编写更干净更加Pythonic的循 ...
- Python 数据处理库 pandas
核心数据结构 pandas最核心的就是Series和DataFrame两个数据结构. 名称 维度 说明 Series 1维 带有标签的同构类型数组 DataFrame 2维 表格结构,带有标签,大小可 ...
- usaco 2009 12 过路费
最近学的图论,oj上的这道题卡了我一上午,写一下总结. 题目描述: 跟所有人一样,农夫约翰以着宁教我负天下牛,休教天下牛负我(原文:宁我负人,休教人负我)的伟大精神,日日夜夜苦思生财之道.为了发财,他 ...
- linux centos 6.1 安装 redis
1, yum install redis 检测是否有redis 2,没有的话就运行:yum install epel-release 3,再执行 yum install redis
- mybatis 错误: There is no getter for property named '*' in 'class java.lang.String解决
现象: mybatis mapper.xml 的sql里如果直接使用了想要传入的变量,比如: <select id="selectXx" resultType="i ...