Python爬虫之XML
一、请求参数形式为xml
举例说明。
现在有这样一个网址:https://www.runff.com/html/live/s1484.html;想要查询图片列表,打开F12,观察到请求如下:
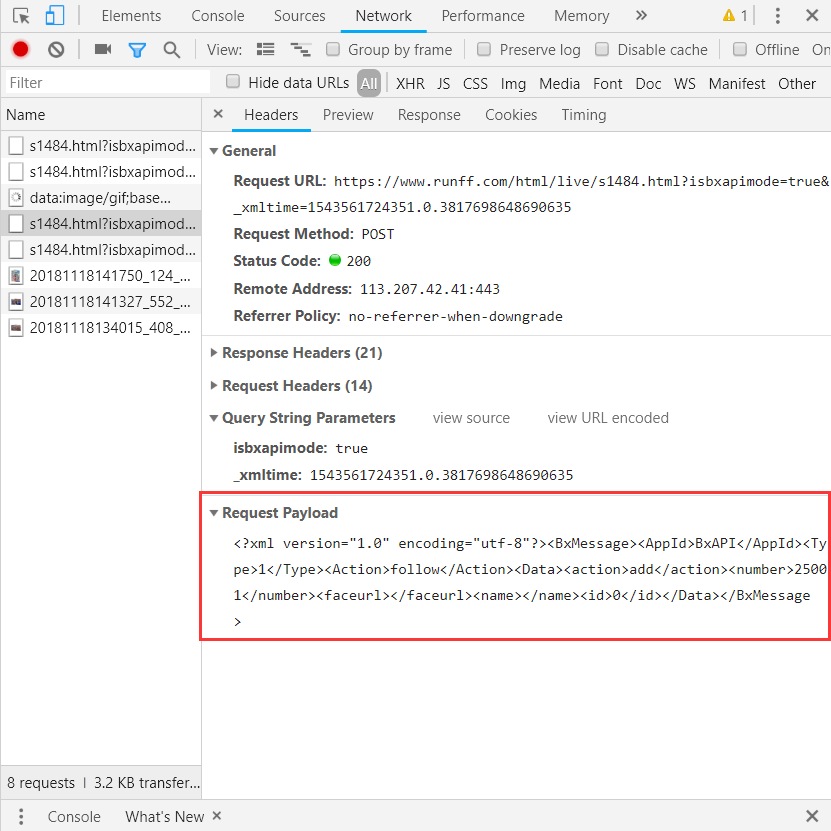
这里的请求参数形式为xml,使用python模仿请求的代码这样写
import requests fid = 3748813
bib = 25001 url = "https://www.runff.com/html/live/s1484.html"
params = {
"isbxapimode": "true",
"_xmltime": "1543561724351.0.3817698648690635"
}
headers = {
"cookie": "ASP.NET_SessionId=hb30jkbmqnfwyhjo0iqrrkdi",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36",
}
payload = '<?xml version="1.0" encoding="utf-8"?><BxMessage><AppId>BxAPI</AppId><Type>1</Type>' \
'<Action>getPhotoList</Action><Data><fid>{}</fid>' \
'<number>{}</number><minpid>0</minpid>' \
'<time>Wed Nov 21 2018 14:21:42 GMT+0800 (中国标准时间)</time><sign>false</sign>' \
'<pagesize>100</pagesize></Data></BxMessage>'.format(fid, bib)
payload = payload.encode('utf-8')
r = requests.post(url, headers=headers, params=params, data=payload, timeout=3)
print(r.content.decode('utf-8'))
这里主要使用了post方法,将xml的参数直接以字符串的形式传给post的‘data’参数。
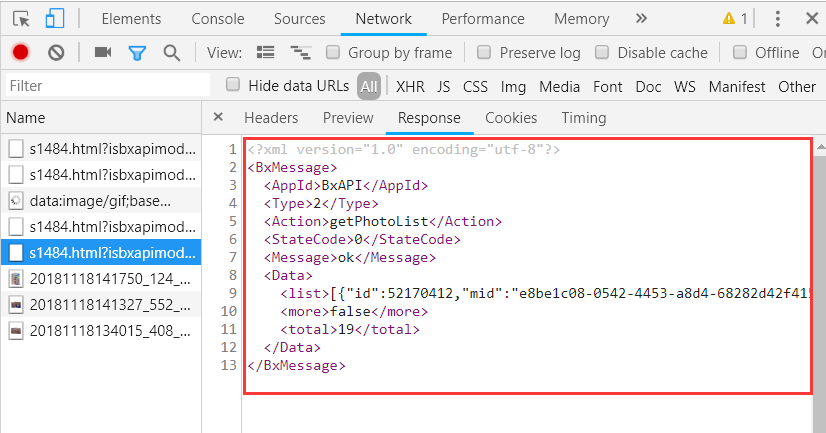
可以看到我们返回内容也是xml。这个时候就需要解析xml。
二、xml解析
xml原文(与上文的请求返回结果无关):
<?xml version="1.0" encoding="utf-8"?>
<BxMessage>
<AppId>BxAPI</AppId>
<Type>2</Type>
<Action>getPhotoList</Action>
<StateCode>2</StateCode>
<Message index="">请先登录</Message>
<Message index="">ok</Message>
<Data></Data>
</BxMessage>
1.直接转成json处理
使用 xmltodict 库
代码:
from xmltodict import parse xml = '<?xml version="1.0" encoding="utf-8"?><BxMessage><AppId>BxAPI</AppId><Type>2</Type>' \
'<Action>getPhotoList</Action><StateCode>2</StateCode><Message index="0">请先登录</Message>' \
'<Message index="1">ok</Message><Data></Data></BxMessage>' data = parse(xml) # 解析xml为有序字典
print(data)
box = data.get('BxMessage', {}) # 获取最外层的标签
app_id = box.get('AppId') # 获取次外层的标签
print(app_id) msg = box.get('Message', []) # 多个标签名相同时,获取到的是标签列表
for m in msg:
print(m.get('@index')) # 获取属性,使用'@'前缀
print(m.get('#text')) # 获取标签文本,使用'#text'
输出:
OrderedDict([('BxMessage', OrderedDict([('AppId', 'BxAPI'), ('Type', ''), ('Action', 'getPhotoList'), ('StateCode', ''), ('Message', [OrderedDict([('@index', ''), ('#text', '请先登录')]), OrderedDict([('@index', ''), ('#text', 'ok')])]), ('Data', None)]))])
BxAPI
0
请先登录
1
ok
输出的是有序字典,取值可以和字典一样使用“get”。
假设有多个相同标签,转换成字典时,会将相同关键字的值组成一个列表。
2.直接解析xml
使用上文中的xml
简要解析代码:
from xml.etree import ElementTree xml = '<?xml version="1.0" encoding="utf-8"?><BxMessage><AppId>BxAPI</AppId><Type>2</Type>' \
'<Action>getPhotoList</Action><StateCode>2</StateCode><Message index="0">请先登录</Message>' \
'<Message index="1">ok</Message><Data></Data></BxMessage>' tree = ElementTree.fromstring(xml) # 从字符串解析得到xml结构
print(tree) # tree是一个xml 元素, BxMessage
box = tree.find('Message') # 找tree下一级的标签
print(box) # box是一个xml 元素, BxMessage
print(box.text) # 输出标签的内容
print(box.get('index')) # 获取标签属性
boxes = tree.findall('Message') # 找到所有该名字的标签,
print(boxes) # 返回一个列表
输出:
<Element 'BxMessage' at 0x00000217E207D368>
<Element 'Message' at 0x00000217E9CB0958>
请先登录
0
[<Element 'Message' at 0x00000217E9CB0958>, <Element 'Message' at 0x00000217E9CB98B8>]
Python爬虫之XML的更多相关文章
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- python爬虫:一些常用的爬虫技巧
python爬虫:一些常用的爬虫技巧 1.基本抓取网页 get方法: post方法: 2.使用代理IP 在开发爬虫过程中经常会遇到IP被封掉的情况,这时就需要用到代理IP; 在urllib2包中有Pr ...
- [Python爬虫] Selenium实现自动登录163邮箱和Locating Elements介绍
前三篇文章介绍了安装过程和通过Selenium实现访问Firefox浏览器并自动搜索"Eastmount"关键字及截图的功能.而这篇文章主要简单介绍如何实现自动登录163邮箱,同时 ...
- 【Python爬虫】入门知识
爬虫基本知识 这阵子需要用爬虫做点事情,于是系统的学习了一下python爬虫,觉得还挺有意思的,比我想象中的能干更多的事情,这里记录下学习的经历. 网上有关爬虫的资料特别多,写的都挺复杂的,我这里不打 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- Python爬虫实战(3):安居客房产经纪人信息采集
1, 引言 Python开源网络爬虫项目启动之初,我们就把网络爬虫分成两类:即时爬虫和收割式网络爬虫.为了使用各种应用场景,该项目的整个网络爬虫产品线包含了四类产品,如下图所示: 本实战是上图中的“独 ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- python爬虫如何入门
学爬虫是循序渐进的过程,作为零基础小白,大体上可分为三个阶段,第一阶段是入门,掌握必备的基础知识,第二阶段是模仿,跟着别人的爬虫代码学,弄懂每一行代码,第三阶段是自己动手,这个阶段你开始有自己的解题思 ...
随机推荐
- java中double和float精度丢失问题
为什么会出现这个问题呢,就这是java和其它计算机语言都会出现的问题,下面我们分析一下为什么会出现这个问题:float和double类型主要是为了科学计算和工程计算而设计的.他们执行二进制浮点运算,这 ...
- UVa 1616 Caravan Robbers (二分+贪心)
题意:给定 n 个区间,然后把它们变成等长的,并且不相交,问最大长度. 析:首先是二分最大长度,这个地方精度卡的太厉害了,都卡到1e-9了,平时一般的1e-8就行,二分后判断是不是满足不相交,找出最长 ...
- fakeapp, faceswap, deepfacelab等deepfakes换脸程序的简单对比
https://deepfakes.com.cn/index.php/95.html https://www.cnblogs.com/zackstang/p/9011753.html
- spring mvc 数据回显
1.spring mvc自动将传入的pojo数据存入request域 request中的key是该pojo类名,首字母小写. JSP controller 第一次访问user.jsp 填写表单 点击提 ...
- Some_tools
Why and what There are lots of nice or great tools on the internet, sometimes I will just forget a p ...
- Ubuntu的常识使用了解4
寻找文件的「名称」 在Linux系统当中,文件的数量非常非常的多, 需要使用查找工具来高效查找指定文件位置:
- Python + selenium + unittest装饰器 @classmethod
前言 前面讲到unittest里面setUp可以在每次执行用例前执行,这样有效的减少了代码量,但是有个弊端,比如打开浏览器操作,每次执行用例时候都会重新打开,这样就会浪费很多时间. 于是就想是不是可以 ...
- java中父类的静态方法不能被重写
Java中父类的静态方法确实不能被重写的,但是有的人可能去做实验发现在子类中去重写父类static方法时,并没什么问题.这里我来具体解释下. public class Parent { public ...
- [label][JavaScript扩展] JavaSCript扩展
http://www.idangero.us/sliders/swiper/ ,swipper for mobile terminal.
- eclipse中不能找到dubbo.xsd报错”cvc-complex-type.2.4.c“的 两种解决方法
配置dubbo环境过程中的xml文件,安装官网的demo配置好后,出错: "Description Resource Path Location Type cvc-complex-type. ...