gerapy的初步使用(管理分布式爬虫)
一.简介与安装
Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发。
特点:
更方便地控制爬虫运行 更直观地查看爬虫状态 更实时地查看爬取结果 更简单地实现项目部署 更统一地实现主机管理 更轻松地编写爬虫代码(几乎没用,感觉比较鸡肋)
安装:
pip install gerapy #gerapy 判断是否安装成功
F:\gerapy>gerapy
Usage:
gerapy init [--folder=<folder>]
gerapy migrate
gerapy createsuperuser
gerapy runserver [<host:port>]
二.使用
1.初始化项目
gerapy init #执行完毕之后,便会在当前目录下生成一个名字为 gerapy 的文件夹,接着进入该文件夹,可以看到有一个 projects 文件夹 #或者
gerapy init 指定的绝对目录 #这样会在指定的文件夹生成一个gerapy文件夹
2.初始化数据库
进入新生成的gerapy文件夹
cd 到gerapy目录
cd gerapy
gerapy migrate
3.运行gerapy服务
gerapy runserver
这要命令必须新生成的gerapy文件夹只用,否则以前创建的项目都看不奥到
4.访问gerapy界面
http://127.0.0.1:8000
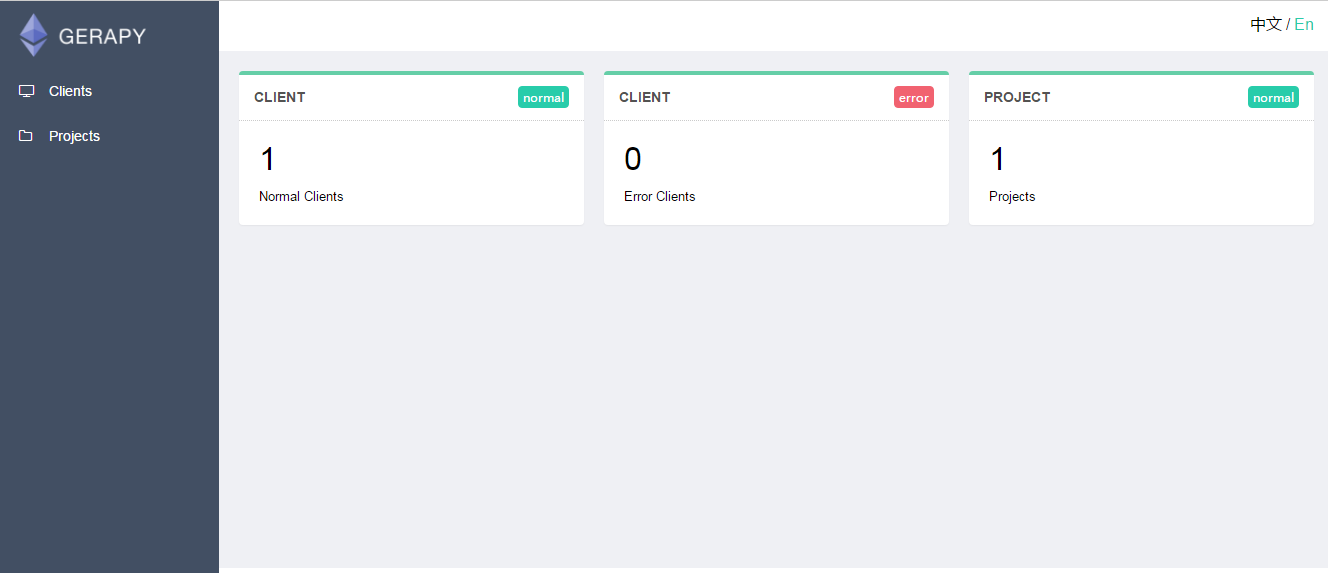
三.gerapy管理界面的使用
1.部署主机
就是配置我们scrapyd 远程服务.(指定远程服务器的ip和端口等等)
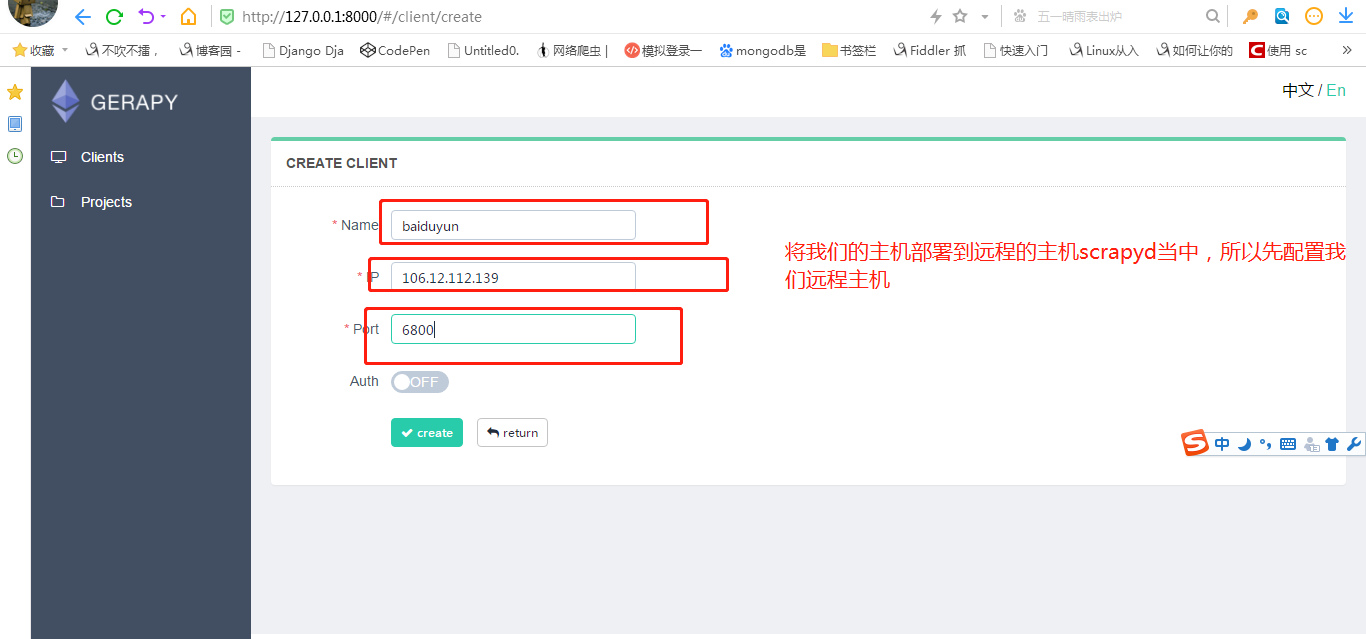
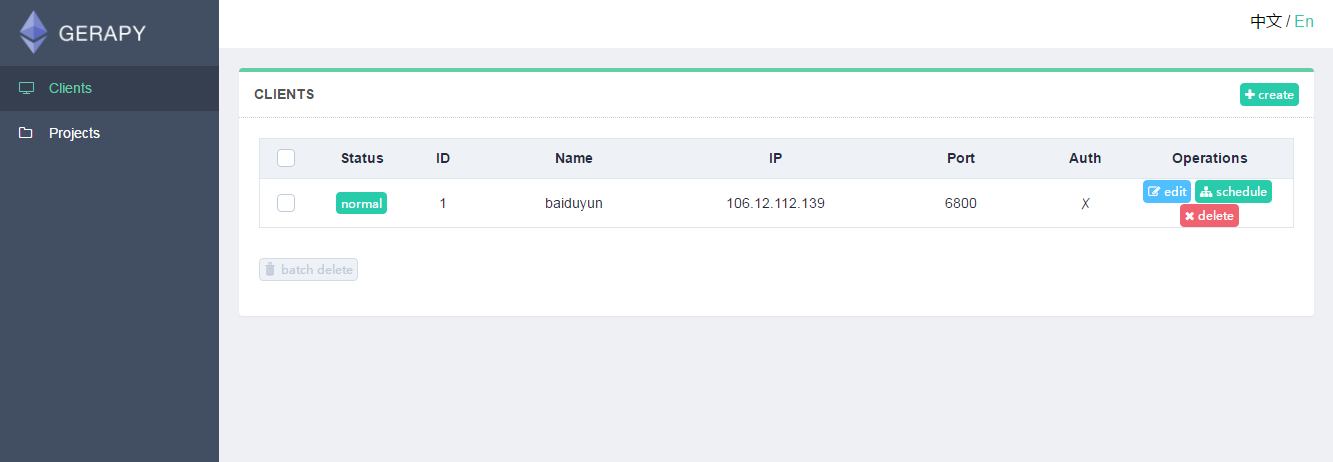
需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表
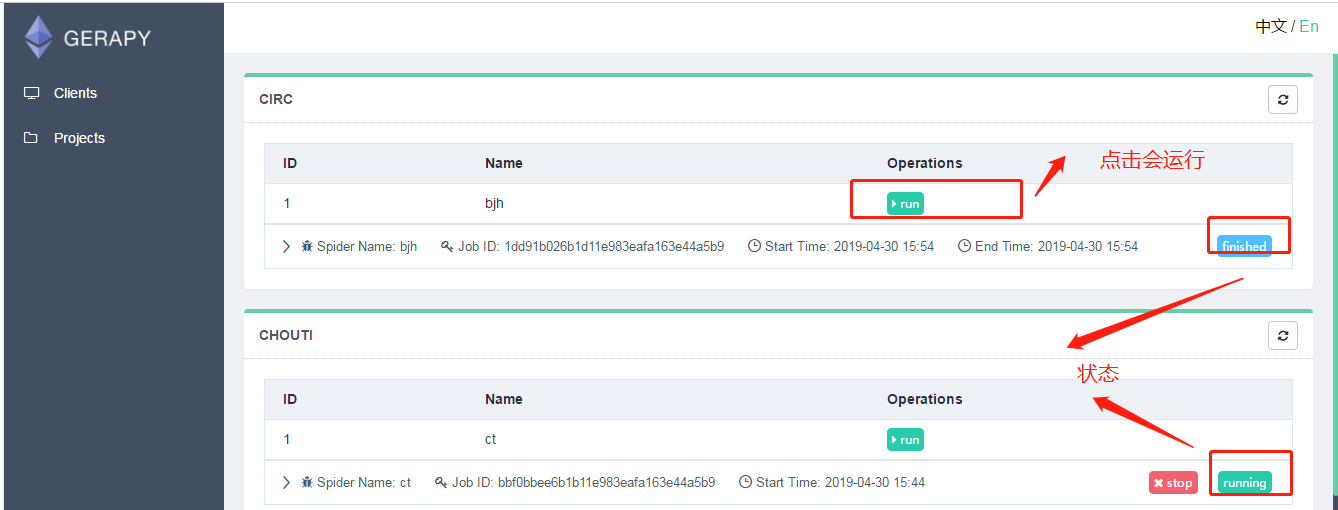
如果想执行爬虫,就点击调度.然后运行.
前提是: 我们配置的scrapyd中,已经发布了 爬虫.
Gerapy 与 scrapyd 有什么关联吗?
我们仅仅使用scrapyd是可以调用scrapy进行爬虫. 只是 需要使用命令行开启爬虫
curl http://127.0.0.1:6800/schedule.json -d project=工程名 -d spider=爬虫名
· 使用Greapy就是为了将使用命令行开启爬虫变成 “小手一点”. 我们在gerapy中配置了scrapyd后,不需要使用命令行,可以通过图形化界面直接开启爬虫.
2.部署项目
我们就可以把我们写好的爬虫文件放在生成的文件夹gerapy下projects内,然后刷新网页就可以发现项目就在里边了
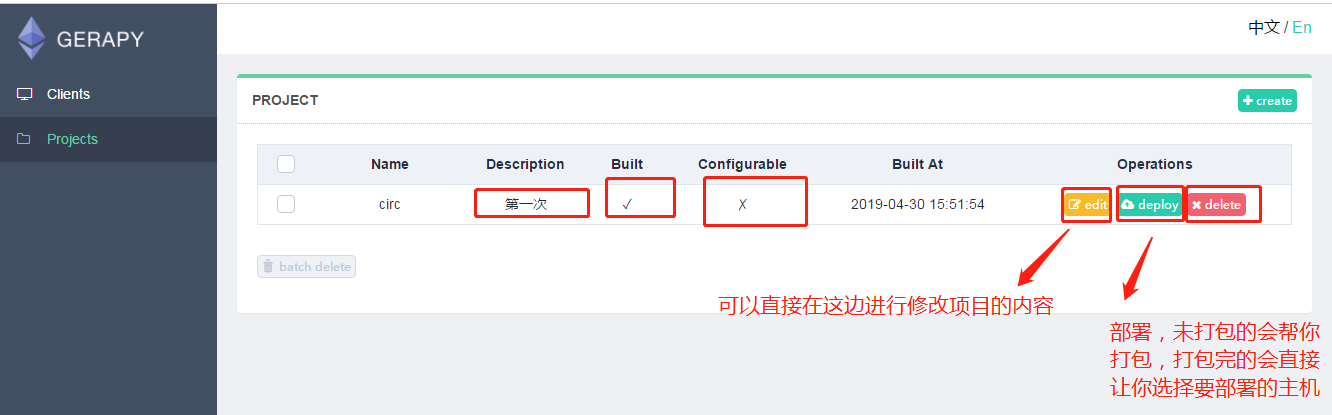
然后我们点击部署按钮就可以进行打包和部署了,描述是自定义的,这个只会在gerapy上显示,然后会提示我们打包成功,同时左侧会显示打包的结果和打包的名称。
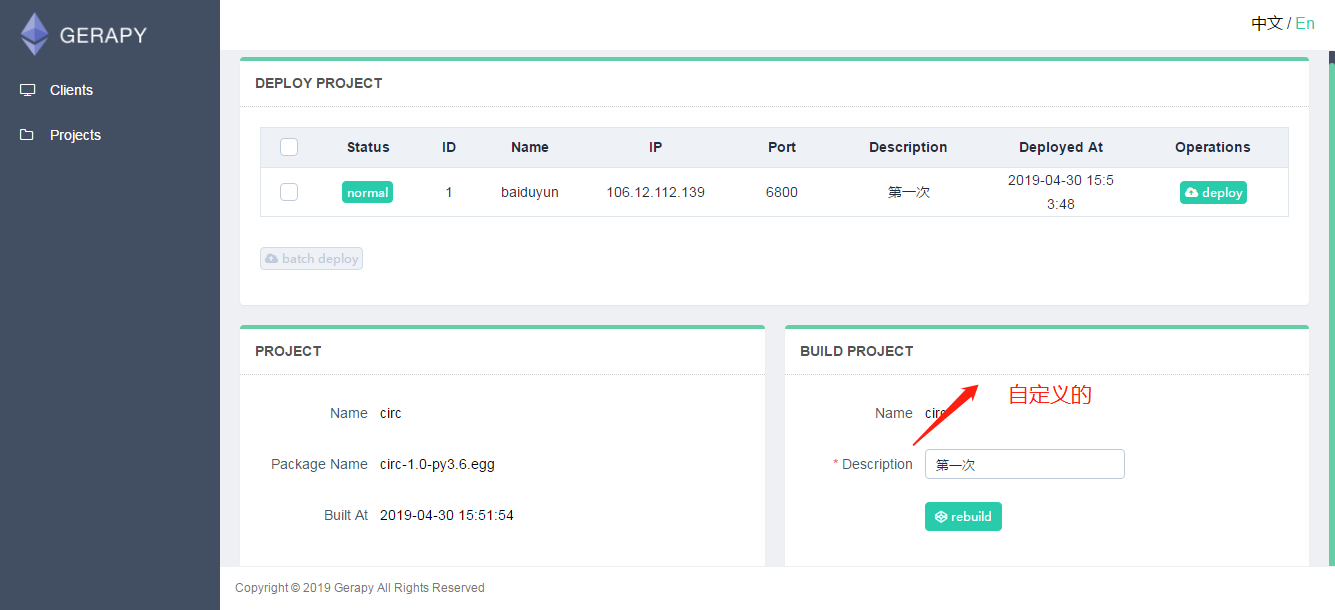
打包成功后我们就可以在进行部署了,如果有多个主机的话,我们就需要选择部署的主机,点击后边部署按钮,也可以同时批量选择主机进行部署。
然后我们就可以在主机的项目页面点击主机,看到爬虫的运行状态,并且不用在cmd中输入命令,通过点击就可以让爬虫
运行,停止,并且查看运行状态。
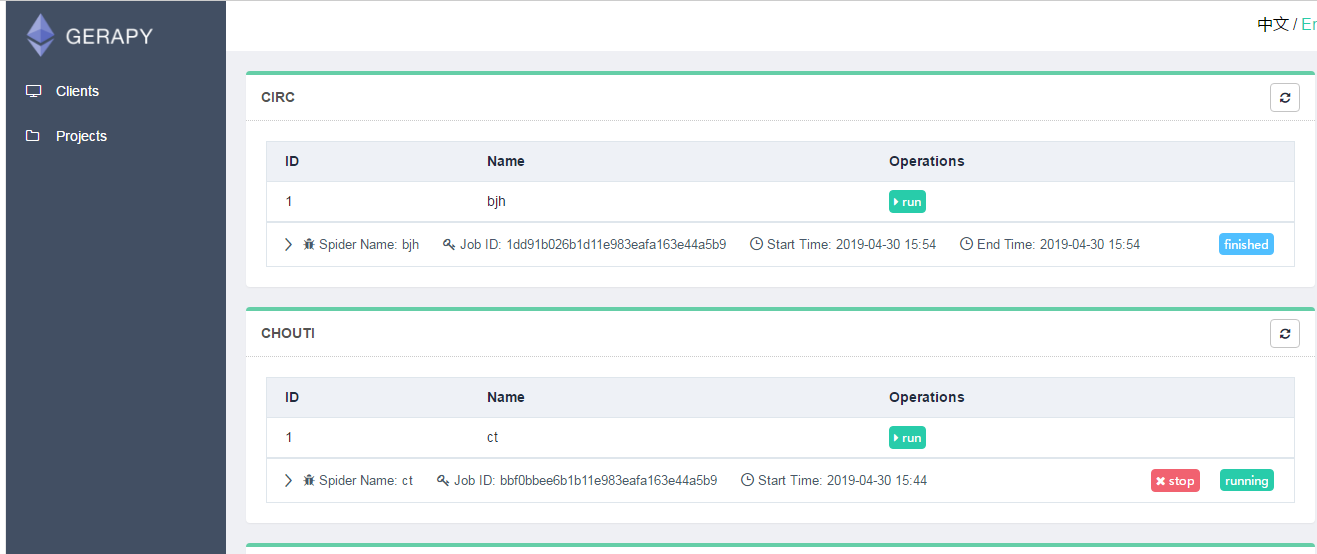
最后,gerapy也支持在其网页上自建爬虫项目,具体这里就不介绍了。
gerapy的初步使用(管理分布式爬虫)的更多相关文章
- gerapy+scrapyd组合管理分布式爬虫
Scrapyd是一款用于管理scrapy爬虫的部署和运行的服务,提供了HTTP JSON形式的API来完成爬虫调度涉及的各项指令.Scrapyd是一款开源软件,代码托管于Github上. 点击此链接h ...
- scrapydweb的初步使用(管理分布式爬虫)
https://github.com/my8100/files/blob/master/scrapydweb/README_CN.md 一.安装配置 1.请先确保所有主机都已经安装和启动 Scrapy ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 跟繁琐的命令行说拜拜!Gerapy分布式爬虫管理框架来袭!
背景 用 Python 做过爬虫的小伙伴可能接触过 Scrapy,GitHub:https://github.com/scrapy/scrapy.Scrapy 的确是一个非常强大的爬虫框架,爬取效率高 ...
- scrapyd部署、使用Gerapy 分布式爬虫管理框架
Scrapyd部署爬虫项目 GitHub:https://github.com/scrapy/scrapyd API 文档:http://scrapyd.readthedocs.io/en/stabl ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 四十三 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字段的类型以及相关属性elasticsearch会根据json源数据的基础类型猜测你想要的字段映射,将输入的数据转换成可搜索的索引项, ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
随机推荐
- centos7安装kubernetes 1.1
原文地址:http://foxhound.blog.51cto.com/1167932/1717105 前提:centos7 已经update yum update -y 一.创建yum源 maste ...
- UVa 10570 Meeting with Aliens (暴力)
题意:给定一个排列,每次可交换两个数,用最少的次数把它变成一个1~n的环状排列. 析:暴力题.很容易想到,把所有的情况都算一下,然后再选出次数最少的那一个,也就是说,我们把所有的可能的形成环状排列全算 ...
- linux计划任务(二)
计划任务的授权 1.at任务 /etc/at.allow /etc/at.deny 2.crontab任务 /etc/cron.allow /etc/cron.deny [注:如果allow文件存在, ...
- mongodb-win32-i386-3.0.6 使用
一.下载地址 https://fastdl.mongodb.org/win32/mongodb-win32-i386-3.0.6.zip 二.安装 1. systeminfo OS 名称: Micro ...
- 创建 Android 项目
创建 Android 项目 上一页下一页 您也应该阅读 项目概览 本课向您介绍如何使用 Android Studio 创建新的 Android 项目并介绍该项目中的一些文件. 在 Android St ...
- Jmeter Cookie管理器 获取JSESSIONID
1.打开jmeter.抓包添加Web请求后,添加Cookie管理器.直接添加就行.值要不要都一样 添加值:${COOKIE_JSESSIONID 域:${server} 2.点击载入到当前脚本 3.到 ...
- Register A Callback To Handle SQLITE_BUSY Errors(译)
http://www.sqlite.org/c3ref/busy_handler.html留着自己看的. Register A Callback To Handle SQLITE_BUSY Error ...
- Hdu1874 畅通工程续 2017-04-12 18:37 48人阅读 评论(0) 收藏
畅通工程续 Time Limit : 3000/1000ms (Java/Other) Memory Limit : 32768/32768K (Java/Other) Total Submiss ...
- Android-Activity启动模式-应用场景
在上一篇博客中,Android-Activity启动模式(launchMode),就介绍了Activity四种启动模式的特点与使用等,但是到底什么样子的场景,去使用什么样子的启动模式呢 Activit ...
- js判断是移动端还是PC端访问网站
window.location.href = /Android|webOS|iPhone|iPod|BlackBerry/i.test(navigator.userAgent) ? "htt ...