Ceph学习之路(二)之Ceph的工作原理及流程
一、RADOS的对象寻址
Ceph 存储集群从 Ceph 客户端接收数据——不管是来自 Ceph 块设备、 Ceph 对象存储、 Ceph 文件系统、还是基于 librados 的自定义实现——并存储为对象。每个对象是文件系统中的一个文件,它们存储在对象存储设备上。由 Ceph OSD 守护进程处理存储设备上的读/写操作。
在传统架构里,客户端与一个中心化的组件通信(如网关、中间件、 API 、前端等等),它作为一个复杂子系统的唯一入口,它引入单故障点的同时,也限制了性能和伸缩性(就是说如果中心化组件挂了,整个系统就挂了)。
Ceph 消除了集中网关,允许客户端直接和 Ceph OSD 守护进程通讯。 Ceph OSD 守护进程自动在其它 Ceph 节点上创建对象副本来确保数据安全和高可用性;为保证高可用性,监视器也实现了集群化。为消除中心节点, Ceph 使用了 CRUSH 算法。
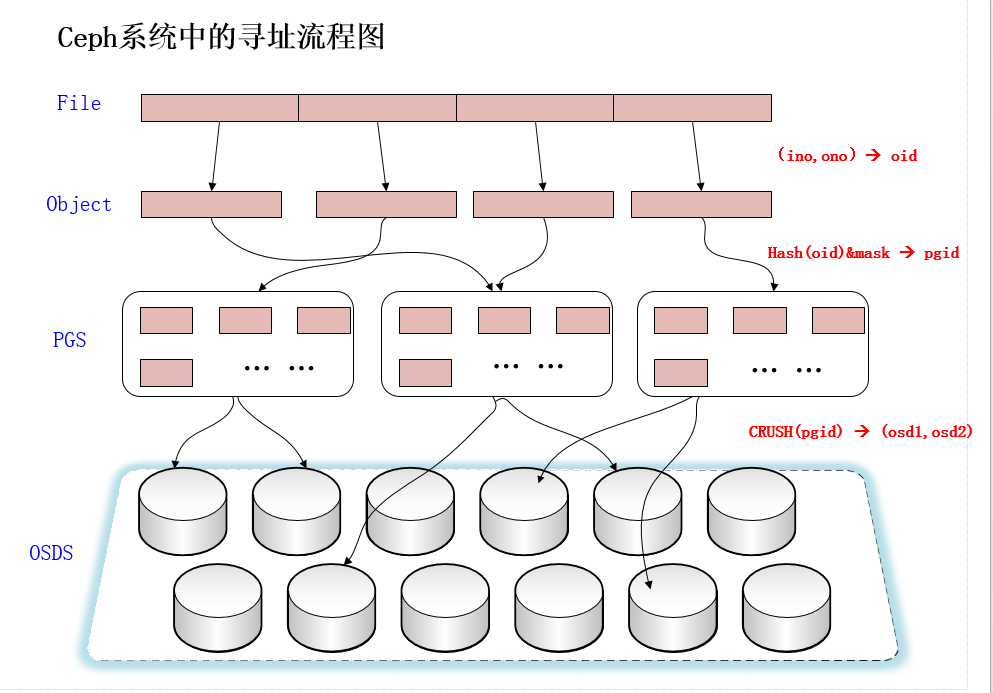
File —— 此处的file就是用户需要存储或者访问的文件。当用户要将数据存储到Ceph集群时,存储数据都会被分割成多个object。
Ojbect —— 每个object都有一个object id,每个object的大小是可以设置的,默认是4MB,object可以看成是Ceph存储的最小存储单元。
PG(Placement Group)—— 顾名思义,PG的用途是对object的存储进行组织和位置映射。由于object的数量很多,所以Ceph引入了PG的概念用于管理object,每个object最后都会通过CRUSH计算映射到某个pg中,一个pg可以包含多个object。
OSD —— 即object storage device,PG也需要通过CRUSH计算映射到osd中去存储,如果是二副本的,则每个pg都会映射到二个osd,比如[osd.1,osd.2],那么osd.1是存放该pg的主副本,osd.2是存放该pg的从副本,保证了数据的冗余。
(1)File -> object映射
这次映射的目的是,将用户要操作的file,映射为RADOS能够处理的object。其映射十分简单,本质上就是按照object的最大size对file进行切分,相当于RAID中的条带化过程。这种切分的好处有二:一是让大小不限的file变成最大size一致、可以被RADOS高效管理的object;二是让对单一file实施的串行处理变为对多个object实施的并行化处理。
每一个切分后产生的object将获得唯一的oid,即object id。其产生方式也是线性映射,极其简单。图中,ino是待操作file的元数据,可以简单理解为该file的唯一id。ono则是由该file切分产生的某个object的序号。而oid就是将这个序号简单连缀在该file id之后得到的。举例而言,如果一个id为filename的file被切分成了三个object,则其object序号依次为0、1和2,而最终得到的oid就依次为filename0、filename1和filename2。
这里隐含的问题是,ino的唯一性必须得到保证,否则后续映射无法正确进行。
- (2)Object -> PG映射
在file被映射为一个或多个object之后,就需要将每个object独立地映射到一个PG中去。这个映射过程也很简单,如图中所示,其计算公式是:
hash(oid) & mask -> pgid
由此可见,其计算由两步组成。首先是使用Ceph系统指定的一个静态哈希函数计算oid的哈希值,将oid映射成为一个近似均匀分布的伪随机值。然后,将这个伪随机值和mask按位相与,得到最终的PG序号(pgid)。根据RADOS的设计,给定PG的总数为m(m应该为2的整数幂),则mask的值为m-1。因此,哈希值计算和按位与操作的整体结果事实上是从所有m个PG中近似均匀地随机选择一个。基于这一机制,当有大量object和大量PG时,RADOS能够保证object和PG之间的近似均匀映射。又因为object是由file切分而来,大部分object的size相同,因而,这一映射最终保证了,各个PG中存储的object的总数据量近似均匀。
从介绍不难看出,这里反复强调了“大量”。只有当object和PG的数量较多时,这种伪随机关系的近似均匀性才能成立,Ceph的数据存储均匀性才有保证。为保证“大量”的成立,一方面,object的最大size应该被合理配置,以使得同样数量的file能够被切分成更多的object;另一方面,Ceph也推荐PG总数应该为OSD总数的数百倍,以保证有足够数量的PG可供映射。
- (3)PG -> OSD映射
第三次映射就是将作为object的逻辑组织单元的PG映射到数据的实际存储单元OSD。如图所示,RADOS采用一个名为CRUSH的算法,将pgid代入其中,然后得到一组共n个OSD。这n个OSD即共同负责存储和维护一个PG中的所有object。前已述及,n的数值可以根据实际应用中对于可靠性的需求而配置,在生产环境下通常为3。具体到每个OSD,则由其上运行的OSD deamon负责执行映射到本地的object在本地文件系统中的存储、访问、元数据维护等操作。
Ceph通过三次映射,完成了从file到object、PG和OSD整个映射过程。通观整个过程,可以看到,这里没有任何的全局性查表操作需求。
二、数据的操作流程
以file写入过程为例,对数据操作流程进行说明。
为简化说明,便于理解,此处进行若干假定。首先,假定待写入的file较小,无需切分,仅被映射为一个object。其次,假定系统中一个PG被映射到3个OSD上。
基于上述假定,则file写入流程可以被下图表示:
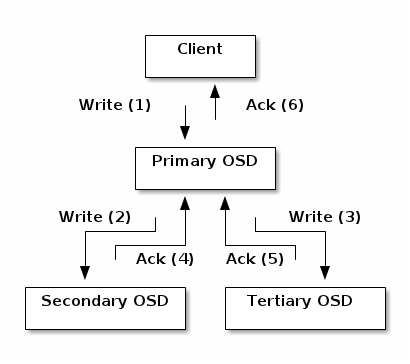
如图所示,当某个client需要向Ceph集群写入一个file时,首先需要在本地完成上面叙述的寻址流程,将file变为一个object,然后找出存储该object的一组三个OSD。这三个OSD具有各自不同的序号,序号最靠前的那个OSD就是这一组中的Primary OSD,而后两个则依次是Secondary OSD和Tertiary OSD。
找出三个OSD后,client将直接和Primary OSD通信,发起写入操作(步骤1)。Primary OSD收到请求后,分别向Secondary OSD和Tertiary OSD发起写入操作(步骤2、3)。当Secondary OSD和Tertiary OSD各自完成写入操作后,将分别向Primary OSD发送确认信息(步骤4、5)。当Primary OSD确信其他两个OSD的写入完成后,则自己也完成数据写入,并向client确认object写入操作完成(步骤6)。
之所以采用这样的写入流程,本质上是为了保证写入过程中的可靠性,尽可能避免造成数据丢失。同时,由于client只需要向Primary OSD发送数据,因此,在Internet使用场景下的外网带宽和整体访问延迟又得到了一定程度的优化。
当然,这种可靠性机制必然导致较长的延迟,特别是,如果等到所有的OSD都将数据写入磁盘后再向client发送确认信号,则整体延迟可能难以忍受。因此,Ceph可以分两次向client进行确认。当各个OSD都将数据写入内存缓冲区后,就先向client发送一次确认,此时client即可以向下执行。待各个OSD都将数据写入磁盘后,会向client发送一个最终确认信号,此时client可以根据需要删除本地数据。
分析上述流程可以看出,在正常情况下,client可以独立完成OSD寻址操作,而不必依赖于其他系统模块。因此,大量的client可以同时和大量的OSD进行并行操作。同时,如果一个file被切分成多个object,这多个object也可被并行发送至多个OSD。
从OSD的角度来看,由于同一个OSD在不同的PG中的角色不同,因此,其工作压力也可以被尽可能均匀地分担,从而避免单个OSD变成性能瓶颈。
如果需要读取数据,client只需完成同样的寻址过程,并直接和Primary OSD联系。
三、集群维护
从上面的学习,我们知道由若干个monitor共同负责整个Ceph集群中所有OSD状态的发现与记录,并且共同形成cluster map的master版本,然后扩散至全体OSD以及client。OSD使用cluster map进行数据的维护,而client使用cluster map进行数据的寻址。
在集群中,各个monitor的功能总体上是一样的,其相互间的关系可以被简单理解为主从备份关系。monitor并不主动轮询各个OSD的当前状态。正相反,OSD需要向monitor上报状态信息。常见的上报有两种情况:一是新的OSD被加入集群,二是某个OSD发现自身或者其他OSD发生异常。在收到这些上报信息后,monitor将更新cluster map信息并加以扩散。
Cluster map的实际内容包括:
Montior Map: 包含集群的 fsid 、位置、名字、地址和端口,也包括当前版本、创建时间、最近修改时间。要查看监视器图,用 ceph mon dump 命令。
OSD Map: 包含集群 fsid 、创建时间、最近修改时间、存储池列表、副本数量、归置组数量、 OSD 列表及其状态(如 up 、 in )。要查看OSD运行图,用 ceph osd dump 命令。
OSD状态的描述分为两个维度:up或者down(表明OSD是否正常工作),in或者out(表明OSD是否在至少一个PG中)。因此,对于任意一个OSD,共有四种可能的状态:
—— Up且in:说明该OSD正常运行,且已经承载至少一个PG的数据。这是一个OSD的标准工作状态;
—— Up且out:说明该OSD正常运行,但并未承载任何PG,其中也没有数据。一个新的OSD刚刚被加入Ceph集群后,便会处于这一状态。而一个出现故障的OSD被修复后,重新加入Ceph集群时,也是处于这一状态;
—— Down且in:说明该OSD发生异常,但仍然承载着至少一个PG,其中仍然存储着数据。这种状态下的OSD刚刚被发现存在异常,可能仍能恢复正常,也可能会彻底无法工作;
—— Down且out:说明该OSD已经彻底发生故障,且已经不再承载任何PG。
PG Map::** 包含归置组版本、其时间戳、最新的 OSD 运行图版本、占满率、以及各归置组详情,像归置组 ID 、 up set 、 acting set 、 PG 状态(如 active+clean ),和各存储池的数据使用情况统计。
CRUSH Map::** 包含存储设备列表、故障域树状结构(如设备、主机、机架、行、房间、等等)、和存储数据时如何利用此树状结构的规则。要查看 CRUSH 规则,执行 ceph osd getcrushmap -o {filename} 命令;然后用 crushtool -d {comp-crushmap-filename} -o {decomp-crushmap-filename} 反编译;然后就可以用 cat 或编辑器查看了。
MDS Map: 包含当前 MDS 图的版本、创建时间、最近修改时间,还包含了存储元数据的存储池、元数据服务器列表、还有哪些元数据服务器是 up 且 in 的。要查看 MDS 图,执行 ceph mds dump 。
四、OSD增加流程
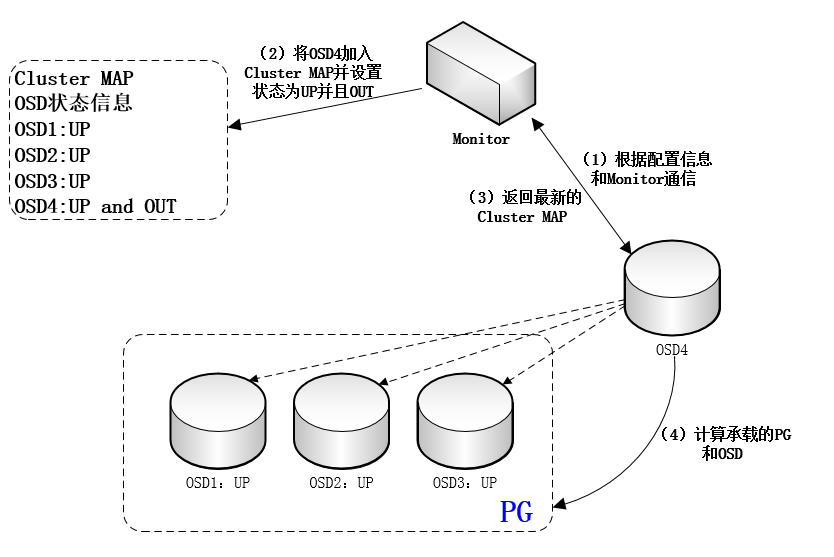
(1)一个新的OSD上线后,首先根据配置信息与monitor通信。Monitor将其加入cluster map,并设置为up且out状态,再将最新版本的cluster map发给这个新OSD。收到monitor发来的cluster map之后,这个新OSD计算出自己所承载的PG(为简化讨论,此处我们假定这个新的OSD开始只承载一个PG),以及和自己承载同一个PG的其他OSD。然后,新OSD将与这些OSD取得联系。如图:
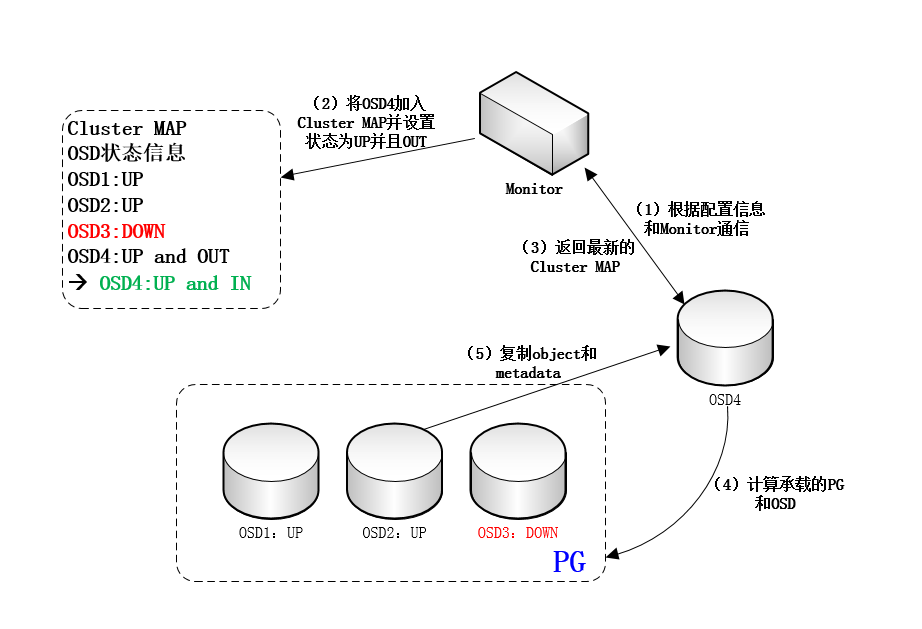
(2)如果这个PG目前处于降级状态(即承载该PG的OSD个数少于正常值,如正常应该是3个,此时只有2个或1个。这种情况通常是OSD故障所致),则其他OSD将把这个PG内的所有对象和元数据复制给新OSD。数据复制完成后,新OSD被置为up且in状态。而cluster map内容也将据此更新。这事实上是一个自动化的failure recovery过程。当然,即便没有新的OSD加入,降级的PG也将计算出其他OSD实现failure recovery,如图:
(3)如果该PG目前一切正常,则这个新OSD将替换掉现有OSD中的一个(PG内将重新选出Primary OSD),并承担其数据。在数据复制完成后,新OSD被置为up且in状态,而被替换的OSD将退出该PG(但状态通常仍然为up且in,因为还要承载其他PG)。而cluster map内容也将据此更新。这事实上是一个自动化的数据re-balancing过程,如图:
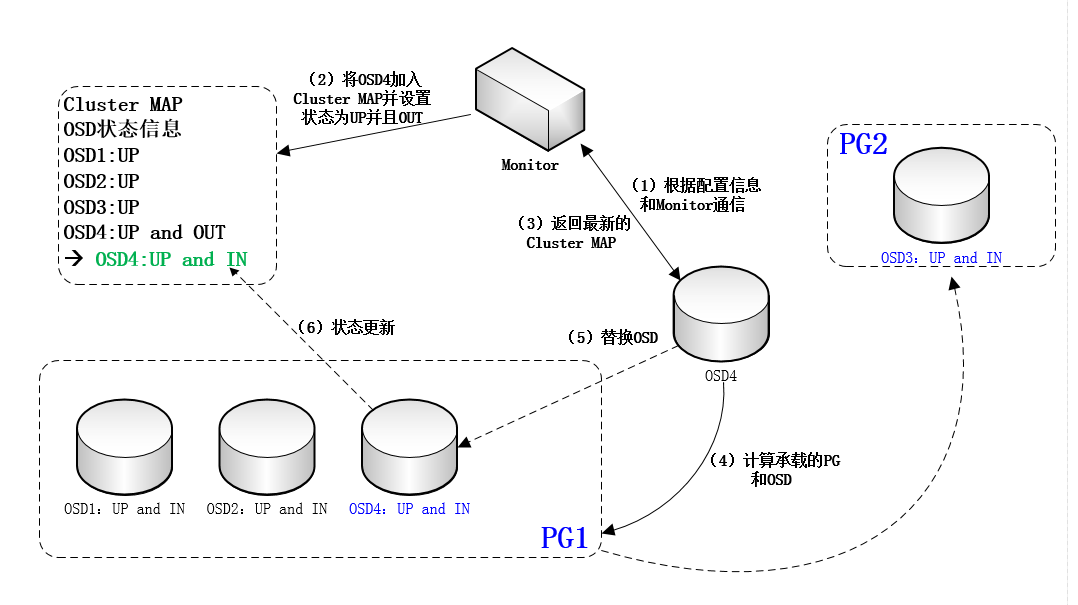
(4)如果一个OSD发现和自己共同承载一个PG的另一个OSD无法联通,则会将这一情况上报monitor。此外,如果一个OSD deamon发现自身工作状态异常,也将把异常情况主动上报给monitor。在上述情况下,monitor将把出现问题的OSD的状态设为down且in。如果超过某一预订时间期限,该OSD仍然无法恢复正常,则其状态将被设置为down且out。反之,如果该OSD能够恢复正常,则其状态会恢复为up且in。在上述这些状态变化发生之后,monitor都将更新cluster map并进行扩散。这事实上是自动化的failure detection过程。
Ceph学习之路(二)之Ceph的工作原理及流程的更多相关文章
- “Ceph浅析”系列之五——Ceph的工作原理及流程
本文将对Ceph的工作原理和若干关键工作流程进行扼要介绍.如前所述,由于Ceph的功能实现本质上依托于RADOS,因而,此处的介绍事实上也是针对RADOS进行.对于上层的部分,特别是RADOS GW和 ...
- Ceph的工作原理及流程
本文将对Ceph的工作原理和若干关键工作流程进行扼要介绍.如前所述,由于Ceph的功能实现本质上依托于RADOS,因而,此处的介绍事实上也是针对RADOS进行.对于上层的部分,特别是RADOS GW和 ...
- HTTPS详解二:SSL / TLS 工作原理和详细握手过程
HTTPS 详解一:附带最精美详尽的 HTTPS 原理图 HTTPS详解二:SSL / TLS 工作原理和详细握手过程 在上篇文章HTTPS详解一中,我已经为大家介绍了 HTTPS 的详细原理和通信流 ...
- Ceph学习之路(一)之ceph初识
一.元数据和元数据管理 (1)元数据 在学习Ceph之前,需要了解元数据的概念.元数据又称为中介数据.中继数据,为描述数据的数据.主要描述数据属性的信息,用来支持如指示存储位置.历史数据.资源查找.文 ...
- Ceph学习之路(三)Ceph luminous版本部署
1.配置ceph.repo并安装批量管理工具ceph-deploy [root@ceph-node1 ~]# vim /etc/yum.repos.d/ceph.repo [ceph] name=Ce ...
- Redis——学习之路二(初识redis服务器命令)
上一章我们已经知道了如果启动redis服务器,现在我们来学习一下,以及如何用客户端连接服务器.接下来我们来学习一下查看操作服务器的命令. 服务器命令: 1.info——当前redis服务器信息 s ...
- 代码管理工具 --- git的学习笔记二《git的工作原理》
通过几个问题来学习代码管理工具之git 一.git是什么?为什么要用它?使用它的好处?它与svn的区别,在Mac上,比较好用的git图形界面客户端有 git 是分布式的代码管理工具,使用它是因为,它便 ...
- Spring学习之旅(四)Spring工作原理再探
上篇博文对Spring的工作原理做了个大概的介绍,想看的同学请出门左转.今天详细说几点. (一)Spring IoC容器及其实例化与使用 Spring IoC容器负责Bean的实例化.配置和组装工作有 ...
- 分布式的几件小事(二)dubbo的工作原理
1.dubbo的工作原理 ①整体设计 图例说明: 图中左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口. 图中从下至上分为十层,各层均为单 ...
随机推荐
- redis.conf 具体配置详解
redis.conf 具体配置详解 # redis 配置文件示例 # 当你需要为某个配置项指定内存大小的时候,必须要带上单位, # 通常的格式就是 1k 5gb 4m 等酱紫: # # 1k => ...
- BZOJ1049:[HAOI2006]数字序列(DP)
Description 现在我们有一个长度为n的整数序列A.但是它太不好看了,于是我们希望把它变成一个单调严格上升的序列. 但是不希望改变过多的数,也不希望改变的幅度太大. Input 第一行包含一个 ...
- BZOJ3573:[HNOI2014]米特运输(树形DP)
Description 米特是D星球上一种非常神秘的物质,蕴含着巨大的能量.在以米特为主要能源的D星上,这种米特能源的运输和储 存一直是一个大问题.D星上有N个城市,我们将其顺序编号为1到N,1号城市 ...
- office2013密钥
GYWDG-NMV9P-746HR-Y2VQW-YPXKK6HDB9-BNRGY-J3F83-CF43C-D67TXG9N3P-GRJK6-VM63J-F9M27-KHGXKX2YWD-NWJ42-3 ...
- linux下批量重命名文件
# 使用通配符批量创建 多个文件:$ touch zqunor{1..7}.txt # 批量将多个后缀为 .txt 的文本文件重命名为以 .c 为后缀的文件:$ rename 's/\.txt/\.c ...
- PAT——1029. 旧键盘
旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现.现在给出应该输入的一段文字.以及实际被输入的文字,请你列出肯定坏掉的那些键. 输入格式: 输入在2行中分别给出应该输入的文字.以及实际 ...
- vlc源码分析(一) RTSP会话流程
可以先了解一下RTSP/RTP/RTCP的概念与区别:RTP与RTCP协议介绍(转载). 在调试vlc-android时,熟悉了RTSP的会话流程.C表示RTSP客户端,S表示RTSP服务端: 第一步 ...
- python爬虫练习 -- 签名器+GUI界面(Tkinter)
效果图: 实现步骤如下: 实现原理:其实就是套了一层GUI的壳,主要还是爬虫抓取某个网站返回的数据,然后利用python自带的GUI工具包Tkinter来实现gui界面: 1.爬虫分析: 目标站点:h ...
- docker tar 镜像 容器相互转换
学习 使用 docker 也有一段时间了 但是在基础去上面有些东西总是容易忘记 整理之前看到的文档,看到一个问题 怎么将一个容器导出成为tar,我本以为是首先 保存成为镜像 再 save 进行保存 查 ...
- Java面试题整理1
Java基础部分 JDK和JRE有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境.JRE:Java Runtime ...