selenium笔记2017
1,from time import sleep(先引入关键词)
sleep(5) (就可以使用这个命令了)
可以停止页面5秒
1-1.
等待页面元素出现的时间(即没出现时,等待元素出现)
在头部加上:
driver=webdriver.Firefox()
driver.implicitly_wait (10)#显式等待
2,定位的语法:
driver.find_element_by_id('kw')
3, A=driver.find_element_by_id('kw'),get_attribute('属性')==”值”
验证元素的属性。
返回ture flase
if driver.find_element_by_id('kw').get_attribute('autocomplete') == 'off':
print "TURE ,百度按钮找到了 "
else:
print "no"
4,定位P标签 只有文字的方法
//div[@class=’suggert’]/p[contatiotains(text(),‘八达岭长城’)]
5,指定一个浏览器或驱动
driver= webdriver.Firefox(executable_path="C:\Program Files (x86)\Mozilla Firefox\firefox.exe")
dr=webdriver.Chrome(executable_path = '/Library/Python/2.7/chromedriver')
6,显示元素的出现等待: (pdf 4.7)
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
input_=driver.find_element_by_id("kw")
element = WebDriverWait(driver,5,0.5).until(
lambda driver :input_.is_displayed())
print element
4.9 iframe的切换
dr.switch_to_frame('iframeUploadMaterialImage') #可自动识别ID OR name
dr.switch_to_default_content()#切回来
4.10 多窗口的切换
7,验证并且不会中止下面代码的执行:
#coding=utf-8
from selenium import webdriver
dr= webdriver.Firefox()
dr.get('http://www.baidu.com')
try:
dr.find_element_by_id('1kw').send_keys('selenium')
dr.find_element_by_id('su').click()
except :
print "oh no" #上面有异常打印这个
exit() #加入这个的话就直接退出程序,不执行下面的用例
else :
print "oh no" #上面正常打印这个
#找不到按钮也会继续执行下面的动作不会中断
dr.quit()
抛出错误就停止可以用assert(看python笔记本第17条)
7-1验证断言写法
B=3
C=3
try:
A=B+C
assert(A==6),"错误信息"
except AssertionError,msg:
print msg
else:
print "PASS"
下面是简写:
try:
A=B+C
assert(A==6)
except :
print “错误信息”
else:
print "PASS"
8.参数化的方法 5.3.2
读取text文件并做分隔的,如:账号密码的登录
9.一个 python获取当前时间 和数据格式化的例子:
例子一:
这个是正确主流的方法:
#coding: utf-8
import datetime #引入类
# 获取当前的时间
today = datetime.date.today()
ab= 'My age is'+ str(today)
#编写标题
dr.find_element_by_name("title").send_keys(ab)
#得出来的日期是字符串的类型,注意字符串格式化的方法%s
例子二:
只是把数据类型变字符串的,使用str()
#coding: utf-8
import datetime #引入类
# 获取当前的时间
today = datetime.date.today()
ab=today
print ab
#编写标题
dr.find_element_by_name("title").send_keys(str(ab))
#使用python的字符串格式化,str()方式,把日期变成字符格式,send_keys正常。
例子三:
#coding: utf-8
import datetime #引入类
# 获取当前的时间
today = datetime.date.today()
ab= 'My age is %s' % today
#编写标题
dr.find_element_by_name("title").send_keys(ab)
#得出来的日期是字符串的类型,注意字符串格式化的方法%s
11,获取对象的属性 和获取标签集的方法
inputs = driver.find_elements_by_tag_name('input')
#然后循环遍历出data-node 为594434493的元素,单击勾选
for input in inputs:
if input.get_attribute('data-node') == '594434493':
input.click()
......
12,警告窗 4-11
#接收弹窗driver.switch_to_alert().accept()
13,当send_keys中文的时候报错,
可以在中文前面加个u即可
Send_keys(u”你好”)
14, 4-3-1
is_displayed() 设置该元素是否用户可见
15,
dr.quit()
退出并关闭窗口的每一个相关的驱动程序,它还有个类似的表弟。
dr.close()
关闭当前窗口 ,用哪个看你的需求了。
16,,清除文本,如果是一个文件输入框
clear()
17,模拟 下页 按键 pg DN (可以解决chrome不可以拖动浏览器的问题)
dr.find_element_by_xpath("/html/body").send_keys(Keys.PAGE_DOWN)
模拟 上页 按键
dr.find_element_by_xpath("/html/body").send_keys(Keys.PAGE_UP)
18.chrome 使用本来的浏览条滚动命令无法滚动 的解决方法
参考网: (亲测OK)http://blog.csdn.net/sinat_21302587/article/details/54341020?locationNum=1&fps=1
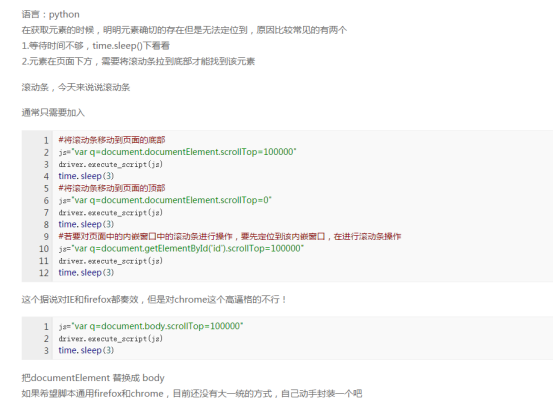
19,判断复选框有没有选中的API
# 点击后,判断元素是否为选中状态
r = driver.find_element_by_id("boy").is_selected()
参考网站:http://www.cnblogs.com/yoyoketang/p/6128675.html
20,获取标签的属性判断bool值
Dr.find_element_by_xpath(~).get_ attribute(“CLASS”)==”123”
返回是bool值 ture or flase
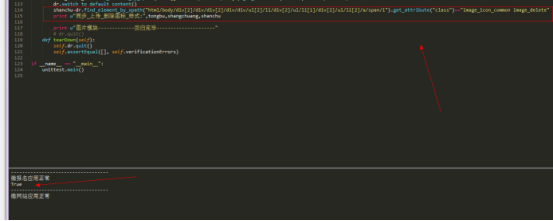
22,双层定位
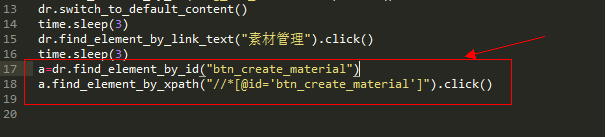
多用于下拉框的定位:
先定位下拉框,再xpath定位下拉框下面的选项
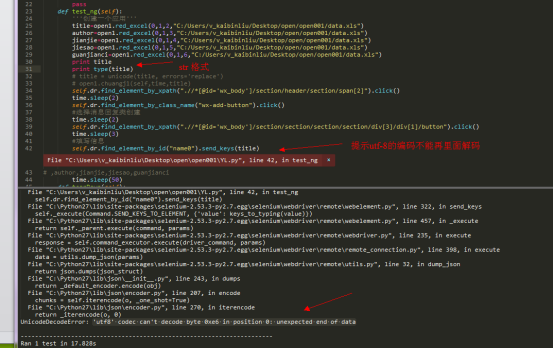
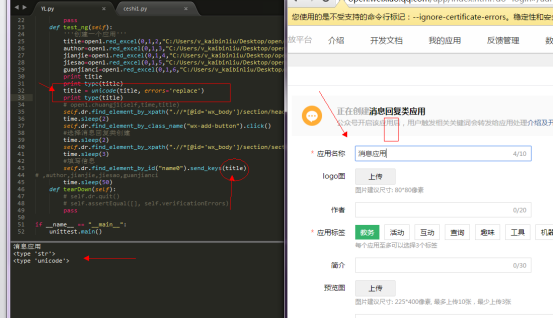
21,做数据分离的时候,从excel取出来的数据,无法放入send_keys API里面去 执行
解决过程:
从excel取出来的数据 type类型是str的 无法send_keys。提示无法解码
但是先把他转成unicode格式再放进去就可以send_keys了
后面发现,原来在函数那边做了utf-8格式转换,不转换的话可以直接调用
22. page_source
获取到页面源码(前端代码)
用法: element.page_source

参考: https://www.cnblogs.com/yoyoketang/p/6512604.html
selenium笔记2017的更多相关文章
- selenium笔记(1)
selenium笔记(1) 一.关闭页面:1.driver.close() 关闭当前页面2.driver.quit() 退出整个浏览器 二.定位元素:1.find_element_by_id: 根据i ...
- Python+Selenium笔记(九):操作警告和弹出框
#之前发的 driver.switch_to_alert() 这句虽然可以运行通过,但是会弹出警告信息(这种写法3.x不建议使用) 改成 driver.switch_to.alert就不会了. (一 ...
- Python+Selenium笔记(一):环境配置+简单的例子
#环境配置基于windows操作系统 #学习selenium要有一些HTML和xpth的基础,完全不会的建议先花点时间学点基础(不然元素定位,特别是xpth可能看的有点懵) #HTML : http ...
- Python 爬虫 selenium 笔记
1. selenium 安装, 与文档 pip install selenium Selenium with Python中文翻译文档 selenium官网英文文档 2. selenium 的第一个示 ...
- Selenium 笔记
1. 截屏:get_screenshot_as_file(“C:\\b1.jpg”) 2. 退出:(1).close----关闭当前窗口 (2).quit()-----用于结束进程,关闭所有的窗口 一 ...
- Python+Selenium笔记(十八):持续集成jenkins
(一)安装xmlrunner 使用Jenkins执行测试时,测试代码中会用到这个模块. pip install xmlrunner (二)安装jenkins (1) 下载jekins https: ...
- Python+Selenium笔记(十七):操作cookie
(一)方法 方法 简单说明 add_cookie(cookie_dict) 在当前会话中添加cookie信息 cookie_dict:字典,name和value是必须的 delete_all_cook ...
- Python+Selenium笔记(十六)屏幕截图
(一) 方法 方法 简单说明 save_screenshot(filename) 获取当前屏幕截图并保存为指定文件 filename:路径/文件名 get_screenshot_as_base64 ...
- Python+Selenium笔记(十五)调用JS
(一) 方法 方法 简单说明 execute_async_script(script, args) 异步执行JS代码 script:被执行的JS代码 args:js代码中的任意参数 execute_s ...
随机推荐
- tar: Cowardly refusing to create an empty archive 问题
在解压 .tar.gz文件的时候遇到了这个解压的问题. 原命令:tar -zcvf ···.tar.gz 提示:tar: Cowardly refusing to create an empty ar ...
- thinkphp5中的配置如何使用
thinkphp5中的配置如何使用 一.总结 一句话总结:先加载配置,然后读取配置即可 加载配置 读取配置 Config::load(APP_PATH.'fry_config.php');\\加载配置 ...
- 2018-2019-2 网络对抗技术 20165332 Exp3 免杀原理与实践
2018-2019-2 网络对抗技术 20165332 Exp3 免杀原理与实践 实验内容 任务一:正确使用msf编码器,msfvenom生成如jar之类的其他文件,veil-evasion,自己利用 ...
- CC工具列表
QuasarRAT Adwind Adzok Arcom Babylon Blacknix Blue Banana Bozok Coringa DarkComet DRAT Gh0st Huige ...
- prim和kruskal比较
推荐:http://squirrelrao.iteye.com/blog/1044867 http://www.cnblogs.com/xwdreamer/archive/2011/06/16/22 ...
- HDU1102 最小生成树prim算法
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1102 题意:给出任意两个城市之间建一条路的时间,给出哪些城市之间已经建好,问最少还要多少时间使所有的城 ...
- 适配器 STL
body, table{font-family: 微软雅黑; font-size: 10pt} table{border-collapse: collapse; border: solid gray; ...
- 用压测模拟并发、并发处理(synchronized,redis分布式锁)
使用工具:Apache an 测压命令: ab -n 100 -c 100 http://www.baidu.com -n代表模拟100个请求,-c代表模拟100个并发,相当于100个人同时访问 ab ...
- 对象存储在什么地方(java编程思想)
用引用操作对象.创建了一个引用,需要进行初始化(与事物进行关联),才能正常使用.new将引用于对象进行关联 对象存储到什么地方? 程序运行时,对象是怎么进行放置安排的呢?特别是内存是怎么分配的呢?对这 ...
- mysql远程连接的设置
有时数据库所在机器与项目运行的机器不是同一个,那么就涉及到远程链接数据库了,配置远程连接数据库的步骤如下: 1.查看mysql数据库中,user表中的信息,如下图,先使用use mysql切换到mys ...