LG3781 [SDOI2017]切树游戏
题意
题目描述
小Q是一个热爱学习的人,他经常去维基百科学习计算机科学。
就在刚才,小Q认真地学习了一系列位运算符,其中按位异或的运算符\(\oplus\)对他影响很大。按位异或的运算符是双目运算符。按位异或具有交换律,即\(i \oplus j = j \oplus i\)。
他发现,按位异或可以理解成被运算的数字的二进制位对应位如果相同,则结果的该位置为\(0\),否则为\(1\),例如:\(1(01) \oplus 2(10) = 3(11)\)。
他还发现,按位异或可以理解成参与运算的数字的每个二进制位都进行了不进位的加法,例如:\(3(11) \oplus 3(11) = 0(00)\)。
现在小Q有一棵\(n\)个结点的无根树\(T\),结点依次编号为\(1\)到\(n\),其中结点\(i\)的权值为\(v_i\)。
定义一棵树的价值为它所有点的权值的异或和,一棵树\(T\)的连通子树就是它的一个连通子图,并且这个图也是一棵树。
小Q想要在这棵树上玩切树游戏,他会不断做以下两种操作:
Change x y 将编号为\(x\)的结点的权值修改为\(y\)。
Query k 询问有多少棵\(T\)的非空连通子树,满足其价值恰好为\(k\)。
小Q非常喜(bu)欢(hui)数学,他希望你能快速回答他的问题,你能写个程序帮帮他吗?
输入输出格式
输入格式:
第一行包含两个正整数\(n\) , \(m\),分别表示结点的个数以及权值的上限。
第二行包含\(n\)个非负整数\(v_1, v_2,\dots , v_n\),分别表示每个结点一开始的权值。
接下来\(n-1\)行,每行包含两个正整数\(a_i , b_i\),表示有一条连接\(a_i\)和\(b_i\)的无向树边。
接下来一行包含一个正整数\(q\),表示小Q操作的次数。
接下来\(q\)行每行依次表示每个操作。
输出格式:
输出若干行,每行一个整数,依次回答每个询问。因为答案可能很大,所以请对\(10007\)取模输出。
输入输出样例
输入样例#1:
4 4
2 0 1 3
1 2
1 3
1 4
12
Query 0
Query 1
Query 2
Query 3
Change 1 0
Change 2 1
Change 3 3
Change 4 1
Query 0
Query 1
Query 2
Query 3
输出样例#1:
3
3
2
3
2
4
2
3
说明
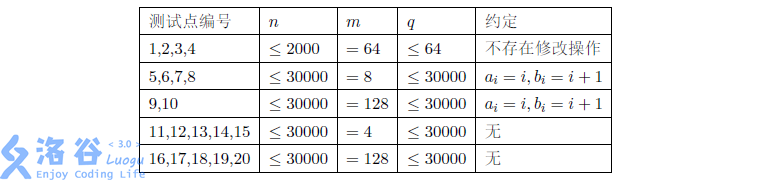
对于\(100\%\)的数据,\(1 \leq a_i,b_i,x \leq n\) , \(0 \leq v_i,y,k < m\),修改操作不超过\(10000\)个。
分析
理论依据首推猫锟的解题报告。
算法讨论
如果只有一次询问,非常容易想到暴力 DP。先转有根树。在全局记录答案数组 \(ans(k)\) 表示权值为 \(k\) 的子树个数。对每个点 \(i\) 记录 \(f(i, k)\) 表示子树中深度最小的点为 \(i\) 且子树权值为 \(k\) 的连通子树个数。记录 \(g(i, j, k)\) 表示子树中深度最小的点为 \(i\) 且所有其他的节点都在 \(i\) 的前 \(j\) 个子节点的子树中的连通子树个数。那么我们就有以下方程(设 \(Ch(i)\) 为 \(i\) 的子节点列表):
- \(g(i, 0, k) = [k=v_i]\)
- \(g(i, j, k) = \sum_{t=0}^{127} g(i,j-1,t)\times (f(Ch(i)_j, k\oplus t) + [k\oplus t = 0])\)
- \(f(i, k) = g(i, |Ch(i)|, k)\)
- \(ans(k) = \sum_{i=1}^n f(i, k)\)
总时间复杂度为 \(O(nm\times 128^2)\)。
接下来可以注意到第 2 个式子是一个“异或卷积”的形式,不难想到使用 FWT 可以优化到 \(O(128\log 128)\)。然后注意到 FWT 之后,加法和乘法都可以直接按位相加,因此可以在一开始就将所有数组 FWT,运算过程中全部使用** FWT 之后的数组**,最后再将 $ans( * ) $ 数组 FWT 回去即可。这样就可以去掉一个 \(\log 128\)。时间复杂度为 \(O((n + \log 128)\times 128)\)。
再接下来就是优化修改复杂度了。看过我论文或做过 BZOJ 4712 的同学容易想到使用链分治维护树上动态 DP。首先将树进行轻重链剖分,然后按照重链构成的树的顺序进行 DP。如果这样以后每一条重链上的转移可以高效维护、支持修改,那么每次修改点 \(p\) 之后,我们就可以高效地更新点 \(p\) 到根的 \(O(\log n)\) 条重链的信息即可。
首先 \(ans(k)\) 是全局变量,不好维护。那么可以不记录 \(ans( * )\),而是记录 \(h(i, k)\) 表示 \(i\) 子树中的 \(f(i, k)\) 的和,那么这样整个 DP 就有子树的阶段性了。
可以发现 \(f(i, k)\) 就是先将 \(g(i, 0, * )\) 和所有子节点 \(p\) 的 \(f(p, k ) + [k = 0]\) 全部卷积起来的值。即如果设 \(F_i(z)\) 表示 \(f(i, * )\) 这一数组的生成函数,那么可以得出 $$F_i(z) = z^{v_i}\prod_{p\in Ch(i)} (F_p(z) + z^0) $$ 这里的卷积定义为异或卷积。那么对于一条重链上的每一个点 \(i\),我们只需要将 \(i\) 的所有轻儿子 \(lp\) 的 \(F_{lp}(z) + z^0\) 全部卷积起来,这样就考虑了所有轻儿子的子树中的贡献,设这个卷积的结果为 \(LF_i(z)\)。同样对于每个点我们记录 \(LH_i(z)\) 表示这个点的每个轻儿子的 \(H_{lp}(z)\) 之和(这里 \(H_i(z)\) 的定义类似 \(F_i(z)\),只不过是对 \(h(i, * )\) 定义的)。每个点的轻边的信息和可以用线段树维护来支持高效修改。
Claris 大神说这里信息可减因此不用线段树,但我觉得这里的 \(LF_i(z)\) 的信息相减需要做除法,如果出现 10007 的倍数则没有逆元,无法相除,因此我仍然采用线段树维护。
注意到上述算法只要求我们能求出 \(F_{重链顶}(z)\) 和 \(H_{重链顶}(z)\),就可以维护父亲重链的信息或答案了。因此现在只需要考虑所有过当前重链的子树。在这里我们有如下两种截然不同的思路。
基于维护序列信息的算法
论文中提到的方法是转化为序列上的问题,然后使用线段树维护。由于连通子树和重链的交一定也是一段连续的链,那么我们显然就可以像最大子段和问题那样,记录 \(D_{a,b}(z)\) 表示 \(a=[\)左端点在连通子树中\(]\)、\(b=[\)右端点在连通子树中\(]\) 的方案数。这个算法将修改复杂度优化为 \(O(128\log^2 n + 128\log 128)\),已经可以通过本题了。
但是这个算法有一定的问题:首先它具有较大的常数因子,运行时间较慢。其次,这个算法仍然利用了具体题目的性质——连通子树和重链的交还是链。而并非所有的题都有这样的性质。最后,由于要不重不漏地计数,代码细节繁多,十分难写。
基于变换合并的算法
对于一条重链,设重链上的点按深度从小到大排序后为 \(p_1,p_2,...,p_c\),那么我们可以得出以下方程:
- \(F_{p_c}(z) = H_{p_c}(z) = z^{v_{p_c}}\) (因为 \(p_c\) 没有子节点)
- \(F_{p_i}(z) = LP_{p_i}(z) \times (F_{p_{i+1}}(z) + z^0) \times {z^{v_{p_i}}}\)
- \(H_{p_i}(z) = H_{p_{i+1}}(z) + F_{p_{i}}(z)\)
而我们所需要求的只有 \(F_{p_1}(z)\) 和 \(H_{p_1}(z)\)。
可以观察到上面这个式子中,向量 \(\left(F_{p_{i+1}}(z), H_{p_{i+1}}(z), z^0\right)\) 是通过一个线性变换得到向量 \(\left(F_{p_i}(z), H_{p_i}(z), z^0\right)\),具体地来说是右乘上这样一个矩阵:
\]
而矩阵乘法是满足结合律的,也就是说,我们只需要用线段树支持单点修改某个矩阵 \(M_i\)、维护矩阵的积,我们就可以高效地求出我们所需要的向量 \((F_{p_1}(z), H_{p_1}(z), 1)\)。而这是容易做到的,因此这个算法是完全可行的。这样,这个算法也将修改复杂度优化为了 \(O(128\log^2 n + 128\log 128)\),可以通过本题。
简单优化这个算法的常数。注意到形如 $$\begin{pmatrix} \underline{a} & \underline{b} & 0 \ 0 & 1 & 0 \ \underline{c} & \underline{d} & 1 \end{pmatrix}$$ 的矩阵乘法对这个形式封闭,因为 $$\begin{pmatrix} \underline{a_1} & \underline{b_1} & 0 \ 0 & 1 & 0 \ \underline{c_1} & \underline{d_1} & 1 \end{pmatrix} \times \begin{pmatrix} \underline{a_2} & \underline{b_2} & 0 \ 0 & 1 & 0 \ \underline{c_2} & \underline{d_2} & 1 \end{pmatrix} = \begin{pmatrix} \underline{a_1 a_2} & \underline{b_1 + a_1 b_2} & 0 \ 0 & 1 & 0 \ \underline{a_2 c_1 + c_2} & \underline{b_2 c_1 + d_1 + d_2} & 1 \end{pmatrix}$$
因此我们只需要对每个矩阵维护 \(a,b,c,d\) 四个变量即可。同时可以直接用等号右边的形式来计算矩阵乘法,这样就只需要做 \(4\) 次而不是 \(27\) 次生成函数乘法了,常数大大减小了。
比较与扩展
这两个算法的时间复杂度相同,并且都可以扩展到询问某一个有根树子树的信息——只需要对那一条重链询问一下信息和/变换和即可。
我们来审视一下后一个算法。首先,这个算法基于的是直接对这个 DP 本身进行优化这样一种思想,而不是通过分析具体题目的性质进行处理,因此这种算法具有更高的通用性。其次,由于这个算法是直接对这个 DP 本身进行优化,因此正确性显然,细节也要少于论文中介绍的在区间中维护 \(D_{a,b}(z)\) 信息的方法(维护 \(D_{a,b}(z)\) 这个方法必须严格分类,因此细节繁多,常数也较大)。因此这个算法比前一个的算法更加优秀。
然而,事实上这个算法同样利用了题目的一些性质——这题是计数类问题,而且转移是线性变换,因此可以用矩阵来维护,而矩阵恰恰是一种可以合并的变换。那么对于其他的题目,是否也能用这种基于变换合并的算法呢? (答案是可以的,下文略)
再分析
猫锟的写法不利于实现,参照Achen的题解。
设为\(f(e)\)为当前子树中包含根节点的每种权值联通块数目的生成函数,\(g(e)\)为子树中所有的每种权值联通块数目的生成函数(g就是答案的生成函数啦)。y是x的儿子。
\]
每个\(f\)后面加了一个\(e^0\)这是为了处理乘起来的时候最后要加一个\(e^0\),我们直接把\(f\)定义中加一个\(e^0\),这样最后用的时候减去一个\(e^0\)就行了。
这个dp是可以用FWT优化的,FWT后可以直接乘除和加减,且可以最后再在根上IFWT回去得到需要的\(g_{root}(e)\),就非常方便了。
带修改我们仍然树剖,下面y为x的轻儿子。
\]
写成矩阵
\]
这样直接套上面那个模板,矩阵里面套数组,就可以$$O(nm\log n*3^3)$$了,应该是可以过的,如果写树剖上线段树再带一个log就不知道能不能过了。
这个矩阵同样具有封闭运算性质:
\]
只需要对每个矩阵维护a,b,c,d就可以了。且这就是一个子段和的形式。不太清楚有没有什么直接得到子段和的方式。
既然舍掉了\(9 \times 9\)的矩阵,那么叶子节点如何初始化?方法是把叶子节点也写成4元素矩阵的形式,最后把系数矩阵乘以一个\(\begin{bmatrix}e^0 \\ 0\\ 1\end{bmatrix}\),相当于从一个虚拟节点转移过来就行了。
这题因为取模又是除法,10007的倍数没有逆元,所以要记录模意义下0的个数来达到除0的目的。
#include<bits/stdc++.h>
#define rg register
#define il inline
#define co const
template<class T>il T read(){
rg T data=0,w=1;
rg char ch=getchar();
while(!isdigit(ch)){
if(ch=='-') w=-1;
ch=getchar();
}
while(isdigit(ch))
data=data*10+ch-'0',ch=getchar();
return data*w;
}
template<class T>il T read(rg T&x){
return x=read<T>();
}
typedef long long ll;
co int N=3e4+7,mod=10007,inv2=5004;
int n,m,val[N],UP,K,inv[mod+7];
char op[10];
void FWT(int a[],int f){
for(int i=1;i<UP;i<<=1)
for(int j=0,pp=i<<1;j<UP;j+=pp)
for(int k=0;k<i;++k){
int x=a[j+k],y=a[i+j+k];
a[j+k]=(x+y)%mod,a[i+j+k]=(x-y+mod)%mod;
if(f==-1) (a[j+k]*=inv2)%=mod,(a[i+j+k]*=inv2)%=mod;
}
}
struct num{
int v,c;
}fy[N][128];
num operator*(co num&A,co num&B) {return (num){A.v*B.v%mod,A.c+B.c};}
num operator/(co num&A,co num&B) {return (num){A.v*inv[B.v]%mod,A.c-B.c};}
void get(num a[],int b[]) {for(int i=0;i<UP;++i) b[i]=a[i].c?0:a[i].v;}
void get(int a[],num b[]) {for(int i=0;i<UP;++i) b[i]=a[i]?(num){a[i],0}:(num){1,1};}
struct jz{
int a[128],b[128],c[128],d[128];
friend jz operator*(co jz&A,co jz&B){
jz rs;
for(int i=0;i<UP;++i){
rs.a[i]=A.a[i]*B.a[i]%mod;
rs.b[i]=(A.a[i]*B.b[i]%mod+A.b[i])%mod;
rs.c[i]=(A.c[i]*B.a[i]%mod+B.c[i])%mod;
rs.d[i]=(A.c[i]*B.b[i]%mod+A.d[i]+B.d[i])%mod;
}
return rs;
}
}dt[N],sum[N];
int prval[128][128];
void pre(){
inv[0]=inv[1]=1;
for(int i=2;i<mod;++i) inv[i]=mod-mod/i*inv[mod%i]%mod;
for(int i=0;i<UP;++i){
for(int j=0;j<UP;++j) prval[i][j]=0;
prval[i][i]=1;
FWT(prval[i],1);
}
}
void get_f(int a[],int val){
for(int i=0;i<UP;++i) a[i]=prval[val][i];
}
int ecnt,fir[N],nxt[N<<1],to[N<<1];
void add(int u,int v){
nxt[++ecnt]=fir[u],fir[u]=ecnt,to[ecnt]=v;
nxt[++ecnt]=fir[v],fir[v]=ecnt,to[ecnt]=u;
}
int sz[N],nsz[N],hvson[N],mson[N];
void dfs1(int x,int fa){
sz[x]=1;
for(int i=fir[x];i;i=nxt[i]) if(to[i]!=fa){
dfs1(to[i],x);
hvson[x]++;
sz[x]+=sz[to[i]];
if(!mson[x]||sz[to[i]]>sz[mson[x]]) mson[x]=to[i];
}
hvson[x]=hvson[x]>1?1:0;
nsz[x]=sz[x]-sz[mson[x]];
}
int p[N],ch[N][2];
#define lc ch[x][0]
#define rc ch[x][1]
bool isroot(int x) {return ch[p[x]][0]!=x&&ch[p[x]][1]!=x;}
void upd(int x){
if(lc) sum[x]=sum[lc]*dt[x];else sum[x]=dt[x];
if(rc) sum[x]=sum[x]*sum[rc];
}
int sta[N],top;
int build(int l,int r){
int tot=0,ntot=0;
for(int i=l;i<=r;++i) tot+=nsz[sta[i]];
for(int i=l;i<=r;++i){
ntot+=nsz[sta[i]];
if(ntot*2>=tot){
int x=sta[i];
lc=build(l,i-1);if(lc) p[lc]=x;
rc=build(i+1,r);if(rc) p[rc]=x;
upd(x);return x;
}
}return 0;
}
int RT,tpf[N];
num tpff[N];
void getac(int x){
get_f(dt[x].a,val[x]);
if(hvson[x]){
get(fy[x],tpf);
for(int l=0;l<UP;++l) (dt[x].a[l]*=tpf[l])%=mod;
}
for(int i=0;i<UP;++i) dt[x].c[i]=dt[x].a[i];
}
int dfs2(int x){
for(int y=x;y;y=mson[y]){
get_f(dt[y].b,0);
for(int l=0;l<UP;++l) dt[y].d[l]=0;
int fl=0;
for(int i=fir[y];i;i=nxt[i]) if(sz[to[i]]<sz[y]&&to[i]!=mson[y]){
int z=dfs2(to[i]);p[z]=y;
for(int l=0;l<UP;++l) tpf[l]=(sum[z].a[l]+sum[z].b[l])%mod;
if(!fl) {get(tpf,fy[y]);fl=1;}
else {get(tpf,tpff);for(int l=0;l<UP;++l) fy[y][l]=fy[y][l]*tpff[l];}
for(int l=0;l<UP;++l) (dt[y].d[l]+=sum[z].c[l]+sum[z].d[l])%=mod;
}
getac(y);
}
top=0;
for(int i=x;i;i=mson[i]) sta[++top]=i;
return build(1,top);
}
void change(int x,int vl){
val[x]=vl;
getac(x);
while(x!=RT){
if(isroot(x)&&p[x]){
for(int l=0;l<UP;++l) tpf[l]=(sum[x].a[l]+sum[x].b[l])%mod;
get(tpf,tpff);
for(int l=0;l<UP;++l) fy[p[x]][l]=fy[p[x]][l]/tpff[l];
for(int l=0;l<UP;++l) dt[p[x]].d[l]=(dt[p[x]].d[l]-sum[x].c[l]-sum[x].d[l]+mod+mod)%mod;
}
upd(x);
if(isroot(x)&&p[x]){
for(int l=0;l<UP;++l) tpf[l]=(sum[x].a[l]+sum[x].b[l])%mod;
get(tpf,tpff);
for(int l=0;l<UP;++l) fy[p[x]][l]=fy[p[x]][l]*tpff[l];
for(int l=0;l<UP;++l) dt[p[x]].d[l]=(dt[p[x]].d[l]+sum[x].c[l]+sum[x].d[l])%mod;
getac(p[x]);
}
x=p[x];
}upd(x);
}
int main(){
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
read(n),read(UP);
pre();
for(int i=1;i<=n;++i) read(val[i]);
for(int i=1;i<n;++i) add(read<int>(),read<int>());
dfs1(1,0);
RT=dfs2(1);
int Q=read<int>();
for(int cs=1;cs<=Q;++cs){
int x,y;
scanf("%s",op);
if(op[0]=='C'){
read(x),read(y);
change(x,y);
}
else{
read(K);
for(int i=0;i<UP;++i) tpf[i]=(sum[RT].c[i]+sum[RT].d[i])%mod;
FWT(tpf,-1);
printf("%d\n",tpf[K]);
}
}
return 0;
}
无关话题
既然是或卷积,那么矩阵中0和1的意思是什么呢?
乘以1我们想要得到原来的元素,所以1代表的应该是多项式\(e^0\)。
乘以0我们想要得到0,所以0的意义就是多项式0。
综上,这个矩阵中的0和1是有意义的。
LG3781 [SDOI2017]切树游戏的更多相关文章
- 【BZOJ4911】[SDOI2017]切树游戏(动态dp,FWT)
[BZOJ4911][SDOI2017]切树游戏(动态dp,FWT) 题面 BZOJ 洛谷 LOJ 题解 首先考虑如何暴力\(dp\),设\(f[i][S]\)表示当前以\(i\)节点为根节点,联通子 ...
- BZOJ4911: [Sdoi2017]切树游戏
BZOJ 4911 切树游戏 重构了三次.jpg 每次都把这个问题想简单了.jpg 果然我还是太菜了.jpg 这种题的题解可以一眼秒掉了,FWT+动态DP简直是裸的一批... 那么接下来,考虑如何维护 ...
- LOJ2269 [SDOI2017] 切树游戏 【FWT】【动态DP】【树链剖分】【线段树】
题目分析: 好题.本来是一道好的非套路题,但是不凑巧的是当年有一位国家集训队员正好介绍了这个算法. 首先考虑静态的情况.这个的DP方程非常容易写出来. 接着可以注意到对于异或结果的计数可以看成一个FW ...
- bzoj 4911: [Sdoi2017]切树游戏
考虑维护原树的lct,在上面dp,由于dp方程特殊,均为异或卷积或加法,计算中可以只使用fwt后的序列 v[w]表示联通子树的最浅点为w,且不选w的splay子树中的点 l[w]表示联通子树的最浅点在 ...
- [SDOI2017]切树游戏
题目 二轮毒瘤题啊 辣鸡洛谷竟然有卡树剖的数据 还是\(loj\)可爱 首先这道题没有带修,设\(dp_{i,j}\)表示以\(i\)为最高点的连通块有多少个异或和为\(j\),\(g_{i,j}=\ ...
- 洛谷 P3781 - [SDOI2017]切树游戏(动态 DP+FWT)
洛谷题面传送门 SDOI 2017 R2 D1 T3,nb tea %%% 讲个笑话,最近我在学动态 dp,wjz 在学 FWT,而我们刚好在同一天做到了这道题,而这道题刚好又是 FWT+动态 dp ...
- 【LOJ】#2269. 「SDOI2017」切树游戏
题解 把所有的数组一开始就FWT好然后再IFWT回去可以减小常数 从13s跑到0.7s-- 可以参照immortalCO的论文,感受一下毒瘤的动态动态DP 就是用数据结构维护线性递推的矩阵的乘积 由于 ...
- loj#2269. 「SDOI2017」切树游戏
还是loj的机子快啊... 普通的DP不难想到,设F[i][zt]为带上根玩出zt的方案数,G[i][zt]为子树中的方案数,后面是可以用FWT优化的 主要是复习了下动态DP #include< ...
- LOJ2269. 「SDOI2017」切树游戏 [FWT,动态DP]
LOJ 思路 显然是要DP的.设\(dp_{u,i}\)表示\(u\)子树内一个包含\(u\)的连通块异或出\(i\)的方案数,发现转移可以用FWT优化,写成生成函数就是这样的: \[ dp_{u}= ...
随机推荐
- 005-matlab2018a安装破解
1.下载地址: 百度云下载链接:https://pan.baidu.com/s/1uTYAxVX1_Hx6nbsgf4W4kA 密码:asrw 官网下载地址: 2.解压. 3.双击setup.exe后 ...
- mysql索引之聚簇索引与非聚簇索引
1 数据结构及算法基础 1.1 索引的本质 官方定义:索引(Index)是帮助MySQL高效获取数据的数据结构 本质:索引是数据结构 查询是数据库的最主要功能之一.我们都希望查询速度能尽可能快,因此数 ...
- 20155305乔磊2016-2017-2《Java程序设计》第九周学习总结
20155305 2016-2017-2 <Java程序设计>第九周学习总结 教材学习内容总结 JDBC入门 JDBC简介 1.JDBC是java联机数据库的标准规范,它定义了一组标准类与 ...
- SQL: 拼接列
1. 因工作需要,需把两列(id,created_by)拼接成一列,结果很有意思,前5个值都是null. 2.解决方法:null加减乘除任何值都等于null,所以使用isnull函数先处理下列的值再拼 ...
- Ubuntu18.04 怎么开热点
先说明,电脑上要有wifi适配器,而且连接wifi时,不能开热点 我的笔记本是双系统,现在介绍一下我的设置 在设置里打开热点这个应该会吧,但是热点密码不是自己设置的,而是随机生成的,本文重点介绍一下怎 ...
- Xilinx SD controller
Features supported by driver Zynq All the HW/IP features are supported by driver ZynqMP All the HW/I ...
- nvm命令行操作命令
1,nvm nvm list 是查找本电脑上所有的node版本 - nvm list 查看已经安装的版本 - nvm list installed 查看已经安装的版本 - nvm list avail ...
- UVa 10375 选择与除法(唯一分解定理)
https://vjudge.net/problem/UVA-10375 题意: 输入整数p,q,r,s,计算C(p,q)/C(r,s). 思路: 先打个素数表,然后用一个数组e来保存每个素数所对应的 ...
- UVa 12034 比赛名次(递推)
https://vjudge.net/problem/UVA-12034 题意: A.B两人赛马,最终名次有3种可能:并列第一:A第一B第二:B第一A第二.输入n,求n人赛马时最终名次的可能性的个数除 ...
- postgres10.2时区研究
搭建两个虚拟环境,操作系统均是cents7. 环境A: 使用timedatectl命令查看时区为 Time zone: Asia/Shanghai (CST, +0800). 本地数据库时区(show ...