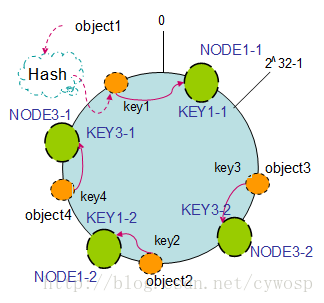
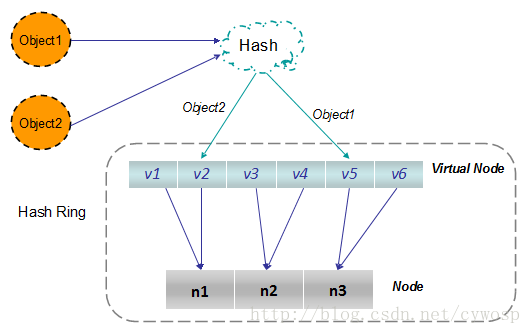
hash环/consistent hashing一致性哈希算法
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。

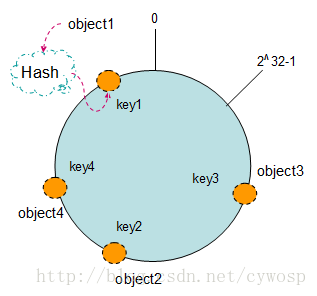
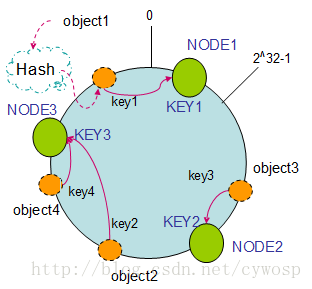
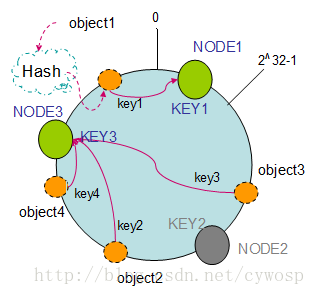
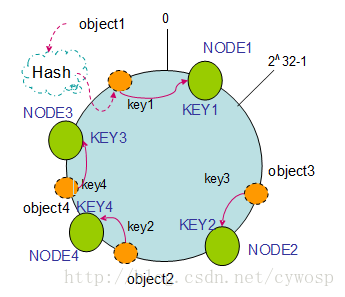
hash环/consistent hashing一致性哈希算法的更多相关文章
- Consistent hashing —— 一致性哈希
原文地址:http://www.codeproject.com/Articles/56138/Consistent-hashing 基于BSD License What is libconhash l ...
- 一致性哈希算法(consistent hashing)(转)
原文链接:每天进步一点点——五分钟理解一致性哈希算法(consistent hashing) 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网 ...
- 一致性哈希算法学习及JAVA代码实现分析
1,对于待存储的海量数据,如何将它们分配到各个机器中去?---数据分片与路由 当数据量很大时,通过改善单机硬件资源的纵向扩充方式来存储数据变得越来越不适用,而通过增加机器数目来获得水平横向扩展的方式则 ...
- _00013 一致性哈希算法 Consistent Hashing 新的讨论,并出现相应的解决
笔者博文:妳那伊抹微笑 博客地址:http://blog.csdn.net/u012185296 个性签名:世界上最遥远的距离不是天涯,也不是海角,而是我站在妳的面前.妳却感觉不到我的存在 技术方向: ...
- 一致性哈希算法(Consistent Hashing Algorithm)
一致性哈希算法(Consistent Hashing Algorithm) 浅谈一致性Hash原理及应用 在讲一致性Hash之前我们先来讨论一个问题. 问题:现在有亿级用户,每日产生千万级订单,如 ...
- 转 白话解析:一致性哈希算法 consistent hashing
摘要: 本文首先以一个经典的分布式缓存的应用场景为铺垫,在了解了这个应用场景之后,生动而又不失风趣地介绍了一致性哈希算法,同时也明确给出了一致性哈希算法的优点.存在的问题及其解决办法. 声明与致谢: ...
- 一致性哈希算法(consistent hashing)PHP实现
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简单哈希 ...
- 一致性哈希算法 - consistent hashing
1 基本场景比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 ...
- 一致性哈希算法(Consistent Hashing) .
应用场景 这里我先描述一个极其简单的业务场景:用4台Cache服务器缓存所有Object. 那么我将如何把一个Object映射至对应的Cache服务器呢?最简单的方法设置缓存规则:object.has ...
随机推荐
- C# 委托/Func() 中 GetInvocationList() 方法的使用 | 接收委托多个返回值
在日常使用委托时,有以下常用方法 方法名称 说明 Clone 创建委托的浅表副本. GetInvocationList 按照调用顺序返回此多路广播委托的调用列表. GetMethodIm ...
- codeforces 156D Clues(prufer序列)
codeforces 156D Clues 题意 给定一个无向图,不保证联通.求添加最少的边使它联通的方案数. 题解 根据prufer序列,带标号无根树的方案数是\(n^{n-2}\) 依这个思想构建 ...
- python选课系统
程序名称: 选课系统 角色:学校.学员.课程.讲师 要求: 1. 创建北京.上海 2 所学校 2. 创建linux , python , go 3个课程 , linux\py 在北京开, go 在上海 ...
- oracle 查看主外键约束
select a.constraint_name, a.table_name, b.constraint_name from user_constraints a, user_constraints ...
- Java 读取Excel数据——POI-3.11 XSSF
POI - the Java API for Microsoft Documents 1.在Apache官网下载Apache最新poi版本:poi-bin-3.11-20141221.zip,解压: ...
- HashMap源代码解析
HashMap原理剖析 之前有看过别人的HashMap源代码的分析,今天尝试自己来分析一波,纯属个人愚见.听一些老的程序员说过,当别人跟你说用某样技术到项目中去,而你按照别人的想法实现了的时候,你只能 ...
- iOS UI(绘图)的几张原理图
Core Animation是对OpenGL ES的Objective-C封装,具有与OpenGL ES几乎等价的高性能,却隐藏了OpenGL ES的复杂性. https://www.cnblogs. ...
- eclipse 自动生成get/set方法
Shift+Alt+S 会弹出一个对话框 选择Generate Getters and Setters
- VIM之打开、保存文件
如何使用命令 在Normal mode下,输入':'字符,在GVIM界面左下可以看到如图所示的界面: 这时候可以键入命令,输入完后按下键盘上的Enter键即可执行命令. 打开文件 使用命令:e [文件 ...
- inux下使用自带mail发送邮件告警
安装mailx工具,mailx是一个小型的邮件发送程序. 具体步骤如下: 1.安装 [root@localhost ~]# yum -y install mailx 2.编辑配置文件 [root@lo ...