KMP算法匹配原理以及C++实现
原创作品,转载请注明出处:点我



#ifndef __KMP__H__
#define __KMP__H__
#include <string>
#include <vector>
using namespace std; class KMP{
public:
//void static getNext(const string &str,vector<int> &vec);
int kmp();
KMP(){}
KMP( const string &target,const string &pattern):mTarget(target),mPattern(pattern){}
void setTarget(const string &target);
void setPattern(const string &pattern);
private:
vector< int> mVec;
string mTarget;
string mPattern;
void getNext();
};
#endif
下面是源代码实现
#include "KMP.h"
#include <iostream>
#include <vector>
using namespace std; //获取字符串str的所有子串中相同子集的长度
//比如字符串ababacb,分别获取字符串a,ab,aba,abab,ababa,ababac,ababacb中D
//最前面和最后面相同的子串的最大长度,比如
//a:因为aa为a单个字符,所以最前面和最后面相同的子串的最大长度为a0
//aba,最前面一个a和最后面一个元a素a相同,所以值为a1,abab最前面2个ab和最后面两个ab相同,值为a2
//ababa最前面3个为aaba,最后面3个为aaba,所以值为a3
void KMP::getNext()
{
mVec.clear(); //清空?ec
//vec.push_back(0);//为a了使用方便,vec的第一个数据不用
mVec.push_back(); //第一个字符的下一个位置一定是0,比如"ababacb",首字符a的值为0
string::const_iterator start = mPattern.begin();
string::const_iterator pos = start + ;
while(pos != mPattern.end())
{
string subStr(start,pos+); //获取子字符串
int strLen = subStr.size() - ;//获取子串中D前后相同的子子串的最大长度
do
{
string prefix(subStr,,strLen); //获取subStr中D的前面strLen子集
string postfix(subStr,subStr.size()-strLen,strLen); //获取subStr中D的前面?trLen子集
if(prefix == postfix)
{
mVec.push_back(strLen);
break;
}
--strLen;
/如果前后相同的子集的长度小于一
/说明没有相同的,则把0压栈
if(strLen < )
mVec.push_back();
} while(strLen > ); ++pos;
}
} void KMP::setPattern(const string &pattern)
{
mPattern = pattern;
} void KMP::setTarget(const string &target)
{
mTarget = target;
} int KMP::kmp()
{
getNext(); //首先获取next数据
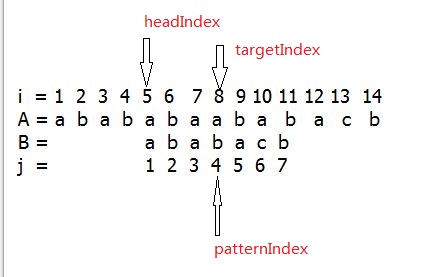
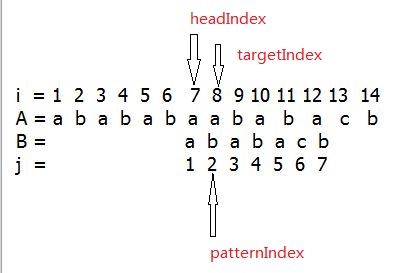
int targetIndex = ;
int patternIndex = ;
int headIndex = ;//指向跟pattern匹配的Target的第一个元素的索引
while(patternIndex != mPattern.size() && targetIndex != mTarget.size())
{
for(int i = ; i < mPattern.size()-;++i)
{
if(mPattern[patternIndex] == mTarget[targetIndex])
{
++patternIndex;
++targetIndex;
if(mPattern.size()== patternIndex)//如果已经匹配成功,则退出循环
break;
}
else
{
if( == patternIndex)//如果第一个字符就不匹配,则把mTarget左移一位
++headIndex;
else
{
headIndex += patternIndex - mVec[patternIndex-];//由于vector索引从零开始,所以要减去一
patternIndex = mVec[patternIndex-];//更新patternIndex索引
}
targetIndex = headIndex + patternIndex;//跟新targetIndex索引
break;
} }
} return headIndex;
}
KMP算法匹配原理以及C++实现的更多相关文章
- 字符串匹配--kmp算法原理整理
kmp算法原理:求出P0···Pi的最大相同前后缀长度k: 字符串匹配是计算机的基本任务之一.举例,字符串"BBC ABCDAB ABCDABCDABDE",里面是否包含另一个字符 ...
- [Algorithm] 字符串匹配算法——KMP算法
1 字符串匹配 字符串匹配是计算机的基本任务之一. 字符串匹配是什么?举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串& ...
- 深入理解KMP算法
前言:本人最近在看<大话数据结构>字符串模式匹配算法的内容,但是看得很迷糊,这本书中这块的内容感觉基本是严蔚敏<数据结构>的一个翻版,此书中给出的代码实现确实非常精炼,但是个人 ...
- KMP算法详解 --- 彻头彻尾理解KMP算法
前言 之前对kmp算法虽然了解它的原理,即求出P0···Pi的最大相同前后缀长度k. 但是问题在于如何求出这个最大前后缀长度呢? 我觉得网上很多帖子都说的不是很清楚,总感觉没有把那层纸戳破, 后来翻看 ...
- 模式匹配KMP算法
关于KMP算法的原理网上有很详细的解释,我试着总结理解一下: KMP算法是什么 以这张图片为例子 匹配到j=5时失效了,BF算法里我们会使i=1,j=0,再看s的第i位开始能不能匹配,而KMP算法接下 ...
- 数据结构(复习)---------字符串-----KMP算法(转载)
字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD" ...
- KMP算法详解 --从july那学的
KMP代码: int KmpSearch(char* s, char* p) { ; ; int sLen = strlen(s); int pLen = strlen(p); while (i &l ...
- KMP算法的一次理解
1. 引言 在一个大的字符串中对一个小的子串进行定位称为字符串的模式匹配,这应该算是字符串中最重要的一个操作之一了.KMP本身不复杂,但网上绝大部分的文章把它讲混乱了.下面,咱们从暴力匹配算法讲起,随 ...
- 字符串匹配KMP算法详解
1. 引言 以前看过很多次KMP算法,一直觉得很有用,但都没有搞明白,一方面是网上很少有比较详细的通俗易懂的讲解,另一方面也怪自己没有沉下心来研究.最近在leetcode上又遇见字符串匹配的题目,以此 ...
随机推荐
- 开源的数据可视化JavaScript图表库:ECharts
ECharts (Enterprise Charts 商业产品图表库)是基于HTML5 Canvas的一个纯Javascript图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表.创新的拖拽 ...
- 如何查看USB方式连接Android设备的外接设备信息
1,USB存储设备(如:U盘,移动硬盘): //USB存储设备 插拔监听与 SD卡插拔监听一致. private USBBroadCastReceiver mBroadcastReceiver; In ...
- Android开发学习之3大类菜单
在Android系统中,菜单可以分为三类:选项菜单(Option Menu),上下文菜单(Context Menu)以及子菜单(Sub Menu). 一.选项菜单(Option Menu) 创建选项菜 ...
- Linux时间子系统(十三) Tick Device layer综述
一.前言 时间子系统中的tick device layer主要涉及kernel/time/tick-*相关的文件,本文的主要内容就是从high level层次(不纠缠在具体的每行代码)描述tick d ...
- MAC 上搭建lua
下载和安装lua:(转自这里) 1. 下载最新版的lua-5.3.1.tar.gz 请点击(http://www.lua.org/ftp/),然后解压 2. 执行"终端"进入到 ...
- java的jdbc简单封装
在学了jdbc一段时间后感觉自己写一个简单的封装来试试,于是參考的一些资料就写了一下不是多好,毕竟刚学也不太久 首先写配置文件:直接在src下建立一个db.properties文件然后写上内容 < ...
- mysql特殊语句学习
一.Mysql ON子句和USING子句 Mysql 中联接SQL语句中,ON子句的语法格式为:table1.column_name = table2.column_name. 当模式设计对联接表的列 ...
- Android Gradle 引用本地 AAR 的几种方式
折衷方案: 1.方式2 - 不完美解决办法2 2.再使用"自定义Gradle代码"来减轻重复设置的问题. 自定义Gradle代码如下: repositories { flatDir ...
- 用rfkill命令管理蓝牙和wifi
rfkill是一个内核级别的管理工具,可以打开和关闭设备的蓝牙和wifi. #列出所有可用设备rfkill list 输出如下:0: phy0: Wireless LAN Soft blocke ...
- [na]锐起无盘机并发部署多台windows
小时候很好奇这个技术,也并无卵,只是为了遂儿时愿, 用到锐起无盘部署,支持win7哦: 视频教程: 拓展:网吧电脑为什么没有硬盘? 网吧电脑没有硬盘是怎么运行的? 所需软件: https://yunp ...