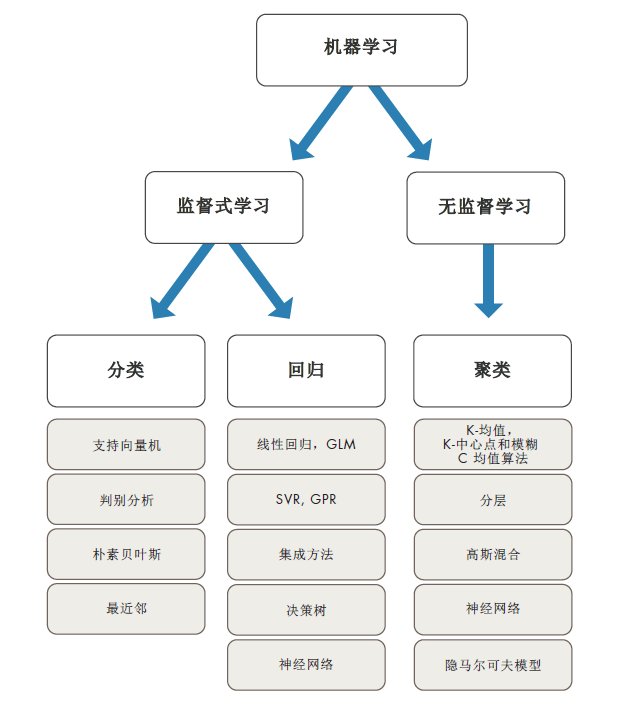
Machine Learning 之二,什么监督性学习,非监督性学习。
1.什么是监督性学习?Supervised Machine Learning.
在监督性学习,我们给定一个数据集以及我们已经知道正确输出的结果,然后找到一个输入和输出的关系。
In Supervised learning,we are given a data set and already know what our correct output should look like ,having the idea that there is a relationship between the input and output.
监督性学习的问题被分为两大类,第一类是回归问题,第二类是分类问题。在回归问题,我们试着预测结果在连续输出,意味着我们试图将输入变量映射到某个连续函数。在分类问题中,相反,我们试图预测离散输出的结果。换句话说,我们试图将输入变量映射到离散类别中。
监督性学习目的是在构建能够根据存在不确定性的证据做出预测的模型。监督性学习算法接受已知的输入数据集和对数据的已知响应输出,然后训练模型,让模型能够未新输入数据的响应生成合理的预测。
监督性学习采用分类(classification)和(regression)技术开发预测模型。
1.分类技术可预测离散的响应(输出)--例如:
电子邮件是真正的邮件还是垃圾邮件,肿瘤是恶性还是良性。分类模型可将输入数据划分不同类别。典型应用包括:医学成像,语音识别,信用评估。
2,回归技术可预测连续的响应--例如,电力需求中温度或波动的变化。
典型的应用包括:电力系统负荷预测和算法交易。
应用:
使用监督性学习预测心脏病发作
假设临床医生希望预测某位患者在一年内是否会心脏病发作,他们有一千就医患者的患者相关数据,包括年龄,体重,身高以及血压。他们呢hi到一千的患者在一年内是否出现过心脏病发作,因此,问题在于如何将现有数据合并到模型中,并让该模型能够预测新患者在一年内是否出现心脏病发作。
2. 什么是非监督性学习?UnSupervised Machine Learning.
非监督性学习可发现数据中隐藏的模式或内在结构,这种技术可包含未标记响应的输入数据的数据集执行推理。
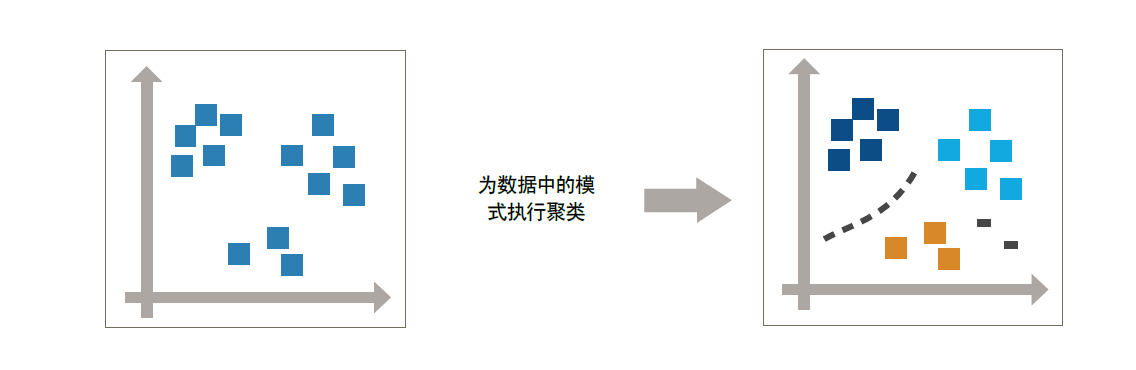
聚类是一种最常用的无监督性学习技术,这种技术可通过探索性数据分析发现数据中隐藏的模式或分组。
聚类的应用包括基因序列分析,市场调查和对象识别。
总结:
监督性机器学习就是根据已知的输入和输出训练模型,让模型能够预测未来输出。
非监督性机器学习就是从输入数据中找出隐藏模式或内在结构。

那么如何确定使用哪种算法?
选择正确的算法看似难以驾驭,需要从几十种监督性学习和非监督性学习算法中选择,每种算法又包含不同的学习方法。
没有最佳方法和完全之策。找到正确的算法知识是错过程的一部分,即使经验丰富的数据科学家,也无法说出某种算法是否无需试错即可使用,但是算法的选择还却决我们要处理数据的大小以及类型,要从数据中获取洞察力以及如何使用这些洞察力。这才是机器学习的开始。。
PS:
知识引用
吴恩达的机器学习
matlab的机器学习
Machine Learning 之二,什么监督性学习,非监督性学习。的更多相关文章
- 斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)
下图为四种不同算法应用在不同大小数据量时的表现,可以看出,随着数据量的增大,算法的表现趋于接近.即不管多么糟糕的算法,数据量非常大的时候,算法表现也可以很好. 数据量很大时,学习算法表现比较好的原理: ...
- 学习笔记之机器学习(Machine Learning)
机器学习 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0 机器学习是人工智能的一个分 ...
- 我的Machine Learning学习之路
从2016年年初,开始用python写一个简单的爬虫,帮我收集一些数据. 6月份,开始学习Machine Learning的相关知识. 9月开始学习Spark和Scala. 现在想,整理一下思路. 先 ...
- 【转载】 我的Machine Learning学习之路
原文地址: https://www.cnblogs.com/steven-yang/p/5857964.html ------------------------------------------- ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
- data mining,machine learning,AI,data science,data science,business analytics
数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics ...
- 数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics)之间有什么关系?
本来我以为不需要解释这个问题的,到底数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)有什么区别,但是前几天因为有个学弟问我,我想了想发现我竟然也回答 ...
- 【Machine Learning】监督学习、非监督学习及强化学习对比
Supervised Learning Unsupervised Learning Reinforced Learning Goal: How to apply these methods How t ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
随机推荐
- Python基础教程(002)--编译型语音和解释器
前言 理解解释器和编译型语言,及跨平台 解释器(科普) 计算机不能直接理解任何出机器语言以外的机器语言,必须要把程序员写的程序语言进行翻译,就是编辑. 将其他语音翻译成机器语言,被称为编译器. 编译器 ...
- sql查询50题
一个项目涉及到的50个Sql语句问题及描述:--1.学生表Student(S#,Sname,Sage,Ssex) --S# 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别--2 ...
- svn 版本管理,trunk(主干),branch(分支),merge(合并)
svn 版本管理,主要对trunk(主干).branch(分支).merge(合并)进行说明. svn作为一个常用的版本管理工具,一些基本操作必须要会,在这里整理一下自己使用svn的一些体会: svn ...
- STM32 系统架构
这里所讲的 STM32 系统架构主要针对的 STM32F103 这些非互联型芯片 STM32 主系统主要由四个驱动单元和四个被动单元构成. 四个驱动单元是: 内核 DCode 总线; 系统总线;通用 ...
- Codeforces Round #499 (Div. 2) Problem-A-Stages(水题纠错)
CF链接 http://codeforces.com/contest/1011/problem/A Natasha is going to fly to Mars. She needs to bui ...
- 递归中,调用forEach方法问题
1 function traverse(objNmae,obj,url){ url = url || objNmae; if(typeof obj === "object" ){ ...
- Leetcode_415字符串相加
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和. 注意: ①num1 和num2 的长度都小于 5100.②num1 和num2 都只包含数字 0-9.③num1 和num2 都不 ...
- Pyhon 格式化输出的几种方式
废话不多说,直接上代码 第一种格式化的输出方式,拼接我就不上了,不建议使用,数据多的时候自己都蒙圈 # -*- coding:utf-8 -*- # Author:覃振鸿 #格式化输出 name=in ...
- Opencv 特征提取与检测-Haar特征
Haar特征介绍(Haar Like Features) 高类间变异性 低类内变异性 局部强度差 不同尺度 计算效率高 这些所谓的特征不就是一堆堆带条纹的矩形么,到底是干什么用的?我这样给出 ...
- Python操作MySQL实战案例讲解
使用Python的pymysql库连接MySQL数据库 #导入pymysql import pymysql #连接MySQL数据库 #输入数据库的IP地址,用户名,密码,端口 db=pymysql.c ...