[论文理解] Squeeze-and-Excitation Networks
Squeeze-and-Excitation Networks
简介
SENet提出了一种更好的特征表示结构,通过支路结构学习作用到input上更好的表示feature。结构上是使用一个支路去学习如何评估通道间的关联,然后作用到原feature map上去,实现对输入的校准。支路的帮助学习到的是神经网络更加适合的表示。为了使网络通过全局信息来衡量通道关联,结构上使用了global pooling捕获全局信息,然后连接两个全连接层,作用到输入上去,即完成了对输入的重校准,可以使网络学习到更好的表示。
SQUEEZE-AND-EXCITATION BLOCKS
一个block的结构大致如下:
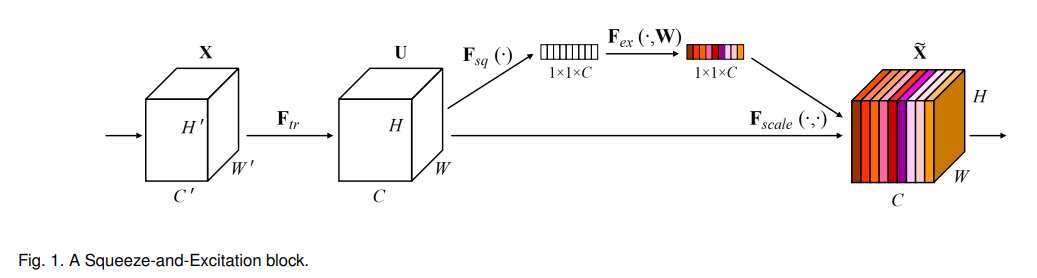
上图中Fsq是Squeeze过程,Fex是Excitation过程,然后通过Fscale将学习到的权重作用在输入上。
Squeeze: Global Information Embedding
作者将Squeeze过程称为global information embedding的过程,因为squeeze的过程实际上是对feature map利用global pooling来整合全局特征。
Excitation: Adaptive Recalibration
作者将Excitation过程称为重校准过程,因为此过程通过支路学习到的权重,作用到原输入上去,要实现对每个通道进行打分,即网络学习到通道score,则必须要学习到非线性结果,所以作者采用fc-relu-fc-sigmoid的excitation结构来实现score映射。
根据作者论文中的举例,可以清楚看到以Inception为例的Squeeze和Excitation过程:
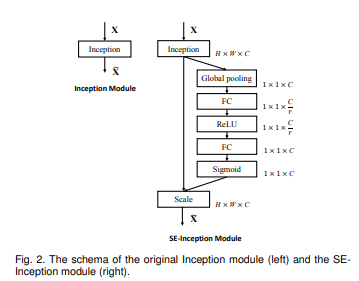
而Fscale过程就是对应相乘,把每个通道的权重对应乘上input的对应通道feature。
这个论文比较好理解。
简单写了一个block:
import torch
import torch.nn as nn
class SEModule(nn.Module):
def __init__(self,r = 3):
super(SEModule,self).__init__()
self.global_pooling = nn.MaxPool2d(128)
self.fc1 = nn.Linear(64,64//r)
self.relu1 = nn.ReLU(64//r)
self.fc2 = nn.Linear(64//r,64)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
se_x = self.global_pooling(x)
se_x = self.fc1(se_x.view(-1,64))
se_x = self.relu1(se_x)
se_x = self.fc2(se_x)
se_x = self.sigmoid(se_x).view(-1,64,1,1)
return x * se_x
if __name__ =="__main__":
from torchsummary import summary
model = SEModule()
summary(model,(64,128,128),device = "cpu")
'''
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
MaxPool2d-1 [-1, 64, 1, 1] 0
Linear-2 [-1, 21] 1,365
ReLU-3 [-1, 21] 0
Linear-4 [-1, 64] 1,408
Sigmoid-5 [-1, 64] 0
================================================================
Total params: 2,773
Trainable params: 2,773
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 4.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.01
Estimated Total Size (MB): 4.01
----------------------------------------------------------------
'''
论文原文:https://arxiv.org/pdf/1709.01507.pdf
[论文理解] Squeeze-and-Excitation Networks的更多相关文章
- [论文理解] Learning Efficient Convolutional Networks through Network Slimming
Learning Efficient Convolutional Networks through Network Slimming 简介 这是我看的第一篇模型压缩方面的论文,应该也算比较出名的一篇吧 ...
- 图像处理论文详解 | Deformable Convolutional Networks | CVPR | 2017
文章转自同一作者的微信公众号:[机器学习炼丹术] 论文名称:"Deformable Convolutional Networks" 论文链接:https://arxiv.org/a ...
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- [论文理解]关于ResNet的进一步理解
[论文理解]关于ResNet的理解 这两天回忆起resnet,感觉残差结构还是不怎么理解(可能当时理解了,时间长了忘了吧),重新梳理一下两点,关于resnet结构的思考. 要解决什么问题 论文的一大贡 ...
- [论文理解] CornerNet: Detecting Objects as Paired Keypoints
[论文理解] CornerNet: Detecting Objects as Paired Keypoints 简介 首先这是一篇anchor free的文章,看了之后觉得方法挺好的,预测左上角和右下 ...
- [论文理解] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 简介 Faster R-CNN是很经典的t ...
- [论文理解]Region-Based Convolutional Networks for Accurate Object Detection and Segmentation
Region-Based Convolutional Networks for Accurate Object Detection and Segmentation 概括 这是一篇2016年的目标检测 ...
- [论文理解] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications Intro MobileNet 我 ...
- [论文理解] Spatial Transformer Networks
Spatial Transformer Networks 简介 本文提出了能够学习feature仿射变换的一种结构,并且该结构不需要给其他额外的监督信息,网络自己就能学习到对预测结果有用的仿射变换.因 ...
随机推荐
- appium+python自动化项目实战(二):项目工程结构
废话不多说,直接上图: nose.cfg配置文件里,可以指定执行的测试用例.生成测试报告等.以后将详细介绍.
- 曹工说Spring Boot源码(5)-- 怎么从properties文件读取bean
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- vue 条件渲染 v-if v-show
1.要点 1.1 v-if 条件性地渲染一块内容 <h1 v-if="awesome">Vue is awesome!</h1> 附带 / v- ...
- springboot学习1
gradle环境配置 https://www.w3cschool.cn/gradle/ctgm1htw.html Spring profile 多环境配置管理 参考:https://www.cnblo ...
- 用 C++ 模板元编程实现有限的静态 introspection
C++ 中的奇技淫巧大部分来源于模板技术,尤其是模版元编程技术(Template Meta-Programming, TMP).TMP 通过将一部分计算任务放在编译时完成,不仅提高了程序的性能,还能让 ...
- centos7搭建docker+k8s集成
1. 关闭防火墙 # systemctl stop firewalld # systemctl disable firewalld # setenforce 2. 使用yum安装etcd和kubern ...
- Electron 5.0 发布
Electron 5.0的主要变化 打包应用程序现在的行为与默认应用程序相同.将创建一个默认的应用程序菜单(除非应用程序有一个),并且将自动处理全部关闭窗口的事件. (除非应用程序处理事件) 现在默认 ...
- ui自动化之selenium操作(三)xpath定位
xpath 的定位方法,非常强大.使用这种方法几乎可以定位到页面上的任意元素. 1. 什么是xpath? xpath 是XML Path的简称, 由于HTML文档本身就是一个标准的XML页面,所以我们 ...
- Xunsearch入门
Xunsearch入门 简介: 开源免费.高性能.多功能.简单易用的专业全文检索技术方案. 1.Xunsearch安装: (1)官网(http://xunsearch.com)下载 wget http ...
- Django 创建 hello world
前言 用Django 创建 hello 哈哈,对这个还是有点意思的 创建文件 在你的目录下 比如我是 F:\python\django 的输入下面的代码: django-admin startproj ...