SparkSQL(一)
一、概述
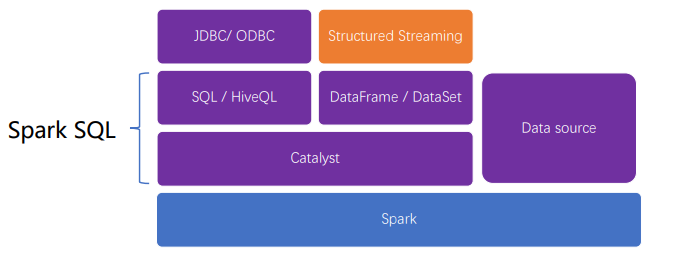
组件

运行机制

转 SparkSQL – 从0到1认识Catalyst https://blog.csdn.net/qq_36421826/article/details/81988157
更高效

查询优化

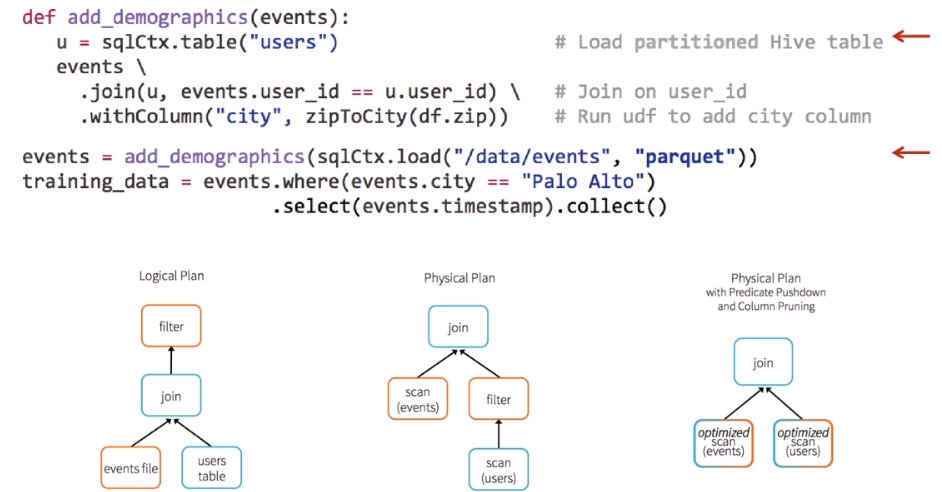
优化:把filter提前
数据源优化

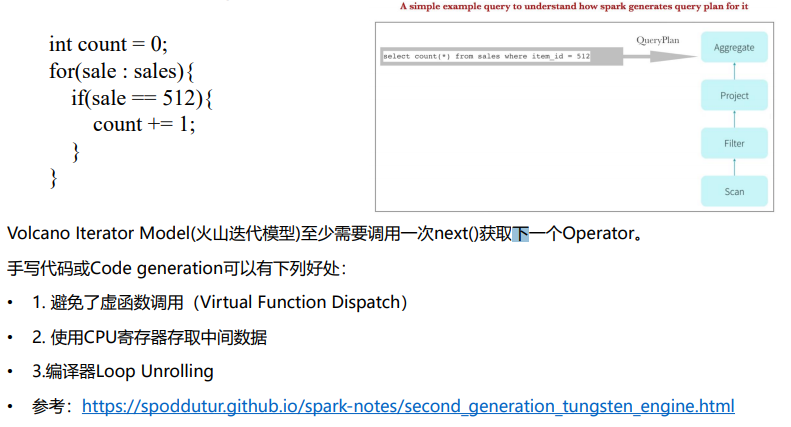
编译优化 Code generation

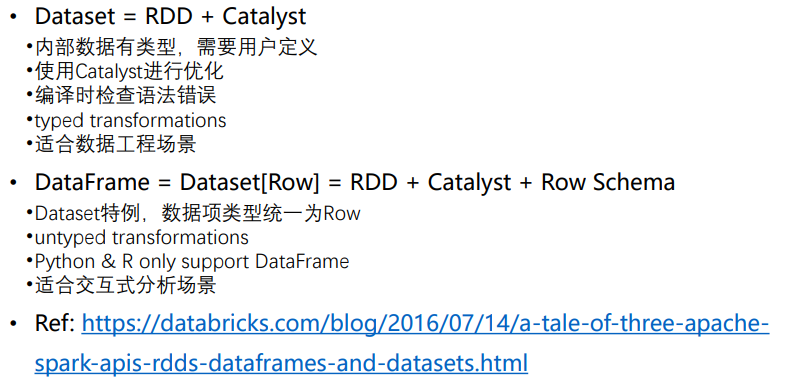
DataSet和DataFrame

数据源

Parquet文件
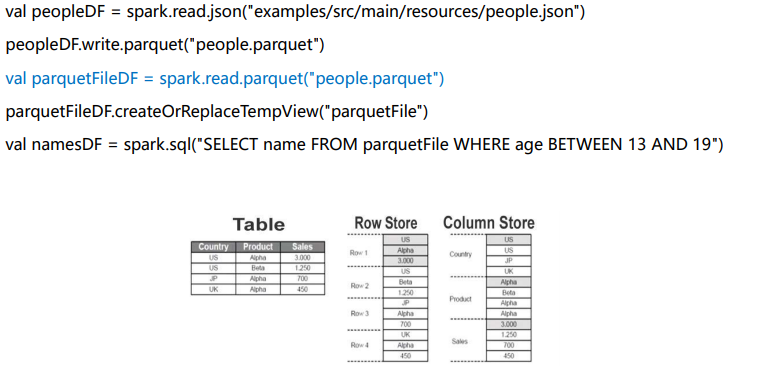
Json文件

读取Hive中文件

外部数据源spark.read.format

二、程序设计
常规流程

API:SQL与DataFrame DSL


统计分析内容大小-全部内容大小,日志条数,最小内容大小,最大内容大小
package org.sparkcourse.log
import org.apache.spark.sql.{Row, SparkSession}
object LogAnalyzerSQL {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Log Analyzer")
.master("local")
.getOrCreate()
import spark.implicits._
val accessLogs = spark
.read
.textFile("data/weblog/apache.access.log")
.map(ApacheAccessLog.parseLogLine).toDF()
accessLogs.createOrReplaceTempView("logs")
// 统计分析内容大小-全部内容大小,日志条数,最小内容大小,最大内容大小
val contentSizeStats: Row = spark.sql("SELECT SUM(contentSize), COUNT(*), MIN(contentSize), MAX(contentSize) FROM logs").first()
val sum = contentSizeStats.getLong(0)
val count = contentSizeStats.getLong(1)
val min = contentSizeStats.getLong(2)
val max = contentSizeStats.getLong(3)
println("sum %s, count %s, min %s, max %s".format(sum, count, min, max))
println("avg %s", sum / count)
spark.close()
}
}
ApacheAccessLog
package org.sparkcourse.log import sun.security.x509.IPAddressName case class ApacheAccessLog(ipAddress: String,
clientIdentd: String,
userId: String,
dateTime: String,
method: String,
endpoint: String,
protocol: String,
responseCode: Int,
contentSize: Long){
} object ApacheAccessLog {
// 64.242.88.10 - - [07/Mar/2004:16:05:49 -0800] "GET /twiki/bin/edit/Main/Double_bounce_sender?topicparent=Main.ConfigurationVariables HTTP/1.1" 401 12846
val PATTERN = """^(\S+) (\S+) (\S+) \[([\w:/]+\s+\-\d{4})\] "(\S+) (\S+) (\S+)" (\d{3}) (\d+)""".r def parseLogLine(log: String): ApacheAccessLog = {
log match {
case PATTERN(ipAddress, clientIdentd, userId, dateTime, method, endpoint, protocol, responseCode, contentSize)
=> ApacheAccessLog(ipAddress, clientIdentd, userId, dateTime, method, endpoint, protocol, responseCode.toInt, contentSize.toLong)
case _ => throw new RuntimeException(s"""Cannot parse log line: $log""")
}
}
String 的 .r 方法 将字符串转为正则表达式
方式一: 通过case class创建DataFrames(反射)
TestDataFrame1.scala
package com.bky // 隐式类的导入
// 定义case class,相当于表结构
case class Dept(var id:Int, var position:String, var location:String) // 需要导入SparkSession这个包
import org.apache.spark.sql.SparkSession /**
* 方式一: 通过case class创建DataFrames(反射)
*/
object TestDataFrame1 { def main(args: Array[String]): Unit = { /**
* 直接使用SparkSession进行文件的创建。
* 封装了SparkContext,SparkConf,SQLContext,
* 为了向后兼容,SQLContext和HiveContext也被保存了下来
*/
val spark = SparkSession
.builder() //构建sql
.appName("TestDataFrame1") // 设置文件名
.master("local[2]") // 设置executor
.getOrCreate() //获取或创建 import spark.implicits._ // 隐式转换
// 将本地的数据读入RDD,将RDD与case class关联
val deptRDD = spark.read.textFile("/Users/hadoop/data/dept.txt")
.map(line => Dept(line.split("\t")(0).toInt,
line.split("\t")(1),
line.split("\t")(2).trim)) // 将RDD转换成DataFrames(反射)
val df = deptRDD.toDF() // 将DataFrames创建成一个临时的视图
df.createOrReplaceTempView("dept") // 使用SQL语句进行查询
spark.sql("select * from dept").show() }
}精简版 TestDataFrame1.scala
package com.bky import org.apache.spark.sql.SparkSession object TestDataFrame1 extends App {
val spark = SparkSession
.builder() //构建sql
.appName("TestDataFrame1")
.master("local[2]")
.getOrCreate() import spark.implicits._
val deptRDD = spark.read.textFile("/Users/hadoop/data/dept.txt")
.map(line => Dept(line.split("\t")(0).toInt,
line.split("\t")(1),
line.split("\t")(2).trim)) val df = deptRDD.toDF()
df.createOrReplaceTempView("dept")
spark.sql("select * from dept").show()
} case class Dept(var id:Int, var position:String, var location:String)方式二:通过创建structType创建DataFrames(编程接口)
TestDataFrame2.scala
package com.bky import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession} /**
*
* 方式二:通过创建structType创建DataFrames(编程接口)
*/
object TestDataFrame2 extends App { val spark = SparkSession
.builder()
.appName("TestDataFrame2")
.master("local[2]")
.getOrCreate() /**
* 将RDD数据映射成Row,需要导入import org.apache.spark.sql.Row
*/
import spark.implicits._
val path = "/Users/hadoop/data/dept.txt"
val fileRDD = spark.read.textFile(path)
val rowRDD= fileRDD.map(line => {
val fields = line.split("\t")
Row(fields(0).toInt, fields(1), fields(2).trim)
}) // 创建StructType来定义结构
val innerStruct = StructType(
// 字段名,字段类型,是否可以为空
StructField("id", IntegerType, true) ::
StructField("position", StringType, true) ::
StructField("location", StringType, true) :: Nil
) val df = spark.createDataFrame(innerStruct)
df.createOrReplaceTempView("dept")
spark.sql("select * from dept").show() }方式三:通过json文件创建DataFrames
TestDataFrame3.scala
package com.bky import org.apache.spark.sql.SparkSession /**
* 方式三:通过json文件创建DataFrames
*/
object TestDataFrame3 extends App { val spark = SparkSession
.builder()
.master("local[2]")
.appName("TestDataFrame3")
.getOrCreate() val path = "/Users/hadoop/data/test.json"
val fileRDD = spark.read.json(path)
fileRDD.createOrReplaceTempView("test")
spark.sql("select * from test").show()
}
统计每种返回码的数量
package org.sparkcourse.log
import org.apache.spark.sql.{Row, SparkSession}
object LogAnalyzerSQL {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Log Analyzer")
.master("local")
.getOrCreate()
import spark.implicits._
val accessLogs = spark
.read
.textFile("data/weblog/apache.access.log")
.map(ApacheAccessLog.parseLogLine).toDF()
accessLogs.createOrReplaceTempView("logs")
// 统计每种返回码的数量.
val responseCodeToCount = spark.sql("SELECT responseCode, COUNT(*) FROM logs GROUP BY responseCode LIMIT 100")
.map(row => (row.getInt(0), row.getLong(1)))
.collect()
responseCodeToCount.foreach(print(_))
}
}
统计哪个IP地址访问服务器超过10次
package org.sparkcourse.log
import org.apache.spark.sql.{Row, SparkSession}
object LogAnalyzerSQL {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Log Analyzer")
.master("local")
.getOrCreate()
import spark.implicits._
val accessLogs = spark
.read
.textFile("data/weblog/apache.access.log")
.map(ApacheAccessLog.parseLogLine).toDF()
accessLogs.createOrReplaceTempView("logs")
// 统计哪个IP地址访问服务器超过10次
val ipAddresses = spark.sql("SELECT ipAddress, COUNT(*) AS total FROM logs GROUP BY ipAddress HAVING total > 10 LIMIT 100")
.map(row => row.getString(0))
.collect()
ipAddresses.foreach(println(_))
}
}
查询访问量最大的访问目的地址
package org.sparkcourse.log
import org.apache.spark.sql.{Row, SparkSession}
object LogAnalyzerSQL {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Log Analyzer")
.master("local")
.getOrCreate()
import spark.implicits._
val accessLogs = spark
.read
.textFile("data/weblog/apache.access.log")
.map(ApacheAccessLog.parseLogLine).toDF()
accessLogs.createOrReplaceTempView("logs")
// 查询访问量最大的访问目的地址
val topEndpoints = spark.sql("SELECT endpoint, COUNT(*) AS total FROM logs GROUP BY endpoint ORDER BY total DESC LIMIT 10")
.map(row => (row.getString(0), row.getLong(1)))
.collect()
topEndpoints.foreach(println(_))
}
}
SparkSQL(一)的更多相关文章
- 踩坑事件:windows操作系统下的eclipse中编写SparkSQL不能从本地读取或者保存parquet文件
这个大坑... .... 如题,在Windows的eclipse中编写SparkSQL代码时,编写如下代码时,一运行就抛出一堆空指针异常: // 首先还是创建SparkConf SparkConf c ...
- sparksql udf的运用----scala及python版(2016年7月17日前完成)
问:udf在sparksql 里面的作用是什么呢? 答:oracle的存储过程会有用到定义函数,那么现在udf就相当于一个在sparksql用到的函数定义: 第二个问题udf是怎么实现的呢? regi ...
- spark-sql性能测试
一,测试环境 1) 硬件环境完全相同: 包括:cpu/内存/网络/磁盘Io/机器数量等 2)软件环境: 相同数据 ...
- SparkSQL读取Hive中的数据
由于我Spark采用的是Cloudera公司的CDH,并且安装的时候是在线自动安装和部署的集群.最近在学习SparkSQL,看到SparkSQL on HIVE.下面主要是介绍一下如何通过SparkS ...
- SparkSQL(源码阅读三)
额,没忍住,想完全了解sparksql,毕竟一直在用嘛,想一次性搞清楚它,所以今天再多看点好了~ 曾几何时,有一个叫做shark的东西,它改了hive的源码...突然有一天,spark Sql突然出现 ...
- Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .SparkSQL的发展历程 1.1 Hive and Shark SparkSQL的前身是 ...
- Spark入门实战系列--6.SparkSQL(中)--深入了解SparkSQL运行计划及调优
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1.1 运行环境说明 1.1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软 ...
- Spark入门实战系列--6.SparkSQL(下)--Spark实战应用
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .运行环境说明 1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软件:VMwa ...
- 大数据——sparksql
sparksql:http://www.cnblogs.com/shishanyuan/p/4723604.html?utm_source=tuicool spark on yarn :http:// ...
- SparkSql 不支持Date Format (支持Timestamp)
最近项目中需要用到sparksql ,需要查询sql Date类型, 无奈,官方现阶段 1.6.0 还不支持Date类型,不过支持Timestamp类型,所以问题可以解决了. 1.解析 SimpleD ...
随机推荐
- C语言结构体实例-创建兔子
参考裸编程思想. #include <stdio.h> //#include "ycjobject.h" // 颜色定义 #define CL_BLACK 0 #def ...
- 常用Concurrent.util包工具类——高并发
一 Concurrent.util常用类: 1. CyclicBarrier: 假设有场景:每个线程代表一个跑步运动员,当运动员都准备好后,才一起出发只要有一个人没有准备好,大家都等待. import ...
- 集成swagger
1.看官方文档 https://docs.microsoft.com/zh-cn/aspnet/core/tutorials/getting-started-with-swashbuckle?view ...
- 【leetcode】931. Minimum Falling Path Sum
题目如下: Given a square array of integers A, we want the minimum sum of a falling path through A. A fal ...
- PHP基础知识------页面静态化
1.在开发项目时,有时会遇到一些页面数据量特别大,但是又不经常改变的情况,如商城首页等,这时候就需要进行页面静态化,减轻服务器和数据库的压力. 这里我们先用原生的PHP写一个简单的demo,用来理解页 ...
- shell 根据路径获取文件名和目录
path=/dir1/dir2/dir3/test.txt echo ${path##*/} 获取文件名 test.txtecho ${path##*.} 获取后缀 txt #不带后缀的文件名temp ...
- 每天一个linux命令:mv(7)
mv mv命令可以用来移动文件或者将文件改名(move (rename) files),是Linux系统下常用的命令,经常用来备份文件或者目录. 在跨文件系统移动文件时,mv先拷贝,再将原有文件删除, ...
- layer icon对应图标
layer icon对应图标 信息框(msg.alert.open.confirm) icon:0 icon:1 icon:2 icon:3 icon:4 icon:5 icon:6 icon:16 ...
- 为什么我markdown里的数学公式全崩了???
目录 try a try ac is ok Typecho博客 https://www.diyifanwen.com/fanwen/dangyuanxindetihui/2665516.htm htt ...
- 运放参数的详细解释和分析-part1,输入偏置电流和输入失调电流【转】
一般运放的datasheet中会列出众多的运放参数,有些易于理解,我们常关注,有些可能会被忽略了.在接下来的一些主题里,将对每一个参数进行详细的说明和分析.力求在原理和对应用的影响上把运放参数阐述清楚 ...