初识内存分配ByteBuf
初识ByteBuf:
ByteBuf 是Netty 整个结构里面最为底层的模块,主要负责把数据从底层IO 里面读到ByteBuf,然后传递给应用程序,应用程序处理完成之后再把数据封装成ByteBuf 写回到IO。所以,ByteBuf 是直接与底层打交道的一层抽象。这块内容,相对于Netty 其他模块来说,是非常复杂的。从不同角度来分析ByteBuf 的分配和回收。主要从内存与内存管理器的抽象、不同规格大小和不同类别的内存的分配策略以及内存的回收过程来展开。
ByteBuf 的基本结构:
我们可以首先来看一下源码中对ByteBuf 的描述如下:

从上面ByteBuf 的结构来看,我们发现ByteBuf 有三个非常重要的指针,分别是readerIndex(记录读指针的开始位置)、writerIndex(记录写指针的开始位置)和capacity(缓冲区的总长度),三者的关系是readerIndex<=writerIndex<=capacity。然后,从0 到readerIndex 为discardable bytes 表示是无效的,从readerIndex 到writerIndex 为readablebytes 表示可读数据区,从writerIndex 到capacity 为writable bytes 表示这段区间空闲可以往里面写数据。除了这三个指针,其实ByteBuf 里面还有一个maxCapacity,这就相当于是ByteBuf 扩容的最大阈值,我们看它的源码中有定义:
/**返回此缓冲区的最大允许容量。此值提供一个上限
* Returns the maximum allowed capacity of this buffer. This value provides an upper
* bound on {@link #capacity()}.
*/
public abstract int maxCapacity();
这个指针可以看做是capactiy 之后的这段,当Netty 发现writable bytes 写数据超出空间大小时,ByteBuf 会提前帮我们自动扩容,扩容之后,就有了足够的空间来写数据,同时capactiy 也会同步更新,maxCapacity 就是扩容后capactiy的最大值。
ByteBuf 的重要API:
接下来我们来看ByteBuf 的基本API,主要包括read()、write()、set()以及mark()、reset()方法。我们用下面的表格对ByteBuf 最重要的API 做一个详细说明:
- readByte():从当前readerIndex 指针开始往后读1 个字节的数据并移动readerIndex,将数据转化为byte。
- readUnsignedByte() :读取一个无符号的byte 数据。
- readShort(): 从当前readerIndex 指针开始往后读2 个字节的数据并移动readerIndex,将数据转化为short。
- readInt(): 从当前readerIndex 指针开始往后读4 个字节的数据并移动readerIndex,将数据转化为int。
- readLong() :从当前readerIndex 指针开始往后读8 个字节的数据并移动readerIndex,将数据转化为long。
- writeByte() :从当前writerIndex 指针开始往后写1 个字节的数据并移动writerIndex。
- setByte() :将byte 数据写入到指定位置,不移动writerIndex。
- markReaderIndex() :在读数据之前,将readerIndex 的状态保存起来,方便在读完数据之后将readerIndex 复原。
- resetReaderIndex() :将readerIndex 复原到调用markReaderIndex()之后的状态。
- markWriterIndex() :在写数据之前,将writerIndex 的状态保存起来,方便在读完数据之后将writerIndex 复原。
- resetWriterIndex() :将writerIndex 复原到调用markWriterIndex()之后的状态。
- readableBytes(): 获取可读数据区大小,相当于获取当前writerIndex 减去readerIndex 的值。
- writableBytes(): 获取可写数据区大小,相当于获取当前capactiy 减去writerIndex 的值。
- maxWritableBytes(): 获取最大可写数据区的大小,相当于获取当前maxCapactiy 减去writerIndex 的值。
在Netty 中,ByteBuf 的大部分功能是在AbstractByteBuf 中来实现的,我们可以先进入AbstractByteBuf 的源码看看:
public abstract class AbstractByteBuf extends ByteBuf {
......
int readerIndex;//读指针
int writerIndex;//写指针
private int markedReaderIndex;//mark 之后的读指针
private int markedWriterIndex;//mark 之后的写指针
private int maxCapacity;//最大容量
......
}
最重要的几个属性readerIndex、writerIndex、markedReaderIndex、markedWriterIndex、maxCapacity 被定义在AbstractByteBuf 这个抽象类中,下面我们可以来看看基本读写的骨架代码实现。例如,几个基本的判断读写区间的API,我们来看一下它的具体实现:
@Override
public boolean isReadable() {return writerIndex > readerIndex;} @Override
public boolean isReadable(int numBytes) {return writerIndex - readerIndex >= numBytes;} @Override
public boolean isWritable() {return capacity() > writerIndex;} @Override
public boolean isWritable(int numBytes) {return capacity() - writerIndex >= numBytes;} @Override
public int readableBytes() {return writerIndex - readerIndex;} @Override
public int writableBytes() {return capacity() - writerIndex;} @Override
public int maxWritableBytes() {return maxCapacity() - writerIndex;} @Override
public ByteBuf markReaderIndex() {
markedReaderIndex = readerIndex;
return this;
}
@Override
public ByteBuf resetReaderIndex() {
readerIndex(markedReaderIndex);
return this;
} @Override
public ByteBuf markWriterIndex() {
markedWriterIndex = writerIndex;
return this;
} @Override
public ByteBuf resetWriterIndex() {
writerIndex(markedWriterIndex);
return this;
}
//再来看几个读写操作的API,具体源码如下:
@Override
public byte readByte() {
checkReadableBytes0(1);
int i = readerIndex;
byte b = _getByte(i);
readerIndex = i + 1;
return b;
}
@Override
public ByteBuf writeByte(int value) {
ensureWritable0(1);
_setByte(writerIndex++, value);
return this;
}
@Override
public byte getByte(int index) {
checkIndex(index);
return _getByte(index);
}
protected abstract byte _getByte(int index);
protected abstract void _setByte(int index, int value);
我们看到,上面的代码中readByte()方法和getByte()方法都调用了一个抽象的_getByte(),这个方法在AbstractByteBuf的子类中实现。在writeByte()方法中有调用一个抽象的_setByte()方法,这个方法同样也是在子类中实现。
ByteBuf 的基本分类:
AbstractByteBuf 之下有众多子类,大致可以从三个维度来进行分类,分别如下:
- Pooled:池化内存,就是从预先分配好的内存空间中提取一段连续内存封装成一个ByteBuf 分给应用程序使用。
- Unsafe:是JDK 底层的一个负责IO 操作的对象,可以直接拿到对象的内存地址,基于内存地址进行读写操作。
- Direct:堆外内存,是直接调用JDK 的底层API 进行物理内存分配,不在JVM 的堆内存中,需要手动释放。
综上所述,其实ByteBuf 一共会有六种组合:Pooled 池化内存和Unpooled 非池化内存;Unsafe 和非Unsafe;Heap堆内存和Direct 堆外内存。下图是ByteBuf 最重要的继承关系类结构图,通过命名就能一目了然:
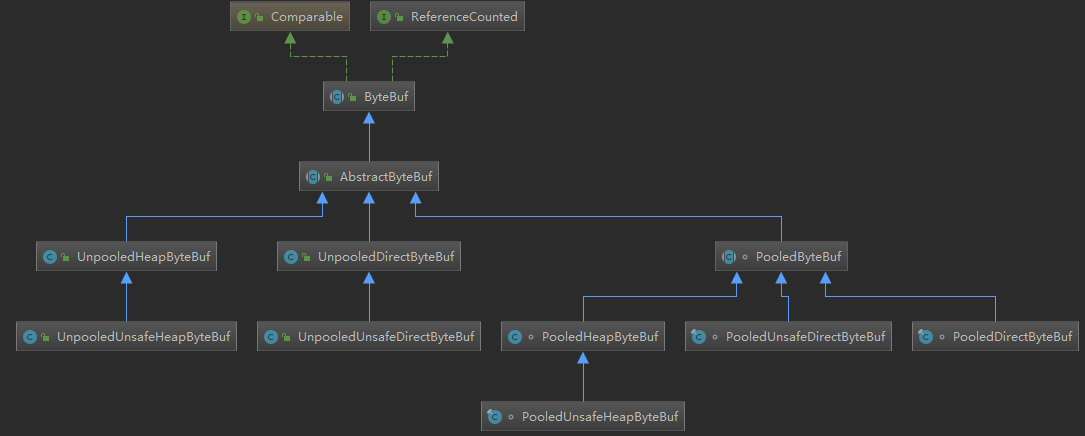
ByteBuf 最基本的读写API 操作在AbstractByteBuf 中已经实现了,其众多子类采用不同的策略来分配内存空间,下面对重要的几个子类总结如下:
- PooledHeapByteBuf :池化的堆内缓冲区
- PooledUnsafeHeapByteBuf :池化的Unsafe 堆内缓冲区
- PooledDirectByteBuf :池化的直接(堆外)缓冲区
- PooledUnsafeDirectByteBuf :池化的Unsafe 直接(堆外)缓冲区
- UnpooledHeapByteBuf :非池化的堆内缓冲区
- UnpooledUnsafeHeapByteBuf :非池化的Unsafe 堆内缓冲区
- UnpooledDirectByteBuf :非池化的直接(堆外)缓冲区
- UnpooledUnsafeDirectByteBuf :非池化的Unsafe 直接(堆外)缓冲区
初步认识了ByteBuf的结构,接下去我们来看看在Netty中是怎么管理这些Buf及分配的。
初识内存分配ByteBuf的更多相关文章
- Netty源码分析第5章(ByteBuf)---->第7节: page级别的内存分配
Netty源码分析第五章: ByteBuf 第六节: page级别的内存分配 前面小节我们剖析过命中缓存的内存分配逻辑, 前提是如果缓存中有数据, 那么缓存中没有数据, netty是如何开辟一块内存进 ...
- Netty源码分析第5章(ByteBuf)---->第8节: subPage级别的内存分配
Netty源码分析第五章: ByteBuf 第八节: subPage级别的内存分配 上一小节我们剖析了page级别的内存分配逻辑, 这一小节带大家剖析有关subPage级别的内存分配 通过之前的学习我 ...
- Netty源码—五、内存分配概述
Netty中的内存管理应该是借鉴了FreeBSD内存管理的思想--jemalloc.Netty内存分配过程中总体遵循以下规则: 优先从缓存中分配 如果缓存中没有的话,从内存池看看有没有剩余可用的 如果 ...
- Netty - 3 内存分配
https://www.cnblogs.com/gaoxing/p/4253833.html netty的buffer引入了缓冲池.该缓冲池实现使用了jemalloc的思想 内存分配是面向虚拟内存的而 ...
- Netty内存池ByteBuf 内存回收
内存池ByteBuf 内存回收: 在前面的章节中我们有提到, 堆外内存是不受JVM 垃圾回收机制控制的, 所以我们分配一块堆外内存进行ByteBuf 操作时, 使用完毕要对对象进行回收, 本节就以Po ...
- Netty之SubPage级别的内存分配
SubPage 级别的内存分配: 通过之前的学习我们知道, 如果我们分配一个缓冲区大小远小于page, 则直接在一个page 上进行分配则会造成内存浪费, 所以需要将page 继续进行切分成多个子块进 ...
- Netty之Page级别的内存分配
Page 级别的内存分配: 之前我们介绍过, netty 内存分配的单位是chunk, 一个chunk 的大小是16MB, 实际上每个chunk, 都以双向链表的形式保存在一个chunkList 中, ...
- Netty内存管理器ByteBufAllocator及内存分配
ByteBufAllocator 内存管理器: Netty 中内存分配有一个最顶层的抽象就是ByteBufAllocator,负责分配所有ByteBuf 类型的内存.功能其实不是很多,主要有以下几个重 ...
- 7.netty内存管理-ByteBuf
ByteBuf ByteBuf是什么 ByteBuf重要API read.write.set.skipBytes mark和reset duplicate.slice.copy retain.rele ...
随机推荐
- 20191119PHP.class类练习
<?phpclass person{ public $name; private $age; public $sex; const WOMAN=0; const MAN=1; function ...
- selenium下拉一个框内的滚动条
js='document.getElementsByClassName("route-tree")[0].scrollTop=10000'
- [POI2006]ORK-Ploughing(贪心,枚举)
[POI2006]ORK-Ploughing 题目描述 Byteasar, the farmer, wants to plough his rectangular field. He can begi ...
- GetExtendedTcpTable
https://blog.csdn.net/sky101010ws/article/details/55511501 AdjustTokenPrivileges function Library Ad ...
- nginx-博客阅读笔记记录-20190916
Nginx 入门学习教程 Ng官网解释: nginx [engine x]是最初由Igor Sysoev编写的HTTP和反向代理服务器,邮件代理服务器和通用TCP / UDP代理服务器. 维基百科解释 ...
- 阿里云ECS无法通过SSL远程链接问题。
自己配置的SSL,通过密码,公司的是通过密钥,结果也是一样, 环境:centos7.x 网络: 家里宽带 公司网络 省图书馆wifi 家里宽带,公司网络均可以链接上去, 但唯独省图书馆wifi链接失败 ...
- navicat连接客户端报错
怎么感觉oracle和sql server是一个货色.装个服务得装半天,还是mysql好,一下子就好了!下面有一个在centos7上面安装oracle11g的详细步骤,感觉找不到比这个更详细的了吧! ...
- jquery用法第二波
过滤器 属性过滤选择器: $("div[id]")选取有id属性的<div> $(“#id”) $("div[title=test]")选取titl ...
- 使用linkedlist封装简单的先进先出队列
创建一个类Queue代表队列(先进先出),添加add(Object obj) 及get()方法, 并添加main()方法进行验证 思路: 使用LinkedList实现队列,在向LinkedList中添 ...
- php substr_count()函数 语法
php substr_count()函数 语法 作用:统计一个字符串,在另一个字符串中出现次数大理石量具 语法:substr_count(string,substring,start,length) ...