一致性Hash算法在Redis分布式中的使用
由于redis是单点,但是项目中不可避免的会使用多台Redis缓存服务器,那么怎么把缓存的Key均匀的映射到多台Redis服务器上,且随着缓存服务器的增加或减少时做到最小化的减少缓存Key的命中率呢?这样就需要我们自己实现分布式。
Memcached对大家应该不陌生,通过把Key映射到Memcached Server上,实现快速读取。我们可以动态对其节点增加,并未影响之前已经映射到内存的Key与memcached Server之间的关系,这就是因为使用了一致性哈希。
因为Memcached的哈希策略是在其客户端实现的,因此不同的客户端实现也有区别,以Spymemcache、Xmemcache为例,都是使用了KETAMA作为其实现。
因此,我们也可以使用一致性hash算法来解决Redis分布式这个问题。在介绍一致性hash算法之前,先介绍一下我之前想的一个方法,怎么把Key均匀的映射到多台Redis Server上。
由于LZ水平有限且对Redis研究的不深,文中有写的不对的地方请指正。
方案一
该方案是前几天想的一个方法,主要思路是通过对缓存Key中的字母和数字的ascii码值求sum,该sum值对Redis Server总数取余得到的数字即为该Key映射到的Redis Server,该方法有一个很大的缺陷就是当Redis Server增加或减少时,基本上所有的Key都映射不到对应的的Redis Server了。代码如下:
/// <summary>
/// 根据缓存的Key映射对应的Server
/// </summary>
/// <param name="Key"></param>
/// <returns></returns>
public static RedisClient GetRedisClientByKey(string Key)
{
List<RedisClientInfo> RedisClientList = new List<RedisClientInfo>();
RedisClientList.Add(new RedisClientInfo() { Num = , IPPort = "127.0.0.1:6379" });
RedisClientList.Add(new RedisClientInfo() { Num = , IPPort = "127.0.0.1:9001" }); char[] charKey = Key.ToCharArray();
//记录Key中的所有字母与数字的ascii码和
int KeyNum = ;
//记录余数
int Num = ;
foreach (var c in charKey)
{
if ((c >= 'a' && 'z' >= c) || (c >= 'A' && 'Z' >= c))
{
System.Text.ASCIIEncoding asciiEncoding = new System.Text.ASCIIEncoding();
KeyNum = KeyNum + (int)asciiEncoding.GetBytes(c.ToString())[];
}
if (c >= '' && '' >= c)
{
KeyNum += Convert.ToInt32(c.ToString());
}
}
Num = KeyNum % RedisClientList.Count;
return new RedisClient(RedisClientList.Where(it => it.Num == Num).First().IPPort);
}
//Redis客户端信息
public class RedisClientInfo
{
//Redis Server编号
public int Num { get; set; }
//Redis Server IP地址和端口号
public string IPPort { get; set; }
}
方案二
1、分布式实现
通过key做一致性哈希,实现key对应redis结点的分布。
一致性哈希的实现:
- hash值计算:通过支持MD5与MurmurHash两种计算方式,默认是采用MurmurHash,高效的hash计算。
- 一致性的实现:通过java的TreeMap来模拟环状结构,实现均匀分布
什么也不多说了,直接上代码吧,LZ也是只知道点皮毛,代码中还有一些看不懂的地方,留着以后慢慢琢磨
public class KetamaNodeLocator
{
//原文中的JAVA类TreeMap实现了Comparator方法,这里我图省事,直接用了net下的SortedList,其中Comparer接口方法)
private SortedList<long, string> ketamaNodes = new SortedList<long, string>();
private HashAlgorithm hashAlg;
private int numReps = ;
//此处参数与JAVA版中有区别,因为使用的静态方法,所以不再传递HashAlgorithm alg参数
public KetamaNodeLocator(List<string> nodes/*,int nodeCopies*/)
{
ketamaNodes = new SortedList<long, string>();
//numReps = nodeCopies;
//对所有节点,生成nCopies个虚拟结点
foreach (string node in nodes)
{
//每四个虚拟结点为一组
for (int i = ; i < numReps / ; i++)
{
//getKeyForNode方法为这组虚拟结点得到惟一名称
byte[] digest = HashAlgorithm.computeMd5(node + i);
/** Md5是一个16字节长度的数组,将16字节的数组每四个字节一组,分别对应一个虚拟结点,这就是为什么上面把虚拟结点四个划分一组的原因*/
for (int h = ; h < ; h++)
{
long m = HashAlgorithm.hash(digest, h);
ketamaNodes[m] = node;
}
}
}
}
public string GetPrimary(string k)
{
byte[] digest = HashAlgorithm.computeMd5(k);
string rv = GetNodeForKey(HashAlgorithm.hash(digest, ));
return rv;
}
string GetNodeForKey(long hash)
{
string rv;
long key = hash;
//如果找到这个节点,直接取节点,返回
if (!ketamaNodes.ContainsKey(key))
{
//得到大于当前key的那个子Map,然后从中取出第一个key,就是大于且离它最近的那个key 说明详见: http://www.javaeye.com/topic/684087
var tailMap = from coll in ketamaNodes
where coll.Key > hash
select new { coll.Key };
if (tailMap == null || tailMap.Count() == )
key = ketamaNodes.FirstOrDefault().Key;
else
key = tailMap.FirstOrDefault().Key;
}
rv = ketamaNodes[key];
return rv;
}
}
public class HashAlgorithm
{
public static long hash(byte[] digest, int nTime)
{
long rv = ((long)(digest[ + nTime * ] & 0xFF) << )
| ((long)(digest[ + nTime * ] & 0xFF) << )
| ((long)(digest[ + nTime * ] & 0xFF) << )
| ((long)digest[ + nTime * ] & 0xFF);
return rv & 0xffffffffL; /* Truncate to 32-bits */
}
/**
* Get the md5 of the given key.
*/
public static byte[] computeMd5(string k)
{
MD5 md5 = new MD5CryptoServiceProvider(); byte[] keyBytes = md5.ComputeHash(Encoding.UTF8.GetBytes(k));
md5.Clear();
//md5.update(keyBytes);
//return md5.digest();
return keyBytes;
}
}
2、分布式测试
1、假设有两个server:0001和0002,循环调用10次看看Key值能不能均匀的映射到server上,代码如下:
static void Main(string[] args)
{
//假设的server
List<string> nodes = new List<string>() { "","" };
KetamaNodeLocator k = new KetamaNodeLocator(nodes);
string str = "";
for (int i = ; i < ; i++)
{
string Key="user_" + i;
str += string.Format("Key:{0}分配到的Server为:{1}\n\n", Key, k.GetPrimary(Key));
} Console.WriteLine(str); Console.ReadLine(); }
程序运行两次的结果如下,发现Key基本上均匀的分配到Server节点上了。
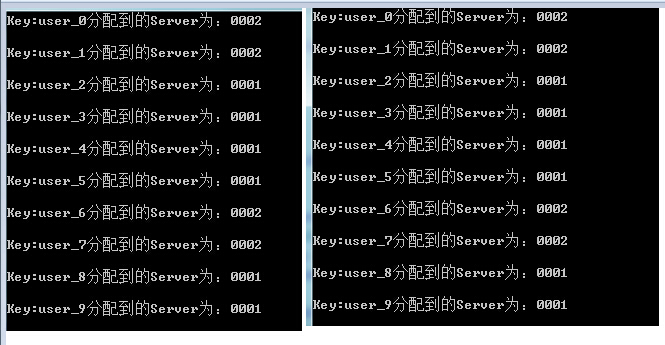
2、我们在添加一个0003的server节点,代码如下:
static void Main(string[] args)
{
//假设的server
List<string> nodes = new List<string>() { "","" ,""};
KetamaNodeLocator k = new KetamaNodeLocator(nodes);
string str = "";
for (int i = ; i < ; i++)
{
string Key="user_" + i;
str += string.Format("Key:{0}分配到的Server为:{1}\n\n", Key, k.GetPrimary(Key));
} Console.WriteLine(str); Console.ReadLine(); }
程序运行两次的结果如下:
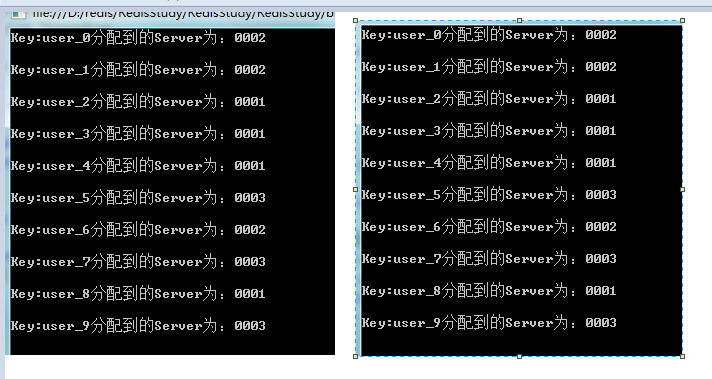
对比第一次的运行结果发现只有user_5,user_7,user_9的缓存丢失,其他的缓存还可以命中。
3、我们去掉server 0002,运行两次的结果如下:

对比第二次和本次运行结果发现 user_0,user_1,user_6 缓存丢失。
结论
通过一致性hash算法可以很好的解决Redis分布式的问题,且当Redis server增加或减少的时候,之前存储的缓存命中率还是比较高的。
关于Redis的其他文章
http://www.cnblogs.com/lc-chenlong/p/4194150.html
http://www.cnblogs.com/lc-chenlong/p/4195033.html
http://www.cnblogs.com/lc-chenlong/p/3218157.html
本文参考
1、http://blog.csdn.net/chen77716/article/details/5949166
2、http://www.cr173.com/html/6474_2.html
一致性Hash算法在Redis分布式中的使用的更多相关文章
- Nginx+Memcache+一致性hash算法 实现页面分布式缓存(转)
网站响应速度优化包括集群架构中很多方面的瓶颈因素,这里所说的将页面静态化.实现分布式高速缓存就是其中的一个很好的解决方案... 1)先来看看Nginx负载均衡 Nginx负载均衡依赖自带的 ngx_h ...
- 一致性Hash算法介绍(分布式环境算法)
32的整数环(这个环被称作一致性Hash环),根据节点名称的Hash值(其分布范围同样为0~232)将节点放置在这个Hash 环上.然后根据KEY值计算得到其Hash值(其分布范围也同样为0~232 ...
- 关于一致性Hash算法
在大型web应用中,缓存可算是当今的一个标准开发配置了.在大规模的缓存应用中,应运而生了分布式缓存系统.分布式缓存系统的基本原理,大家也有所耳闻.key-value如何均匀的分散到集群中?说到此,最常 ...
- 7.redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?
作者:中华石杉 面试题 redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗? 面试官心理分析 在前几年, ...
- 分布式一致性hash算法
写在前面 在学习Redis的集群内容时,看到这么一句话:Redis并没有使用一致性hash算法,而是引入哈希槽的概念.而分布式缓存Memcached则是使用分布式一致性hash算法来实现分布式存储. ...
- 11.redis cluster的hash slot算法和一致性 hash 算法、普通hash算法的介绍
分布式寻址算法 hash 算法(大量缓存重建) 一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡) redis cluster 的 hash slot 算法 一.hash 算法 来了一 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 一致性Hash算法在Memcached中的应用
前言 大家应该都知道Memcached要想实现分布式只能在客户端来完成,目前比较流行的是通过一致性hash算法来实现.常规的方法是将server的hash值与server的总台数进行求余,即hash% ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
随机推荐
- Corba概念(GIOP、IIOP、IOR、ORB、IDL)
CORBA公用对象请求代理(调度)程序体系结构(Common Object Request Broker Architecture),缩写为 CORBA,是对象管理组织(Object Manageme ...
- Substance 6 设置 watermark(水印)
http://www.qumake.com/articles/2011/04/18/1303094833690.html ——————————————————————————————————————— ...
- 4.0以后的新布局方式GridLayout
<?xml version="1.0" encoding="utf-8"?> <GridLayout xmlns:android=" ...
- java基础十一[远程部署的RMI](阅读Head First Java记录)
方法的调用都是发生在相同堆上的两个对象之间(同一台机器的Java虚拟机),如果想要调用另一台机器上的对象,可以通过Socket进行输入/输出. 远程过程调用需要创建出4种东西:服务器.客户端.服务器辅 ...
- Spring aop——前置增强和后置增强 使用注解Aspect和非侵入式配置
AspectJ是一个面向切面的框架,它扩展了java语言,定义了AOP语法,能够在编译期提供代码的织入,所以它有一个专门的编译器用来生成遵守字节码字节编码规范的Class文件 确保使用jdk为5.0以 ...
- [转载] Genymotion 解决虚拟镜像下载速度特别慢的问题
本文转载自: http://blog.csdn.net/qing666888/article/details/51622762 Genymotion号称Android模拟器中运行最快的,但是服务器在国 ...
- C#将Enum枚举映射到文本字符串
介绍 当将以前的C代码移植到C#中时,我快发疯了,因为有很多的数组需要将常量映射到字符串.当我在寻找一个C#的方法来完成的时候,我发现了一个自定义属性和映射的方法. 如何使用代码? 对每一个enum枚 ...
- eclipse使用技巧、快捷键
1.alt+/ 自动提示符,可以快速补整,提高效率. 输入Sysout,再按下alt+/,就可以打印了. 输入main,再按下alt+/,可以直接显示main方法. 2.ctrl+左键,快速进入 ...
- JSP中setattribute与setParameter的区别
HttpServletRequest类既有getAttribute()方法,也由getParameter()方法,这两个方法有以下区别: (1)HttpServletRequest类有setAttri ...
- pycharm Cannot find declaration to goto----解决方案
系统中已经有了该类库,还是找不到类提示 close the project in intellij. close intellij. go to the project folder and dele ...