Druid数据库连接池源码分析
上一篇文章重点介绍了一下Java的Future模式,最后意淫了一个数据库连接池的场景。本想通过Future模式来防止,当多个线程同时获取数据库连接时各自都生成一个,造成资源浪费。但是忽略了一个根本的功能,就是多个线程同时调用get方法时,得到的是同一个数据库连接的多个引用,这会导致严重的问题。
所以,我抽空看了看呼声很高的Druid的数据库连接池实现,当然关注点主要是多线程方面的处理。我觉得,带着问题去看源码是一种很好的思考方式。
Druid不仅仅是一个数据库连接池,还有很多标签,比如统计监控、过滤器、SQL解析等。既然要分析连接池,那先看看DruidDataSource类
getConnection方法的实现:
@Override
public DruidPooledConnection getConnection() throws SQLException {
return getConnection(maxWait);
} public DruidPooledConnection getConnection(long maxWaitMillis) throws SQLException {
init(); if (filters.size() > 0) {
FilterChainImpl filterChain = new FilterChainImpl(this);
return filterChain.dataSource_connect(this, maxWaitMillis);
} else {
return getConnectionDirect(maxWaitMillis);
}
}
返回的是一个DruidPooledConnection,这个类后面再说;另外这里传入了一个long类型maxWait,应该是用来做超时处理的;init方法在getConnection方法里面调用,这也是一种很好的设计;里面的过滤器链的处理就不多说了。
public void init() throws SQLException {
if (inited) {
return;
}
final ReentrantLock lock = this.lock; // 使用lock而不是synchronized
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
throw new SQLException("interrupt", e);
}
boolean init = false;
try {
if (inited) {
return;
}
init = true;
connections = new DruidConnectionHolder[maxActive]; // 数组
try {
// init connections
for (int i = 0, size = getInitialSize(); i < size; ++i) {
Connection conn = createPhysicalConnection(); // 生成真正的数据库连接
DruidConnectionHolder holder = new DruidConnectionHolder(this, conn);
connections[poolingCount] = holder;
incrementPoolingCount();
}
if (poolingCount > 0) {
poolingPeak = poolingCount;
poolingPeakTime = System.currentTimeMillis();
}
} catch (SQLException ex) {
LOG.error("init datasource error, url: " + this.getUrl(), ex);
connectError = ex;
}
createAndLogThread();
createAndStartCreatorThread();
createAndStartDestroyThread();
initedLatch.await();
initedTime = new Date();
registerMbean();
if (connectError != null && poolingCount == 0) {
throw connectError;
}
} catch (SQLException e) {
LOG.error("dataSource init error", e);
throw e;
} catch (InterruptedException e) {
throw new SQLException(e.getMessage(), e);
} finally {
inited = true;
lock.unlock(); // 释放锁
if (init && LOG.isInfoEnabled()) {
LOG.info("{dataSource-" + this.getID() + "} inited");
}
}
}
我这里做了删减,加了一些简单的注释。通过这个方法,正好复习一下之前写的那些知识点,如果感兴趣,可以看看我之前写的文章。
这里使用了lock,并且保证只会被执行一次。根据初始容量,先生成了一批数据库连接,用一个数组connections存放这些连接的引用,而且专门定义了一个变量poolingCount来保存这些连接的总数量。
看到initedLatch.await有一种似曾相识的感觉
private final CountDownLatch initedLatch = new CountDownLatch(2);
这里调用了await方法,那countDown方法在哪些线程里面被调用呢
protected void createAndStartCreatorThread() {
if (createScheduler == null) {
String threadName = "Druid-ConnectionPool-Create-" + System.identityHashCode(this);
createConnectionThread = new CreateConnectionThread(threadName);
createConnectionThread.start();
return;
}
initedLatch.countDown();
}
这里先判断createScheduler这个调度线程池是否被设置,如果没有设置,直接countDown;否则,就开启一个创建数据库连接的线程,当然这个线程的run方法还是会调用countDown方法。但是这里我有一个疑问:开启创建连接的线程,为什么一定要有一个调度线程池呢???
难道是当数据库连接创建失败的时候,需要过了指定时间后,再重试?这么理解好像有点牵强,希望高人来评论。
还有就是,当开启destroy线程的时候也会调用countDown方法。
接着在看getConnection方法,一直调用到getConnectionInternal方法
DruidConnectionHolder holder;
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
connectErrorCount.incrementAndGet();
throw new SQLException("interrupt", e);
} try {
if (maxWait > 0) {
holder = pollLast(nanos);
} else {
holder = takeLast();
} } catch (InterruptedException e) {
connectErrorCount.incrementAndGet();
throw new SQLException(e.getMessage(), e);
} catch (SQLException e) {
connectErrorCount.incrementAndGet();
throw e;
} finally {
lock.unlock();
} holder.incrementUseCount(); DruidPooledConnection poolalbeConnection = new DruidPooledConnection(holder);
return poolalbeConnection;
我这里还是做了删减。大体逻辑是:先从连接池中取出DruidConnectionHolder,然后再封装成DruidPooledConnection对象返回。再看看取holder的方法:
DruidConnectionHolder takeLast() throws InterruptedException, SQLException {
try {
while (poolingCount == 0) {
emptySignal(); // send signal to CreateThread create connection
notEmptyWaitThreadCount++;
if (notEmptyWaitThreadCount > notEmptyWaitThreadPeak) {
notEmptyWaitThreadPeak = notEmptyWaitThreadCount;
}
try {
notEmpty.await(); // signal by recycle or creator
} finally {
notEmptyWaitThreadCount--;
}
notEmptyWaitCount++;
if (!enable) {
connectErrorCount.incrementAndGet();
throw new DataSourceDisableException();
}
}
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
notEmptySignalCount++;
throw ie;
}
decrementPoolingCount();
DruidConnectionHolder last = connections[poolingCount];
connections[poolingCount] = null;
return last;
}
这个方法非常好的诠释了Lock-Condition的使用场景,几行绿色的注释解释的很明白了,如果对empty和notEmpty看不太懂,可以去看看我之前写的那篇文章。
这个方法的逻辑:先判断池中的连接数,如果到0了,那么本线程就得被挂起,同时释放empty信号,并且等待notEmpty的信号。如果还有连接,就取出数组的最后一个,同时更改poolingCount。
到这里,基本理解了Druid数据库连接池获取连接的实现流程。但是,如果不去看看里面的数据结构,还是会一头雾水。我们就看看几个基本的类,以及它们之间的持有关系。
1、DruidDataSource持有一个DruidConnectionHolder的数组,保存所有的数据库连接
private volatile DruidConnectionHolder[] connections; // 注意这里的volatile
2、DruidConnectionHolder持有数据库连接,还有所在的DataSource等
private final DruidAbstractDataSource dataSource;
private final Connection conn;
3、DruidPooledConnection持有DruidConnectionHolder,所在线程等
protected volatile DruidConnectionHolder holder;
private final Thread ownerThread;
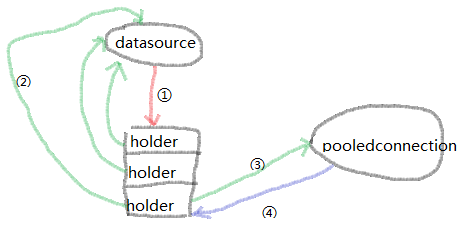
对于这种设计,我很好奇为什么要添加一层holder做封装,数组里直接存放Connection好像也未尝不可。
其实,这么设计是有道理的。比如说,一个Connection对象可以产生多个Statement对象,当我们想同时保存Connection和对应的多个Statement的时候,就比较纠结。
再看看DruidConnectionHolder的成员变量
private PreparedStatementPool statementPool;
private final List<Statement> statementTrace = new ArrayList<Statement>(2);
这样的话,既可以做缓存,也可以做统计。
最终我们对Connection的操作都是通过DruidPooledConnection来实现,比如commit、rollback等,它们大都是通过实际的数据库连接完成工作。而我比较关心的是close方法的实现,close方法最核心的逻辑是recycle方法:
public void recycle() throws SQLException {
if (this.disable) {
return;
}
DruidConnectionHolder holder = this.holder;
if (holder == null) {
if (dupCloseLogEnable) {
LOG.error("dup close");
}
return;
}
if (!this.abandoned) {
DruidAbstractDataSource dataSource = holder.getDataSource();
dataSource.recycle(this);
}
this.holder = null;
conn = null;
transactionInfo = null;
closed = true;
}
通过最后几行代码,能够看出,并没有调用实际数据库连接的close方法,而只是断开了之前那张图里面的4号引用。用这种方式,来实现数据库连接的复用。
Druid数据库连接池源码分析的更多相关文章
- java多线程----线程池源码分析
http://www.cnblogs.com/skywang12345/p/3509954.html 线程池示例 在分析线程池之前,先看一个简单的线程池示例. 1 import java.util.c ...
- java多线程——线程池源码分析(一)
本文首发于cdream的个人博客,点击获得更好的阅读体验! 欢迎转载,转载请注明出处. 通常应用多线程技术时,我们并不会直接创建一个线程,因为系统启动一个新线程的成本是比较高的,涉及与操作系统的交互, ...
- 线程池之ThreadPoolExecutor线程池源码分析笔记
1.线程池的作用 一方面当执行大量异步任务时候线程池能够提供较好的性能,在不使用线程池的时候,每当需要执行异步任务时候是直接 new 一线程进行运行,而线程的创建和销毁是需要开销的.使用线程池时候,线 ...
- java线程池源码分析
我们在关闭线程池的时候会使用shutdown()和shutdownNow(),那么问题来了: 这两个方法又什么区别呢? 他们背后的原理是什么呢? 线程池中线程超过了coresize后会怎么操作呢? 为 ...
- Java并发编程中线程池源码分析及使用
当Java处理高并发的时候,线程数量特别的多的时候,而且每个线程都是执行很短的时间就结束了,频繁创建线程和销毁线程需要占用很多系统的资源和时间,会降低系统的工作效率. 参考http://www.cnb ...
- 【图灵学院10】高并发之java线程池源码分析
1. 提纲 1)线程池的模块结构 2)示例&原理解析 2. 问题 1)线程池包含哪些东西 2)线程池的运作原理 3)调度线程池的运作原理 4)线程池怎么实现FixRate,FixDelay,他 ...
- 线程池之ScheduledThreadPoolExecutor线程池源码分析笔记
1.ScheduledThreadPoolExecutor 整体结构剖析. 1.1类图介绍 根据上面类图图可以看到Executor其实是一个工具类,里面提供了好多静态方法,根据用户选择返回不同的线程池 ...
- druid 源码分析与学习(含详细监控设计思路的彩蛋)(转)
原文路径:http://herman-liu76.iteye.com/blog/2308563 Druid是阿里巴巴公司的数据库连接池工具,昨天突然想学习一下阿里的druid源码,于是下载下来分析了 ...
- Solr4.8.0源码分析(3)之index的线程池管理
Solr4.8.0源码分析(3)之index的线程池管理 Solr建索引时候是有最大的线程数限制的,它由solrconfig.xml的<maxIndexingThreads>8</m ...
随机推荐
- C#写的较完美验证码通用类
using System; using System.Collections; using System.ComponentModel; using System.Data; using System ...
- python定时利用QQ邮件发送天气预报
大致介绍 好久没有写博客了,正好今天有时间把前几天写的利用python定时发送QQ邮件记录一下 1.首先利用request库去请求数据,天气预报使用的是和风天气的API(www.heweather.c ...
- Java面试之框架篇(九)
spring现在无疑是Java中最火的框架,使用范围广,几乎每个公司面试都会涉及spring和数据库,你可以对Struts不熟悉,但一定不能表现出对spring不了解.第九篇赢在面试全篇介绍sprin ...
- centos6.7安装openblas错误
centos系统:CentOS release 6.7 (Final)安装OpenBLAS # Install OpenBLAS at /usr/local/openblas git clone ht ...
- 【笔记】web 的回流与重绘及优化
最近看了幕课网 web 前端性能优化的课程,其中说到了浏览器的回流(reflow) 及 重绘(repaint).觉得以后面试或许会被问到所以做一下笔记: 课程从回流及重绘这两个点延伸出了一个知识点就是 ...
- 2712:细菌繁殖-poj
2712:细菌繁殖 总时间限制: 1000ms 内存限制: 65536kB 描述 一种细菌的繁殖速度是每天成倍增长.例如:第一天有10个,第二天就变成20个,第三天变成40个,第四天变成80个,… ...
- cmd 更改计算机名
bat 更改计算机名 不用重启电脑就生效^_^ @Echo off Color 0A title --更改计算机名 :A cls echo. echo. [0]退出 echo. echo. 不用重启 ...
- 运行时动态库:not found 及介绍-linux的-Wl,-rpath命令
---此文章同步自我的CSDN博客--- 一.运行时动态库:not found 今天在使用linux编写c/c++程序时,需要用到第三方的动态库文件.刚开始编译完后,运行提示找不到动态库文件.我就 ...
- 《Linux命令行与shell脚本编程大全》第二十一章 sed进阶
本章介绍一些sed编辑器提供的高级特性. 21.1 多行命令 按照之前的知识,所有的sed编辑器命令都是针对单行数据执行操作的. 在sed编辑器读取数据流时,它会基于换行符的位置将数据分成行,一次处理 ...
- 使用SSH快速下载Git项目
文章首发于[博客园-陈树义],点击跳转到原文使用SSH快速下载Git项目. Git下载项目的几种方式 Git是常用的代码版本技术,而GitLab则是开源的Git版本管理软件,GitLab是最受欢迎的版 ...