JavaSE(十)之Collection总结
前面几篇把集合中的知识大概都详细的说了一遍,但是我觉得还是要总结一下,这样的话,可以更好的理解集合。
一、Collection接口
首先我们要一张图来说明:
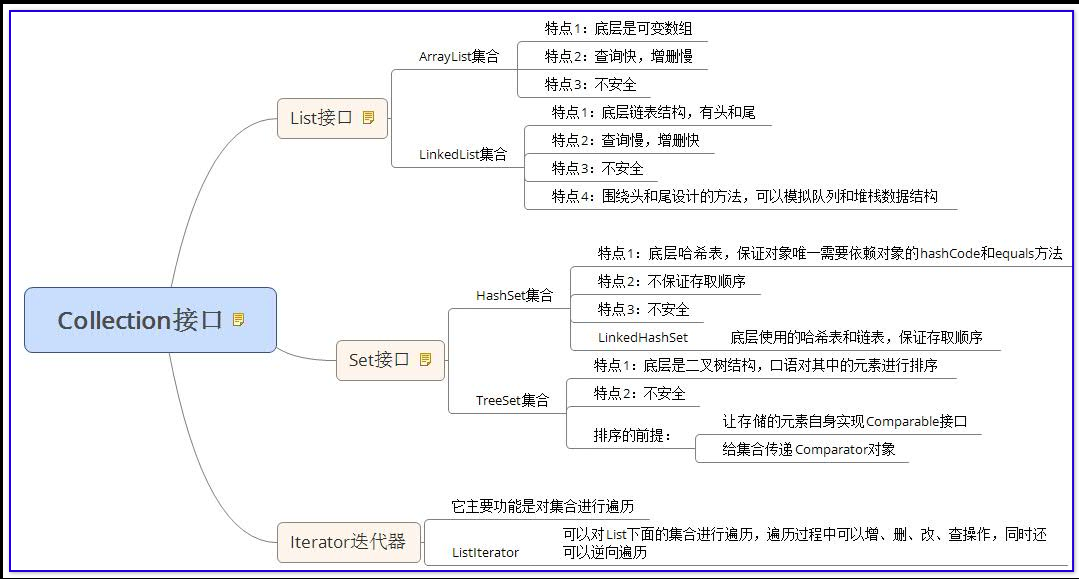
Collection接口,它是集合的顶层接口。其中定义了集合共性的操作方法。
增:add、addAll
删除:clear、remove、removeAll、RetainAll
查询:size
遍历:iterator,得到一个迭代器对象
判断:contains、containsAll、isEmpty
迭代器对象:Iterator,它是所有集合共有的迭代对象
1)先要判断,使用hasNext方法
2)取出元素,使用next方法
细节:1是:一次判断,最好使用一次next方法。二是在遍历的时候,不要使用集合自身的增删方法修改集合。
二、List接口
2.1、List接口概述
List接口它是Collection接口的子接口。
特点:List接口下的所有集合容器:有序、可重复、有索引。
由于List接口下的集合拥有下标,因此List接口拥有自己特有的方法:这些方法都是围绕下标设计的。
add(int index , Object element )
remove( int index )
get( int index )
set( int index , Object element )
List接口自己的迭代器:
ListIterator:它可以正向或逆向遍历List集合。同时可以对集合进行增,删、改、查操作。
2.2、ArrayList集合
ArrayList:它的底层是可变数组,查询快,增删慢,不安全!
2.3、LinkedList集合
1)概述
LinkedList集合,它也List接口的实现类。和ArrayList相同。都可以去使用List接口中的所有方法。
sun公司给List接口提供多个实现类的目的:
原因是实际开发中,我们需要不同的容器来存储不同对象。
不同的容器:每个容器都有自己对数据的存储方式(数据结构)。不同方式结构存储的数据,它们在性能上差异很大。
2)LinkedList的数据结构
链表:它主要也是用来存储数据。存储数据的每个空间被称为节点。
节点一般分成2个小空间:一个存储的节点的地址,一个存储的真正存放的数据

3)特有方法
由于LinkedList集合底层是链表结构。因此LinkedList集合在List接口之上,有增加了围绕头和尾而设计的增、删、改、查操作。xxxxFirst 和 xxxxxLast方法。
// 删除方法
public static void demo2() {
/// 创建集合对象
LinkedList list = new LinkedList();
// 添加元素
list.addFirst("aaa");
list.addFirst("bbb");
list.addLast("ccc");
// 删除方法
Object obj = list.removeFirst();
System.out.println(obj);
System.out.println(list);
}
// 添加方法
public static void demo1() {
/// 创建集合对象
LinkedList list = new LinkedList();
// 添加元素
list.addFirst("aaa");
list.addFirst("bbb");
list.addLast("ccc");
// 遍历
for( Iterator it = list.iterator() ; it.hasNext() ; ){
System.out.println(it.next());
}
}
演示
2.4、Vector
Vector集合它是JDK1.0时期存在的集合。其功能和ArrayList集合相同。
Vector的底层使用的也是可变数组。Vector集合它增删、查询都慢。它的底层是安全的。后期看到Vector集合,就当作ArrayList集合使用。
演示:
// 使用Iterator遍历
public static void demo1() {
// 创建集合对象
Vector v = new Vector();
// 添加方法
v.addElement("aaa");
v.add("bbb");
v.add("bbb");
v.add("ccc");
// 使用Iterator遍历
for( Iterator it = v.iterator() ; it.hasNext() ; ){
System .out.println(it.next());
}
}
demo1
使用枚举类遍历
// 使用古老的枚举迭代器遍历
public static void demo2() { // 创建集合对象 Vector v = new Vector(); // 添加方法 v.addElement("aaa"); v.add("bbb"); v.add("bbb"); v.add("ccc"); /* * 使用Vector中的 elements 方法可以得到一个枚举迭代器(早期迭代器) * Enumeration : 它是一个接口,主要用来遍历集合(Vector) * Enumeration这个接口被Iterator代替,并且Iterator中有remove方法, * Iterator中的方法名称较短。 */ Enumeration en = v.elements(); while( en.hasMoreElements() ){ System.out.println(en.nextElement()); } }
demo2
2.5、List接口总结
List接口:它限定它下面的所有集合容器拥有下标、可以存放重复元素、有序。其中定义了围绕下标而操作的方法。
ArrayList:
底层是可变数组。增删慢、查询快。不安全。可以使用null作为元素。
LinkedList:
底层是链表结构。增删快、查询慢,不安全。可以使用null作为元素。其中定义了围绕头和尾的方法,可以模拟 队列或堆栈数据结构。
Vector:
底层是可变数组,被ArrayList代替。什么都慢。但安全。可以使用null作为元素
Enumeration:它是古老的迭代器。被Iterator代替。
三、Set接口之HashSet
前面学习Collection接口的时候,下面有2个子接口:
List接口:可以保存重复元素,有下标,有序。
Set接口:可以保存不重复元素。
注意:Set接口没有自己特有的方法,所有方法全部来自于Collection接口。
3.1、HashSet集合
HashSet:它的底层是哈希表结构支持。它不保证迭代顺序(存取),同时它不安全。

3.2、哈希表介绍
哈希表:它也是一种存储数据的方式。它的底层使用的依然是数组,只是在存储元素的时候不按照数组下标从小到大的顺序存放。
如果有元素需要给哈希表结构中保存的时候,这时不会直接将元素给表中保存,而是根据当前这个元素自身的一些特点(成员变量等)计算这个元素应该在表中的哪个空间中保存。

哈希表存放对象的时候,需要根据当前对象的特定计算对象在表中的存储位置。任何对象都可以给集合中保存,那么任何对象肯定可以给HashSet集合中保存。
任何对象在保存的时候,都需要计算存储位置。任何对都应该具体计算存储位置的功能,这个功能(方法)定义在Object类中。
int hashCode() 返回该对象的哈希码值
我们给任何哈希表中存储的对象,都会依赖这个对象的hashCode方法计算哈希值,通过哈希值确定对象在表中的存储位置。
哈希冲突:如果两个对象调用hahsCode方法之后得到的哈希值相同,称为哈希冲突。
在给哈希中存放对象的时候,如果存储哈希冲突,这时就会调用2个对象equals方法计算它们是否相同。如果相同,就丢弃当前正要存放的这个对象,如果不同就会继续保存。
3.3、HashSet存放自定义对象(理解hashCode和equals方法作用)
自定义对象:不使用JDK中提供的类创建的对象,自己书写一个,然后创建这个类的对象,最后将其保存在HashSet集合中。
/*
* 演示给HashSet中存放自定义对象
*/
public class HashSetDemo2{
public static void main(String[] args) {
// 创建集合对象
HashSet set = new HashSet();
// 添加Person对象到集合中
Person p = new Person("zhangsan",);
set.add(p);
set.add(new Person("lisi",));
set.add(new Person("lisi",));
set.add(new Person("wangwu",));
set.add(new Person("zhaoliu",));
set.add(new Person("zhaoliu",));
set.add(new Person("tianqi",));
// 遍历
for( Iterator it = set.iterator(); it.hasNext() ; ){
System.out.println(it.next());
}
}
}
/*
* 自定义类
*/
public class Person {
private String name;
private int age;
// alt + shift + S
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
}
HashSetDemo
运行上面的程序,给HashSet中保存Person对象:
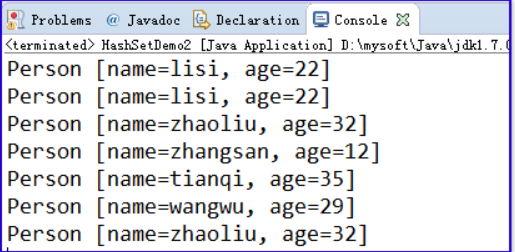
发现运行的结果出现了重复的数据。
解释存储的Person对象重复的原因:
我们知道HashSet的底层使用的哈希表,哈希表在存储对象的时候需要调用对象自身的hashCode方法计算在表中存储的位置。
而在我们自己的程序中,我们创建了多个Person对象,每个Person对象都在堆中有自己的内存地址。虽然有些Person对象表示的name和age相同的,但是他们所在的对象的内存地址是不同的。
而我们在书写的Person类又继承了Object类,这样就相当于Person类拥有了hashCode方法,而这个hashCode方法完全使用的是Object类中的。而Object类中的hashCode方法是根据当前对象的内存地址计算哈希值,
每个Person对象都拥有自己的内存地址,即使他们的name和age相同,但是他们的内存地址不同,计算出来的哈希值肯定也不同,那么每个Person对象都可以保存到哈希表中。
解决方案:
根据每个Person对象自己的name和age计算它们的哈希值。相当于Person类继承到Object类中的hashCode方法不适合当前Person类,Person类需要复写hashCode方法。
复写完hashCode方法之后,还要复写Object类中的equals方法。因为如果hashCode计算的结果相同,这时还要调用equals方法来判断2个对象是否相同。
而Object类中的equals方法在使用2个对象的地址比较。而我们创建的每个Person地址都不相同,那么直接使用Object类中的equals方法,比较的结果肯定是false。我们希望通过2个对象的name和age比较2个对象是否相同。
3.4、HashSet保证元素唯一原因
HashSet集合保证对象唯一:
1)首先会调用对象的hashCode方法计算存储位置。
2)如果位置相同,会调用equals方法。如果equals方法返回的true,当前对象就不会被保存。如果是false依然保存。
结论:以后只要是给HashSet集合中保存的对象,这个对象所属的类一定要复写Object类中的hashCode和equals方法。
3.5、总结
1)HashSet集合是Set接口的实现类。它保证元素不重复。
2)HashSet底层使用的哈希表,不保证存取的顺序(迭代顺序)。
3)保证对象不重复需要复写hashCode和equals方法。
4)HashSet集合只能使用Iterator和foreach遍历,不能使用List接口的特有方法遍历。
5)HashSet不安全。
3.6、LinkedHashSet
LinkedHashSet集合:它是HashSet的子类。它的底层接口是链表+哈希表结构。
特点:肯定可以保证对象唯一,不安全,可以保证元素的存取顺序。
LinkedHashSet集合没有自己特有方法,所有方法全部继承与HashSet集合。
四、Set接口之Treeset
4.1、概述
ArrayList:底层可变数组,可以保存重复元素,有下标。
LinkedList:底层链表结构,有头和尾,可以保存重复元素。
HashSet:底层哈希表,不重复,不保证存储顺序。
LinkedHashSet:底层哈希表+链表,不重复,保证存取顺序。
上面的这些集合容器可以存储对象,但是他们都不能对其中保存的对象进行排序操作。
TreeSet:它依然是Set接口的实现类,肯定可以使用Set接口中的所有方法。同时也会保证对象的唯一。
TreeSet集合容器中保存对象的时候,只要将对象放到这个集合中,集合底层会自动的对其中的所有元素进行排序。当我们在取出的时候,元素全部排序完成。
TreeSet集合:它的底层使用二叉树(红黑树)结构。这种结构可以对其中的元素进行自然排序。
构造方法:

4.2、存储字符串时按字典排序
/*
* 演示TreeSet集合
*/
publicclass TreeSetDemo {
publicstaticvoid main(String[] args) {
// 创建集合对象
TreeSet set = new TreeSet();
// 给集合中添加方法
set.add("aaa");
set.add("aaa");
set.add("aaa");
set.add("bbb");
set.add("bbb");
set.add("AAA");
set.add("ABC");
set.add("Abc");
set.add("");
// 遍历
for( Iterator it = set.iterator() ; it.hasNext() ; ){
System.out.println(it.next());
}
}
}
TreeSetDemo
4.3、树结构介绍
树:它也是一种数据结构。这种结构它默认可以对其中的数据进行排序。
我们如果给树结构中存储元素的时候,每个存储元素的空间被节点。处于树根的位置节点称为根节点。其他节点称为子节点(叶子节点)。
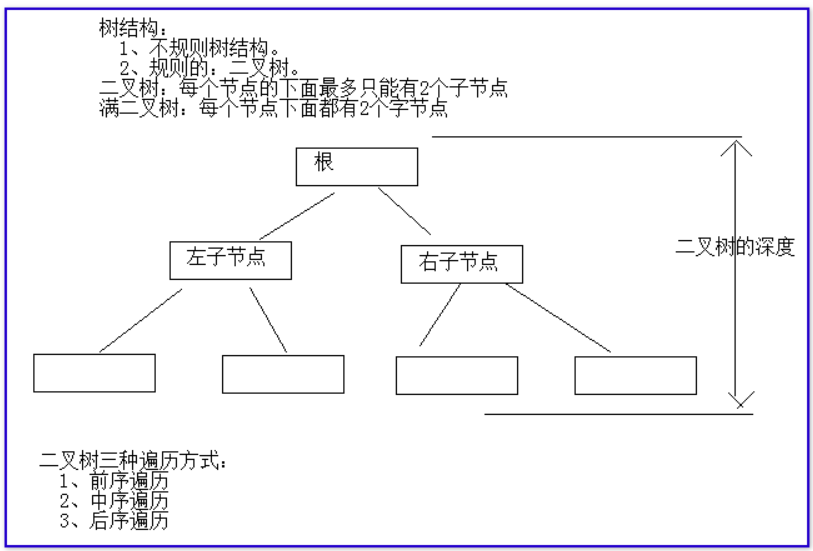
TreeSet底层存储数据时的方式:
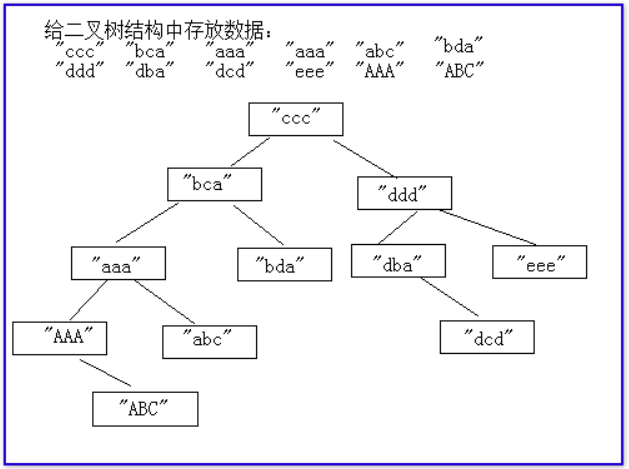
当我们给TreeSet集合中保存对象的时候,需要拿当前这个对象和已经在树上的元素进行比较大小,如果存储的元素小,就会当前这个节点的左侧保存,如果比当前这个节点的值大,就给当前这个节点的右侧保存。如果和当前 这个节点相同,丢弃不保存。
需要拿当前这个对象和当前节点上的值进行大小的比较。这时要求能够TreeSet集合中保存的对象,一定可以进行大小的比较。
注意:给TreeSet中保存的对象,一定要保证这些对象类型相同,或者他们之间有继承关系。
4.4、TreeSet保存自定义对象
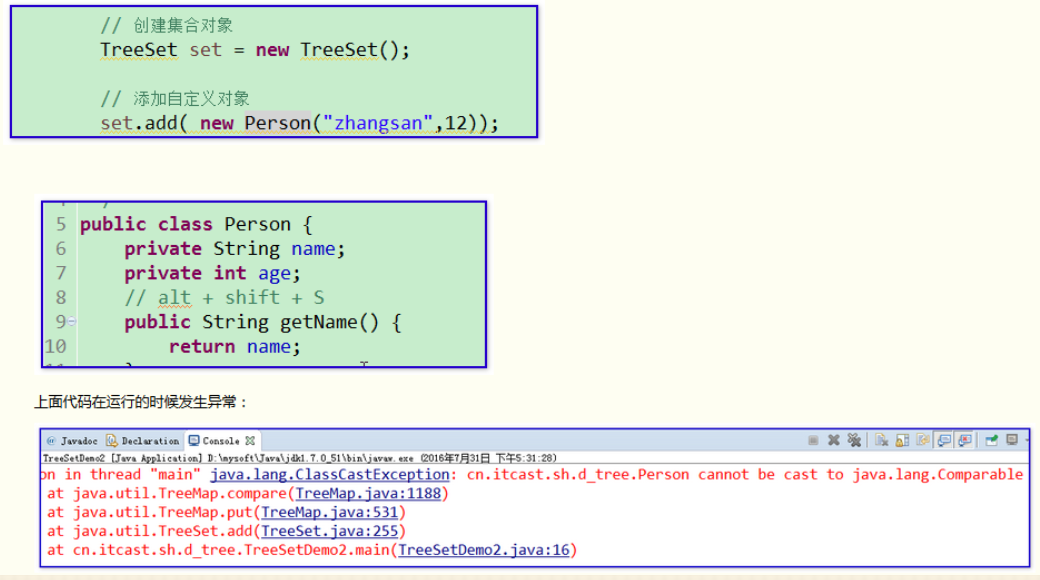
发生异常原因:
在TreeSet的底层,需要将添加到TreeSet集合中的对象强制转成Comparable类型。如果添加的对象不属于Comparable类型,那么在添加的时候就会发生类型转换异常。
底层将传递的对象强转成Comparable接口的原因:因为Comparable接口是Java中规定的比较大小的接口。只要哪个类需要比较大小,就应该主动去实现Comparable接口。
异常的解决方案:让Person类实现Comparable接口。
publicclass Person implements Comparable{
private String name;
privateintage;
// alt + shift + S
public String getName() {
returnname;
}
publicvoid setName(String name) {
this.name = name;
}
publicint getAge() {
returnage;
}
publicvoid setAge(intage) {
this.age = age;
}
@Override
public String toString() {
return"Person [name=" + name + ", age=" + age + "]";
}
public Person(String name, intage) {
super();
this.name = name;
this.age = age;
}
/*
* 当一个类实现Comparable接口之后,这个类中肯定会compareTo方法
* 而这个方法才是真比较对象大小的方法,
* 这个方法的返回值有三种情况:
* 零:表示两个对象相同
* 正数:调用这个方法的那个对象,比传递进来的这个对象大
* 负数:调用这个方法的那个对象,比传递进来的这个对象小
* 因此一般要求在实现Comparable接口之后在compareTo方法中
* 根据当前对象的自身属性的特定比较大小
*/
publicint compareTo(Object o) {
// 由于传递进来的对象被提升成Object类型,因此需要向下转型
if( !(oinstanceof Person ) ){
// 如果判断成立,说明传递进来的不是Person
thrownew ClassCastException("请传递一个Person进来,否则不给你比较");
}
// 向下转型
Person p = (Person) o;
// 因为age都是int值,如果相等,它们的差值恰好是零
inttemp = this.age - p.age;
returntemp == ? this.name.compareTo(p.name) : temp;
}
}
Person
1)Comparable接口
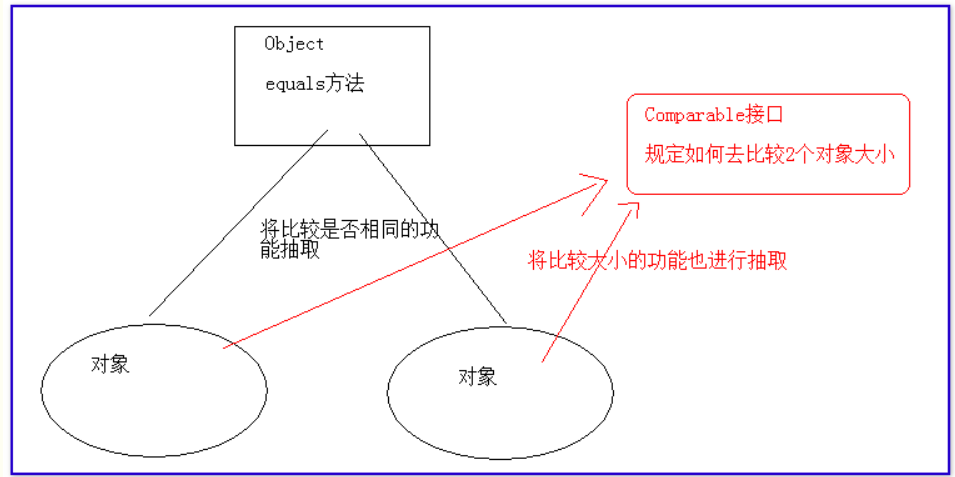
Comparable:实现它的任何类创建的对象都可以进行大小的比较。
方法:
int compareTo( T o )
Comparable接口中的compareTo方法是对2个对象进行大小比较的。
compareTo方法的返回值:
零:表示2个对象相等。
负数:表示调用compareTo方法的对象比参数中的对象小。
整数:表示调用compareTo方法的对象比参数中的对象大。
String类中拥有compareTo方法,其实是因为String类实现了Comparable接口,才使得String类可以比较任意2个字符串的大小。
总结:以后如果我们需要对某个对象进行大小比较的时候,这时需要当前这个对象所属的类实现Comparable接口。任何实现了Comparable接口的类,它们自身就具备比较大小的compareTo方法。
注意:我们让某个类实现Comparable接口,这个类具备的compareTo方法,可以比较大小,但是具体的比较的方式(compareTo方法体)依然由我们自己来书写。
2)Comparator
String类本身已经具备compareTo方法对任意2个字符串进行大小比较,String类中的compareTo方法是按照字符串中每个字符的编码值大小进行比较。
需求:希望按照字符串的长度进行比较。
分析:相当于String类中的compareTo方法不适合当前的需求,可以按照继承的方式,复写String类中的compareTo方法。
上述的这种方案,针对String类不行。

如果一个类自身已经具备compareTo方法(实现了Comparable接口),但是compareTo方法不适合当前程序要求,这时就没有办法再去使用compareTo进行2个对象的大小比较。
针对这个问题:Java中给出另外一个Comparator的接口。Comparator称为比较器。它可以对任何的对象进行大小的比较,不需要被比较的对象实现这个接口。
/*
* 演示 使用比较器 对字符串按照长度进行比较 */ public class TreeSetDemo3 { public static void main(String[] args) { /* * 在创建TreeSet集合对象的时候,如果使用的空参数的构造方法 * 创建出来的TreeSet对象底层会使用存放的元素自身的compareTo方法比较大小 * 如果在创建TreeSet对象的时候传递Comparator对象,这时TreeSet底层 * 会使用比较器对集合中的元素进行大小比较。 */ TreeSet set = new TreeSet( new MyComparator() ); set.add("aaa"); set.add("aaa"); set.add("a"); set.add("ABC"); set.add("ABC"); set.add("aa"); set.add("aa"); set.add("AAAAA"); set.add("bbbbbbbb"); // 遍历 for (Iterator it = set.iterator(); it.hasNext();) { System.out.println(it.next()); } } } /* * 自定义比较器对象 */ public class MyComparator implements Comparator{ @Override public int compare(Object o1, Object o2) { /*由于将比较器传递给TreeSet集合对象,在给TreeSet集合中存储元素的时候 自然会调用比较器中的compare方法,将正要给集合中保证的元素和已经在集合中的元素传递给 compare方法的o1和o2,这时需要我们在compare方法中书写具体的比较规则 */ if( !(o1 instanceof String) ){ throw new ClassCastException("传递的对象不是String类型"); } if( !(o2 instanceof String) ){ throw new ClassCastException("传递的对象不是String类型"); } String s1 = (String) o1; String s2 = (String) o2; /* if( s1.length() == s2.length() ){ return 0; }else if( s1.length() > s2.length() ){ return 1; }else { return -1; } */ int temp = s1.length() - s2.length(); return temp == ? s1.compareTo(s2) : temp ; } }
TreeSetDemo3
3)总结Comparator和Comparable的区别

相同点:Comparable和Comparator它们都接口,它们都可以对对象进行大小比较。
不同点:
1)Comparable需要让被比较的对象所属的类实现这个接口,在其中实现compareTo方法
2)Comparator它不要被对象所属类实现,而是自己定义Comparator接口的实现类,在需要的时候将实现类对象传递给对应的集合(工具类),在集合底层就可以使用使用比较器对象集合(工具类)中的元素进行大小比较。
3)Comparable接口中的比较方法compareTo,Comparator接口中的比较方法compare方法
觉得不错的点个“”推荐“哦”!
JavaSE(十)之Collection总结的更多相关文章
- JAVASE(十四) 集合: 数组和集合、Collection、Iterator、List、Set、Map
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.数组和集合 1.1 内存中对数据进行存储和管理的“容器”:数组,集合 1.2 数组存储的特点和缺点 ...
- Java笔记(二十二)……Collection集合
概述 为什么会出现集合类 面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式 数组和集合类同是容器,有何不同 数组虽然也可以存储 ...
- 十、collection的作用+变量
一.collection作用?容器 组织业务逻辑 导入导出 其他功能,比如监控和mock server 二.为什么要使用变量 假设我们需要测试n个api,这些api的domain都是相同的,比如 ap ...
- JAVASE(十八) 反射: Class的获取、ClassLoader、反射的应用、动态代理
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.反射(JAVA Reflection)的理解 1.1 什么是反射(JAVA Reflection) ...
- JAVASE(十六) IO流 :File类、节点流、缓冲流、转换流、编码集、对象流
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.File类型 1.1.File类的理解 File类是在java.io包下 File可以理解成一个文件 ...
- JAVASE(十五) 泛型 :泛型用例、自定义泛型类、通配符
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.泛型在集合中的使用 1.1 在集合中使用泛型之前的例子 为什么要有泛型(Generic)? 1. ...
- JAVASE(十二) Java常用类: 包装类、String类、StringBuffer类、时间日期API、其他类
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.包装类 1 .1 八个包装类 1. 2 基本数据类型,包装类,String者之间的转换 2. ...
- JAVASE(十)面向对象:特性之多态性、Object类、代码块、关键字:static、final、父子类执行顺序
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1.面向对象的特性之:多态性 多态性的理解:事物的多种形态 1.1 广义上多态性的体现:①方法的重写,重 ...
- Java学习笔记(4)——JavaSE
一.HashMap HashMap以键值对的形式存储对象,关键字Key是唯一的,不重复的 1,key可以是任何对象,Value可以任何对象 2,重复的key算一个,重复添加是替换操作(会覆盖原来的元素 ...
- Scala 语法基础
一 简介 Scala 是一门多范式(multi-paradigm)的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性.Scala 运行在Java虚拟机上,并兼容现有的Java程序.Scal ...
随机推荐
- imshow显示超大图像
在matlab做图像处理时,有些图片比较大,或者自己的显示器比较小,又要求查看完整的图片怎么办呢? 如果使用imshow直接显示,则显然没法达到要求.最好的办法还是滚动条: hFig = figure ...
- noip普及组2004 火星人
火星人 描述 人类终于登上了火星的土地并且见到了神秘的火星人.人类和火星人都无法理解对方的语言,但是我们的科学家发明了一种用数字交流的方法.这种交流方法是这样的,首先,火星人把一个非常大的数字告诉人类 ...
- ASP.NET Core 运行原理解剖[2]:Hosting补充之配置介绍
在上一章中,我们介绍了 ASP.NET Core 的启动过程,主要是对 WebHost 源码的探索.而本文则是对上文的一个补充,更加偏向于实战,详细的介绍一下我们在实际开发中需要对 Hosting 做 ...
- 2_http协议详解
当客户端与服务器进行交互时,就存在web请求,这种请求都基于统一的应用层协议(http协议)交互数据.它允许将HTML文档从web服务器传送到web浏览器. http协议是无状态的协议.无状态是指we ...
- 挖个坑,写一个Spring+SpringMVC+Mybatis的项目
想挖个坑督促自己练技术,有时候想到一个项目,大概想了一些要实现的功能,怎么实现.现在觉得自己差不多能完成QQ空间的主要功能了.准备立个牌坊,写一个类似功能的网站.并且把进度放到这里来. 初步计划实现以 ...
- js动态获取时间的方式
列子的时间是这样实现的."2017/7/25 下午10:27:11 星期二" 列子中有一个div用来放时间. 每隔1s执行一次函数,秒就会变. function showTime( ...
- Python内存优化
实际项目中,pythoner更加关注的是Python的性能问题,之前也写过一篇文章<Python性能优化>介绍Python性能优化的一些方法.而本文,关注的是Python的内存优化,一般说 ...
- Java起源
Java历史发展和特点 作为一名合格的程序员,如果不了解一些关于Java语言的起源是有一些不太合适的.下面就介绍一下我所了解的Java起源. 1.Java名字的来源 Java是印度尼西亚爪哇岛的英文名 ...
- Junit单元测试实例
1.非注解 public class Test { @org.junit.Test public void testPrice() { ClassPathXmlApplicationContext b ...
- spring整合mybatis错误:HTTP Status 404 - xxx-xxx....
运行环境:jdk1.7.0_17 + tomcat 7 + spring 3.2.0 +mybatis 3.2.7+ eclipse,访问路径:http://localhost:8085/Spring ...