netty 入门二 (传输bytebuf 或者pojo)
基于流的数据传输:
在基于流的传输(如TCP / IP)中,接收的数据被存储到套接字接收缓冲器中。 不幸的是,基于流的传输的缓冲区不是数据包的队列,而是字节队列。 这意味着,即使您将两个消息作为两个独立数据包发送,操作系统也不会把它们视为两个消息,而只是一堆字节。 因此,您无法保证您所读取的内容正是您远程发送信息时的正确切分。 例如,假设操作系统的TCP / IP堆栈已经收到三个数据包:
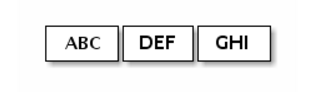
由于基于流的协议,读取的数据分片信息可能如下:
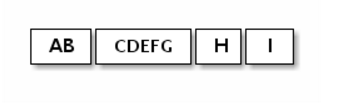
因此,无论服务器端或客户端如何,接收部分都应将接收到的数据进行碎片整理,以将其应用到逻辑上容易理解的一个或多个有意义的帧中。 在上述示例的情况下,接收到的数据应该如下所示:
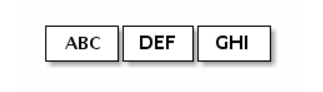
解决方案一:
现在让我们回到TIME时间客户端的例子。 我们在这里也有同样的问题。 一个32位整数是非常少量的数据,它不可能经常被分段。 然而,问题是可以分散,碎片化的可能性会随着流量的增加而增加。
简单的解决方案是创建内部累积缓冲区,并等待所有4个字节都被接收到内部缓冲区。 以下是修改的TimeClientHandler实现,可以解决问题:
package io.netty.example.time;
import java.util.Date;
public class TimeClientHandler extends ChannelInboundHandlerAdapter {
private ByteBuf buf;
@Override
public void handlerAdded(ChannelHandlerContext ctx) {
buf = ctx.alloc().buffer(4); // (1)
}
@Override
public void handlerRemoved(ChannelHandlerContext ctx) {
buf.release(); // (1)
buf = null;
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf m = (ByteBuf) msg;
buf.writeBytes(m); // (2)
m.release();
if (buf.readableBytes() >= 4) { // (3)
long currentTimeMillis = (buf.readUnsignedInt() - 2208988800L) * 1000L;
System.out.println(new Date(currentTimeMillis));
ctx.close();
}
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
cause.printStackTrace();
ctx.close();
}
}
ChannelHandler有两个生命周期侦听器方法:handlerAdded()和handlerRemoved()。 只要阻塞时间不长,您可以执行任意的初始化任务。
首先,所有收到的数据应该被累积到buf。然后,处理程序必须检查buf是否有足够的数据,在此示例中为4个字节,然后继续执行业务逻辑。 否则,Netty会在更多数据到达时再次调用channelRead()方法,最终所有4个字节都将被累积。
解决方案二:
你会发现第一种方式缺少灵活性,无法应对可变的长度字段,ChannelInboundHandler实现将很快变得不可靠。
您可能已经注意到,您可以向ChannelPipeline添加多个ChannelHandler,因此,您可以将一个单一的ChannelHandler拆分成多个模块化通道,以减少应用程序的复杂性。 例如,您可以将TimeClientHandler拆分为两个处理程序:
处理碎片问题的TimeDecoder,
初始简单版本的TimeClientHandler。
幸运的是,Netty提供了一个可扩展的类,可帮助您编写开箱即用的第一个:
package io.netty.example.time;
public class TimeDecoder extends ByteToMessageDecoder { // (1)
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) { // (2)
if (in.readableBytes() < 4) {
return; // (3)
}
out.add(in.readBytes(4)); // (4)
}
}
1,ByteToMessageDecoder是ChannelInboundHandler的一个实现,它可以轻松应对碎片问题。
2,当接收到新数据时,ByteToMessageDecoder会在内部维护的累积缓冲区中调用decode()方法。
decode()累积到足够的数据到缓存区还会刷出数据。 当接收到更多数据时,ByteToMessageDecoder将持续调用decode()。
3,如果decode()将对象刷出去,则表示解码器成功解码了消息,ByteToMessageDecoder将丢弃累积缓冲区的已经刷出的读取部分。
4,ByteToMessageDecoder将继续调用decode()方法,直到它没有读取到更多的数据。
现在我们有另一个处理程序插入ChannelPipeline,我们应该修改TimeClient中的ChannelInitializer实现:
b.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new TimeDecoder(), new TimeClientHandler());
}
});
如果你是一个冒险的人,你可能想尝试ReplayingDecoder,这更简单的解码器。 但是,您需要参考API参考资料。
public class TimeDecoder extends ReplayingDecoder<Void> {
@Override
protected void decode(
ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
out.add(in.readBytes(4));
}
}
此外,Netty还提供开箱即用的解码器,使您能够轻松实现大多数协议,并帮助您避免使用单一的不可维护的处理程序实现。 有关更多详细示例,请参阅以下软件包:
io.netty.example.factorial为二进制协议
io.netty.example.telnet用于基于文本行的协议。
==========================================================================================
读取实体(pojo)代替二进制流
我们迄今为止审查的所有示例都使用ByteBuf作为协议消息的主要数据结构。 在本节中,我们将改进TIME协议客户端和服务器示例,以使用POJO而不是ByteBuf。
在您的ChannelHandlers中使用POJO的优势是显而易见的 您的处理程序变得更加可维护,并且可以通过将从ByteBuf中提取信息的代码从处理程序中分离出来来重新使用。 在TIME客户端和服务器示例中,我们只读取一个32位整数,直接使用ByteBuf不是一个主要问题。 但是,您将发现在实现真实世界协议时需要进行分离。
首先,让我们定义一个名为UnixTime的新类型。
package io.netty.example.time;
import java.util.Date;
public class UnixTime {
private final long value;
public UnixTime() {
this(System.currentTimeMillis() / 1000L + 2208988800L);
}
public UnixTime(long value) {
this.value = value;
}
public long value() {
return value;
}
@Override
public String toString() {
return new Date((value() - 2208988800L) * 1000L).toString();
}
}
我们现在可以修改TimeDecoder来生成UnixTime而不是ByteBuf。
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
if (in.readableBytes() < 4) {
return;
} out.add(new UnixTime(in.readUnsignedInt()));
}
使用更新的解码器,TimeClientHandler不再使用ByteBuf:
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
UnixTime m = (UnixTime) msg;
System.out.println(m);
ctx.close();
}
更简单和优雅,对吧? 同样的技术可以在服务器端应用。 这次我们先来更新TimeServerHandler:
@Override
public void channelActive(ChannelHandlerContext ctx) {
ChannelFuture f = ctx.writeAndFlush(new UnixTime());
f.addListener(ChannelFutureListener.CLOSE);
}
现在,唯一缺少的部分是一个编码器,它是一个ChannelOutboundHandler的实现,将UnixTime转换成一个ByteBuf。 它比编写解码器要简单得多,因为在编码消息时不需要处理数据包碎片和汇编。
package io.netty.example.time;
public class TimeEncoder extends ChannelOutboundHandlerAdapter {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) {
UnixTime m = (UnixTime) msg;
ByteBuf encoded = ctx.alloc().buffer(4);
encoded.writeInt((int)m.value());
ctx.write(encoded, promise); // (1)
}
}
这一行中有很多重要的事情。
首先,我们按原样传递原来的ChannelPromise,以便Netty将编码数据实际写入电线时将其标记为成功或失败。
其次,我们没有调用ctx.flush()。 有一个单独的处理方法void flush(ChannelHandlerContext ctx),用于覆盖flush()操作。
为了进一步简化,您可以使用MessageToByteEncoder:
public class TimeEncoder extends MessageToByteEncoder<UnixTime> {
@Override
protected void encode(ChannelHandlerContext ctx, UnixTime msg, ByteBuf out) {
out.writeInt((int)msg.value());
}
}
最后一个任务是将TimeEncoder插入到TimeServerHandler之前的服务器端的ChannelPipeline中,这是一个简单的练习。
===============================================================================
关闭你的应用
关闭Netty应用程序通常就像关闭通过shutdownGracefully()创建的所有EventLoopGroups一样简单。 它返回一个将EventLoopGroup完全终止并且属于该组的所有通道已关闭的通知您的未来。
总结
在本章中,我们快速浏览了Netty,并展示了如何在Netty上编写完整的网络应用程序。
有关Netty的更多详细信息在即将到来的章节。 我们还鼓励您查看io.netty.example包中的Netty示例。
还请注意,社区一直在等待您的问题和想法,以帮助您,并根据您的反馈不断改进Netty及其文档。
netty 入门二 (传输bytebuf 或者pojo)的更多相关文章
- Netty入门二:开发第一个Netty应用程序
Netty入门二:开发第一个Netty应用程序 时间 2014-05-07 18:25:43 CSDN博客 原文 http://blog.csdn.net/suifeng3051/article/ ...
- Netty入门(二)之PC聊天室
参看Netty入门(一):Netty入门(一)之webSocket聊天室 Netty4.X下载地址:http://netty.io/downloads.html 一:服务端 1.SimpleChatS ...
- Netty入门(二):Channel
前言 Netty系列索引: 1.Netty入门(一):ByteBuf 2.Netty入门(二):Channel 在Netty框架中,Channel是其中之一的核心概念,是Netty网络通信的主体,由它 ...
- Netty入门之客户端与服务端通信(二)
Netty入门之客户端与服务端通信(二) 一.简介 在上一篇博文中笔者写了关于Netty入门级的Hello World程序.书接上回,本博文是关于客户端与服务端的通信,感觉也没什么好说的了,直接上代码 ...
- netty权威指南学习笔记二——netty入门应用
经过了前面的NIO基础知识准备,我们已经对NIO有了较大了解,现在就进入netty的实际应用中来看看吧.重点体会整个过程. 按照权威指南写程序的过程中,发现一些问题:当我们在定义handler继承Ch ...
- Netty入门之HelloWorld
Netty系列入门之HelloWorld(一) 一. 简介 Netty is a NIO client server framework which enables quick and easy de ...
- Netty入门
一.NIO Netty框架底层是对NIO的高度封装,所以想要更好的学习Netty之前,应先了解下什么是NIO - NIO是non-blocking的简称,在jdk1.4 里提供的新api,他的他的特性 ...
- Netty入门教程——认识Netty
什么是Netty? Netty 是一个利用 Java 的高级网络的能力,隐藏其背后的复杂性而提供一个易于使用的 API 的客户端/服务器框架. Netty 是一个广泛使用的 Java 网络编程框架(N ...
- Netty 系列(三)Netty 入门
Netty 系列(三)Netty 入门 Netty 是一个提供异步事件驱动的网络应用框架,用以快速开发高性能.高可靠性的网络服务器和客户端程序.更多请参考:Netty Github 和 Netty中文 ...
随机推荐
- Entity Framework 之Code First自动数据迁移
using MvcShopping.Migrations; using MvcShopping.Models; using System; using System.Collections.Gener ...
- 【转载】CSS3 filter:drop-shadow滤镜与box-shadow区别应用
文章转载自 张鑫旭-鑫空间-鑫生活 http://www.zhangxinxu.com/wordpress/ 原文链接:http://www.zhangxinxu.com/wordpress/?p=5 ...
- win10 UWP 隐式转换
implicit operator string <script type="text/javascript"> $(function () { $('pre.pret ...
- LVS原理讲解
一.lvs介绍 LVS的英文全名为"Linux Virtual Server",即Linux虚拟服务器,是一个虚拟的四层交换器集群系统,根据目标地址和目标端口实现用户请求转发,本身 ...
- Windows下Mysql5.7开启binlog步骤及注意事项
1.查看是否开启了binlog:show binary logs; 默认情况下是不开启的. 2.开启binlog:修改mysql的配置文件my.ini.添加如下配置: 该文件默认不允许修改,需要右键“ ...
- 重写equals和hashCode
equals()方法 1. 自反性:A.equals(A)要返回true. 2. 对称性:如果A.equals(B)返回true, 则B.equals(A)也要返回true. 3. 传递性:如果A.e ...
- Linux系统网络基本配置
1. ifconfig命令的使用: (1)查看所有网卡基本信息:ifconfig (2)查看特定网卡信息:ifconfig (网卡名,如:eht0) (3)停止网卡设备服务:ifconfig (网卡名 ...
- maven中jetty插件配置
maven中jetty插件的配置,可用于项目在内置jetty服务器中的部署. <plugin> <groupId>org.mortbay.jetty</groupId&g ...
- 2017上海QCon之旅总结(中)
本来这个公众号的交流消息中间件相关的技术的.上周去上海参加了QCon,第一次参加这样的技术会议,感受挺多的,所以整理一下自己的一些想法接公众号和大家交流一下. 三天的内容还挺多的,原计划分上下两篇总结 ...
- linux中必会的目录
第1章 find命令扩展 1.1 方法一 |xargs 通过|xargs将前面命令的执行结果传给后面. [root@znix ~]# find /oldboy/ -type f -name " ...